HTTP 란?
HTTP는 Hyper Text Transfer Protocol의 약자로, 인터넷에서 데이터를 주고받을 수 있는 프로토콜입니다.
프로토콜은 규칙이라고 생각하면 되는데요, 이렇게 규칙을 정해두었기 때문에, 모든 프로그램이 이 규칙에 맞춰
개발하면서 서로 정보를 교환할 수 있게 된거죠.
HTTP를 가장 많이 사용하는 개발자는 아마 웹 개발자일겁니다. 따라서 웹 개발자라면 HTTP에 대해서
잘 알고 있어야 하지만, 많이들 HTTP를 간과하는것 같습니다. 백엔드 개발자는 좀 덜하지만,
프론트엔드 개발자가 HTTP를 모르는 경우가 꽤 많더군요. 하지만 프론트엔드 개발자의 역할 중 하나가
서버로 데이터를 전송하는 것이기 때문에, HTTP를 모른다면 그 역할을 다하고 있다고 말할 수 없을것 같습니다.
에러를 해결하는데도 HTTP 지식이 중요한데요, 데이터를 주고 받을 때 흔히 발생하는 CORS, CORB 같은
에러들은 HTTP만 잘 알아도 쉽게 해결할 수 있습니다.
서버의 역할은 요청에 대한 응답을 보내준다는 것임을 기억하고 개념정리를 시작하겠습니다.
HTTP / 네트워크 에서 우리가 알아둬야 할것.
1. 클라이언트-서버 아키텍처를 이해할 수 있다.
쇼핑몰 앱을 이용할때, 인터넷이 끊긴 상태에서 앱을 이용한다면 정상적으로 앱을 이용할 수 없습니다.
그 이유는, 상품정보를 인터넷 어딘가에 존재하는 서버로부터 받아오기 때문입니다. 그렇기 때문에
서버로 이동할 수 있는 인터넷과 연결이 되지 않는다면 정보들을 받아올 수 없기때문에 쇼핑몰 앱을
이용할 수 없는것입니다.
그렇다고 모든 정보를 앱 자체에 담아버린다면 어떤 일이 생길까요?
처음에는 큰 문제는 없겠죠, 하지만 새로운 상품들이 최신화가 되고, 앱의 UI가 업데이트가 된다면
앱을 이용하는 사용자는 앱스토어에가서 앱을 업데이트 시켜줘야 될겁니다.
뭐, 한두번이야 괜찮겠지만 상품은 계속해서 올라올것이고, 폰트하나, 간격하나만 바뀌어도 사용자가
맨날 앱을 업데이트 시켜야 한다면 그것은 꽤 귀찮은 일이 될겁니다.
실시간으로 정보를 전달하기가 매우 어려워진다는것이죠, 그걸 떠나서도 결제라는 행동을 할때도
어차피 은행과의 서버 연결이 필요하기 때문에 인터넷, 서버없이는 앱을 운용할 수 없을것입니다.
이렇게 상품정보같은 리소스가 존재하는 곳과, 리소스를 사용하는 앱을 분리시킨것을
클라이언트-서버 아키텍처 (2티어 아키텍처) 라고 합니다.
상품정보는 서버에서 다루고 있고, 클라이언트(앱) 은 단지 상품의 정보만을 조회하는 겁니다.
2. HTTP를 이용한 클라이언트-서버 통신을 이해할 수 있다.
클라이언트와 서버가 어떤식으로 통신하는지 이해해보겠습니다.
클라이언트와 서버간의 통신은 요청과 응답으로 구성됩니다.
예시를 들어보자면, 카페에 온 손님과 카페 직원이 있습니다. 손님은 커피를 주문하고
직원은 주문받은 커피를 만들어 손님에게 제공하겠죠.
직원이 인심이 좋아서 주문하지도 않은 커피를 갑자기 제공할 수도 있겠지만,
대개는 손님으로부터 주문이 들어와야 커피가 나갑니다.
클라이언트와 서버의 관계도 마찬가지 입니다, 클라이언트에게서 요청이 들어와야
서버가 그에 맞는 응답을 보내줄 수 있는겁니다.
그리고 클라이언트-서버 간 통신을 이해하기 위해 필요한것이 있는데, 그건 프로토콜의 개념입니다.
프로토콜은 통신규약, 즉 약속입니다.
카페에 들어온 손님이 갑자기 국밥을 주문하거나, 알아들을 수 없는 외계어같은 말로 주문을 한다면
직원은 그 요청에 대한 응답을 제공할 수가 없겠죠? 이렇듯 요청을하기 위해서는 몇가지 약속이 존재합니다.
웹 어플리케이션 아키텍쳐에서는 클라이언트와 서버가 서로 HTTP라는 프로토콜을 이용해서
서로 대화를 나눕니다. HTTP를 이용해 주고받는 메세지를 "HTTP 메세지" 라고 하죠.
우리는 카페에 가서 커피를 주문할때 여러방법으로 주문을 할 수 있습니다.
직원에게 직접 주문을 하는방법, 핸드폰 어플을 이용하는 방법, 키오스크를 이용하는방법, 다양합니다.
이런 방법 하나하나가 전부 프로토콜이라고 볼 수 있습니다,
같은일을 하기위해 다양한방법이 존재할 수 있다는겁니다.
이번엔 규약이라는 측면에서 이해를 해볼까요, 앞에서 이야기했듯 카페에서 외계어나, 메뉴에 없는것을
요청한다면 상품주문을 할 수 없겠죠. 우편을 보낼때도, 수신자나 우표를 첨부하지 않는다면 우편은
수신자에게 전달되지 못할겁니다, 우편을 보낼때도 규약이란것이 있다는걸 의미하는거죠.
프로토콜은 각자의 프로토콜마다 지켜야하는 규칙이 존재합니다.
3. API의 개념을 이해할 수 있다.
다시 카페로 돌아가보겠습니다. 카페에 온 손님은 메뉴판을 보고 주문을 하게 됩니다.
그런데 이때 손님이 직원에게 "알아서 맛있게 타와" 라고 한다면? 뭐.. 손님과 직원이 그정도의
친한관계라면 알아서 대접하겠지만, 그렇지 않다면 불쾌해하며 메뉴판에 있는 메뉴를 주문하도록
다시 요청하겠죠, 그렇다고는 해도 직원이 아무거나 탈 수는 있습니다, 하진 않을 뿐이죠.
하지만 컴퓨터세계에서는 다릅니다, 컴퓨터에게는 아무거나 맛있게 타오라는 요청은 의미가 없습니다.
0과 1로 되어있는 요청만을 원할뿐입니다, 그것만 해석할 수 있거든요, 그래서 컴퓨터가 원하는대로
그렇게 요청해주려는데 생각해보니까 우리는 서버가 어떻게 구성되어 있는지를 알 수가 없습니다,
우리가 이 서버를 만든게 아니니까요, 그래서 주문을 하고 싶어도 못하는 상황이 발생하게 됩니다.
이럴때 우리는 어떻게 사용가능한 자원을 파악할 수 있을까요?
이때 필요한것이 바로 API (Application Progamming Interface) 입니다.
서버는 클라이언트에게 리소스를 잘 활용할 수 있도록 인터페이스를 제공해줘야 합니다.
서버를 이용할 수 있는 메뉴판을 제공한다고 생각하면 쉬울것 같습니다.
또 카페로 와보자면, 카페는 손님이 엉뚱한 주문을 하지 않게끔 하기 위해 도와주어야 합니다.
카페에 와서 손님이 설렁탕(메뉴에 없는 주문) 을 주문하지않게 하기위해서지요,
손님은 "아메리카노, 라떼, 에이드 를 주문할 수 있습니다." 라고 메뉴판을 만들어 놓아야
손님이 그것을 보고 적절하게 아메리카노 등을 주문할 수 있게 되는것입니다.
마찬가지로 서버가 리소스 전달을 위한 메뉴판, 즉 API를 구축해 놓아야 클라이언트가 이를 활용할 수 있게됩니다.
보통 인터넷에 있는 데이터를 요청할 때에는 HTTP 라는 프로토콜을 사용하며, 주소(URL,URI)를 통해
접근할 수 있게 됩니다.
HTTP 요청에는 메소드라는것이 존재합니다. 앞서 카페에서는 리소스를 그저 달라고 (GET) 요청했지만,
사용자 관리 API에서는 사용자를 추가해달라고 (CREATE) 요청하거나, 지워달라고 (DELETE)
요청할 수 있습니다.
우리가 기억해야 할 다섯가지 메소드는 다음과 같습니다, GET, POST, PUT or PATCH, DELETE
각각 조회, 추가, 갱신, 삭제와 관련이 있다. 행동에 맞게 메소드를 적절하게 사용해야 됩니다.
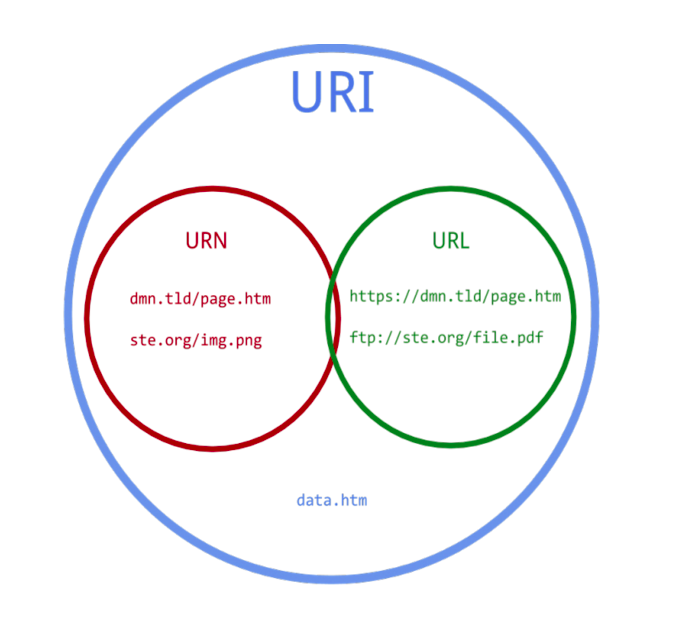
4. URL과 URI의 차이를 이해할 수 있다.

URL은 Uniform Resource Locator의 줄임말로, 네트워크 상에서 웹 페이지, 이미지, 동영상 등의
파일이 위치한 정보를 나타냅니다.
URL은 scheme, hosts, url-path로 구분할 수 있습니다. 가장 먼저 작성하는scheme는
통신 방식(프로토콜)을 결정합니다. 7가지의 프로토콜이 있고, 그 중 하나가 사용됩니다.
일반적인 웹 브라우저에서는 http(s)를 사용합니다. 가장 많이 접한것일겁니다.
hosts는 웹 서버의 이름이나 도메인, IP를 사용하며 주소를 나타냅니다.
url-path는 웹 서버에서 지정한 루트 디렉토리부터 시작하여 웹 페이지, 이미지, 동영상 등이
위치한 경로와 파일명을 나타냅니다.
인터넷 상에서 특정 자원(파일, 이미지, 페이지)을 나타내는 유일한 주소 라고 생각하면 될것 같습니다.
URI는 Uniform Resource Identifier의 줄임말로, 일반적으로 URL의 기본 요소인
scheme, hosts, url-path에 더해 query, bookmark를 포함합니다.
query는 웹 서버에 보내는 추가적인 질문입니다.
위 그림의 http://www.google.com:80/search?q=JavaScript 를 브라우저의 검색창에 입력하면,
구글에서 JavaScript를 검색한 결과가 나타납니다.
URI 가 URL을 포함하는 상위개념이라고 생각하면 됩니다. 아래의 그림이 참고가 될겁니다.
5. IP 주소와 PORT에 대해 이해할 수 있다.
$ IP주소란 무엇인가?
ip주소는 '네트워킹이 가능한 장비를 식별하는 주소' 입니다.
여기에서 말하는 네트워킹이 가능한 장비라 함은 PC, 서버장비, 스마트폰, 태블릿pc, 인터넷이가능한
전자사전 등등, 인터넷에 연결되는 모든 장비들을 말합니다.
네트워크상에서 통신을 하기위해서는 몇가지 통신규약(Protocol)을 따라야 하는데, 그러한 규약들중에는
"네트워킹을 하는 장비들에게 숫자 12개의 고유한 주소를 주어서, 그 주소로 통신을 할 상대를 구분하도록 하자!"
라는 의미를 가진 규약이 존재합니다. 위의 규약에서 말하는 숫자12개의 고유한 주소가
바로 ip주소가 되는것이죠. 따라서 ip주소는 여러분들이 사용하는 통신기기에 하나씩 부여가 되고,
그 덕분에 인터넷이 가능하게 되는 원리입니다.
ip주소라는 개념이 처음 만들어질때 당시에는, 지금처럼 네트워킹이 가능한 장비의 종류가 다양하지 않았습니다.
또한 그 수도 많지 않았었기도 했죠. 당시의 개발자들은 기술의 발전을 염두에두고, 12자리의 10진수 숫자의 배열로
ip주소를 만듦으로서 약 40억개의 주소가 존재할 수 있도록 설계하였었는데,
이것이 바로 IPv4 입니다. (123.321.465.789) 이러한 형태를 가지고 있습니다.
하지만, 기술이 급속도로 발전하면서 PC가 보급되고, 노트북, 심지어는 스마트폰까지 등장하면서
한 사람이 가지는 네트워킹이 가능한 단말기의 수가 2개, 3개가 되어버리자 약 40억개에 달하는
ip주소의 수가 부족해지기 시작하는 지경에 이르게 되었습니다.
그렇게 해서 등장한것이 IPv6인데, 여기까지 깊게들어가진 않겠습니다,
쉽게만 설명하자면 40억개에서 거의 무한대에 가까운 IP주소를 만들어 냈다고 보면 될것 같네요.
$ PORT란 무엇인가?
PORT 는 보통 항구나 공항(airport)을 나타냅니다.
이러한 항구와 공항은 외부세계와 (해외) 접속할 수 있는 관문이 됩니다.
컴퓨터에서도 마찬가지인데, 컴퓨터에서의 포트(port)란
외부의 다른 장비와 접속하기 위한 플러그와 같은 것을 의미합니다.
컴퓨터나 노트북의 뒷면이나 옆면을 보면 네트워크, 마우스, 키보드 등을 연결하기 위한
포트들을 확인할 수 있죠. 이러한 포트 개념은 프로그램에도 있습니다.
우리가 웹브라우저를 이용하여 인터넷상에 있는 서버에 접속할 때, 컴퓨터에 있는 웹브라우저 프로그램과
서버에 있는 웹서버 프로그램간을 연결해주는 플러그와 같은 역할을 하는 것이 바로 포트입니다.
우리가 특정 서버에 접속하려면 URL이나 IP 주소를 입력하죠?
그러면 인터넷상에서 URL 또는 IP를 토대로 해당 서버가 있는 컴퓨터로 찾아가게 됩니다.
그런데 대부분의 컴퓨터에서는 여러 개의 프로그램이 동시에 실행되고 있어서,
이 여러개의 프로그램 중 어느 프로그램이 내가 접속하려는 프로그램인지 컴퓨터에게 알려 주어야 합니다.
여기서 포트 번호는 어떤 프로그램에 접속 할 것인지 컴퓨터에게 알려줍니다.
즉, 포트는 "논리적인 접속장소를 나타내는 이정표"라고 말할 수 있겠습니다.
[IP address, Port] => IP address는 컴퓨터를 찾을 때 필요한 주소를 나타내며,
Port는 컴퓨터 안에서 프로그램을 찾을 때를 나타내는 것입니다.
이 두 개를 이용하여 특정 컴퓨터의 프로그램을 이용 할 수 있게 되는것입니다.
6. DNS와 IP 주소의 관계를 설명할 수 있다.
우리가 네이버에 접속할때, 주소창에 네이버의 IP주소를 적고 들어가는 경우는 거의 없는걸로 알고 있습니다.
왜냐하면 네이버의 IP주소 125.209.222.141 보다 도메인주소 naver.com 을 더 많이 기억하고 있기 때문이죠.
DNS는 Domain Name Server 의 약자로, 네트워크상 에서 사람이 알기 쉽게 만들어진 도메인을
컴퓨터가 읽을 수 있는 IP주소로 바꿔주는 시스템입니다.
우리는 친구에게 전화를 걸때, 친구의 이름을 검색해서 전화를 걸지만, 친구의 이름으로 전화를 거는것이 아니라
이름에 저장되어 있는 친구의 전화번호로 전화를 거는것이죠?
이처럼 도메인 이름도 그 자체가 주소가 아닌, IP주소가 저장되어 있는 사용자가 사용하기 쉽도록 작성된
이름이라고 생각하면 될듯합니다. 우리가 도메인 주소를 입력하면, 컴퓨터는 그 도메인 주소에 등록되어 있는
그 사이트의 IP주소로 변환하여 사이트에 접속이 되는것입니다.
그리고 이것을 가능하게 해주는것이 바로 DNS가 되겠습니다.
