
📢 개요
지난 포스트에 이어서 이번 포스트에서는 Data Reduction 과정 중 두 번째 방법인 'Feature Selection' 방법에 대해 정리해보고자 한다. 기존의 데이터 feature들의 결합 변수를 만들어 데이터를 축소하는 Feature Extraction method와 달리, Feature Selection method는 feature 중 target에 가장 관련성이 높은 feature만을 선정하여 feature의 수를 줄이는 방법이다. 이는 모형을 단순화해주며 훈련 시간을 단축할 수 있으며 차원의 저주 및 과적합(Overfitting)을 방지할 수 있는 장점이 있는 기법이다. Feature Selection에 해당하는 기법들에는 무엇이 있는지 지금부터 알아보도록 하자.
✏️ 특성 선택(Feature Selection)이란?
👉 피쳐 중 타겟에 가장 관련성이 높은 피쳐만을 선정하여 피쳐의 수를 줄이는 방법
👉 모델 성능을 높이기 위해서 반드시 필요한 기술 중 하나
👉 모델링 시 data의 모든 feature를 사용하는 것은 memory 측면에서 매우 비효율적이기 때문에 일부 필요한 feature만 선택해서 사용하고자 하는 기법
⭐ 장점
- 학습 시간을 줄일 수 있음
- 결과를 해석하기 쉽게 모델이 단순화
- 차원의 저주 및 과적합 방지
📂 방법
👉 Feature Selection의 방법은 크게 3가지로 분류됨
- Filter Method : Feature 간 관련성을 측정하는 방법
- Wrapper Method : Feature Subset의 유용성을 측정하는 방법
- Embedded Method : Feature Subset의 유용성을 측정하지만, 내장 metric을 사용하는 방법
📙 Filter Method
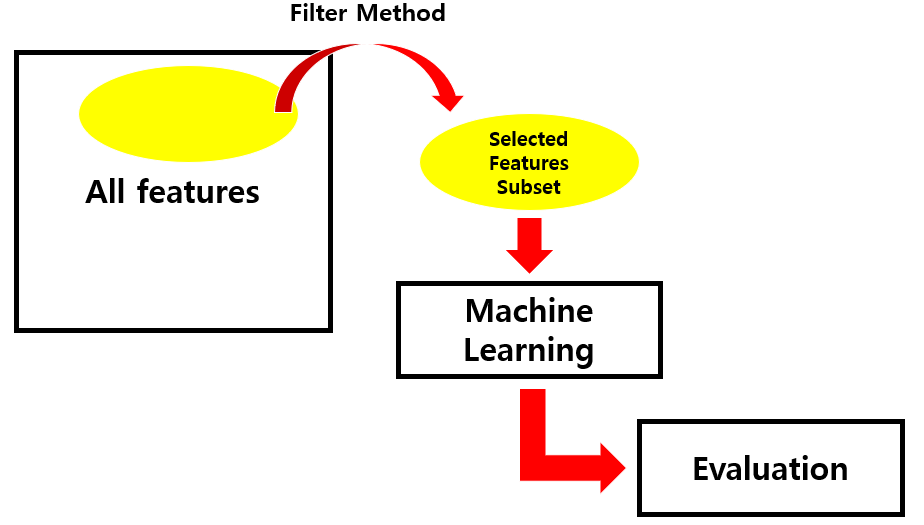
👉 전처리 과정에서 통계적 측정 방법을 사용하여 feature 간의 상관관계를 파악한 뒤, 높은 상관계수(영향력)을 가지는 feature를 사용하는 방법
👉 상관계수가 높은 feature라고 해서 모델에 적합한 feature 인 것은 아님
👉 계산속도가 빠르고 변수 간 상관관계를 알아내는 데 적합하여 래퍼 기법(Wrapper Method)을 사용하기 전에 전처리하는 데 사용
👉 가장 많이 사용되는 방법
🔎 알고리즘 종류
✅ 분산 기반 선택(Variance Threshold)
- 분산이 낮은 변수를 제거하는 방법
✅ 정보 소득(Information Gain)
- 가장 정보 소득이 높은 속성을 선택하여 데이터를 더 잘 구분하게 되는 것
✅ 카이제곱 검정(Chi-Square Test)
- 카이제곱 분포에 기초한 통계적 방법으로 관찰된 빈도가 기대되는 빈도와 의미있게 다른지 여부를 검증하기 위해 사용되는 검증 방법
✅ 피셔 스코어(Fisher Score)
- 최대 가능성 방정식을 풀기 위해 통계에 사용되는 방법
✅ 상관계수(Correlation Coefficient)
- 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관관계의 정도를 수치적으로 나타낸 계수
📗 Wrapper Method
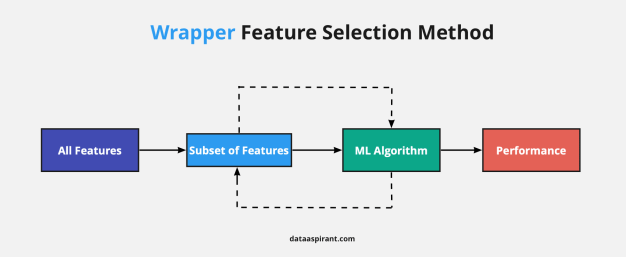
👉 예측 정확도 측면에서 가장 좋은 성능을 보이는 Feature Subset(특성 집합)을 선택하는 기법
👉 Feature의 조합을 정하여 기계학습을 진행 한 뒤, 성능 평가까지의 일련의 과정을 feature 조합을 바꿔가면서 계속해서 반복하여 가장 성능이 좋은 조합을 찾아내는 기법
👉 반복적으로 학습을 진행하는 방법이기에 굉장히 많은 시간이 소요되며, 부분집합의 수가 기하급수적으로 증가하여 과적합의 위험이 존재
👉 일반적으로 Filter Method보다 예측 정확도가 높음
🔎 알고리즘 종류
✅ Forward Selection
- 변수가 없는 상태로 시작하여, 모형을 가장 많이 향상시키는 변수를 하나씩 점진적으로 추가하는 방법
- 더 이상의 성능 향상이 없을 때 까지 변수를 추가
✅ Backward Elimination
- 모든 feature를 가지고 시작하여 가장 적은 영향을 주는 feature를 하나씩 제거하면서 성능을 향상시키는 방법
- 더 이상의 성능 향상이 없을 때 까지 변수를 제거
✅ Stepwise Method
- Forward Selection과 Backward Elimination을 결합하여 사용하는 방법
- 모든 변수를 가지고 시작하여 최악의 feature를 제거하거나, 모델에서 빠져있는 feature 중 최상의 feature를 추가하는 방법
- 즉 변수의 추가, 삭제를 반복하는 방법
- 반대로 feature가 없는 상태에서 시작하여 변수의 추가, 삭제를 반복할 수도 있음
📗 Embedded Method
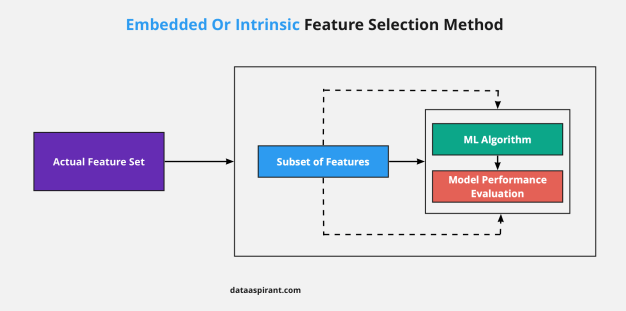
👉 Filter와 Wrapper method의 장점을 결합한 방법
👉 Feature selection 기능이 자체적으로 추가되어 있는 모델을 사용하는 방법
👉 각각의 feature를 직접 학습하여 모델의 정확도에 기여하는 feature를 선택
🔎 알고리즘 종류
✅ Lasso Regression
- L1-norm을 통해 제약을 주는 방법
✅ Ridge Regression
- L2-norm을 통해 제약을 주는 방법
✅ SelectFromModel
- Decision Tree 기반 알고리즘에서 feature를 뽑아오는 방법
✅ Elastic Net
- 위 둘을 선형결합한 방법
🙏 Reference
https://analysisbugs.tistory.com/112
https://wooono.tistory.com/249
