
Spring
IoC (Inversion of Control) 란 ?
제어의 역전
- IoC는 객체의 생성과 관리를 스프링 프레임워크가 대신하도록 위임
- 스프링 컨테이너에 Bean을 미리 등록하고, 필요한 곳에서 컨테이너에서 빈을 가져와 사용할 수 있게 된다.
- 이때, Bean을 가져올 때 의존성 주입(DI) 방식을 사용하여 객체 간의 의존성을 자동으로 주입받을 수 있게 된다.
DI (Dependency Injection) 란 ?
의존성 주입
- DI는 객체 간의 의존성을 줄이고 유지보수성을 높이기 위해 사용된다.
- 스프링에 Bean으로 등록한 객체를 주입받아서 사용할 수 있다.
- 생성자 주입, Setter 주입, Field 주입 세 가지 방법이 있는데, 이 중 생성자 주입을 권장
- 객체의 생명주기를 관리하는 것을 스프링 컨테이너에게 위임하여 객체 간의 결합도를 낮추고 유연한 구조를 유지할 수 있게 되어, 개발자는 객체 생성에 대한 부분을 신경 쓰지 않고 비즈니스 로직에만 집중할 수 있게 되어, 코드의 가독성과 유지보수성을 높일 수 있다.
Spring Bean 이란 ?
- 스프링 컨테이너에 의해 관리되는 객체
- 객체 생성, 의존성 주입, 라이프 사이클 관리 등을 스프링에 위임
@Bean,@Configuration을 이용해서 직접 등록@Component어노테이션
Bean 생명주기
스프링 IoC 컨테이너 생성 → 스프링 Bean 생성 → 의존성 주입 → 초기화 콜백 메서드 호출 → Bean 사용 → 소멸 전 콜백 메서드 호출 → 스프링 종료
- 생명 주기 : 객체 생성 → 의존 설정 → 초기화 → 사용 → 소멸
@PostConstruct로 초기화 /@PreDestory로 소멸
콜백 메서드 : 개발자가 정의한 클래스나 인터페이스에 의해 호출되는 메서드
ex) @PostConstruct - init() / @PreDestroy - destroy()
Bean Scope
빈이 언제 생성되고, 언제 소멸되는지 → 싱클톤 / 프로토타입 / Rquest / Session
- 싱글톤이 기본으로 설정 → 가장 긴 주기를 갖는 빈 스코프
- 프로토타입 → 가장 짧은 생명주기를 갖는 빈 스코프, 호출 시 생성되고 스프링 컨테이너에서 관리하지 않음
Spring IoC Container
Spring이 Bean으로 등록된 객체의 라이프 사이클과 의존성을 관리해 주는 컨테이너
애플리케이션 실행 시점에 Bean 객체를 인스턴스화하고, 의존성을 주입한 뒤에 최초로 애플리케이션을 기동 할 빈 하나를 제공해 줍니다.
MVC
MVC는 Model, View, Controller의 약자로, 애플리케이션을 구성하는 컴포넌트들의 역할을 크게 3가지로 구분한 것
- Model은 비즈니스 로직과 데이터를 담당합니다. 비즈니스 로직을 통해 데이터를 처리하고, 저장하는 등의 역할
- View는 모델에서 처리된 데이터를 사용자에게 보여주는 역할을 합니다. 주로 HTML, CSS, JS로 이루어진 프런트 영역
- Controller는 클라이언트와 소통을 담당합니다. 즉, 클라이언트의 요청을 받아서 처리하고, 그 결과를 View에 전달하는 역할
레이어드 아키텍처
레어이드 아키텍처는 애플리케이션을 구성하는 컴포넌트를 레이어로 묶어서 수평적으로 구성한 구조
Spring Boot Project를 만들 때 MVC 패턴과 레이어드 아키텍처를 이용하여 프로젝트 구조를 설계
- 프레젠테이션 계층과 비즈니스 계층, 데이터 접근 계층의 3 계층으로 구성
- Controller는 프레젠테이션 계층을 담당, 클라이언트의 요청을 처리하는 역할
- Service는 비즈니스 계층에 혜당, Repository를 이용하여 데이터에 접근하고 비즈니스 로직을 처리하여 Controller로 반환
- Repository는 데이터 접근 계층에 해당되어 DB에 직접 접근하는 역할
4 계층으로 표현될 경우 인프라 계층(DB)까지 포함한 것
레이어드 아키텍처와 MVC 패턴을 이용했을 때 장점
- 각 레이어가 위에서 설명한 특정한 책임과 역할을 명확히 가지게 돼서 객체지향적으로 설계할 수 있다.
- 각 레이어의 역할이 명확해져서, 코드를 이해하기 쉬워지고 유지보수가 쉬워진다.
- 각 레이어의 게층을 나눠서 모듈화 할 수 있다.
- 각 레이어의 하위 모듈에만 의존하도록 하여 의존성을 최소화 할 수 있다.
- 각 레이어의 역할이 명확하고 모듈화되어 테스트가 용이해진다.
- 각 레이어가 독집럭으로 개발되기 때문에 재사용성과 확장성이 좋아진다.
Spring MVC 동작구조 - DispatcherServlet
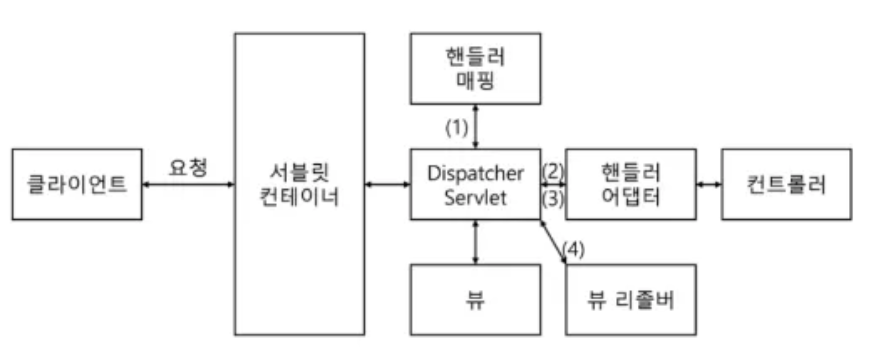
- 클라이언트에게 요청(HttpServletRequest)을 받는다.
- DispatcherServlet은 HandlerMapping을 통해 Handler를 찾는다.
- DispatcherServlet은 HandlerAdapter 조회하고 실행한다.
- HandlerAdapter는 Handler를 호출해서 요청을 처리합니다.
- 처리된 데이터는 DispatcherServlet으로 반환됩니다.
REST 방식의 경우
데이터를 MessageConverter를 통해 JSON 형식으로 변환하고, ResponseBody로 응답
REST 방식이 아닌 경우
View Resolver를 찾아서 실행하고, 이 ViewResolver는 View에 전달할 데이터를 추가하여 클라이언트에게 View를 반환합니다.
- Dispatcher Servlet : 요청부터 응답까지 처리 과정을 제어, 통제
- HandlerMapping : 어떤 Controller가 요청을 처리할지 결정
- HandlerAdapter : HandlerMapping을 통해 얻은 Handler(Controller) 정보를 바탕으로 해당 메서드를 호출한다.
- ViewResolver : View를 랜더링 하여 클라이언트에 반환한다.
JPA
ORM이란 ?
Object Relational Mapping으로, 객체 관계 매핑을 의미합니다. 객체지향 언어에서 객체와 RDB의 테이블을 자동으로 매핑해 주는 기술입니다.
DB 테이블을 마치 객체처럼 다룰 수 있게 해 주어서, SQL문 대신 코드로 DB를 다룰 수 있게 도와줍니다.
장점
- 객체지향적으로 DB쿼리를 조작할 수 있고, SQL을 직접 작성하지 안하도 돼서 개발 비용이 줄어든다.
- 코드 가독성, 재사용성, 유지보수성이 좋아진다.
- 특정 DB에 대한 종속성이 줄어든다.
ORM, JPA, Spring data JPA의 차이
JPA는 자바 진영에서 표준으로 된 ORM이고, JPA는 인터페이스의 집합이다.
즉 JAVA에서 사용하는 ORM 표준은 JPA이다.
Spring data JPA라는 라이브러리를 주로 사용
JPA는 인터페이스라고 하였는데, JPA의 대표적인 구현체 중 하나인 Hibernate를 개발자가 사용하기 쉽게 모듈화 한 것이 Spring data JPA
- ORM!= JPA / Spring data JPA!= JPA
- JPA는 자바의 ORM
- Spring data JPA = JPA의 구현체중 하나인 Hibernate를 사용하기 편하게 모듈화 하여 제공하는 라이브러리
영속성 컨텍스트란 ?
- 데이터를 영구 보관하는 환경
- 애플리케이션과 DB 사이에서 객체를 보관하는 가상 데이터베이스 역할
- 논리적인 개념으로, 눈에 보이진 않지만 EntityManager가 생성될 때 1대 1로 영속성 컨텍스트가 생성
- EntityManager를 통해 영속성 컨텍스트에 접근하여 데이터를 핸들링
영속성 컨텍스트는 트랜잭션 단위로 동작
트랜잭션이 시작될 때 EntityManger가 생성되고, 1대 1로 영속성 컨텍스트가 생성
트랜잭션이 커밋되면 EntityManger와 영속성 컨텍스트 모두 사라지게 된다.
JPA 영속성 컨텍스트의 이점
1차 캐시
영속성 컨텍스트 내에 위치하여 캐시와 같은 역할 수행
- 데이터를 SELECT 할 때, 우선 1차 캐시에서 해당 데이터를 탐색
- 만약 1차 캐시에 해당 데이터가 있으면 1차 캐시에 있는 데이터를 반환
- 없으면 DB에서 직접 SELECT 하여, 1차 캐시에 저장 후 1차 캐시에 저장된 데이터를 반환
마찬가지로 저장할 떄도 1차 캐시에 우선 저장되고 트랜잭션 커밋 시에 실제 DB에 저장한다.
동일성 보장
1차 캐시에 의해 엔티티는 영속성 컨텍스트에 관리되고, SELECT 해올 때 1차 캐시에서 데이터를 불러온다. 이 때문에 JPA로 같은 데이터를 두 번 조회하면 두 데이터는 주소까지 일치하게 되어 == 비교가 가능하다.
쓰기 지연
트랜잭션이 커밋되기 전 까지 영속성 컨텍스트 내에 위치한 쓰기 지연 SQL 저장소에 SQL 쿼리를 저장해 뒀다가 트랜잭션이 커밋되는 시점에 모든 SQL을 DB에 전달
변경 감지
엔티티가 변경되면 따로 저장하거나, 수정하는 코드 또는 쿼리를 작성하지 않아도 자동으로 변경
처음 DB에서 데이터를 SELECT 하여 1차 캐시에 데이터를 저장할 때 스냅샷을 저장해 뒀다가 커밋이 일어날 때 이 스냅샷과 비교하여 UPDATE 쿼리를 자동으로 생성하여 DB에 전달
지연 로딩
연관관계가 있는 엔티티가 있을 때, 해당 엔티티를 실제 사용할 때 SELECT 쿼리를 날리는 기능
연관관계의 주인인 Entity를 조회할 때 연관관계 Entity까지 동시에 불러오게 되는 즉시로딩과 대비되는 개념
JPA N+1 문제
N + 1 문제란 ?
N + 1 문제는 연관관계 설정된 필드가 있는 Entity를 findAll() 메서드를 이용해서 여러 건의 Entity를 한 번에 조회할 때 발생하는 문제. findAll()로 조회한 Entity의 개수만큼, 연관관계 Entity에 대한 단건 조회 쿼리가 나간다.
findAll() 로 n개의 데이터를 조회했을 때, 연관관계 Entity에 대한 단건 조회 쿼리가 n번 나가게 되어 총 n + 1 개의 쿼리가 나가게 된다.
여기서 단건 조회 쿼리는 findById() 와 같은 쿼리를 말한다.
해결방법
@Query 어노테이션을 이용해서 JPQL을 직접 작성하여 join fetch 구문을 추가하여 연관관계 Entity까지 한번에 조회하는 방법으로 해결할 수 있다.
@Query("SELECT distinct t FROM Team t join fetch t.members")
List<TeamEntity> findAll();지연로딩, 즉시로딩 중 언제 N+1 문제 발생 ?
이 문제는 지연 로딩, 즉시 로딩 모두 발생한다.
즉시 로딩 시에는 조회 메서드 사용 시 findAll()을 한 Entity를 불러오는 쿼리가 1번 나가고, 연관 관계 Entity에 대한 단건 조회 쿼리가 n번 나간다.
지연 로딩 시에는 findAll() 메서드 사용 시 1번의 쿼리만 나가지만 마찬가지로 조회한 메서드를 순회하며 연관관계 Entity를 사용한다면 연관관계 Entity에 대한 단건 조회가 n번 나간다.
지연 로딩 시 findAll()로 불러온 List중 하나의 데이터의 연관관계 Entity만 조회한다면 1번만 추가로 쿼리가 나간다.
