0. Introduction
GPT1의 논문 제목은 "Improving Language Understanding
by Generative Pre-Training"이다. 논문의 abstract를 보면 다음과 같이 기술되어 있다. 대규모의 unlabeled 말뭉치는 많지만 특정 task를 학습하기 위한 labeled data는 적다. 따라서 이러한 문제를 해결하기 위해서 pre-train 단계에서 풍부한 unlabeled data에서 진행하고 그 다음에 fine- tunning을 진행 시키겠다는 것이다.
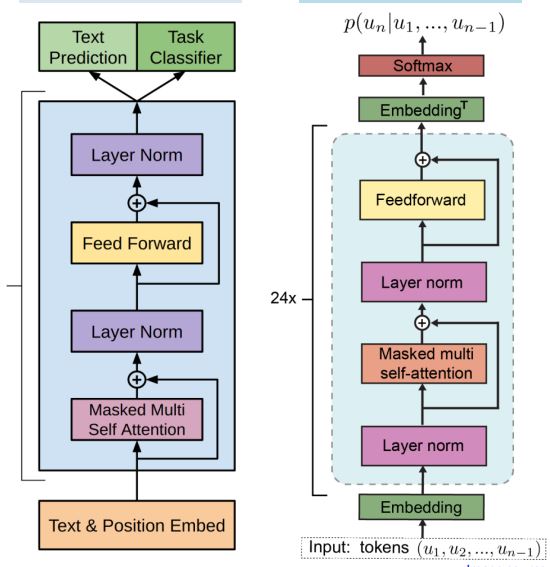
1. GPT 1,2 모델 아키텍쳐 비교
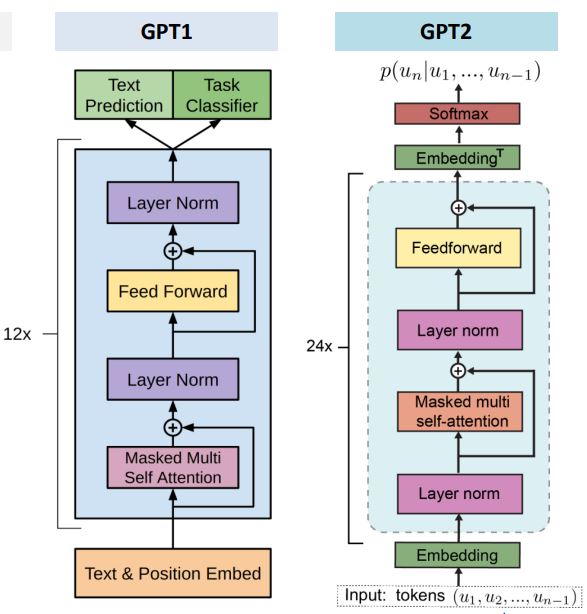
[출처] : https://www.researchgate.net/publication/335737829_Tracking_Naturalistic_Linguistic_Predictions_with_Deep_Neural_Language_Models
기본적으로 GPT는 Transformer의 decoder부분을 떼어와서 만든 것이다. Transformer와의 차이점이라면 활성함수를 relu가 아닌 gelu를 사용했다는 점과 Ecoder의 output과 연결되는 Multi-head attention층을 없앤 것이 주요 특징이다. GPT 1,2의 차이는
layer normalization의 위치가 바뀌었다는 점이 가장 두드러지는 점이다. 또한 추가적인 layer normalization이 Residual connection에 의해 masked multi self attentnion 다음에 추가되었다.
2. 특정 task에서의 input transformation
GPT 1에서는 모든 transformation이 랜덤하게 초기화된 start, end 토큰을 추가하는 것을 포함 합니다.
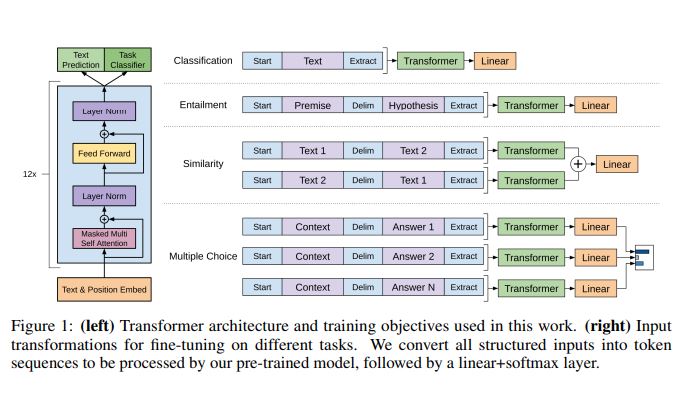
[출처] : https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
즉 어떤 특정 task에서는 모든 문장 마다 start ,end 토큰을 삽입해 주는 format을 가진 다는 것인데 하지만 이는 의무적인 것은 아닙니다. text 생성을 하는 것이 아니라면 굳이, start symbol을 삽입 할 필요가 없기 때문입니다.
실습 코드
gpt-2의 아키텍쳐를 실습해 볼 수 있습니다. colab에서 실행해 보시면 되겠습니다.
https://colab.research.google.com/drive/146o1LBpb4s98Ei1jE7ggCw97EnZ1ICxn?usp=sharing
참고 자료
