🔖논문링크 : arxiv.org
Abstract
Recommender systems(RS, 추천시스템)
사용자 행동 데이터(user behaviors)에서 사용자 맞춤형 선호도(users’ personalized preferences)를 포착하는 것이 목표
RS의 문제들
Dynamic Preference(동적 선호도)
사용자의 관심사와 선호는 시간에 따라 변하는데(장기적, 단기적 선호) 변화가 잦을수록 추천 결과가 불안정해지고 신뢰도가 떨어질 수 있다.
특히, 실시간으로 사용자의 변화를 감지하고 이를 모델에 반영하는 건 정말 어렵다. 과거 데이터를 활용하는 것이 어려운 경우도 있다.
Information Cocoon(정보의 코쿤)
사용자가 자신이 원하는 정보에만 노출되는 환경인데, 사용자의 능동적인 선택 으로 인해 발생한다. 원하는 정보만 선택해서 받아들이는 것이다.
- 다양성 부족: 사용자에게 다양한 관점을 접할 기회가 줄어든다.
- 인지적 편향 강화: 사용자의 편향된 관점이 더욱 고착된다.
- 정보의 질 저하: 추천 결과가 사용자에게 유익하지 않을 수 있다.
Inherent Feedback Loop(내재적 피드백 루프)
추천 시스템의 동적인 특성으로 인해 발생하는데, 시스템이 유저에게 추천을 제공하고, 유저 반응을 수집하고 이를 바탕으로 알고리즘을 재훈련하는 순환적인 과정을 의미한다. 지속적인 user-system interaction을 통해 형성되는 순환적 관계이다.
- 추천 품질 저하 : 초기의 편향으로 인해 추천의 다양성이 줄어들고 알고리즘 예측 정확도가 떨어진다.
- 사용자 행동의 동질화 : 사용자들이 비슷한 추천을 받게 되어 행동 패턴이 비슷해진다.
- 필터 버블 현상 : 사용자가 자신의 기존 선호와 유사한 콘텐츠만 접한다.
- 인기 편향 강화 : 인기가 더 많은 아이템이 더 많이 노출되어 인기도 격차가 커진다
- 모델 업데이트의 복잡성 : 변화하는 사용자 선호도 실시간 반영이 어렵다.
- 필터 버블 vs 정보의 코쿤 정보의 코쿤 :
능동적으로 자신이 좋아하는 것만 선택하는 것 필터 버블 : 알고리즘이 과거 행동과 선호도를 기반으로자동으로정보를 필터링하는 것!
📍전통적 추천 알고리즘의 한계
주로 Positive Historical Behaviors(긍정적 행동 데이터)에 초점을 맞추고, Negative Feedback(부정적 피드백)을 간과하는 경우가 많다.
negative sampling은 사용자 행동의 부정적인 측면을 포착하여 추천 품질을 향상시는 데 기여할 수 있다.
💡목적 : NS의 역할을 논의하고, challenges 분석
1 Introduction
Positive feedback과 마찬가지로 negative feedback도 사용자 선호를 반영할 수 있는 중요한 지표인데, 데이터가 희소한 경우 더욱 중요하다.
예를 들어, 사용자가 영화를 낮은 평점으로 평가한 행동은 단순히 부정적인 감정을 나타내는 것이 아니라, 사용자가 해당 영화를 이미 보았다는 점을 의미하며 사용자 선호를 드러내는 지표가 될 수 있다.
현재까지 다양한 negative sampling 알고리즘을 제안해왔지만, 각 알고리즘이 모든 추천 작업에서 동일하게 효과적인 것은 아니므로, 각 추천 시스템에 적합한 전략을 선택하는 것이 중요하다.
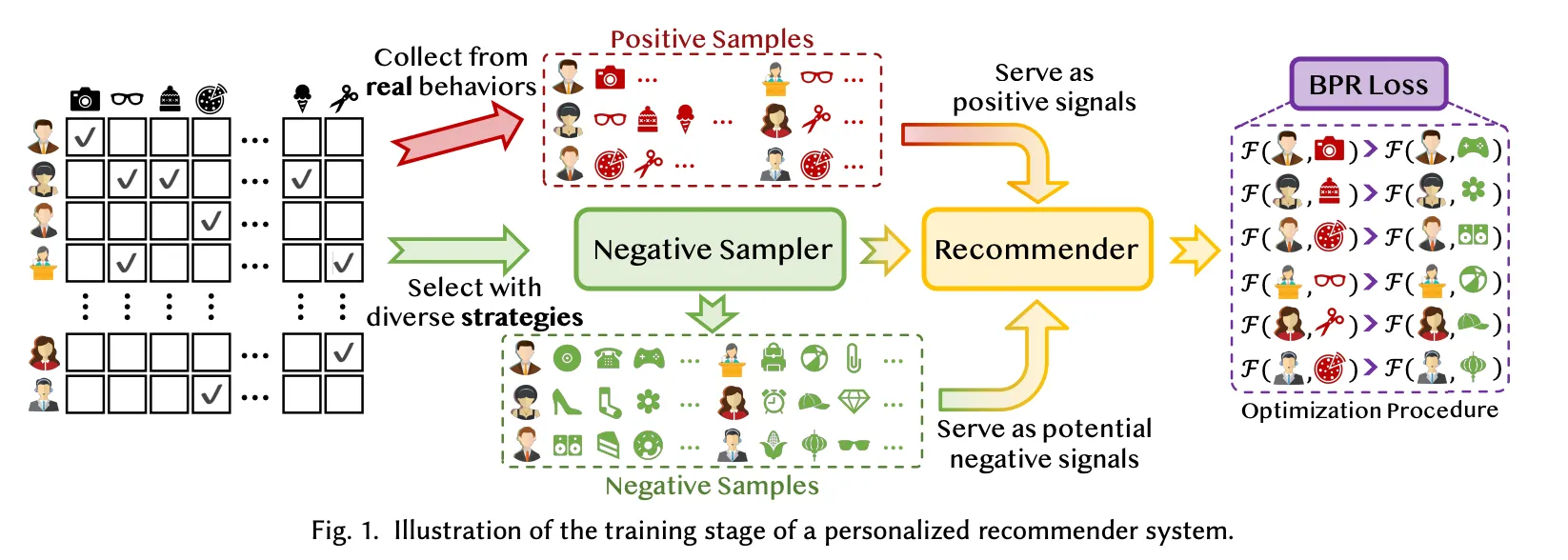
2 Necessity and Challenges of Negative Sampling
2.1 Role of Negative Sampling in Recommendation
Negative Sampling
모든 unobserved items에서 샘플링된 데이터를 학습에 사용하는 것
📌 negative sample의 유형
- Negative samples (NS) : 데이터셋 내 모든 상호작용하지 않은 아이템.(unobserved item)
- Hard Negative Samples (HNS) : 일반적인 NS보다 더 많은 정보를 담고 있는 샘플(사용자의 positive feedback과 관련이 높은 샘플)
- False Negative Samples (FNS) : NS로 잘못 식별되었지만 실제로는 사용자의 진짜 관심사를 나타내는 샘플. 즉, positive feedback을 negative feedback으로 잘못 분류한 샘플.
추천 시스템은 데이터 희소성(data sparsity), 동적인 사용자 관심(dynamics of user interests), 콜드 스타터(cold start) 등 여러 문제가 있다.
feedback loop와 information cocoons으로 인해 제한된 수의 아이템들과만 상호작용하게 되므로 데이터 희소성 문제가 발생한다.
또한, 새로운 사용자와 아이템이 유입되었을 경우 과거의 상호작용 데이터가 부족해 콜드 스타트 문제로 인해 기존의 데이터만으로는 정확한 추천을 제공하기 어렵다.
💡negative sampling은 희소한 상호작용 데이터로부터 동적인 사용자 선호를 모델링을 가능하게 한다. 거대한 unobserved items(비관찰 아이템) 중에서 샘플을 선택해 모델의 현재 상태를 최적화할 수 있다 !!
negative 사례로부터 명확한 신호를 얻고, 추천 품질을 크게 향상시킬 수 있다.
📍효과적인 negative sampling의 특성
- 높은 정보성 (Heightened Informativeness): 샘플이 모델에 충분히 새로운 정보를 제공해야 합니다.
- 증가된 판별력 (Increased Discriminative Capacity): 유사한 아이템을 더 잘 구분하거나 추천 정확도를 높이는 데 기여합니다.
- 향상된 정밀도 (Enhanced Precision): negative sampling에서 선택된 샘플이 실제 부정적인 피드백을 나타내는 아이템에 더 가깝기 때문에 효과적이다.
➡️ hard negative samples(HNS)는 이러한 특성을 충족한다.
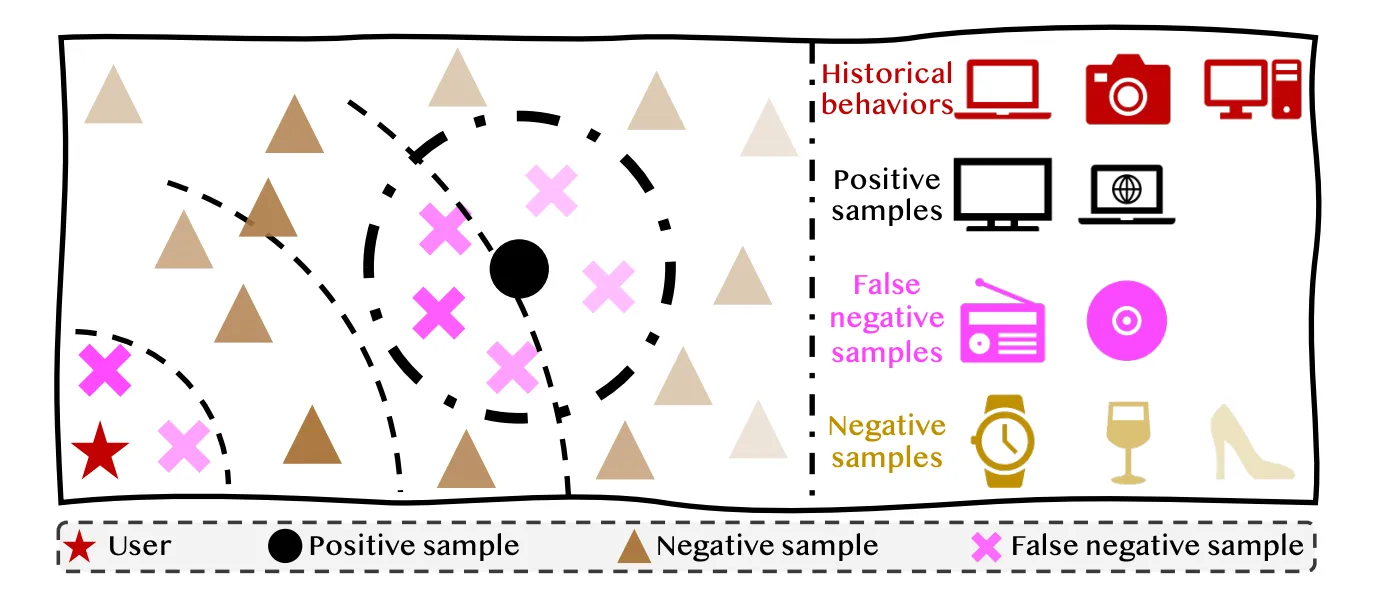
** False negative sample은 실제로 positive feedback을 negative feedback으로 잘못 분류한 샘플이다.
2.2 Challenges of Negative Sampling in Recommendation
negative sampling은 모든 unobserved item(상호작용하지 않은 아이템)에서 샘플을 선택해 학습에 활용해 모델이 사용자 선호도를 보다 정확하게 학습할 수 있도록 지원하는 기술인데, 3가지 주요 도전 과제가 있다.
-
False negative 문제 : 잘못된 부정 샘플이 모델 학습 방해
✔️추천 시스템에서의 지식을 바탕으로 negative feedback을 정확히 식별하려면?
-
정확도, 효율성 및 안정성 간의 균형 문제 : 성능이 좋으면 보통 계산 비용이 높으므로 정확도, 효율성, 안정성 간의 균형을 맞추는 것이 어렵다.
✔️모델 학습에서 정확도, 효율성, 안정성 간의 균형을 어떻게 맞춰야?
-
다양한 작업, 목표 및 데이터셋에 걸친 보편성 문제 : 다양한 추천 시나리오와 데이터셋을 처리하는 데 있어 단일 샘플링 전략은 한계를 가진다. (보편적인 NS전략은 존재하지 않는다.)
✔️다양한 목표와 데이터 가용성을 가진 multiple 추천 시나리오를 어떻게 처리?
📍전통적인 추천 시스템
상호작용하지 않은 아이템을 무작위로 negative sample로 선택
📍최근?
HNS를 더 harder하게 만드는 데 집중하고 있으나, 지나치게 hard sample은 학습 수렴 속도를 낮추고 local optima에 빠질 위험이 있다.
📍추천시스템 설게의 핵심 요소
- Accuracy(정확도) : 사용자 선호에 대한 모델 예측의 정밀도
- Efficiency(효율성) : 단위 시간당 추천 시스템이 처리할 수 있는 쿼리 수
- Stability(안정성) : 다양한 데이터셋에 걸친 추천 시스템의 일관된 성능
✔️정확도를 위해 더 많은 데이터와 복잡한 계산이 필요하면 효율성이 감소
✔️효율성을 위해 간단한 모델을 사용하면 정확도 감소
✔️안정성 유지를 유지하려면 다양한 데이터셋에서 일관된 성능을 보여야 하는데 효율성과 충돌할 가능성 존재
➡️ 균형을 맞추는 전략이 필요 : 성능 최저화와 계산 효율성
📍추천 알고리즘의 고려 대상
- 데이터셋
- 학습 목표(e.g., matching and ranking)
- 추천 시나리오(collaborative filtering, multi-model recommendation)
- 평가 방법
3 LITERATURE REVIEW OF NEGATIVE SAMPLING IN RECOMMENDATION
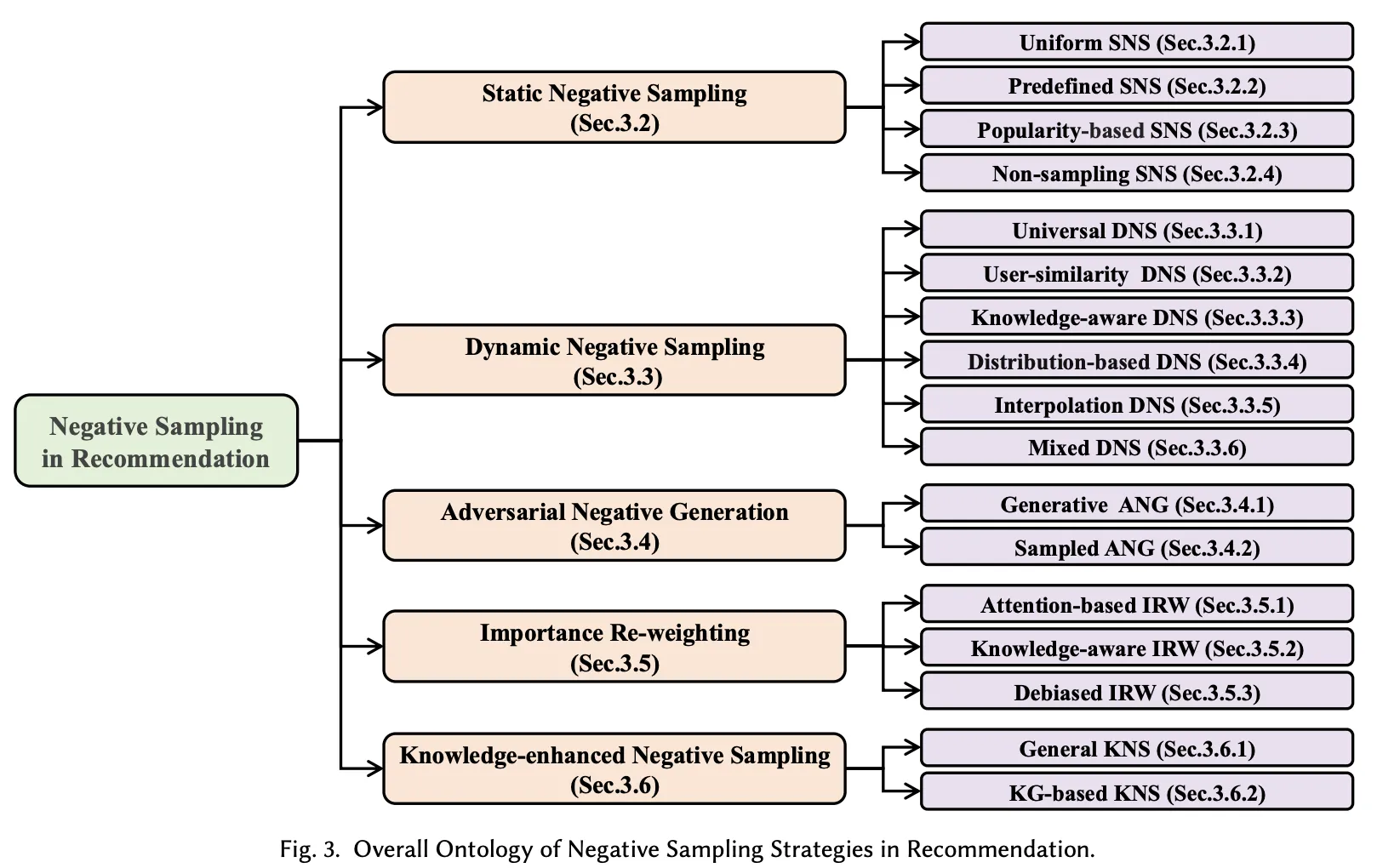
3.1 Static Negative Sampling(SNS, 정적 부정 샘플링)
고정된 규칙 또는 확률을 기반으로 negative samples를 선택
장점 : 계산 비용이 낮고 구현이 간단하고, 다양한 추천 시나리오와 애플리케이션에서 널리 사용
단점 : 데이터 특성에 따라 성능 차이 발생 가능
3.1.1 Uniform SNS
무작위로 NS 선택
장점 : 무작위로 선택하기 때문에 계산비용이 낮고 간단해 대규모 시스템에 적합하고, 다양성을 추가해 모델의 과적합을 완화시킨다.
단점 : 최적의 NS를 보장하지 않으므로 데이터 특성에 따라 성능 차이가 발생할 수 있다
3.1.2 Predefined SNS
데이터셋에서 미리 정의된 부정 샘플을 추천 모델의 학습 과정에 포함
사용자의 실제 행동(스킵, 클릭, 주문)을 부정 샘플로 정의하는데, 일부 연구에서는 명시적 평점(explicit ratings)(4, 5점은 긍정 샘플, 1, 2점 또는 1, 2, 3점은 부정 샘플로 지정)을 사용한다. 클릭 후 구매하지 않은 상품이나 평점이 낮은 영화와 같은 샘플은 명확히 부정 샘플로 간주될 수 있다.
➡️ 사용자의 행동 데이터를 활용해 실제로 선호하지 않는 아이템을 학습에 포함시킬 수 있다.
3.1.3 Popularity-based SNS
아이템의 전반적인 인기도를 기준으로 NS 선택
인기가 있으면 사용자의 잠재적 관심사를 더 잘 반영할 가능성이 있다는 가정에 기초
📌 특히 협업 필터링 기반 추천 시스템에 유용하며, 모델이 적절한 사용자 선호도를 학습하도록 돕는다.
다만 특정 아이템에 지나치게 집중하여 장기적 다양성을 해칠 수 있다.
3.1.4 Non-sampling SNS
모든 비관찰 데이터를 부정 샘플로 간주해 학습에 활용 - 샘플링을 하지 않는다.
데이터 분포의 편향성과 샘플링 과정에서 발생할 수 있는 오류를 완화할 수 있지만, 모든 데이터를 학습에 활용하기 때문에 시간 복잡도가 증가해 계산 비용이 증가할 수 있다.
데이터의 크기가 적절한 경우 사용하기 좋다.
- 비관찰 데이터가 negative sampling 아닌가? 비관찰 데이터를 어떻게 활용하느냐에 따라 관점이 달라질 수 있다. negative sampling과 non-samplingSNS의 접근법을 구분해야 한다.
-
Negative sampling : 관찰되지 않은 데이터(즉, 사용자가 명시적으로 상호작용하지 않은 아이템들)를 부정 샘플로 간주하여 학습에 사용한다.
영화를 시청하지 않은 경우 부정 샘플로 취급한다는 의미
부정 샘플의 일부만 선택하는 것이 일반적이다. (랜덤, 인기기반, 행동기반) 즉, 관찰되지 않은 데이터 중 일부를 선택해 학습에 활용하는 것!
-
Non-sampling SNS
관찰되지 않은 데이터 전체를 이용하여, 부정 샘플링 자체를 생략한다.
선택하게 되면 샘플 수나 데이터 분포에 따라 학습이 왜곡될 위험이 있다(중요 데이터를 놓치거나, 샘플링 비율이 모델 성능에 민감하게 작용할 수 있다. )
그래서 관찰되지 않은 전체 데이터를 모델에 통합해, 모든 비관찰 데이터 = 부정 샘플로 취급하며 데이터 분포를 온전히 반영한다.
EATNN, ENMF, EHCF 같은 모델들이 모든 비관찰 데이터를 학습 과정에 포함해 샘플링의 편향성 문제를 해결하려고 한다.
-
3.2 Dynamic Negative Sampling
positive sample과 더 관련이 있는 아이템을 NS로 선택해 적응성을 높이고 정보성 있는 샘플을 학습에 활용
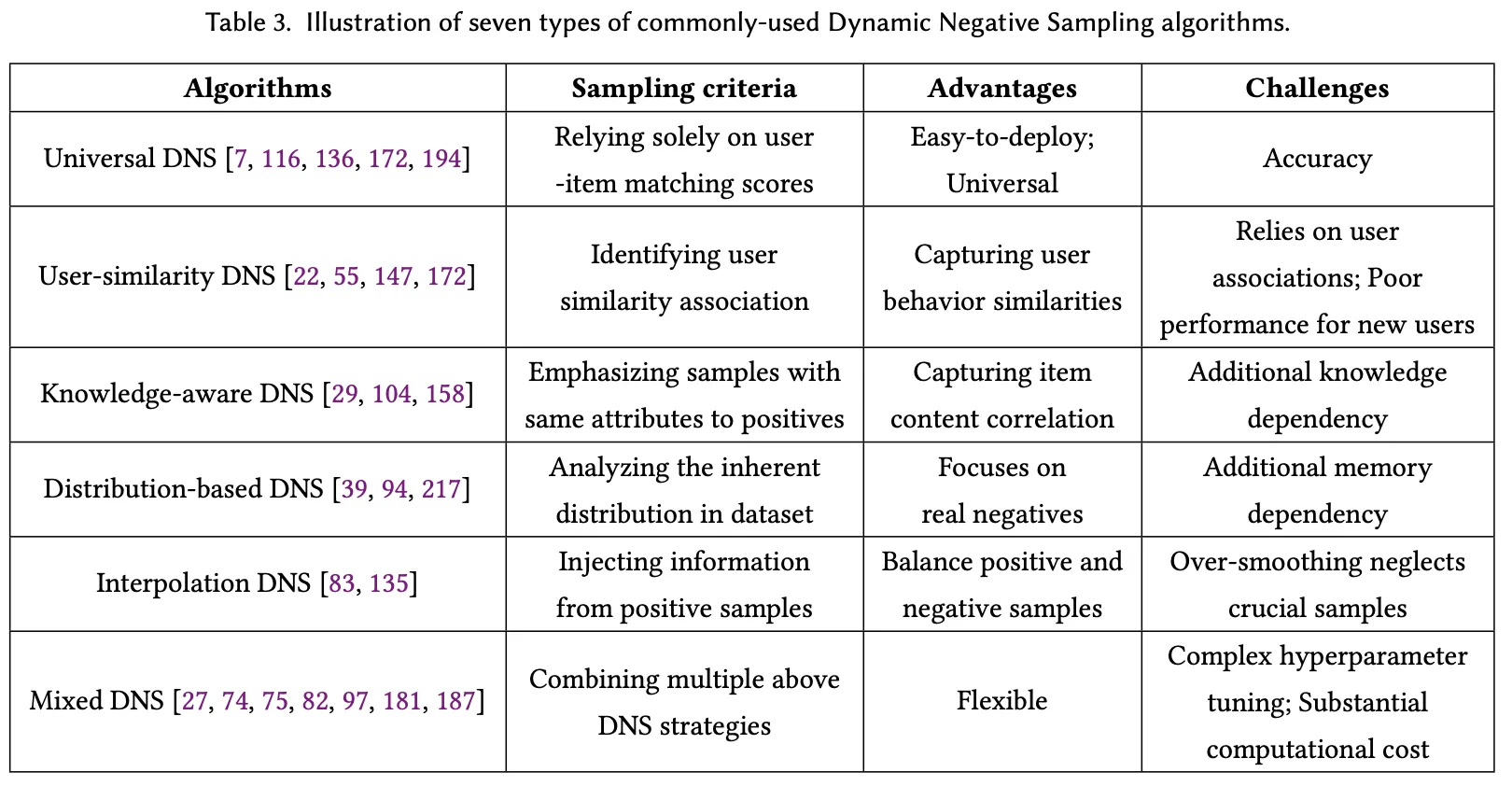
3.2.1 Universal DNS
무작위로 선택된 아이템 후보들 중에서 상위에 랭크된 항목을 NS로 선택해 더 정보성이 높은 NS를 선택
user-item관계를 동적으로 반영
📍Top-ranked Universal Negative selection
상위 랭크된 아이템을 동적으로 선택하여 학습 데이터로 활용
관측되지 않은 항목(negative sample)이 관측된 긍정 샘플(positive sample)보다 높은 랭크를 가져서는 안 된다는 가설을 기반으로 한다.
상위 랭크된 아이템을 oversampling하여 인기 아이템에 대한 편향(popularity bias)을 완화한다. NS 과정에서 상위 랭크 아이템의 선택 빈도를 높여서 인기 아이템이 과소 추천되거나 비인기 아이템이 과대 추천되는 문제를 줄인다. (지나치게 해서 인기 아이템에 대한 과대 평가가 되면 안된다)
✓ 기존의 SNS가 특정 후보군에서 무작위로 샘플을 선택하므로 사용자와 아이템 간의 실제 관계를 고려하지 않기 때문에 의미 없는 NS를 생성할 가능성이 있다. → 후에 정보량 부족 문제로 이어진다.
✓ universal DNS는 현재 모델이 이해하는 user-item 관계에 따라 NS를 선택한다.
- MCRec
- 순수 행렬 분해(pure matrix factorization) 방법을 사용하여 노드 임베딩을 사전 학습한다.
- 경로 상의 두 연속된 노드 간의 pairwise 유사도를 계산하고, 이를 평균화하여 평균 유사도가 가장 높은 top-k 경로(path instances)를 유지한다.
- 데이터 간의 연결 강도를 측정하여 가장 밀접한 경로만 학습에 사용한다.
- 효율성과 성능을 동시에 확보한다.
- CA-FME : positive triplet의 triple sides에서 harder NS를 높은 확률로 샘플링하여 긍정 샘플과 관련된 아이템 간의 관계를 더욱 정교하게 학습
- Positive triplet의 세 가지 측면에서 부정 샘플을 선택하며, 호환성 점수(compatibility score)에 따라 harder negative samples에 더 높은 샘플링 확률을 부여한다.
- Positive item과 유사한 부정 항목(hard negatives)을 중점적으로 학습하여, 모델이 이러한 항목을 구별하는 데 필요한 학습을 강화한다.
📍Dynamic Negative Selection with High-ranking Scope
상위 랭킹 범위를 유연하게 조정하여 부정 샘플링의 정확성과 다양성을 동시에 확보
점수가 높은 항목은 긍정 샘플일 가능성이 높아 false negative 문제를 발생시킬 가능성이 높지만, 상위 랭크된 항목이 무작위 항목보다 positive item에 더 유사하다는 점을 활용
➡️ 맞다/틀리다 를 넘어 미묘한 차이를 학습할 수 있도록 유도
- PinSage : 2000-5000위로 랭크된 아이템을 샘플링함으로써, False negative를 방지한다. 상위 1000위 내 아이템은 종종 False negative일 가능성이 높기 때문!
📍Collaborative Distillation of DNS
상위 랭크된 아이템을 더 자주 샘플링하여(우선적으로) 학습 효율성을 증대
- CD-SG : knowledge Distillation(KD)을 활용해 NS
- positive feedback의 희소성과 누락된 피드백의 모호성을 해결하기 위해 DNS를 KD로 변환
📍Adjacent Relation-based Selection in Graph Structures
그래프 내 노드 간의 인접성(adjacency)를 활용해 모델이 관계 정보를 더 잘 학습할 수 있도록 샘플링 전략을 최적화
그래프 구조에서 NS은 유사한 그래프 영역에서의 샘플링을 통해 topology를 보존하고, 샘플링 편향을 줄이는 데 초점
- MCNS : 변형된 Metropolis-Hastings 알고리즘을 사용해 그래프 구조에서 균형잡힌 샘플링이 가능
- 하나의 노드에 대한 마르코프 체인이 그 이웃 노드에서도 잘 작동할 가능성이 높다는 가정에 기반
- 이웃 노드가 유사한 속성을 가질 가능성이 높다는 자연적 특성을 활용하여 부정 샘플링에서도 이웃 노드를 포함시켜 학습을 수행한다.
- 마르코프 체인의 전이 행렬(노드 간 이동 확률)을 반복적으로 업데이트하여 부정 샘플링과 정보 집계를 동시에 최적화 → GNN 기반 추천 시스템의 성능을———- 개선
📍Dynamic Selection with Representation Learning
추천시스템 학습 중 생성된 Representation을 활용해 NS를 동적으로 선택
- . Improved efficiency of dynamic negative selection DNS는 pairwise ranking을 최적화하기 위해 암묵적 피드백 기반 (implicit feedback-based recommender system) 추천 시스템에서 널리 사용되었는데, 매 라운드마다 모든 항목의 점수를 다시 계산해야 하기 때문에 효율성이 제한적이다. DNS는 학습 과정에서 항목 점수를 반복적으로 계산해야 하므로, 대규모 데이터셋에서는 시간이 많이 소요될 수 있으므로, 샘플링 전략의 개선을 모색해야 한다. ELF는 list-wise(리스트 단위) ranking을 채택해 이 문제를 해결하며, 새로운 동적 부정 샘플링 전략을 제안해 샘플링 효율성을 개선하면서 유사한 수준의 정확도를 달성한다. GraphCS는 클러스터링 알고리즘을 사용해 후보군을 여러 클래스로 군집화한 뒤, 해당 클래스에서 부정 샘플을 무작위로 선택함으로써 부정 샘플링 과정의 효율성을 더욱 향상시킨다. 후보군을 클러스터로 나누는 방식은 계산량을 줄이고, 유사한 항목끼리 그룹화하여 더 의미 있는 샘플링을 가능하게 한다. GraphCS는 이렇게 그룹화된 클래스에서 무작위로 샘플을 선택함으로써 효율적인 샘플링을 실현한다.
3.2.2 User-similarity DNS
사용자 유사도를 식별하고, 사용자 행동의 유사성을 포착하지만, 사용자 관계에 의존하고 신규 사용자에게는 성능이 떨어지는 문제점이 있다.
3.2.3 Knowledge-aware DNS(지식 기반)
긍정 샘플과 유사한 속성을 가진 샘플을 강조하고, 아이템 콘텐츠 간의 상관관계를 포착하지만, 추가적인 지식 의존성이 필요하다.
3.2.4 Distribution-based DNS(분포 기반)
데이터셋의 내재된 분포를 분석하고, 실제 부정 샘플에 초점을 맞추지만, 추가적인 메모리 의존성이 필요하다
3.2.5 Interpolation DNS(보간)
긍정 샘플에서 정보를 주입하여 긍정적/부정적 샘플을 균형 있게 만드는 방식인데, 과도한 평활화 문제로(over-smoothing issues) 중요한 샘플을 간과할 수 있다.
3.2.6 Mixed DNS
여러 DNS 전략을 결합해 유연성을 제공하지만, 복잡한 하이퍼파라미터 튜닝과 상당한 계산 비용이 수반된다.
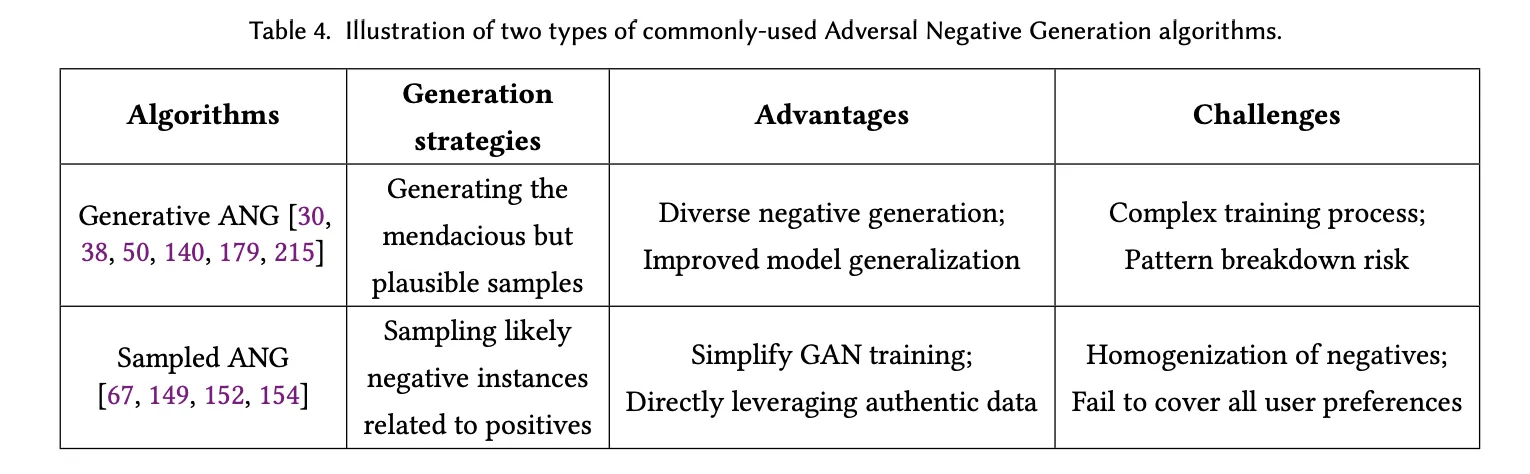
3.3 Adversarial Negative Generation (ANG)
NS를 생성해 모델의 학습 성능 향상
positive sample이 과하게 많고, real negative sample은 부족한 데이터 불균형 문제를 해결한다
📌 GAN(Generative Adversarial Network, 생성적 적대 신경망)
새로운 데이터를 생성하는 인공지능 모델이다. 여기서 적대 = 경쟁(adversarial) 관계
-
생성기 : 진짜 데이터처럼 보이는 가짜 데이터를 생성하는 역할, 진짜처럼 보이는 데이터를 만들어 판별기를 속이는 것이 목표이다.
-
판별기 : 입력 데이터가 진짜인지 가짜인지 판별하는 역할이고, 생성기가 만든 가짜 데이터를 진짜 데이터와 구분하는 것이 목표이다.
GAN은 미니맥스 게임(minimax game)으로 진행하고, 다음의 미니맥스 손실 함수를 최적화한다.
-
초기 상태 : 생성기는 랜덤한 데이터를 생성하고, 판별기는 데이터를 쉽게 가짜라고 구분한다.
-
반복 학습 : 판별기가 진짜와 가짜를 잘 구분하도록 학습하고, 생성기는 판별기를 속이도록 더 진짜 같은 데이터를 생성하도록 학습
-
균형 상태(Nash Equilibrium) : 생성기가 만들어낸 데이터가 진짜 데이터와 거의 구분되지 않으면 판별기의 출력은 항상 0.5에 가까워지는데 이 상태에서 최적의 학습 상태에 도달한다.
-
미니맥스 게임
목표 : 한쪽은 자신의 최악의 손해를 최소화하고, 다른 한쪽은 상대의 최선의 선택을 방해하여 최대화하려는 전략을 취한다.
생성기는 판별기가 구분하기 어려운 샘플을 생성하려고 하고(판별기의 성능을 최소화), 판별기는 생성기가 만든 가짜 샘플을 최대한 정확히 구분(생성기의 오류를 최대화)하려고 한다.
이 과정은 수학적으로 손실 함수(Loss function)을 최적화하는 형태로 나타난다. **
-
Nash Equilibrium(내쉬 균형)
Nash Equilibrium (내쉬 균형 상태)참여자들이 각자의 최적 전략을 선택하여 서로의 전략을 바꾸지 않는 상태를 말한다. 즉, 서로의 선택에 만족한 상태입니다. GAN을 통해 생성기와 판별기가 서로 학습하면서, 생성기가 만든 가짜 데이터를 판별기가 더 이상 구분할 수 없게 되는 상태가 내쉬 균형이다.
GAN은 생성기와 판별기가 계속 경쟁하는 방식으로 학습이 진행되고, 내쉬 균형에 도달하는 것이 이상적인 목표이지만, 현실적으로 완벽한 내쉬 균형 상태에 도달하는 것은 어렵다. 따라서 다양한 GAN 변형 기법이 사용된다.
3.3.1 Generative ANG
GAN을 활용해 NS 생성
Generator(생성기)는 그럴듯한 부정 샘플을 합성하고, discriminator(판별기)는 진짜 데이터와 생성된 샘플을 구분한다. 반복적인 adversarial training을 통해 생성기는 점점 더 교묘하지만 타당한 부정 샘플을 생성할 수 있게 된다.
장점: 다양한 부정 샘플 생성을 통해 모델 일반화 능력 향상을 돕고, 추천 시스템의 견고성 강화
단점: GAN 훈련이 복잡하기 때문에 과도한 계산 비용과 훈련 시간이 소요되고, 패턴 붕괴(pattern breakdown) 위험과 복잡한 학습 과정
3.3.2 Sampled ANG
데이터셋의 기저 분포(underlying distribution)을 최대한 정확히 반영하려고 시도하고, positive sample과 관련된 가장 가능성 있는 부정 샘플을 선택한다.
샘플을 생성하지 않고 기존 데이터셋에 있는 항목들(corpus) 중에서 직접적으로 샘플을 선택한다.
NS : 사용자에게 추천되지 않았거나 상호작용하지 않은 항목
📍IRGAN
미니맥스 게임을 활용해 생성기로 후보 풀에서 전략적으로 부정 샘플을 선택해 긍정 샘플과 혼합하고, 이를 통해 판별기를 혼란스럽게 만든다.
NS를 직접 생성하지 않고 생성기를 통해 후보 항목과 쿼리 간의 추정된 상관관계를 기반으로 NS를 선택한다.
📍GraphGAN
생성기는 그래프 구조 내의 기저 연결성 분포를 근사화하고(노드 간 연결성을 학습), 실제 데이터의 즉각적인 이웃(immediate neighbors)와 유사한 관련 정점을 샘플링(실제 데이터와 비슷한 노드를 샘플링)하여 판별기를 속이려고 시도하고, 판별기는 샘플링된 정점이 실제 데이터에서 나온 것인지 아니면 생성기에 의해 선택된 것인지를 판별하려 한다.
연결된 이웃 노드와 유사한 항목을 NS로 선택하므로 그래프 기반 추천 시스템에서의 부정 NS성능을 강화시킨다.
📍NMRN-GAN
GAN에서 생성기와 판별기 간의 내쉬 균형 상태(Nash Equilibrium)에 도달했을 때, 데이터셋에서 적절한 아이템을 전략적으로 샘플링한다
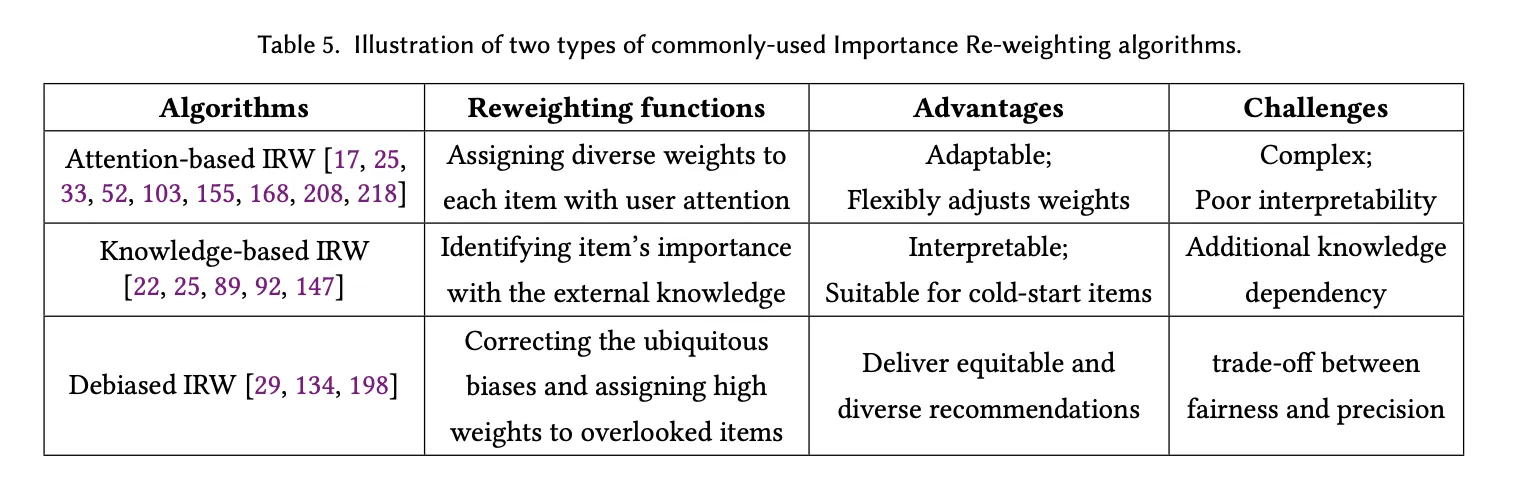
3.4 Importance Re-weighting(IRW)
샘플의 가중치를 조정하여 특정 부정 샘플을 우선시하는 정교한 통계 기법
긴 꼬리 분포(long-tailed distributions), 샘플 중요도가 다른 데이터셋이나 불균형한 데이터셋 문제를 해결하는 데 유용하다.
✓ 현실에서는 positive feedback은 소수고, 대부분은 부정적이거나 관찰되지 않은 상태인데, IRW 사용 시 NS의 가중치를 재조정해서 추천 시스템이 더 균형 잡힌 학습을 할 수 있도록 돕는다. 어떤 항목이 더 중요한지를 모델이 알 수 있도록 가중치를 부여하는 것이 핵심!
3.4.1 Attention-based IRW
사용자의 관심도에 따라 가중치 할당하므로, 관심도를 직접적으로 반영할 수 있다.
- challenges : complexity and poor interpretability
- 예) 사용자가 자주 클릭하는 항목이나 시간을 많이 소비하는 항목에 더 높은 가중치를 부여한다.
3.4.2 Knowledge-based IRW
외부의 구조화된 지식(카테고리 정보, 제품의 특징)을 사용해 항목의 중요도를 식별한다.
외부 지식을 가져오기 때문에 콜드 스타트 문제(신규 사용자 등장으로 인해 추천이 어려운 경우)에 유용하다.
- challenges : 추가적인 지식 의존성(knowledge dependence) 필요
- 예) 새로운 영화가 등장했을 때 그 영화의 장르나 감독 정보 등을 통해 가중치를 할당할 수 있다.
3.4.3 Debiased IRW
시스템이 특정 항목이나 사용자 그룹에 대해 지나치게 집중하지 않도록 가중치를 부여한다. 일반적인 편향을 수정하는 것을 목표로 한다.
간과된 항목(overlook items)에 더 높은 가중치를 부여한다.
- challenges ; trade-off between fairness and precision → 공정성을 너무 높이려다 보면 추천의 정확도가 떨어질 수 있다
- 예) 인기 있는 아이템을 지나치게 추천하는 편향을 수정하여 덜 알려진 아이템을 추천할 수 있도록 유도
3.5 Knowledge-enhanced Negative Sampling
단순히 무작위 random negative sample을 선택하는 대신, 사용자와 아이템 간의 더 높은 연관성과 정보성을 가진 negative sample을 선택한다.
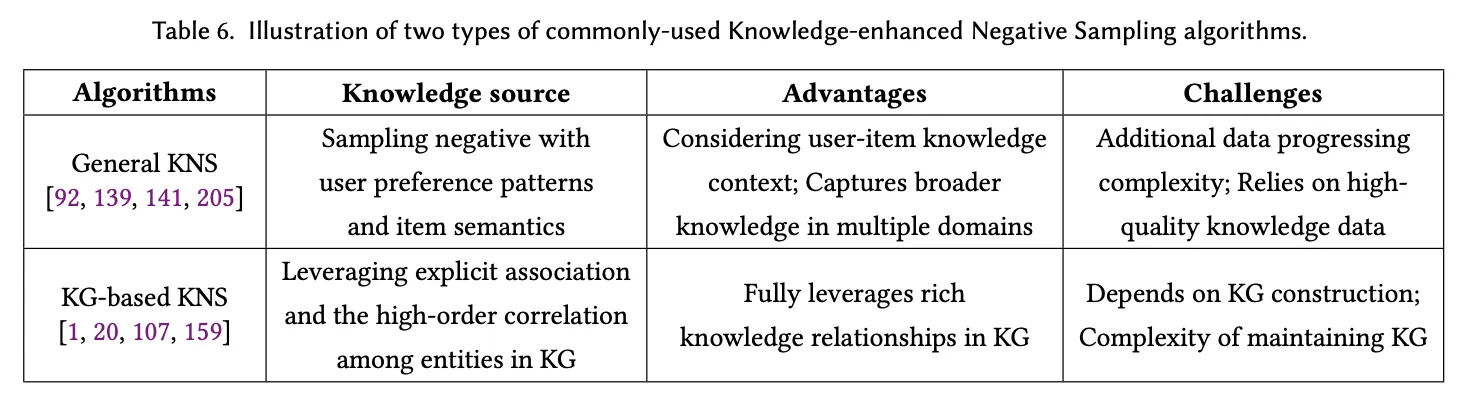
📍장점
- 추천 정확도와 다양성 향상(negative sample의 정보가 증가하기 때문에) - 데이터 희소성 문제 해결
- 콜드 스타트 문제를 효과적으로 해결 가능 : 새로운 사용자나 아이템에 대한 보조 지식을 사용함으로써 초기 추천 성능을 보완한다.
- 사용자 선호도와 아이템 특징을 세밀하게 포착 가능
📍challenge
- 외부 지식(feature data, knowledge graph)이 필요한데 항상 사용 가능한 것은 아니다
- 경우에 따라 계산 복잡도가 증가할 수 있다 : 그래프 기반이나 의미 기반 접근법은 추가적인 연산이 필요하다
KNS는 보조 지식을 활용해 더 정보성이 높은 negative sample을 서택하며, 데이터 희소성 문제와 콜드 스타트 같은 도전 과제를 해결하는 것을 목표로 한다.
- 보조 지식을 활용해 더 정보성이 높고 관련성 있는 negative sample을 선택
- 데이터 희소성과 콜드 스타트 같은 도전 과제를 해결하기 위해 설계
- KNS는 사용자의 세부적인 선호도와 아이템의 특징을 잘 포착할 수 있다.
negative sampling 과정에서 보조 지식을 활용하여 데이터의 한계를 극복하려는 접근법이다.
negative sample은 추천 시스템에서 사용자의 행동 데이터(구매 기록, 클릭 기록 등)에 따라 관찰되지 않은(negative) 데이터를 의미한다.
대부분의 추천 시스템 데이터는 희소성 문제를 겪고, 이는 사용자가 실제로 상호작용한 데이터가 전체 데이터에 비해 매우 적다는 것을 의미한다
KNS의 목적은 단순히 무작위 random negative sample을 선택하는 대신, 사용자와 아이템 간의 더 높은 연관성과 정보성을 가진 negative sample을 선택하는 것이다.
3.5.1 Attribute-based KNS(속성 기반)
아이템의 속성(feature)을 활용해 negative sample을 선택하는데, 세부적인 사용자 선호도를 포착하는 데 도움이 된다.
item의 feature 정보를 negative sampling과정에 통합한다. 아이템의 카테고리, 가격, 브랜드와 같은 속성을 활용하여 사용자와 연관성이 높은 음성 샘플을 선택한다.
예시 ) NAIS는 아이템 속성과 과거 상호작용 데이터를 기반으로 부정 샘플을 선택한다.
3.5.2 Graph-based KNS(그래프 기반)
그래프 구조를 활용하여 사용자와 아이템 간의 관계를 모델링한다. 그래프 기반 접근법은 단순한 1차원 관계를 넘어 higher-order connectivity(고차 연결성) 정보를 분석할 수 있다
예를 들어, 두 명의 사용자가 동일한 제품을 구매했으면, 이들을 간접적으로 연결된 관계로 분석
예시) KGAT, CKAN, KGIN은 지식 그래프를 활용하여 음성 샘플링을 수행한다.
3.5.3 Semantic-based KNS(의미 기반)
의미론적 정보를 활용하여 음성 샘플을 선택한다. 예를 들어, 책 추천 시스템에서 두 권의 책이 모두 소설이라는 카테고리에 속하지만, 하나는 SF소설이고 다른 하나는 로맨스 소설이라면, 이러한 차이를 음성 샘플링에 반영한다.
아이템 간 미묘한 차이를 포착하는 데 중점을 둔다.
KSNS 는 지식 임베딩 기술을 용해 아이템 간의 의미적 관계를 계산하고, 의미적 유사성이 높은 negative sample에 더 높은 중요도를 부여한다.
4 NEGATIVE SAMPLING IN MULTIPLE PRACTICAL RECOMMENDATION SCENARIOS
모든 추천 시스템에 적합한 범용적인 음성 샘플링 방법도 있지만, 추천 시나리오마다 목적, 데이터 가용성, 사용 방식이 다르기 때문에 모든 추천 시나리오를 포괄할 수 있는 negative sampling 알고리즘은 부재한 상황이다.
이 섹션에서는 다양한 추천 시나리오의 특수성을 심층적으로 탐구하며, 동일한 추천 시나리오 내에서도 음성 샘플링 방법론에서 나타나는 미묘한 차이를 구체적으로 설명한다.
궁극적으로, 각 특정 시나리오에 맞춘 맞춤형 negative sampling 기술 패러다임에 대한 종합적인 논의와 전망으로 결론을 맺는다.
5가지 추천 시나리오들 ..
negative sampling이 중요한 이유
- 데이터 희소성 극복
- 콜드 스타트 문제 해결
- 학습 효율성 향상 : 무작위로 음성 샘플을 선택하는 것보다 더 정보성이 높은 음성 샘플을 선택하면 모델 학습 속도가 빨라지고 성능이 향상된다.
4.1 Introduction of Negative Feedback in Practical Recommendation
실제 추천 시스템에서 부정적 피드백(negative feedback)의 도입에 대해 논의한다.
부정적 피드백의 주요 3가지 유형(명시적, 암시적, 가상 부정적 피드백)과 이를 추천 알고리즘에 통합하는 다양한 전략을 설명한다.
부정적 피드백 활용 시 발생할 수 있는 문제(희소성, 노이즈, 편향)과 이를 극복하기 위한 방법논 논의
사용자의 negative feedback을 파악하고 추천 정확도를 개선하는 게 매우 중요한데, explicit negative feedback은 실제 시나리오에서 흔하지 않다는 점을 지적한다.
이를 위해 추천 시스템에서 사용할 수 있는 부정적 피드백의 3가지 source
- 명시적 : 싫어요, 낮은 평점, 부정적 리뷰 등 유용하지만 데이터 양이 제한적이다.
- 암시적 : 사용자 행동(콘텐츠 건너뛰기, 짧은 시청 시간, 장바구니 포기 등) 에서 추론. 풍부하지만 노이즈 많고 정확한 해석이 어렵다
- (pseudo-negative feedback)가상 부정적 피드백 : 사용자가 상호작용하지 않은 아이템을 잠재적 부정적 샘플로 간주한다. false negative의 가능성이 있다.
이후, 부정적 피드백을 추천 알고리즘에 통합하기 위해 다양한 전략
- pairwise 학습 : 긍정 부정 샘플을 비교해 사용자의 선호를 학습한다.(BPR) - 아이템 a, b 중 사용자가 더 선호할 가능성이 높은 것들을 예측. 사용자-아이템 행렬의 희소성 문제를 해결하는 데 유용하다
- pointwise learning : 추천 문제를 분류 또는 회귀 문제로 처리하며, 부정적 피드백을 학습 목표에 직접 통합 - 각 아이템에 대해 점수르 매겨 긍정/부정 여부 학습 - 분류 문제(긍/부정) 회귀 문제(선호도 점수 예측)으로 접근 가능
- Listwise learning : 전체 순위 리스트를 최적화하며, 긍정적 및 부정적 피드백을 동시에 고려한다. - 추천 리스트에서 상위 n개 아이템에 대해 긍정적 피드백의 비율을 최대화한다
부정적 피드백의 challenges
- 희소성(sparsity) ; 명시적 부정적 피드백이 제한적이라 사용자 선호도를 일반화하기 어렵다
- 노이즈 : 암시적 부저적 피드백은 모호하며, 반드시 사용자의 진정한 비선호를 반영하지 않을 수 있다
- 편향(bias) : 사용자는 강한 의견이 있는 아이템에만 피드백을 제공하는 경향이 있어서 피드백 분포가 왜곡될 가능성이 있다. (특정 항목에만 집중되어 추천의 공정성 아웃)
4.2 Collaborative-guided Recommendation
target user의 potential preference를 예측하기 위해 모든 협업 행동을 수집하고 분석하는 것을 목표로 한다.
일반적으로 CR은 사용자와 아이템을 잠재된 임베딩 공간(latent embedding space)로 투영하여 사용자의 선호를 반영하는 데 초첨을 맞춘다. 데이터 간의 관계를 추출해 관측되지 않은 아이템에 대한 사용자의 선호도를 예측하는 것
- 잠재 임베딩 공간 사용자의 행동 패턴과 아이템의 특성을 수치 벡터 형태로 잠재 공간에 투영하여 관계를 표현 그정 사용자가 SF영화를 선호하는 패턴이 잠재 공간에 나타나면, 유사한 특성을 가진 아이템(영화)를 추천할 수 있다. 이는 행렬 분해나 딥러닝 기반 임베딩 방법으로 구현된다.
정의와 목적
협업 기반 추천(collaborative-guided recommendation)은 협업 신호(collaborative signals)을 활용하여 부정 샘플(negative samples)을 선택하는 방법이다.
이 접근 방식은 추천 과정에서 사용자와 아이템 간의 복잡한 관계를 포착하는 것을 목표로 한다.
[협업 신호]
- 사용자 간 관계 : 비슷한 취향의 사용자 그룹
- 아이템 간 관계 : 비슷한 특성을 가진 아이템
- 사용자 - 아이템 상호작용 : 특정 사용자가 특정 아이템에 대해 좋아요를 누르거나 구매한 기록
부정적 샘플을 더 정교하게 선택함으로써 데이터 희소성 문제와 콜드 스타트 문제를 해결하는 데 도움을 줄 수 있다.
CR에서는 user-item interactions로 제한된다.
사용자가 선호한다고 명시적으로 나타난 데이터(높은 평점, 구매기록 등)만을 활용하는 경우가 많은데, 부정적 인스턴스(클릭하지 않거나, 구매하지 않은 아이템)을 고려하지 않으면, 사용자의 미묘한 선호 패턴을 반영하는 데 한계가 있다. 그래서 negative sample도 학습 과정에 포함하여 모델의 정밀도를 높이려고 한다. CF 작업에서 데이터 가용성의 제약으로 안해, 기존의 부정적 샘플링은 SNS(sampled negative sampling, 관측되지 않은 데이터를 부정적 데이터로 간주하고, 랜덤 샘플링을 통해 학습 데이터로 활용)을 사용해 부정적 샘플 선택 과정을 이용한다. unobserved data corpus에서 동일한 확률로 아이템을 무작위 샘플링하는 방법이 CF에서 널리 사용된다.
다수의 CF 접근법은 CF모델의 학습 중 정보성이 높고(Contextually suitable) 현재 맥락에 적합한 부정적 샘플을 동적으로 선택하는 데 초점을 맞추고 있다. (실시간으로 부정적 샘플 선택)
DNS는 가장 높은 점수를 가진 아이템을 가장 정보성이 높은 샘플로 간주하고 이를 부정적 샘플로 선택하려고 시도한다.
현재 CF 작업에서 부정 샘플을 선택하는 방법은 관찰되지 않은 항목에서 무작위로 샘플링을 하여 부정 샘플을 선택하는 방식인데, 주로 동적 확률로 샘플을 뽑는 방식을 따른다.랜덤이므로 단순하지만, 항상 최적의 부정 샘플을 선택한다고 보장할 수는 없다. 그러므로, DNS selection을 통해 부정 샘플을 고를 때 정보가 풍부하고 현재 학습 중인 모델에 적합한 부정적샘플을 선택해야 한다.
- SRNS(statistical-based Random negative sampling) : 긍정 샘플과 부정 샘플간의 분포를 활용하여 더 정보성이 높은 부정 샘플을 동적으로 선택
- GDNS(Graph-based Dynamic Negative Sampling) : 그래프 기반 추천 시스템에서 아이템 간 관계를 바탕으로 부정 샘플을 선택한다.
- DENS(Dynamic Ensemble Negative Sampling) : 부정 샘플을 다수의 모델을 활용해 동적으로 선택하는 방법
CL-based CF 알고리즘
EGLN(Emebedding Graph Learning Network)은 협업 필터링을 위한 구조적 증강을 통해 local-global을 최적화하는 방법이다. 상호작용 그래프(interaction graph)에서 구조를 증강시켜, 더 나은 협업 표현 학습을 목표로 한다. 그래서 협업 관계를 global수준에서 유지하면서도, 로컬(Local)환경에 맞게 최적화할 수 있다.
4.3 Sequential Recommendation(SR)
사용자의 과거 행동 데이터를 기반으로 사용자의 동적 선호도(dynamic preference patterns)를 효과적으로 포착하기 위한 접근법이다.
- 목적 : 사용자의 행동 스퀀스(behavioral sequence)에 존재하는 시간적 상관관계를 모델링하여, 사용자가 다음에 관심을 가질 가능성이 높은 아이템을 예측하는 것이다.
- SR은 시간에 따라 변화하는 사용자의 선호도를 다루기 때문에, 기존의 정적인 추천 시스템보다 사용자 행동의 동적 특성을 더 잘 반영한다.
📍Negative sampling과 SR의 관계
Hard negative sampling : 긍정 샘플과 일정 수준의 유사성을 가진 부정 샘플을 선택함으로써, 추천 모델이 사용자의 미묘한 동적 선호도를 더 잘 구분할 수 있도록 한다.
현재 대부분의 SR연구는 관찰되지 않은 아이템을 무작위로 부정 샘플로 선택한다.
- DEEMS : hard negative sampling을 사용하지만, 사용자와 행동 간의 시간적 관계(temporal relationship)을 고려하지 않는다. 모든 상호작용을 동일한 중요도로 처리하는 단접이 있다
- GeoSAN : DEEMS와 유사하게 시간적 관계를 무시하고, 행동 간의 연관성을 동일하게 평가한다.
- ELECRec : GAN의 discriminator를 활용하여 타겟 샘플을 구분하려고 하지만, 사용자 행동 시퀀스에 내재된 순차적 지식(sequential knowledge)를 간과한다.
📍Contrastive LEarning기반 부정 샘플링
CL(contrastive learning)을 활용한 SR연구에서는 다양한 sequence agumentation 방법을 사용하여 부정 샘플을 생성하는데, 사용자의 temporal preferences를 더 잘 모델링하는 데 도움을 준다.
- 주요 증강 방법
- crop : 시퀀스에서 특정 부분을 잘라냄
- mask : 특정 아이템을 가림
- recorder : 시퀀스의 순서를 재배열
- substitute : 아이템을 대체
- insert : 새로운 아이템을 추가
📍SR의 과제와 연구 방향
아직 해결되지 않은 challenges
- 시간적 관계(temporal relationships) 고려 부족
- 사용자의 행동 시퀀스에서 시간적 관계를 간과하고, 모든 상호작용을 동일하게 처리한다.
- 시간적 맥락을 반영하지 않으면 사용자의 동적 선호도 학습이 제한된다.
- GAN ghkfdyddml gksrP
- 부정 샘플 구분에 유용하지만, 순차적 정보를 반영하지 못하는 단점이 있다.
즉, 시간적 특성을 반영한 샘플링이 필요하다.
4.4 Multi-model Recommendation
다양한 모달리티 기반 정보(micro-videos, 이미지, 오디오, 텍스트 등)을 활용해 추천 시스템을 개선하는데, 실제 환경에서의 추천 응용에 필수적이다.
📍MMR에서 negative sampling의 필요성
지도 학습 방식을 사용하므로, 추천 모델을 훈련한다면 다량의 긍정 샘플(관찰된 상호작용)과 부정 샘플(관찰되지 않은 상호작용)이 필요하다
실제 선호도에 더 잘 맞는 정보가 풍부한 부정 샘플을 선택하는 방법을 탐구하는데, 역시나 대부분의 연구에서는 SNS(single negative sampling)을 적용해 모든 아이템을 동일한 확률로 선택(Uniform SNS)하고, 미리 정의된 기준에 따라 샘플링(predefined SNS)한다. 단순하고 널리 사용되지만, 다중 모달 정보를 충분히 활용하지 못한다.
📍샘플링 전략
긍정 샘플과의 의미적 관계를 고려해 더 정교한 부정 샘플을 선택한다.(HNS)
- FairNeg
- 그룹 수준의 불공정성(group-level unfairness)를 완화하고, 의미적 그룹(sematic group)의 샘플링 확률을 균형 있게 맞춰 결과적으로 편향 없는 추천을 달성한다.
- RPRM
- 리뷰 속성(review properties)의 일관성을 모델링
- 긍정 샘플과 유사한 리뷰 속성을 가진 부정 샘플을 선택해서 모달리티 간 리뷰 특성을 반영
- POWERec
- 동일한 아이템에서 학습된 다중 모달 표현을 활용해 모달리티별 사용자 관심사를 모두 학습 가능하게 한다.
📍MMR에서 Contrastive Learning의 활용
CL은 MMR에서 모달리티 간 숨겨진 관계를 탐색하는 데 유용하다. 다중 모달 데이터를 활용해 CL pair를 생성하고, 이를 통해 더 나은 부정 샘플링을 가능하게 한다.
예) 아이템의 모달리티 간 상관관계를 분석하여 샘플링 수행
현재는 아직 다중 모달 정보를 충분히 활용하지 못하므로 정교한 샘플링 전략이 필요하다.
4.5 Multi-behavior Recommendation(MBR)
실제 추천 시스템에서 사용자와 아이템 간 다양한 상호작용 유형(스킵, 클릭, 구매 등)을 활용하여 데이터 희소성(data sparsity)또는 콜드스타트 문제를 완화하려는 접근 방식이다.
📍핵심 아이디어
여러 유형 간의 의존성(cross-type behavior dependency)을 모델링해서 보완적 정보를 활용해 사용자 관심사의 표현을 더 정밀하게 반영한다.
예시) 사용자가 아이템을 클릭했지만 구매하지 않은 경우, 클릭과 스킵 같은 다른 행동 데이터를 통해 사용자의 실제 선호도를 추론할 수 있다.
다중 행동 데이터를 활용하면 사용자 관심사에 대한 보조적 지식과 정확한 선호도 표현을 제공한다.
예시) 단순히 구매 데이터를 분석하는 것보다 클릭, 조회 등 다양한 행동 패턴을 함께 고려하면 더 풍부한 사용자 의도를 이해할 수 있다.
📍현재 접근 방식
주로 사전 정의된 행동 간 상관관계(predefined correlations)를 활용하여 다중 행동 데이터를 분석한다.
그러나 대부분 부정 샘플링을 통해 개별 행동 유형별로 다양한 부정 샘플을 선택하는 데는 소홀하다.
이는 실제 세계의 복잡한 추천 시나리오에서 다중 행동 간의 복잡한 의존성을 완전히 포착하는 능력을 제한한다.
📍대표적인 모델
-
ZEUS
교차 행동 간의 상호작용(inter-connection)을 모델링하기 위해 부정적인 CL쌍을 독립적으로 생성한다.
behavior-aware hyper meta-graph를 생성해 다양한 행동 패턴과 행동 간 의존성을 동시에 모델링해 행동 유형 간의 복잡한 관계를 학습해 사용자의 관심사를 더 정확히 표현한다.
-
HMG-CR
다중 행동 데이터를 연결해 negative CL pair를 구성해 행동 간 의존성과 다중 상호작용 패턴을 모델링해 사용자 관심사 표현을 강화한다.
📍장점
-
다양한 행동 데이터를 활용해 풍부한 정보를 제공한다.
-
사용자 관심사 표현 강화 : 사용자의 underlying interests를 더 세밀하게 반영
예) 클릭 데이터는 탐색적 관심을 나타내고, 구매 데이터는 확정적 선호를 나타낼 수 있다
-
콜드스타트 문제 해결
행동 데이터가 적은 신규 사용자나 아이템에 대해, 다양한 행동 패턴 데이터를 활용해 문제를 완화한다.
-
부정 샘플링의 활용 가능성
행동 간의 관계를 고려한 부정 샘플링 전략은 다중 행동 의존성을 더 잘 학습하도록 돕는 중요한 방향이다.
📍미래 연구 방향
행동 유형별 맞춤형 부정 샘플링 전략을 개발하고, 단순히 행동 간 상관관계를 사용하는 것을 넘어, 행동 간 복잡한 상호작용 패턴을 학습하는 모델을 설계하고, 행동 인식 그래프를 더 발전시켜 실제 시나리오의 다양한 상호작용을 포착해야 한다.
4.6 Cross-domain Recommendation(CDR)
데이터 희소성(data sparsity) 및 콜드스타터 문제를 완화하기 위해 다른 도메인에서 수집된 보조 사용자 행동 데이터를 활용하는 방법이다.
4.7 CL-enhanced Recommendation
Constractive Learning(CL)은 CV, NLP, GRL(그래프 표현 학습)에서 성공적으로 활용된 학습 패러다임인데 RS에도 적용중이다.
CL은 positive pairs의 일치성을 최대화하고, negative pairs의 일치성을 최소화하여 원본 데이터와 증강 데이터 간의 지식 전이를 도모한다.
- 양성 쌍 : 특정 아이템 표현(임베딩)과 그에 대한 증강 표현
- 음성 쌍 : 특정 아이템의 표현과 다른 아이템의 증강 표현
CL은 주로 음성 증강 전략(NA)에 크게 의존하는데, 추천 모델이 더 풍부한 의미론적 상관관계(semantic correlation)을 학습하도록 돕는다.
NA 전략을 통해 양성 데이터와의 대조를 통해 학습을 최적화하고, 부정적인 데이터 간격을 명확히 정의하여 더 나은 표현 학습을 수행한다.
📍In-Batch Negative Sampling
가장 널리 사용되는 CL 증강 전략인데 미니배치에 포함된 나머지 아이템의 증강 표현을 음성 샘플로 취급해 전체 데이터셋에서 샘플링하지 않으므로 계산 복잡도 없이 학습 속도를 가속화할 수 있다.
📍CL기반 추천 시스템의 음성 증강 전략 : Graph-based negative augmentation(그래프 기반 음성 증강)
그래프 구조를 기반으로 음성 쌍을 생성한다.
- 노드 엣지 드롭아웃
- 노드 엣지 구별
- 랜덤 워크
- 구조 변형
- SGL , EGLN, RGCL이 있다.
노드와 엣지 간의 상관성을 고려하여 다양한 그래프 기반 NA 전략을 제안한다.
- 추가
4.1. Pre-defined Negative Augmentation (사전 정의된 음성 증강)
-
개념:
도메인별 전문 지식이나 특정 태스크 기준을 기반으로 음성 샘플 풀을 증강.
-
예시:
- CauseRec [202]:
- 사용자 행동 시퀀스에서 핵심 개념을 대체하여 반사실(counterfactual) 데이터 분포를 모델링.
- 사용자 행동 중 중요한 데이터를 음성 쌍으로 설정.
4.2. Graph-based Negative Augmentation (그래프 기반 음성 증강)
-
개념:
- *그래프 구조(interaction graphs, social graphs, heterogeneous graphs)**를 기반으로 음성 쌍을 생성.
-
방법:
- 노드/엣지 드롭아웃(Node/Edge Dropout)
- 노드/엣지 구별(Node/Edge Discrimination)
- 랜덤 워크(Random Walk)
- 구조 변형(Structure Perturbation)
-
예시:
- SGL [169], EGLN [193], RGCL [137]:
- 노드와 엣지 간의 상관성을 고려하여 다양한 그래프 기반 NA 전략을 제안.
4.3. Sequence-based Negative Augmentation (시퀀스 기반 음성 증강)
-
개념:
사용자의 과거 행동 시퀀스를 기반으로 음성 샘플을 증강하여, 사용자의 동적 행동 특징(dynamic characteristics)을 캡처.
-
방법:
- 시퀀스 셔플(Shuffle)
- 마스킹(Mask)
- 크롭(Crop)
-
예시:
- Tailored Self-Supervised Representation Augmentation을 통해 더 견고하고 정확한 추천 모델 구축.
4.4. Scenarios-aware Negative Augmentation (시나리오 인식 음성 증강)
-
개념:
다양한 추천 시나리오의 복잡성과 요구 사항에 맞춰 음성 샘플을 증강.
-
예시:
- MMR [143, 163]:
- CL을 활용하여 사용자 선호도와 아이템 표현 간의 다중 뷰 관계(Multi-view Relationships)를 도출.
- 편향성이나 다양성 부족 문제 해결.
- MBR [59, 186]:
- 사용자 행동 패턴을 모델링하기 위해 보조 행동 데이터(auxiliary behavior data)를 기반으로 음성 샘플 생성.
- MMR [143, 163]:
-
5 CONCLUSION AND FUTURE DIRECTION
추천 시스템에서 negative sampling은 data sparsity, dynamic user preferences, inherent feedback loops(bias) 같은 문제를 해결하는 데 중요한 역할을 한다.
negative sampling 전략의 다섯 가지 분류
- static negative sampling(고정된 기준으로 음성 샘플 선택)
- dynamic negative sampling(사용자 행동이나 모델 학습 단계에 따라 동적으로 음성 샘플 선택)
- adversarial negative sampling(모델이 핛브하기 가장 어려운 음성 샘플 생성해 모델의 일반화 성능을 향상시키기 위해 최악의 시나리오 학습)
- Importance Re-weighting(음성 샘플의 중요도를 재가중화하여 모델 학습에서 더 의미 있는 샘플에 가중치 부여)
- Knowledge-enhanced Negative Sampling(지식 그래프 같은 외부 지식을 사용해 더 정교한 음성 샘플을 생성)
