[혼공컴운] 1주차
많은 사람들이 사용하는 프로그램을 만들기 위해서는 입력과 출력 뿐만 아니라 성능, 용량, 비용 문제를 고려해야 하는데 이를 위해서는 컴퓨터 구조를 알아야 한다.
01-2 컴퓨터 구조의 큰 그림
데이터, 명령어, 메모리, CPU, 보조기억장치, 입출력장치, 시스템 버스
컴퓨터 구조
- 컴퓨터가 이해하는 정보
- 컴퓨터의 네 가지 핵심 부품
컴퓨터가 이해하는 정보
컴퓨터는 0과 1로 표현된 정보만을 이해하는데 데이터와 명령어가 있다. 데이터는 컴퓨터와 주고받는 정보나 저장된 정보이고, 명령어는 데이터를 움직이고 컴퓨터를 작동시킨다. 즉, 명령어는 컴퓨터를 작동시키는 정보이고 데이터는 명령어를 위해 존재하는 일종의 재료이다. 컴퓨터 프로그램을 명령어들의 모음이라고 정의하기도 한다.
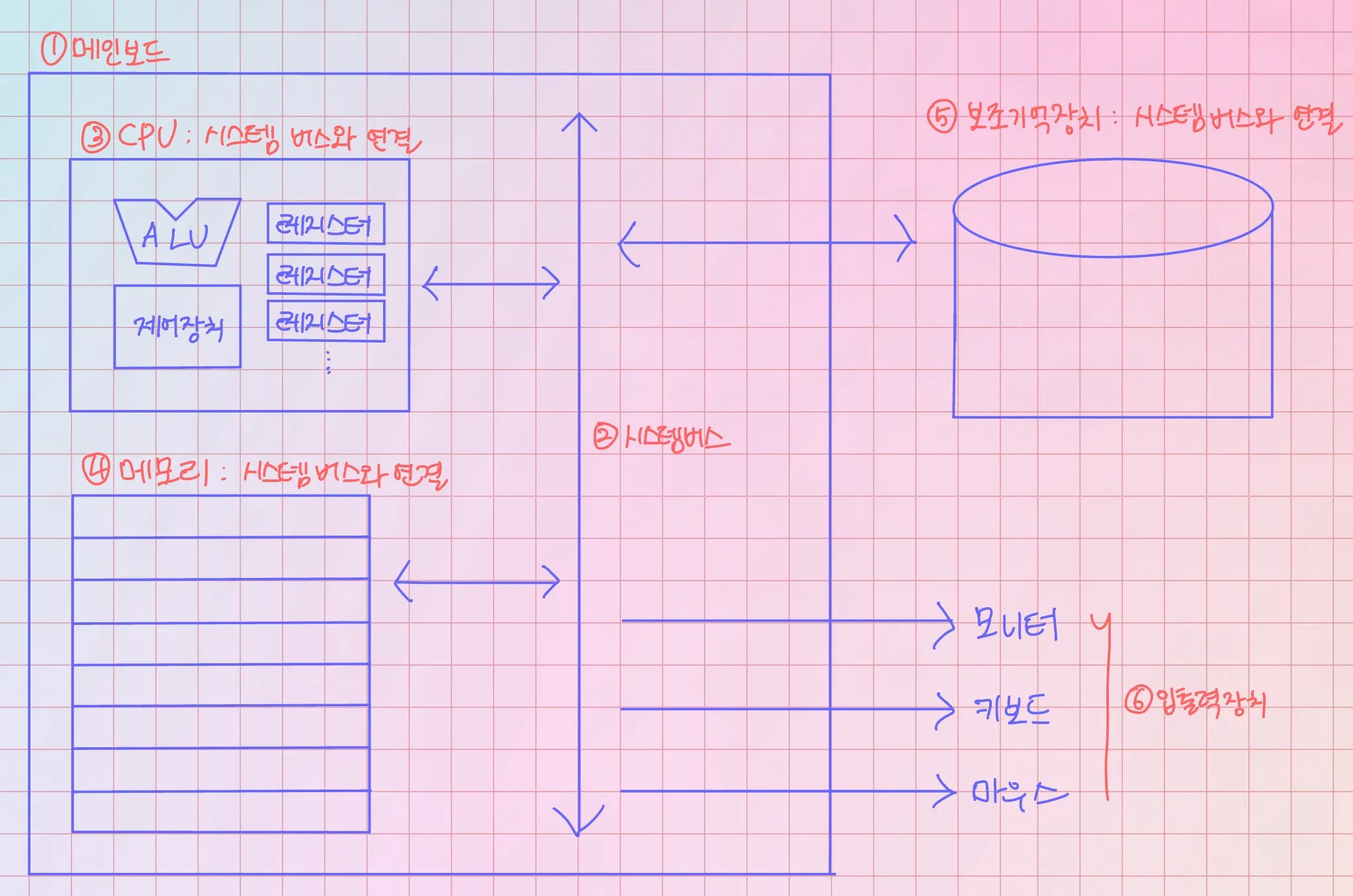
컴퓨터의 네 가지 핵심 부붐
중앙처리장치(CPU), 주기억장치(main, memory, 메모리), 보조기억장치, 입출력장치
주기억장치에는 RAM과 ROM이 있는데 메모리라는 용어는 보통 RAM을 지칭한다.
메모리
현재 실행되는 프로그램의 명령어와 데이터를 저장하는 부품
메모리에는 저장된 값에 빠르고 효율적으로 접근하기 위해 주소를 사용한다.
- 프로그램이 실행되기 위해서는 반드시 메모리에 저장되어 있어야 한다.
- 메모리는 현재 실행되는 프로그램의 명령어와 데이터를 저장한다.
- 메모리에 저장된 값의 위치는 주소로 알 수 있다.
CPU
메모리에 저장된 명령어를 읽어 들이고, 해석하고, 실행하는 부품
- 산술논리연산장치(ALU, arithmetic logic unit) : 계산기
- 레지스터(register) : 작은 임시 저장 장치. 프로그램을 실행하는 데 필요한 값들을 임시로 저장
- 제어장치(CU, control unit) : 제어 신호라는 전기 신호를 내보내고 명령어를 해석하는 장치
- 제어 신호 : 컴퓨터 부품들을 관리하고 작동시키기 위한 일종의 전기 신호
보조기억장치
전원이 꺼져도 보관될 프로그램을 저장하는 부품
메모리의 약점
- 가격이 비싸 저장 용량이 적다
- 전원이 꺼지면 저장된 내용을 잃는다
즉, 메모리보다 크기가 크고, 전원이 꺼져도 저장된 내용이 그대로인 장치가 필요하다. 메모리는 현재 실행될 프로그램을 저장하고, 보조기억장치는 보관할 프로그램을 저장한다.
HDD, SSD, USB메모리, DVD, CD-ROM 등
입출력장치
컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환할 수 있는 부품
마이크, 스피커, 프린터, 마우스, 키보드 등
보조기억장치와 입출력장치를 컴퓨터 주변에 붙어있는 장치라는 의미에서 주변장치라 통칭하기도 한다. 보조기억장치는 메모리를 보조하는 특별한 기능을 수행하는 입출력장치이다.
메인보드(마더보드)
여러 컴퓨터 부품을 연결
여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자가 있다.
시스템 버스
컴퓨터의 네 가지 핵심 부품이 서로 정보를 주고받는 통로
컴퓨터 내부에는 다양한 종류의 버스(통로)가 있는데, 가장 중요한 버스는 시스템 버스이다.
- 주소 버스 : 주소를 주고받는 통로
- 데이터 버스 : 데이터를 주고받는 통로
- 제어 버스 : 제어 신호를 주고받는 통로
- 제어장치는 제어 버스를 통해 신호를 내보낸다.
📍메모리 속 명령어를 읽기 위해서
- 제어 버스로 메모리 읽기 제어 신호를 내보낸다.
- 주소 버스로 읽고자 하는 주소를 내보낸다.
- 메모리는 데이터 버스로 CPU가 요청한 주소에 있는 내용을 내보낸다.
📌 51p 확인 문제 3번
프로그램이 실행되려면 반드시 메모리에 저장되어 있어야 한다.
02. 데이터
02-1. 0과 1로 숫자를 표현하는 방법
비트, 바이트, 이진법, 2의 보수, 십육진법
컴퓨터가 이해하는 정보의 단위를 학습하고, 이진법과 십육진법을 통해 다양한 숫자를 표현하는 방법에 대해 학습한다.
정보 단위
컴퓨터는 0과 1밖에 이해하지 못한다.
비트 : 0과 1을 나타내는 가장 작은 정보 단위
비트는 2가지 정보(0 또는 1)을 표현할 수 있다. n비트로 표현할 수 있는 상태는 가지이다. 우리가 실행하는 프로그램은 수십만, 수백만 비트로 이루어져 있는데, 프로그램의 크기를 말할 때 표현의 편의를 위해 비트보다는 큰 단위를 사용한다. → 바이트, 킬로바이트, 메가바이트, 기가바이트, 테라바이트
바이트 제외 모두 1000개를 묶어 표현한 단위이다.
- 바이트(byte) : 여덟 개의 비트를 묶은 단위이다. 1바이트는 개의 정보를 표현할 수 있다.
- 킬로바이트(kB) : 1바이트 1000개
- 메가바이트(MB) : 1킬로바이트를 1000개
- 기가바이트(GB) : 1메가바이트 1000개
- 테라바이트(TB) : 1기가바이트 1000개
+) 워드(word) : CPU가 한 번에 처리할 수 있는 데이터 크기이다. cpu가 16비트를 처리할 수 있으면 1워드는 16비트이고, 한 번에 32비트를 처리할 수 있으면 1워드는 32비트이다.
워드의 절반 크기를 하프 워드, 1배 크기를 풀 워드, 2배 크기를 더블 워드라곡 부른다. 컴퓨터의 워드 크기는 보통 32비트 또는 64비트이다. 인텔의 x86 cpu는 32비트 워드 cpu, x64 cpu는 64비트 워드 cpu이다.
이진법
수학에서 0과 1만으로 모든 숫자를 표현하는 방법이다. 1이 넘어가는 시점에 자리 올림을 하여 0과 1 두 개의 숫자만으로 모든 수를 표현한다. 컴퓨터에게는 이진수로 알려줘야 한다. 이진수 끝에는 (2)를 붙이거나(수학적) 이진수 앞에는 0b(코드 상)를 붙인다.
음수를 표현하기 위해서 2의 보수를 구해 이 값을 음수로 간주한다.
2의 보수 : 모든 0과 1을 뒤집고, 거기에 1을 더한 값이다.
- 11 : 00 → 01
11의 2의 보수(음수 표현)은 01이다.
n비트로는 과 이라는 수를 동시에 표현할 수 없다.
음수를 제대로 구했는지 알아보기 위해서는 어떤 수의 2의 보수를 두 번 구했을 때 자기자신이 되는지 확인한다.
실제로 이진수가 양인지 음인지 구분이 어려워서 플래그(flag)라는 부가 정보를 사용한다.
십육진법
데이터를 2진법으로만 나타내기에는 길이가 너무 길어지므로 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식인 십육진법도 자주 사용한다. 아래첨자로 (16)을 붙이거나(수학적으로) 0x(코드상으로)를 붙여 구분한다. A는 주먹이라 10, B는 하나 폈으니까 1 이렇게 기억한다.
십육진수를 이진수로 표현하려면 각각을 이진수로 표현하고 이어붙이면 된다. 이진수를 십육진수로 표현하려면 이진수 숫자 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환하고 이어 붙인다.
십육진법은 이진수를 십육진수로, 십육진수를 이진수로 변환하기 쉽기 때문에 자주 사용한다.
📌 65p 확인문제 3번
1101 → 0010 → 0011 이므로, 1101을 음수로 표현한 값은 0011이다.
02-2. 0과 1로 문자를 표현하는 방법
문자 집합, 아스키 코드, EUC-KR, 유니코드
아스키 코드, 유니코드 등은 컴퓨터가 이해할 수 있는 0과 1로 다양한 문자를 표현하는 방법이다. 여러 가지 문자 표현 방법을 학습한다.
문자 집합과 인코딩
- 문자 집합 : 컴퓨터가 인식하고 표현할 수 있는 문자의 모음이다. 컴퓨터는 문자 집합에 속해 있어야만 이해할 수 있다. {a, b, c} 는 이해하고 f는 이해못한다.
- 문자 인코딩 : 문자 집합에 속한 문자를 컴퓨터가 이해할 수 있도록 0과 1로 변환하는 과정이다. 인코딩 후 0과 1로 이루어진 결과값이 문자 코드가 된다.
- 문자 디코딩 : 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정이다.
📍아스키 코드(ASCII)
아스키는 초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 일부 특수 문자를 포함한다. 아스키 문자는 7비트로 표현되므로 128개의 문자를 표현할 수 있다. 1비트는 패리티 비트(parity bit)로 불리는 오류 검출을 위해 사용되는 바이트이기 때문에 실질적으로 문자 표현을 위해 사용되는 비트는 7비트이다. 아스키 문자에 대응된 고유한 수를 아스키 코드라고 한다. A에 대응된 고유한 수인 65가 아스키 코드이다.
아스키 코드는 한글 뿐만 아니라 아스키 문자 집합 외의 문자는 표현이 어렵다. 한국 포함 영어권 나라들은 각자의 언어를 표현할 수 있는 인코딩 방식이 필요한데, 한글은 EUC-KR을 사용한다.
📍EUC-KR
한글 인코딩에는 완성형과 조합형이 있다.
- 완성형 인코딩 : 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여한다.
- 가는 1, 나는 2, 다는 3으로 인코딩
- 조합형 인코딩 : 초성 중성 종성을 위한 비트열에 각각 할당한다.
- ㄱ에 1, ㅏ에 2 이런식
EUC-KR은 완성형 인코딩 방식이다. 한글 단어에 2바이트 크기의 코드를 부여한다. 16비트니까 4자리 십육진수로 표현이 가능하다. 표현할 수 없는 한글 단어가 존재한다. CP949를 사용해 EUC-KR로는 표현이 어려운 다양한 문자를 표현할 수 있다. 하지만 한글 전체를 표현하기 어렵다.
📍유니코드
모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이다. 대부분 나라의 문자, 특수문자, 화살표, 이모티콘까지 코드로 표현이 가능하다.
유니코드 문자 집합에서 아스키 코드나 EUC-KR과 같이 각 문자마다 고유한 값이 부여되고 이전과 달리 부여된 값 자체를 인코딩된 값으로 삼지 않고 다양한 방법으로 인코딩한다. utf-8, utf-16 등이 있다. UTF는 유니코드를 인코딩하는 방법이다.
03 명령어
03-1 소스 코드와 명령어
고급 언어, 저급 언어, 기계어, 어셈블리어, 컴파일 언어, 인터프리터 언어
개발자가 프로그래밍 언어로 작성한 소스 코드가 컴퓨터 내부에서 명령어가 되고 실행되는 과정을 학습한다.
📍모든 소스 코드는 컴퓨터 내부에서 명령어로 변환된다!
고급 언어와 저급 언어
✔️ 고급 언어
사람을 위한 언어
프로그래밍 언어는 컴퓨터가 아닌 사람이 사용하기 쉽게 만들어진 언어이므로, 컴퓨터가 이해하지 못한다.
✔️ 저급 언어
컴퓨터가 직접 이해하고 실행할 수 있는 언어
컴퓨터는 저급 언어만 이해할 수 있어서 고급 언어로 작성된 소스 코드가 실행되려면 꼭 저급 언어인 명령어로 변환되어야 한다.
- 저급 언어
- 기계어 : 0과 1로 이루어진 언어. 이진수로 나열하면 가독성이 떨어져 십육진수로 표현하기도 한다. 컴퓨터만 이해할 수 있다.
- 어셈블리어 : 기계어를 읽기 편한 형태로 번역한 언어. 어셈블리어 한 줄 한 줄이 명렁어이다.
- 0101 0101 → push rbp
- 0101 1101 → pop rbp
어셈블리어는 그저 기계어를 읽기 쉽게 번역한 것이므로 어셈블리어로 프로그램을 구현할 수 없으므로 고급 언어를 이용해 구현한다.
하드웨어와 연관이 깊은 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보 보안 분야 개발자는 많이 이용하고, 작성 뿐만 아니라 중요한 관찰의 대상이다.
어셈블리어를 읽으면 컴퓨터가 프로그램을 어떤 과정으로 실행하는지, 프로그램이 어떤 절차로 작동하는지를 가장 근본적인 단계에서부터 하나하나 추적하고 관찰할 수 있다.
컴파일 언어와 인터프리터 언어
고급 → 저급 변환하는 방법에는 크게 컴파일 방식과 인터프리트 방식이 있고 각각 해당 방식을 사용하는 언어를 컴파일 언어, 인터프리터 언어라고 한다.
📌 컴파일 언어
- 소스코드 전체가 저급 언어로 변환되어 실행된다.
- 소스 코드 전체가 저급 언어로 변환되는 과정이 컴파일이다.
- 컴파일 해주는 도구 : 컴파일러
- 오류를 하나라도 발견하면 컴파일에 실패한다.
- C가 대표적
- 저급 언어로 변환된 코드를 목적 코드라고 한다. (저급 언어 코드)
📌 인터프리터 언어
- 인터프리터에 의해 소스 코드가 한 줄씩 실행된다.
- 한 줄씩 실행되기 때문에 n줄에 오류가 있어도 n-1번째 줄까지는 제대로 실행된다.
- python이 대표적이다.
- 컴파일 언어보다 느리다.
✔️ 아주 명확하게 구분되는 개념은 아니다. 컴파일이 가능하다고 해서 인터프리트가 불가능하지는 않다. 대표적인 방식이구나 하고 이해하면 된다.
목적 파일 vs 실행 파일
목적 파일은 목적 코드로 구성되어 있고, 실행 파일은 실행 코드로 구성되어 있다. 저급 언어라고 해서 바로 실행되는 것이 아니라 각각의 기능이 다른 소스코드에 구현되어 있으면 연결해줘야 비로소 실행할 수 있다.
📍링킹
목적 코드가 실행 파일이 되기 위해서 거쳐야 하는 과정으로 목적 코드에 연결된 것이 있을 때 그 부분들을 연결 짓는 과정이 필요하다. 연결짓는 과정을 링킹이라고 하고, 링킹 작업까지 거쳐야 하나의 실행 파일이 만들어진다.
main파일 따로 helper파일 따로 컴파일되므로 연결해주면 하나의 실행 파일이 만들어진다.
📌89p 확인 문제
기계어와 어셈블리어는 저급 언어이다.
인터프리터 언어는 한 줄 한 줄 저급 언어로 해석하며 실행해야 하므로 일반적으로 컴파일 언어보다 느리다.
03-2 명령어의 구조
명령어, 연산 코드, 오퍼랜드, 주소 지정 방식
명령어의 구조와 주소 지정 방식을 학습하며 명령어의 생김새와 작동 원리 이해하기
연산 코드와 오퍼랜드
무엇을 대상으로, 어떤 작동을 수행하라
| 더해라 | 100과 | 120을 |
|---|---|---|
| 빼라 | 메모리 32번지 안의 값과 | 메모리 33번지 안의 값을 |
| 저장해라 | 10을 | 메모리 128번지에 |
📍연산 코드(연산자)
명령어가 수행할 연산(작동)
명령어의 종류와 생김새는 cpu마다 다르므로, 연산 코드의 종류와 생김새 또한 다르다.
공통으로 이해하는 대표적이고 가장 기본적인 연산 코드 유형
✔️ 데이터 전송
| MOVE | 데이터를 옮겨라 |
|---|---|
| STORE | 메모리에 저장해라 |
| LOAD(FETCH) | 메모리에서 cpu로 데이터를 가져와라 |
| PUSH | 스택에 데이터를 저장해라 |
| POP | 스택의 최상단 데이터를 가져와라 |
✔️ 산술/논리 연산
| ADD / SUBTRACT / MULTIPLY / DIVIDE | 덧셈 / 뺄셈 / 곱셈 / 나눗셈을 수행하라 |
|---|---|
| INCREMENT / DECREMENT | 오퍼랜드에 1을 더하라 / 오퍼랜드에 1을 빼라 |
| AND / OR / NOT | 각각의 연산을 수행하기 |
| COMPARE | 두 개의 숫자 또는 TRUE/FALSE 값을 비교하라 |
✔️ 제어 흐름 변경
| JUMP | 특정 주소로 실행 순서를 옮겨라 |
|---|---|
| CONDITIONAL JUMP | 조건에 부합할 때 특정 주소로 실행 순서를 옮겨라 |
| HALT | 프로그램의 실행을 멈춰라 |
| CALL | 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라 |
| RETURN | CALL을 호출할 때 저장했던 주소로 돌아가라 |
✔️ 입출력 제어
| READ(INPUT) | 특정 입출력 장치로부터 데이터를 읽어라 |
|---|---|
| WRITE(OUTPUT) | 특정 입출력 장치로 데이터를 써라 |
| START IO | 입출력 장치를 시작하라 |
| TEST IO | 입출력 장치의 상태를 확인하라 |
📍오퍼랜드(operand, 피연산자, 주소필드)
연산에 사용할 데이터 또는 연산에 사용할 데이터가 저장된 위치
- 숫자와 문자 등을 나타내는 데이터
- 레지스터 주소
보통은 데이터를 직접 명시하기 보다는 메모리 주소나 레지스터 이름이 담긴다. 그래서 주소 필드라고도 불린다.
| 연산 코드 필드 | 오퍼랜드 필드 |
|---|
mov eax, 0 # 오퍼렌드가 두 개
pop rbp # 오퍼랜드가 한 개
ret # 오퍼랜드가 없음✔️ 0 - 주소 명령어 : 오퍼랜드 0개
| 연산 코드 |
|---|
✔️ 1 - 주소 명령어 : 오퍼랜드 1개
✔️ 2 - 주소 명령어 : 오퍼랜드 2개
✔️ 3 - 주소 명령어 : 오퍼랜드 3개
| 연산 코드 | 오퍼랜드 | 오퍼랜드 | 오퍼랜드 |
|---|
주소 지정 방식
오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법 = 유효 주소 찾는 방법
💡 유효 주소
연산 코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치
❓오퍼랜드 필드에 메모리나 레지스터의 주소를 담는 이유
<연산 코드, 연산 코드에 사용될 데이터> 형식으로 구성하면 왜 안될까?
❗️ 명령어 길이 때문!
하나의 명령어가 n비트고 연산 코드 필드가 m비트면 오퍼랜드 필드에 가장 많은 공간을 할당할 수 있는 1-주소 명령어라 할지라도 오퍼랜드 필드의 길이는 n-m 비트이다. 2-주소 명령어, 3-주소 명령어라면 오퍼랜드 필드의 크기가 작아진다.
하지만, 메모리 주소가 담긴다면? 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다. 레지스터 이름도 마찬가지로 해당 레지스터가 저장할 수 있는 공간만큼 커진다.
e.g. 명령어 크기 16비트, 연산 코드 필드 4비트인 2-주소 명령어에서는 오퍼랜드 필드당 6비트만 남아서 개밖에 되지 않는다. 한 주소에 16비트를 저장할 수 있는 메모리는 정보의 가짓수가 2^16으로 커진다.
📌 즉시 주소 지정 방식
연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
물론 정보의 가짓수가 한계가 있지만, 메모리나 레지스터로부터 찾는 과정이 없어 주소 지정 방식들보다 빠르다.
📌 직접 주소 지정 방식
오퍼랜드 필드에 유효 주소를 직접적으로 명시
즉시 주소 지정 방식보다는 커졌어도 유효 주소를 표현할 수 있는 범위가 연산 코드 비트 수만큼 줄어든다. - 유효 주소에 제한이 생길 수 있다.
📌 간접 주소 지정 방식
유효 주소의 주소를 오퍼랜드 필드에 명시한다.
표현할 수 있는 유효 주소의 범위는 넓어지지만 두 번의 메모리 접근이 필요하므로 일반적으로 느리다.
📌 레지스터 주소 지정 방식
직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시
일반적으로 cpu 외부에 있는 메모리보다 내부의 레지스터에 접근하는 것이 빠르다. 직접 주소 지정 방식과 비슷하게 레지스터 크기에 제한이 생길 수 있다.
📌 레지스터 간접 주소 지정 방식
연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시
간접 주소 지정 방식과 비슷한데 메모리에 접근하는 횟수가 1번이라 더 빠르다.
스택과 큐
📍 스택
한쪽 끝이 막혀 있는 통과 같은 저장 공간이다. 한쪽 끝이 막혀 있어서 막혀있지 않은 쪽으로 데이터가 쌓이고, 가장 마지막으로 저장한 데이터부터 뺴낸다. Last in First Out(LIFO, 리포) 자료 구조이다.
- PUSH : 스택에 새로운 데이터를 저장하는 명령어
- POP : 스택에 저장된 데이터를 꺼내는 명령어
📍 큐
양쪽이 뚫렬 있는 통과 같은 저장 공간인데 한쪽으로 데이터를 저장하고 한쪽으로 데이터를 빼낸다. First in First Out(FIFO, 피포) 자료 구조이다.
