
데이터 프레임 Data Frame
데이터프레임은 행과 열로 이루어진 데이터의 집합체로, 행렬과 유사합니다.
가장 보편적인 데이터셋 형식이에요!
하지만, 행렬과 다른 점은, 데이터프레임에는 자료형이 다른 데이터를 함께 입력할 수 있다는 점입니다.
데이터 프레임 만들기
데이터프레임은 data.frame() 함수를 사용하여 만듭니다.
각 열에 해당되는 자료형의 벡터로 각 열을 설정합니다.
> persons <- data.frame(Name = c("Sea", "Sangwoo", "Vely"), Gender = c("Female", "Male", "Neutral"),
Age = c(27, 33, 9),
Major = c("Aerospace", "Aerospace", "Cat-stuff"))
> persons
Name Gender Age Major
1 Sea Female 27 Aerospace
2 Sangwoo Male 33 Aerospace
3 Vely Neutral 9 Cat-stuff
데이터프레임을 만드는 방법은 리스트를 만드는 방법과 동일해요!
또, 리스트를 만든 뒤 data.frame(리스트명) 또는 as.data.frame(리스트명) 으로 데이터 프레임을 만들 수도 있습니다.
> l1 <- list(x=c(1,2,3), y=c("a","b","c"))
> data.frame(l1)
x y
1 1 a
2 2 b
3 3 c
> as.data.frame(l1)
x y
1 1 a
2 2 b
3 3 c
행렬도 마찬가지입니다.
> m1 <- matrix(c(1,2,3,4,5,6,7,8,9), nrow=3, byrow=FALSE)
> data.frame(m1)
X1 X2 X3
1 1 4 7
2 2 5 8
3 3 6 9
> as.data.frame(m1)
V1 V2 V3
1 1 4 7
2 2 5 8
3 3 6 9
행과 열 명명하기
데이터프레임에서 데이터의 행과 열은 다음과 같이 명명할 수 있습니다.
> df1 <- data.frame(id=1:5, x=c(0,2,1,-1,-3),y=c(0.5,0.2,0.1,0.5,0.9))
> df1
id x y
1 1 0 0.5
2 2 2 0.2
3 3 1 0.1
4 4 -1 0.5
5 5 -3 0.9
> colnames(df1) <- c("id", "level", "score")
> rownames(df1) <- letters[1:5]
> df1
id level score
a 1 0 0.5
b 2 2 0.2
c 3 1 0.1
d 4 -1 0.5
e 5 -3 0.9
행렬과 마찬가지의 방법으로 행과 열의 이름을 변경할 수 있어요!
데이터프레임 서브세팅
데이터프레임은 행렬과 유사하고, 열벡터로 구성된 리스트라고 볼 수 있는데요,
따라서 이러한 성질을 이용하면 데이터프레임의 요소와 부분 집합을 추출할 수 있습니다.
리스트처럼 서브세팅하기
데이터프레임을 벡터의 리스트로 간주해서, 리스트 표기법과 동일하게 값 또는 부분 집합을 추출할 수 있습니다.
예를 들어, $ 기호를 사용하여 이름으로 열 값을 추출하거나, [[]]에 위치 정보를 이용하여 데이터에 접근할 수 있습니다.
> df1$id
[1] 1 2 3 4 5
> df1[[1]]
[1] 1 2 3 4 5
> df1[1]
id
a 1
b 2
c 3
d 4
e 5
> df1[1:2]
id level
a 1 0
b 2 2
c 3 1
d 4 -1
e 5 -3
> df1["level"]
level
a 0
b 2
c 1
d -1
e -3
> df1[c("id", "score")]
id score
a 1 0.5
b 2 0.2
c 3 0.1
d 4 0.5
e 5 0.9
> df1[c(TRUE, FALSE, TRUE)]
id score
a 1 0.5
b 2 0.2
c 3 0.1
d 4 0.5
e 5 0.9
행렬처럼 서브세팅하기
리스트 방식은 열 집합과 같아서, 행 선택을 지원하지 않습니다.
대신, 데이터 프레임을 행렬과 같이 2차원으로 접근하면 행과 열 모두를 자유롭게 선택하여 부분 데이터 집합에 쉽게 접근할 수 있습니다.
행렬 방식으로 열 선택자를 지정하는 방법은 다음과 같습니다.
> df1[,"level"][1] 0 2 1 -1 -3
> df1[, c("id", "level")]
id level
a 1 0
b 2 2
c 3 1
d 4 -1
e 5 -3
> df1[, 1:2]
id level
a 1 0
b 2 2
c 3 1
d 4 -1
e 5 -3
그러면 당연히 행 선택자 지정하는 방법도 아시겠지요?
> df1[1:4,]
id level score
a 1 0 0.5
b 2 2 0.2
c 3 1 0.1
d 4 -1 0.5
> df1[c("c", "e"),]
id level score
c 3 1 0.1
e 5 -3 0.9
행과 열을 동시에 선택할 수도 있어요.
> df1[1:4, "id"]
[1] 1 2 3 4
> df1[1:3, c("id", "score")]
id score
a 1 0.5
b 2 0.2
c 3 0.1
결과를 항상 데이터 프레임으로 유지하기 위해서는 다음과 같이 사용합니다.
> df1[1:4,]["id"]
id
a 1
b 2
c 3
d 4
또는,
> df1[1:4, "id", drop=FALSE]
id
a 1
b 2
c 3
d 4
이렇게 씁니다.
> df1[1:4, "id"]
[1] 1 2 3 4
데이터 연산 시 이렇게 쓰면, 데이터 프레임이 아닌 벡터가 주어지기 때문에, 오류가 발생할 수 있습니다.
데이터 필터링
다음 코드로 score >= 0.5라는 조건을 만족하는 df1의 행을 선택하고, id와 level 열을 선택합니다.
> df1$score >= 0.5
[1] TRUE FALSE FALSE TRUE TRUE
> df1[df1$score>=0.5, c("id", "level")]
id level
a 1 0
d 4 -1
e 5 -3
다음 코드는 이름이 a, d, e인 행들과 id, score 열만 골라내는 필터링을 합니다.
> rownames(df1) %in% c("a","d","e")
[1] TRUE FALSE FALSE TRUE TRUE
> df1[rownames(df1) %in% c("a","d","e"), c("id","score")]
id score
a 1 0.5
d 4 0.5
e 5 0.9
행을 선택할 때는 논리형 벡터를 사용하고, 열을 선택할 때는 문자형 벡터를 사용하였습니다.
값 설정하기
데이터 프레임의 부분 집합에 해당하는 값을 설정할 때도, 마찬가지로 리스트와 행렬 방식 모두 사용할 수 있습니다.
리스트처럼 값 설정하기
$와 <-기호를 사용하여 새로운 값을 리스트 구성요소로 할당 가능합니다.
> df1$score <- c(0.6, 0.3, 0.2, 0.4, 0.8)
> df1
id level score
a 1 0 0.6
b 2 2 0.3
c 3 1 0.2
d 4 -1 0.4
e 5 -3 0.8
대괄호를 사용할 수도 있습니다.
대괄호[]는 한 표현식에 여러 열을 동시 변경할 수 있고, 이중 대괄호[[]]는 한 번에 한 열만 수정할 수 있습니다.
> df1["score"] <- c(0.8,0.5,0.2,0.4,0.8)
> df1
id level score
a 1 0 0.8
b 2 2 0.5
c 3 1 0.2
d 4 -1 0.4
e 5 -3 0.8
> df1[["score"]] <- c(0.4,0.5,0.2,0.8,0.4)
> df1
id level score
a 1 0 0.4
b 2 2 0.5
c 3 1 0.2
d 4 -1 0.8
e 5 -3 0.4
> df1[c("level", "score")] <- list(level = c(1,2,1,0,0), score = c(0.1,0.2,0.3,0.4,0.5))
> df1
id level score
a 1 1 0.1
b 2 2 0.2
c 3 1 0.3
d 4 0 0.4
e 5 0 0.5
요인 (Factor)
persons 데이터프레임에 str() 함수를 호출하면,
> str(persons)
'data.frame': 3 obs. of 4 variables:
$ Name : chr "Sea" "Sangwoo" "Vely"
$ Gender: chr "Female" "Male" "Male"
$ Age : num 27 33 9
$ Major : chr "Aerospace" "Aerospace" "Cat-stuff"
이때 Sangwoo와 Vely의 성별은 Male로 동일합니다. 이렇게 한정된 값을 표현하기 위해서는 문자형 벡터를 사용하는 것보다 요인(factor)으로 나타내는 것이 합리적입니다.
> persons <- data.frame(Name = c("Sea", "Sangwoo", "Vely"),
Gender = factor(c("Female", "Male", "Male")),
Age = c(27, 33, 9),
Major = c("Aerospace", "Aerospace", "Cat-stuff"),
stringsAsFactors = FALSE)
> str(persons)
'data.frame': 3 obs. of 4 variables:
$ Name : chr "Sea" "Sangwoo" "Vely"
$ Gender: Factor w/ 2 levels "Female","Male": 1 2 2
$ Age : num 27 33 9
$ Major : chr "Aerospace" "Aerospace" "Cat-stuff"
데이터 프레임에 유용한 함수
데이터 프레임에서 자주 사용하는 함수들 몇 가지가 있어요!
summary()
summary() 함수는 데이터프레임의 각 열에 대한 기본 통계량을 나타냅니다.
> summary(persons)
Name Gender Age Major
Length:3 Female:1 Min. : 9 Length:3
Class :character Male :2 1st Qu.:18 Class :character
Mode :character Median :27 Mode :character
Mean :23
3rd Qu.:30
Max. :33
요인 항목은 각 요인값을 갖는 행의 개수를 센다.
수치형 벡터는 열에 있는 수치값들의 최솟값, 중앙값, 평균, 최댓값, 1Quarter, 3Quarter등 중요한 수치 정보를 알려줍니다.
이외의 항목에서는 열의 길이, 클래스, 모드를 알려줍니다.
Binding
여러가지 데이터 프레임을 행이나 열로 바인딩할 수 있습니다.
이를 위해 rbind()와 cbind() 함수를 사용하는데, 이름과 같이 행과 열 바인딩을 각각 수행합니다.
데이터 프레임에 행 추가하기
rbind()로 데이터프레임에 새로운 레코드를 추가합니다.
> rbind(persons, data.frame(Name="Cherry", Gender="Female", Age=25, Major="K-Medicine"))
Name Gender Age Major
1 Sea Female 27 Aerospace
2 Sangwoo Male 33 Aerospace
3 Vely Male 9 Cat-stuff
4 Cherry Female 25 K-Medicine
데이터 프레임에 열 추가하기
cbind()로는 새로운 열 항목을 추가할 수 있습니다.
> cbind(persons, Registered = c(TRUE, TRUE, FALSE))
Name Gender Age Major Registered
1 Sea Female 27 Aerospace TRUE
2 Sangwoo Male 33 Aerospace TRUE
3 Vely Male 9 Cat-stuff FALSE
단, rbind()와 cbind() 함수를 사용하면, 원래의 데이터는 변하지 않고 주어진 행과 열이 추가된 새로운 데이터 프레임이 생성되는 것입니다.
Expand.grid()
expand.grid() 함수는 각 열에 가능한 모든 값의 조합을 포함하는 데이터 프레임을 생성합니다.
> expand.grid(type = c("A","B"), class=c("S","M","L","XL"))
type class
1 A S
2 B S
3 A M
4 B M
5 A L
6 B L
7 A XL
8 B XL
유용한 함수들이 이 외에도 매우 많지만, 나중에 더 자세하게 다루도록 하겠습니다.
데이터 읽고 쓰기
데이터는 주로 파일 형식으로 저장합니다. R은 기본적으로 파일에서 테이블을 읽거나, 파일에 데이터프레임을 저장하기 위한 여러가지 함수들을 제공합니다.
주로 이러한 데이터 형식으로는 CSV(Comma-Seperated Values)를 사용합니다. 이름과 같이 데이터가 쉼표로 구분되어 있습니다. 아 참! 첫 번째 행은 헤더로 간주됩니다.
어떤 데이터 프레임을 CSV 파일에 저장하려면 몇가지 추가 인수와 함께 write.csv(file) 함수를 사용합니다.
> write.csv(persons, "data/persons.csv", row.names=FALSE, quote=FALSE)
여기서, row.names=FALSE는 행 이름을 저장하지 않는다는 의미입니다.
quote=FALSE는 문자열에 따옴표를 생략한다는 의미입니다.
그러면, 정말로 저장되었을까요? 확인해보겠습니다.

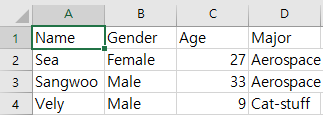
데이터프레임이 CSV 파일로 저장되었습니다.
이번에는 CSV 파일을 R 환경으로 읽어오겠습니다.
> read.csv("data/persons.csv")
Name Gender Age Major
1 Sea Female 27 Aerospace
2 Sangwoo Male 33 Aerospace
3 Vely Male 9 Cat-stuff
데이터 프레임에 관한 내용을 정리하여 보았습니다.
앞으로는 R과 Python 머신러닝을 병행하여 공부하려고 합니다.
스트리밍까지 함께 다 하려니 하루가 너무너무 부족합니다. (˘・_・˘)
[참고자료 : 「R 교과서」, 쿤 렌, (주)도서출판길벗, 2020-04-29]
