
Thread
-
스레드는 프로세스가 할당 받은 자원을 이용하는 실행 흐름의 단위이다.
하나의 프로그램은 하나 이상의 프로세스를 가지고 있고,
하나의 프로세스는 반드시 하나 이상의 스레드를 갖는다. -
즉, 하나의 프로세스 내에서 동시 에 진행되는 작업의 갈래, 흐름의 단위 를 말한다.
-
동일한 프로그램을 여러 개의 프로세스로 만들게 되면 ( 멀티 프로세스 ) , 그만큼 메모리를 차지하고 CPU 에서 할당받는 자원이 중복되게 된다.
-
스레드는 이러한 프로세스의 한계를 해결하기 위해 탄생했다.

-
크롬 브라우저 실행 시 우리는 브라우저에서 파일을 다운 받으며 온라인 쇼핑을 하는 등 다중 작업을 진행한다.
-
이러한 행위가 가능한 것은 하나의 프로세스 안에서 여러가지 작업들의 흐름이 동시에 진행되기 때문에 가능한 것인데, 이러한 일련의 작업의 흐름을 스레드라고 한다.
-
하나의 프로세스 안에는 여러 개의 스레드들이 들어 있을 수 있다. 스레드 수가 많을 수록 프로그램도 동시에 하는 작업이 많아져 성능이 올라간다.
하지만 모든 상황에 대해 스레드가 많은 것이 더 좋지만은 않다. 멀티 스레드가 싱글 스레드보다 무조건 좋다고 할 수도 없다. 그 이유는 여러가지인데 다음 기회에 작성하도록 하겠다.
- 프로세스를 생성하면 기본적으로 하나의 main 스레드를 생성하게 되어 있다. 그 외 스레드는 개발자가 직접 프로그래밍하여 위치시켜줘야 한다.
JAVA 는 JVM 위에서 동작하는데 JVM은 프로그램의 시작점인 main 메서드를 찾아 main 스레드를 생성하고 실행한다.
스레드의 자원 공유
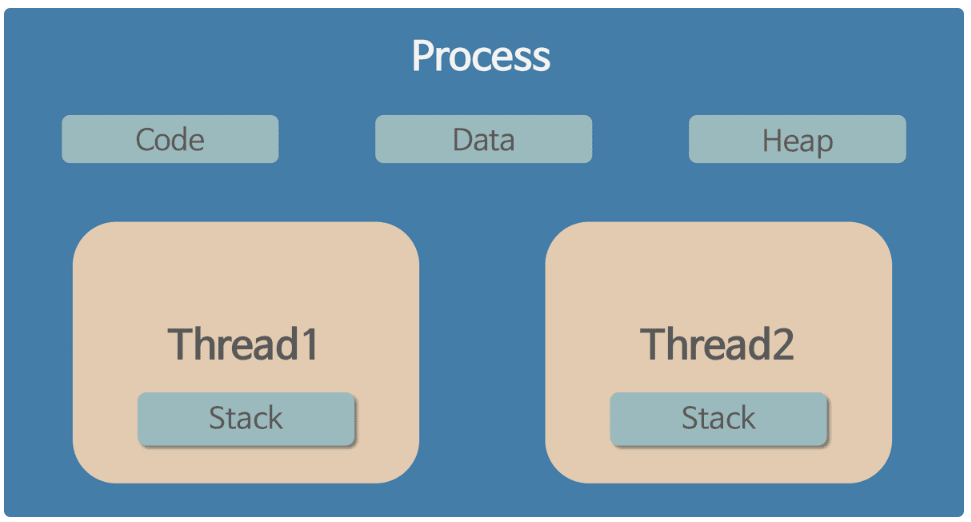
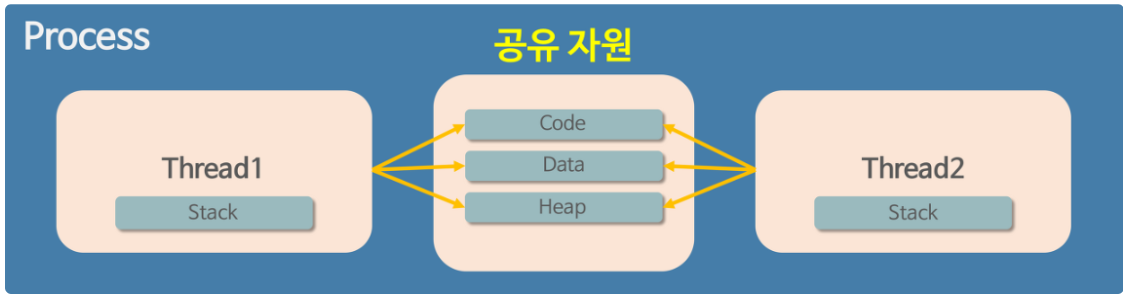
- 스레드는 스레드들끼리 프로세스의 자원을 공유하면서 프로세스 실행 흐름의 일부가 되어 동시 작업을 진행한다.
-
이때 프로세스의 4가지 메모리영역 ( Code/Text , Data , Heap , Stack ) 중 스레드는 Stack 만 할당 받아 복사하고 각각 Stack 을 하나씩 가지고 있는다.
-
나머지 Code, Data, Heap 은 스레드들과 공유된다.
-
그래서 각각의 스레드는 별도의 Stack 을 가지고 있지만 Heap 메모리는 고유하기 때문에 서로 다른 스레드에서 가져와 읽고 쓰며 공유한다.
-
이렇게 구성한 이유는 하나의 프로세스를 다수의 스레드로 구분하여 자원을 공유함으로서, 자원의 생성과 중복성을 최소화하여 수행 능력을 올리기 위해서이다.
Stack 은 함수 호출과 관계되는 지역변수, 매개변수 등이 저장되는 메모리 공간이기 때문에 독립적인 스택을 가졌다는 것은 독립적인 함수 호출이 가능하며 독립적인 실행 흐름을 가진다는 의미다.
스레드의 동시 실행 원리
-
앞서 배운 프로세스 동시 실행 원리와 동일하다.
-
CPU의 멀티 태스킹 기술로 병렬성과 동시성을 이용한 작업 처리 방식을 통해 여러 개의 코어를 동시 진행하면서 프로세스를 잘게 쪼개면서 처리한다.
논리적인 코어 갯수인 CPU 의 스레드는 가령 12 스레드일 땐 12 개의 프로세스가 실행이 가능하다. 그리고 한 코어당 한 프로세스가 작동을 하는 원리로 되어있다.
이를 멀티태스킹으로 프로세스 작업들을 잘게 쪼개서 조금씩 실행하도록 구현하여 수십개의 프로세스를 처리하게 만들었다.
스레드도 마찬가지로 한 프로세스에는 하나의 스레드가 돌아가지만, 여러개의 스레드 작업들을 잘게 쪼개 조금씩 실행하도록 구현하여 수십개의 스레드가 돌아가도록 만든 것이다.
스레드 스케쥴링
-
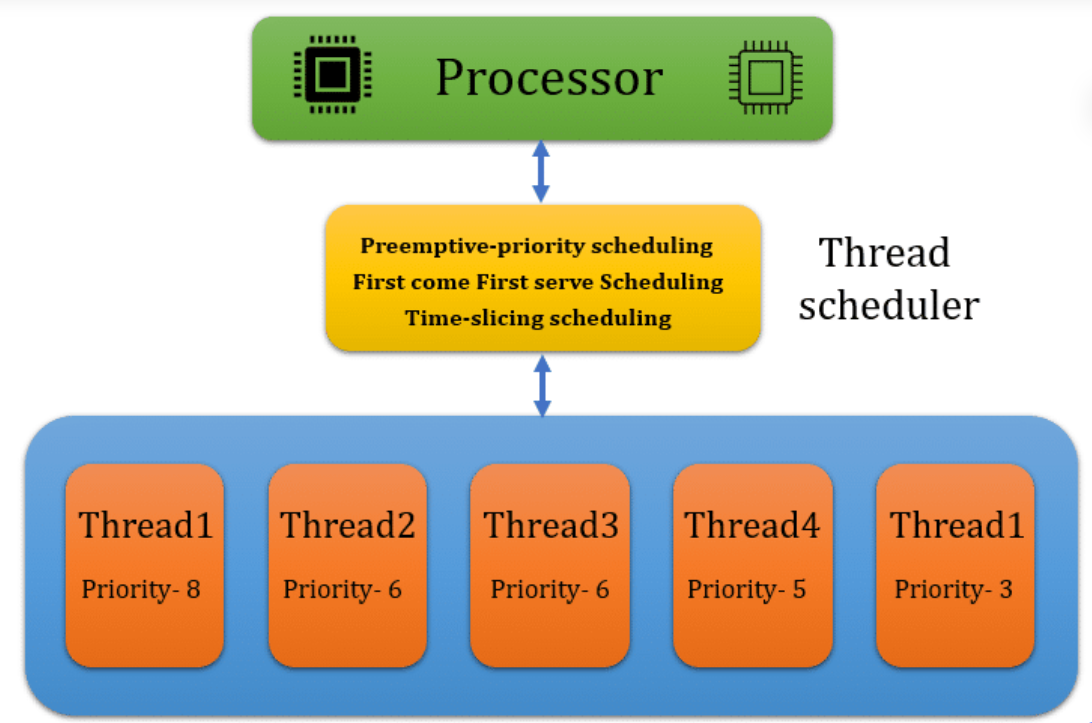
스레드 스케쥴링은 앞서 배운 프로세스 스케쥴링과 마찬가지로 OS 에서 다중 스레드를 관리한다.
-
OS 는 스레드의 우선순위 , 실행 시간 , 입출력 요청 등의 정보를 고려하여 CPU 를 사용할 수 있는 스레드를 선택하는 알고리즘을 돌려 CPU 를 할당한다.
-
알고리즘의 대표적으로 RR(Round Robin), Priority-based scheduling , Multi-level Queue scheduling 등이 있다.
-
다만 스레드 스케쥴링은 프로세스 스케쥴링과 다르게 하나의 프로세스 내에서 다수의 스레드가 동작하는 형태이기 때문에, 스레드 간의 상호작용과 동기화 문제를 고려해야 한다는 차이점이 존재한다.
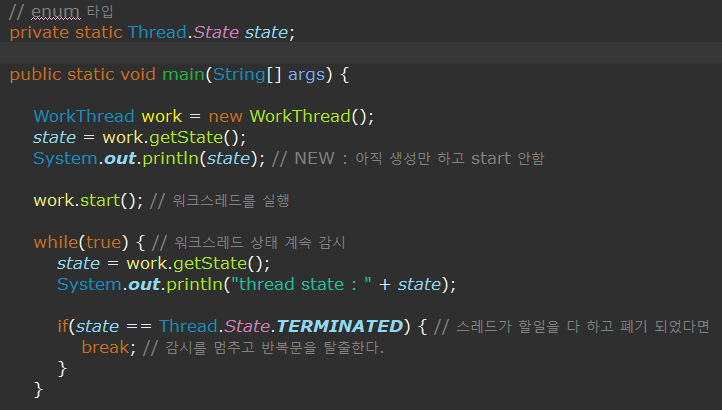
스레드의 상태
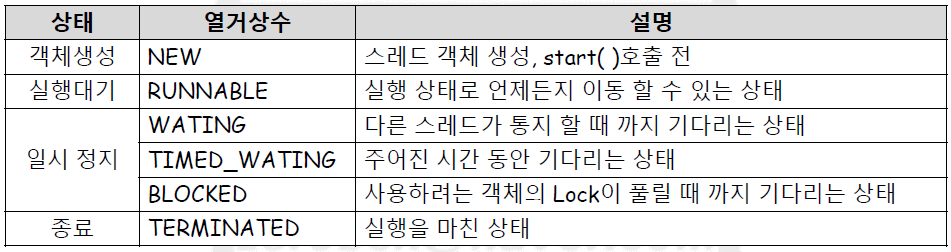
- NEW : 스레드 객체 생성. 하지만 아직 start() 로 호출되지 않은 상태
- RUNNABLE : 실행대기 상태. 언제든 CPU 에 할당받을 준비가 되어 있다.
- WAITING : 일시 정지 상태. 다른 스레드가 통지 할 때까지 기다린다.
- TIMED_WAITING : 일시 정지 상태. 주어진 시간 동안 기다리는 상태.
- BLOCKED : 일시 정지 상태. 사용하려는 객체의 Lock 이 풀릴 때까지 기다리는 상태.
WAITING , TIMED_WAITING , BLOCKED 는 일시 정지 상태로 CPU의 할당을 받지 못하며, 풀리면 RUNNABLE 실행대기 상태로 돌아간다.
- TERMINATED : 실행을 완료하고 종료된 상태. 더 이상 실행할 수 없으며 메모리에서 제거된다.
스레드는 한 번 생성할 때마다 OS 가 해당 스레드를 위한 메모리 영역을 확보해주고 스레드가 필요 없을 땐 다시 이 메모리 영역을 회수하는 작업이 일어난다. 이는 비용이 상당한 작업이기 때문에 이런 상황이 반복될 경우 퍼포먼스에 영향이 간다.
이를 제어하기 위해 Thread pool 이 존재한다.
Thread pool 은 다음 시리즈에 정리하기로...
- 실행 중일 때 상태는 존재하지 않는다.
다만 스레드의 상태를 출력했을 때 실행 중에 RUNNABLE 이 찍힌다.- 그 이유는 멀티태스킹에 의해 스레드가 잘게 쪼개져 실행<->실행대기를 계속 반복 하여 RUNNABLE 상태가 출력되는 것이다.
Thread Context switching
-
스레드 컨텍스트 스위칭은 멀티스레딩 환경에서 스레드 간의 실행을 전환하는 기술이다.
-
프로세스 컨텍스트 스위칭은 한 프로세스에서 다른 프로세스로 전환할 때 발생하는 과정을 말하면,
스레드 컨텍스트 스위칭은 한 프로세스 안에서 스레드들을 교환한다.
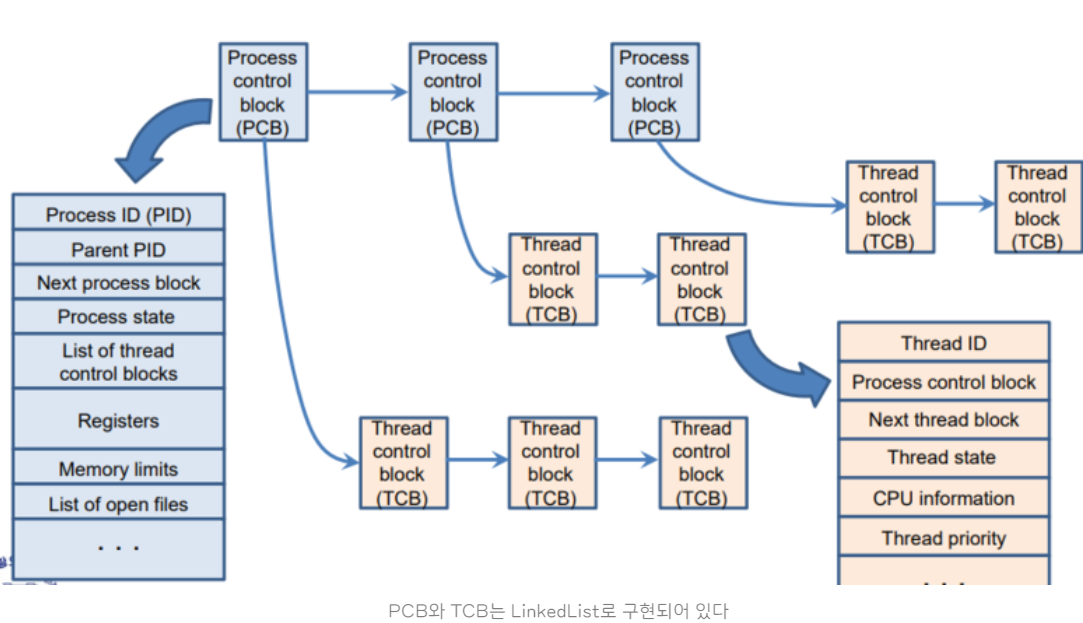
TCB (Thread Control Block)
-
PCB 처럼, TCB 는 각 스레드마다 OS 에서 유지하는 스레드에 대한 정보를 담고 있는 자료구조이다.
-
TCB 는 PCB 안에 들어가 있고, PCB 와 TCB 는 LinkedList 로 구현되어 있다.
-
스레드의 상태정보 , ID , 우선순위 , 스케쥴링 정보 등 다양한 정보를 저장한다.
-
TCB 도 PCB 와 같이 스레드가 생성될 때 OS 에 의해 생성이 되며 스레드의 소멸 시 함께 소멸한다.
-
또한 스레드 간의 자원 공유와 동기화도 TCB 를 사용하여 관리된다.
예를 들어, 뮤텍스나 세마포어와 같은 동기화 기법을 사용할 때, TCB 에서 해당 스레드의 뮤텍스나 세마포어 정보를 관리하고, 스레드가 해당 자원에 대한 접근 권한을 획득하거나 반납할 때 TCB 의 정보를 업데이트하게 된다.
- 임계영역 ( Critical Section ) : 멀티 스레드 프로그래밍에서 임계영역은 공유 자원을 접근하는 코드 영역을 말한다.
(ex) 전역 변수 , heap 메모리 영역 등...- 뮤텍스 ( mutex ) : 임계 구역에 1개의 스레드만 들어갈 수 있는 동기화 기법
- 세마포어 ( semaphore ) : 임계 구역에 여러 스레드가 들어갈 수 있고, counter 를 두어서 허용 가능한 스레드를 제한하는 기법
Process context switching vs Thread context switching
1. TCB 가 PCB 보다 가볍다
프로세스 내 스레드들은 TEXT/CODE , DATA , HEAP 영역 메모리를 공유하기 때문에 TCB 에는 STACK 및 간단한 Register 포인트 정보만을 저장하기 때문에 PCB 보다 더 빨리 읽고 쓸 수 있다.
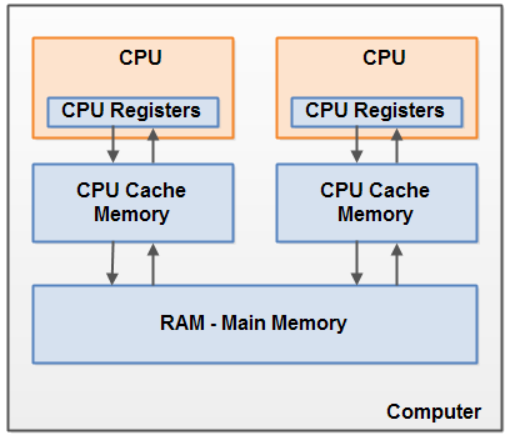
2. 캐시 메모리 초기화 여부
-
CPU Cache Memory 는 CPU 와 메인 메모리 사이에 위치해있다.
-
CPU 에서 한 번 이상 읽어들인 메모리의 데이터를 저장하고 있다가,
CPU 가 다시 그 메모리에 저장된 데이터를 요구할 때,
메인 메모리를 통하지 않고 곧바로 데이터를 전달해 주는 용도이다. -
그런데 Process Context Switching 일 경우, CPU 가 새로운 명령어와 데이터를 로드해야 하기 때문에 CPU 캐시 메모리를 초기화한다.
-
Thread Context Switching 일 경우, 프로세스 내 스택과 레지스터 값 등 일부 정보만 변경되므로 CPU 캐시 메모리는 초기화되지 않는다.
-
이로 인해 스레드 스위칭이 프로세스 스위칭보다 가벼워 훨씬 빠르고 좋다.
-
다만 Thread 가 다른 CPU 코어에서 실행될 경우에는 초기화 될 수 있다.
( 다른 CPU 코어의 캐시 메모리에 TCB 가 로드되어야 하므로 )
3. 자원 동기화 문제
-
Thread Context Switching 이 발생해 다른 스레드가 heap 영역의 공유 데이터에 접근할 때, 이전 스레드가 그 자원을 사용하고 있는 경우에 동기화 문제가 발생할 수 있다.
-
프로세스는 기본적으로 독립된 공간이지만 IPC 와 같은 공유 자원을 사용하는 경우에 똑같은 문제가 발생할 수 있다.
-
따라서 이들을 해결하기 위해서 적절한 공유 자원에 대한 동기화 메커니즘이 필요해진다.
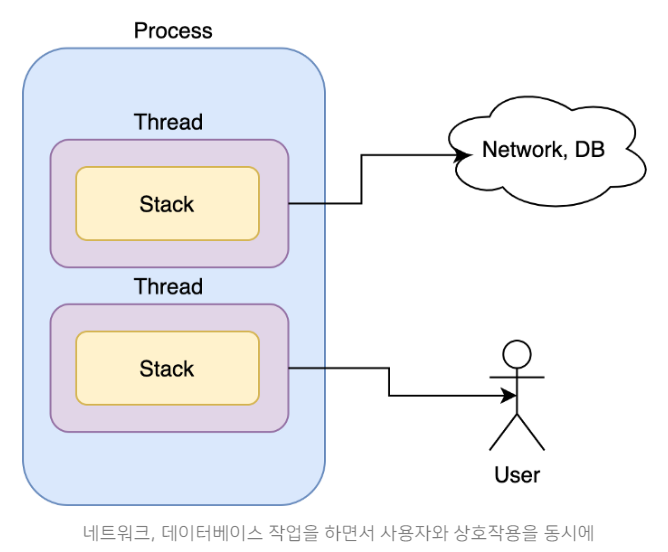
멀티 스레드 (Multi Thread)
-
하나의 프로세스 안에 여러 개의 스레드가 있어 하나의 프로그램에서 두가지 이상의 동작을 동시에 처리하는 것이 가능하다.
-
웹 서버는 대표적인 멀티스레드 응용 프로그램이다.
멀티스레드를 이용하여 네트워크, 데이터베이스 작업을 하면서 동시에 사용자와 상호작용을 할 수 있다. -
하나의 스레드가 지연되더라도, 다른 스레드는 작업을 지속할 수 있다.
-
멀티 프로세스는 웹 브라우저에서 여러 탭이나 여러 창이라면,
멀티 스레드는 단일 탭/창에서 브라우저 이벤트 루프, 네트워크 처리, I/O 및 기타 작업을 관리하고 처리하는데 사용한다.
멀티 스레드의 장점
-
OS 는 멀티 프로세싱을 지원하고 있지만 멀티 스레딩을 기본으로 하고 있다.
-
왜 멀티 프로세스보다 멀티 스레드로 프로그램을 돌리는 것이 유리할까?
1. 프로세스보다 가벼움
- 스레드는 프로세스보다 용량이 가볍다.
프로세스 내에서 스레드가 생성되기 때문에 스레드의 실행 환경을 설정하는 작업이 매우 간단해 생성 및 종료가 빠르다.
또 스택 영역을 제외한 나머지 자원을 서로 공유하기 때문에 내장되어있는 데이터 용량이 더 작다.
2. 자원의 효율성
- 멀티 스레드는 스택 영역을 제외한 나머지 영역의 메모리를 공유한다.
반면 프로세스는 통신 ( IPC ) 을 이용해 자원을 공유하기 때문에 CPU 캐시 메모리 초기화 등 자원 부담이 크다.
3. Context Switching 비용 감소
- 스레드에도 Context Switching Overhead 가 존재한다.
- 하지만 프로세스 스위칭은 CPU 캐시 메모리 초기화, 적재 등의 높은 오버헤드 비용이 드는 반면 스레드 스위칭은 스레드 정보 ( stack , register ) 만 교체하면 되므로 오버헤드 비용이 상대적으로 낮다.
4. 응답 시간 단축
- 앞선 장점들을 종합하면 멀티스레드는 멀티프로세스보다 요청을 더 빨리 처리할 수 있으므로 응답시간이 빠를 수 밖에 없다.
- 이러한 이유로 멀티 프로세서 환경에서 멀티 스레드를 이용하여 작업을 처리하는 것이 멀티 프로세스를 사용하는 것보다 더 효율적이라고 말할 수 있다.
멀티 스레드의 단점
1. 안정성
- 멀티 프로세스는 각 프로세스가 독립적인 메모리에 저장되기 때문에 프로세스간에 영향을 받지 않는다. 그래서 하나가 죽어도 다른 것들은 동작을 할 수 있다.
- 하지만 멀티 스레드에서는 하나의 스레드가 문제가 생기면 다른 스레드들도 영향을 받아 프로그램이 종료될 수 있다.
- 이는 프로그래머의 역량에 따라 극복할 수 있지만 이때 추가 비용이 발생한다.
스레드 에러 발생 시 예외 처리를 적절하게 해주거나, 에러 발생 시 새로운 스레드를 생성하거나, 스레드 풀에서 잔여 스레드를 가져오던지 하여 프로그램 종료를 방지할 수 있다.
2. 동기화로 인한 성능 저하
- 스레드들이 공유 자원에 동시 접근하면 동기화 문제가 발생할 수 있다.
- 따라서 스레드 간 동기화(syncronized) 는 데이터 접근을 제어하기 위한 필수적인 기술이다.
- 그러나 동기화 작업은 여러 스레드 접근을 제한하기 때문에 병목현상이 일어나 성능이 저하될 가능성이 높다는 단점이 있다.
- 이를 해결하기 위해 임계영역(Critical Section) 에 대하여 뮤텍스, 세포어 방식을 활용한다.
임계영역, 뮤텍스, 세마포어는 위에 간단히 적어놨지만 이후에 자세히 알아보도록 하자...
3. Dead Lock ( 교착상태 )
- 다수의 프로세스나 스레드가 서로 자원을 점유하고 다른 프로세스나 스레드가 점유한 자원을 기다리는 상황에서 발생하는 교착 상태를 데드락이라고 한다.
- 다수의 스레드가 같은 lock 을 동시에 다른 명령에 의해 획득하려고 할 때 서로 절대 불가능한 일을 계속적으로 기다리는 무한루프와 같은 현상이 일어난다.
예를 들어 자원A 를 점유한 스레드A 가 자원B 가 필요하고
자원B 를 점유한 스레드B 가 자원A 가 필요한 상황이라고 가정해보자.
스레드 A는 자원B가 필요하지만 스레드B가 자원B를 점유하고 있고
스레드 B는 자원A가 필요하지만 스레드A가 자원A를 점유하고 있어서
서로 자원을 빌려줄 수 없는 상황이 된다.
이 때 발생하는 것이 Dead-Lock 교착 상태인 것이다.
- 이러한 현상은 스레드의 특징인 공유자원에 대한 동시 엑세스로 인한 문제로,
이를 방지하기 위한 상호배제(Mutual Exclusion), 점유와 대기(Hold and Wait), 비선점(No Preemption), 순환 대기(Circular Wait)와 같은 여러 알고리즘을 통해 극복해야 한다. - 다만 멀티 프로세스도 IPC 를 통해 공유자원을 사용할 수 있기 때문에 똑같이 교착 상태에 빠질 수 있다. 결국 둘 모두의 문제이다.
4. Context Switching Overhead
- 멀티 프로세스보다 유리하더라도 오버헤드 비용 자체를 무시할 수는 없다.
스레드 수가 많으면 많을 수록 스위칭도 많아져 이는 성능 저하로 이어진다. - 이러한 부분은 스레드를 많이 쓰는 것이 항상 성능이 좋은 지에 대한 의문을 제기한다.
5. 디버깅이 어려움
- 멀티 스레드를 이용하면 여러 개의 스레드가 동시에 실행되기 때문에 각 스레드의 동작을 추적하기 어려울 수 있다.
- 예를 들어 코드를 디버깅하는 중 다른 스레드가 실행되어 예기치 않은 결과를 발생할 수 있다.
또 어떤 스레드가 어떤 자원에 접근하고 어떤 순서로 실행되는지 등 파악하기 어려울 수도 있다. - 따라서 스레드간의 상호작용과 동기화 기법을 잘 이해하고, 디버깅 도구를 적극적으로 활용해야 한다.
