
Thread
요약
- 모든 프로세스는 최소한 하나의 스레드를 가지고 있다.
- 우리가 사용하는 대부분의 스레드는 멀티스레드 이다.
- 멀티프로세스보다 멀티스레드 사용이 더 효율적이다.
- 멀티스레드는 프로세스의 stack 영역 외에 자원 공유가 가능하다.
- 안정성 , 동기화 , 교착상태 , 스레드의 효율분배 등을 잘 고려해야 한다.
- JVM 은 프로그램 시작점임 main 메서드를 찾아 main 스레드를 생성하고 실행한다
- 이제 스레드를 생성하고 사용해보자.
Thread / Runnable
Thread 클래스


- Thread 클래스를 상속받는 WorkThread 클래스를 생성한다.
- run( ) 메서드를 오버라이드하여 실행할 내용을 적는다.
Thread 클래스는 일반클래스이기 때문에 run( ) 메서드가 필수 작성이 아니므로 주의
- 만든 WorkThread 워크스레드 클래스는 main 메서드에서 객체로 가져온다.
- start( ) 메서드로 실행시킨다.
이 때 start( ) 로 인해 실행준비상태에 들어간 것이다.
만약 여러 스레드 객체에 start( ) 메서드를 호출하면 코드 작성 순서와는 상관 없이 OS 의 스레드 스케쥴링에 의해 순서가 정해져 run( ) 안의 내용이 실행된다. - Thread 클래스는 익명객체로도 사용이 가능하다.
Runnable 인터페이스

- Runnable 인터페이스를 구현받는 WorkThread 클래스를 생성한다.
- run( ) 추상메서드가 강제로 오버라이드되어 실행할 내용을 적는다.
- WorkThread 워크스레드 클래스는 main 메서드에서 객체로 가져온다.
- Thread 객체 생성 후 매개변수로 넣는다.
Thread 객체가 있어야 스레드 생성이 된다.
이때 new Thread(Runnable r) 로 다형성에 의해 Runnable 인터페이스가 구현된 클래스들은 매개변수로 들어갈 수 있다. - start( ) 메서드로 실행시킨다.
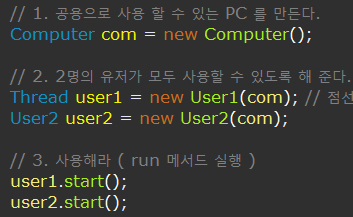
- Runnable 인터페이스는 익명객체로도 사용이 가능하다.
Runnable 사용 이유
- 보기에는 Thread 클래스를 사용 하는 것이 더 편리해 보인다.
- 그럼에도 Runnable 사용 이유는 Thread 클래스는 단일 상속밖에 되지 않기 때문이다.
- Runnable 은 인터페이스이기 때문에 다중구현이 가능하다.
- 따라서 여러가지를 상속받거나 구현받아야 할 경우에는 Runnable 을 사용한다.
스레드 Stack 영역 생성 원리
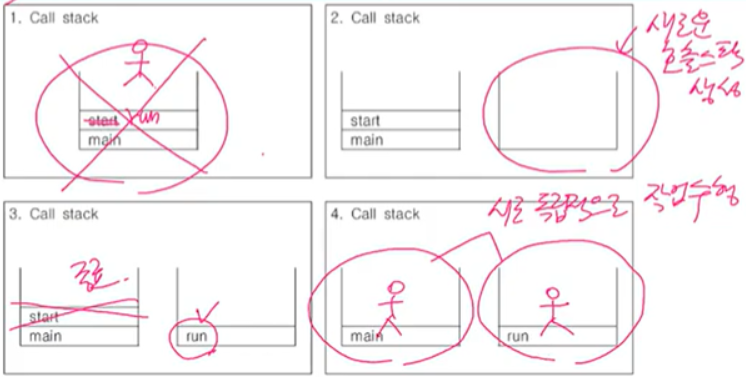
- JVM 에 의해 main 스레드 생성 후 main 메서드가 위로 올라가고 그 위로 스레드 객체의 start( ) 메서드가 호출된다.
- start( ) 메서드가 호출되면 새로운 호출 스택을 생성한다.
- 새로운 호출 스택에 해당 스레드 객체의 run( ) 메서드를 올린다
- start( ) 는 종료되어 스택 밖으로 빠져나간다
- 각각의 호출 스택에 main 메서드와 run( ) 메서드가 남고 서로 독립적인 작업을 수행한다.
스레드는 stack 영역에서 독립적으로 작업을 수행하기 때문에 main 메서드가 완료가 되도 다른 스레드는 자기 할 일이 끝나야 소멸한다.
Thread 제어
- 스레드를 사용하면 순서가 뒤죽박죽이다.
- 스레드는 OS 의 스레드 스케쥴링에 의해 움직이므로 원하는 순서나 실행 시간 등을 제어할 수 없다.
스레드 스케쥴링 알고리즘은 RR(Round Robin) , Priority-based scheduling , Multi-level Queue scheduling 등이 있다.
- 그래서 먼저 시작했다고 해서 먼저 끝나지 않는다.
- 이런 Thread 를 제어하기 위한 방법들이 필요하다
동기화(synchronized)
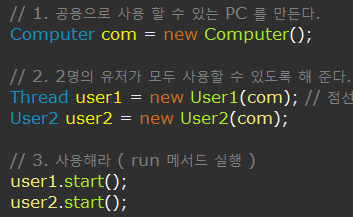
가령 공동 PC를 만들어 스레드 user1 , user2 가 동시에 사용한다고 가정해보자.
PC 의 하는 일은 사용자가 만든 점수를 저장하고 2초 동안 해당 작업자가 sleep() 상태를 가진 후 자신의 점수를 확인할 수 있도록 하는 것이다.
그리고 user1 의 점수는 500 / user2 의 점수는 100 이다.
- 메서드가 실행됬을 때 user1 이 랜덤으로 먼저 PC 에 접근해 점수를 500 으로 저장해놓고 2초간 잠에 든다.
- 그 사이 user2 가 PC에 들어와 점수를 100 점으로 저장해놓고 2초간 잠에 든다.
- 그 사이 user1 이 깨어나 자신의 점수가 몇 점인지 학인한다. --> 100점 출력
- 남은 user2 도 깨어나 자신의 점수가 몇 점인지 확인한다 --> 100점 출력
결국 user1 의 점수와 user2 의 점수가 100점이 나오는 불상사가 일어난다.
- 스레드는 stack 영역을 제외한 나머지 메모리를 공유하기 때문에 객체 간의 간섭이 일어날 수 있다.
- 즉, 내가 사용하고 있는 데이터를 누군가 사용하여 값에 변화가 생길 수 있다는 것이다.
- 이런 불상사를 대비하기 위해 내 작업이 끝나기 전에 접근을 막아야 한다.
- 이렇게 접근을 막는 방식을 동기화(synchronized) 라고 부른다.
임계 영역 (Critical Section)
-
공유되는 자원, 즉 동시 접근하려고 하는 자원에서 문제가 발생하지 않게 독점을 보장해줘야 하는 영역을 임계영역이라고 한다.
-
어떤 스레드가 객체의 lock 을 가지고있으면 다른 스레드는 그 객체의 임계영역에 들어갈 수 없다.
( 한 객체는 하나의 lock 을 가지고 있다 )
동기화 방법
- 동기화 하는 객체의 변수는 private 로 설정해주어야 한다.
다른 스레드가 직접 건드릴 수 있는 변수라면 동기화의 의미가 없기 때문이다. - 그래서 getter/setter 메서드에도 sysnchronized 키워드를 붙이는 것이 좋다.
( 값을 넣고 불러오는 동안 값이 변경되면 안되기 때문이다 )
1. 메서드 전체를 임계 영역으로 지정 - 동기화 메서드
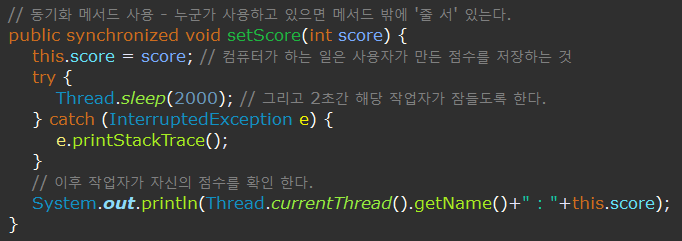
- 메서드에 sysnchronized 키워드를 건다.
- 임계 영역이 많을 수록 병목현상과 동시작업 진행의 어려움으로 인해 성능이 떨어지므로 영역과 개수를 최소화하는 것이 좋다.
2. 특정 영역을 임계 영역으로 지정 - 동기화 블록
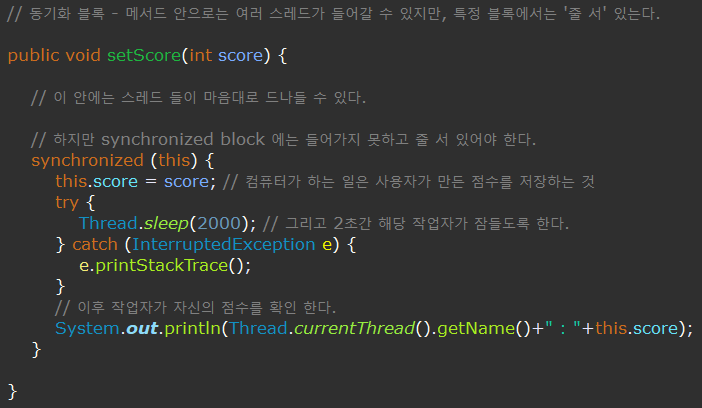
- sysnchronized ( 객체의 참조변수 ) { ... } 를 사용한다.
sysnchronized(this){...} 로 많이 사용
- 메서드 안에 블록을 생성하면 해당 메서드 안에는 여러 스레드가 동시에 입장이 가능하지만, 특정 블록에서는 '줄 서' 있도록 한다.
동기화로 인한 성능 저하 문제
- 스레드 간의 동기화(syncronized) 는 데이터 접근을 제어하기 위한 필수적인 기술이다.
- 하지만 동기화 작업은 여러 스레드 접근을 제한하기 때문에 병목현상이 일어나 성능이 저하될 가능성이 높다는 단점이 있다.
- 이를 해결하기 위해 임계영역 에 대하여 뮤텍스, 세마포어 방식을 활용한다.
뮤텍스 (Mutex)
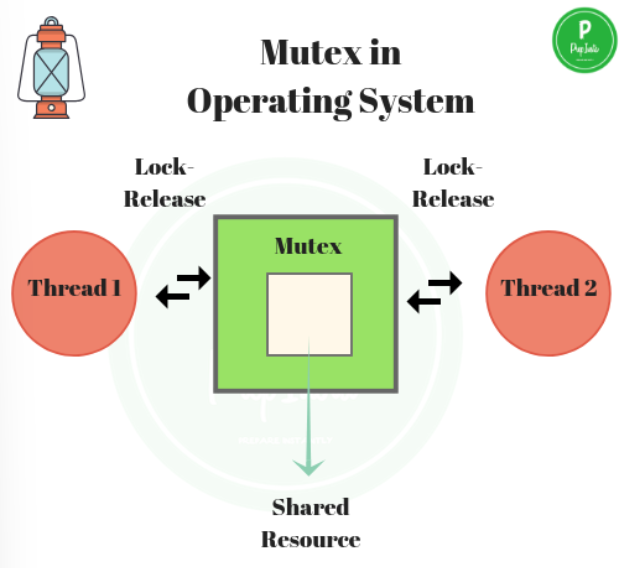
- 공유 자원에 대한 접근을 제어하기 위한 상호 배제 기법 중 하나.
- 임계 영역에 진입하기 전 락(lock) 을 획득하고,
임계 영역을 빠져나올 땐 락(lock) 을 해제하여 다른 스레드들이 접근할 수 있도록 한다. - 오직 1개의 스레드만이 공유 자원에 접근할 수 있도록 제어하는 기법이다.
- 그래서 Mutex 는 동기화 대상이 1개 일 때 사용한다.
세마포어 (Semaphore)
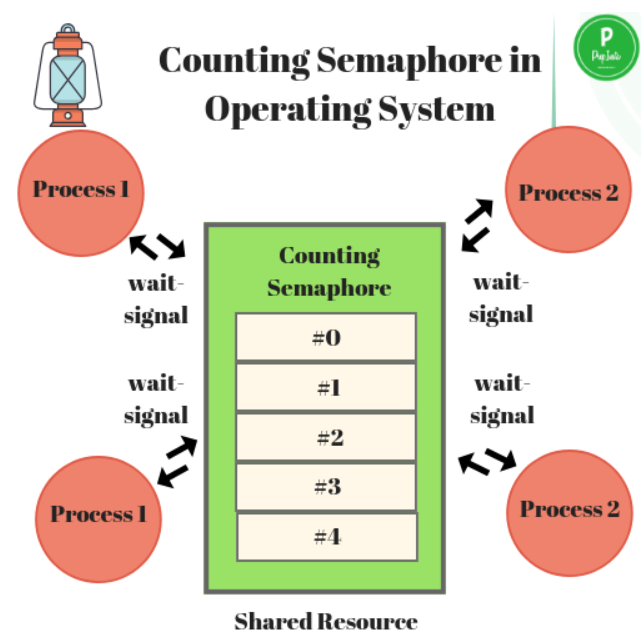
- 공유 자원에 대한 접근을 제어하기 위한 상호 배제 기법 중 하나.
- 세마포어는 카운터 ( Counter ) 를 이용하여 동시에 자원에 접근할 수 있는 프로세스 개수를 제한한다.
- 공유자원에 접근할 수 있는 프로세스 , 스레드의 최대 허용치 ( Counter 수 ) 만큼 접근이 가능하다.
- 임계 영역에 진입하기 전 세마포어의 값을 확인하고, 값이 허용된 범위 내에 있을 때만 락(lock) 을 획득한 후 세마포어의 카운터 값을 변경한다.
- Semaphore 는 동기화 대상이 1개 이상일 때 주로 사용한다.
뮤텍스와 세마포어의 차이
-
세마포어의 카운터가 1이면 뮤텍스와 역할이 동일하여 뮤텍스가 될 수 있지만 반대는 안된다.
-
뮤텍스는 자원을 소유할 수 있고 그 책임을 가진다.
반면 세마포어는 자원 소유가 불가능하다. -
뮤텍스는 상태가 0,1 뿐이므로 Lock 을 가질 수 있고, 소유하고 있는 스레드만이 이 뮤텍스의 Lock 을 해제할 수 있다.
반면 세마포어는 소유하지 않은 스레드도 해제할 수 있다. -
세마포어는 시스템 범위에 걸쳐 있고, 파일 시스템 상의 파일로 존재한다.
뮤텍스는 프로세스 범위를 가지고 있고 프로세스가 종료될 때 자동으로 Clean up 된다.
wait( ) / notify( ) / notifyAll( )
- 동기화는 한번에 한 스레드만 들어갈 수 있기 때문에 비효율적이다.
- 이러한 동기화의 효율을 높이기 위해 wait( ) , notify( ) 를 사용한다.
- Object 클래스에 정의되어 있으며, synchronized 블록 내에서만 사용이 가능 하다.
wait( )
- wait( ) 메서드의 기능이 객체에 대한 lock 을 해제하여 제어권을 넘겨주는 역할이기 때문에 wait( ) 을 호출하는 스레드가 lock 을 가지고 있지 않으면 에러가 발생한다.
- wait( ) 메서드에 의해 스레드는 waiting pool 에 들어가며 WAITING / TIMED_WAITING 상태로 변한다.
- 이 때 TIMED_WAITING 의 경우 wait(1000) 와 같이 특정 시간을 설정해주면 자동으로 RUNNABLE 상태로 변경된다.
sleep( ) 은 현제 스레드를 잠시 멈추게 할 뿐 lock 을 넘겨주지 않는다.
notify( )
- waiting pool 에서 대기중인 스레드 중 하나를 깨운다.
- 어떤 스레드를 깨울 지는 랜덤이기 때문에 wait( ) 과 notify( ) 는 2 개의 스레드가 번갈아가면서 깨울 때 사용하는게 좋다.
- notify( ) -> wait( ) 순서로 실행하는 것이 좋다.
만약 lock 을 가진 스레드 외에 모든 스레드가 WAITING 상태일 경우 wait( ) 먼저 실행해버리면 모두가 WAITING 상태가 되는 문제가 발생한다.
notifyAll( )
- notify( ) 는 다수의 스레드가 대기 상태 시 랜덤으로 깨우기 때문에 잘못하면 특정 스레드가 계속 대기 상태가 되는 경우가 발생할 수 있다.
- 그래서 notifyAll( ) 은 waiting pool 에서 대기 중인 모든 스레드를 깨운다.
어차피 깨어난 스레드 중 하나만 lock 을 얻어 자신이 wait( ) 가 걸린 지점으로 돌아가고 나머지는 실행할 수 있는 상태를 가지게 될 것이다. 그래서 아예 대기상태로 실행이 못되는 것보다 쓰임이 좋다.
