

알고리즘
💬 정의 : 알고리즘은 문제해결을 위해 정해진 일련의 절차이다.
- 컴퓨터 프로그래밍의 토대이다.
- 일반적으로, 알고리즘은 어떤 종류의 일을 수행하기 위한 명확한 프로세스를 의미한다.
- 컴퓨터 프로그램이란 단순히 컴퓨터가 이해할 수 있게끔 충분히 정밀하게 고안된 언어로 작성한
알고리즘의 명세이다. - 프로그램은 그것의 알고리즘을 함축한다.
프로그래밍 언어
- 익히 알려진 프로그래밍 언어들:
- 최신언어 : Java, C, C++, Visual Basic, JavaScript, Perl, Tcl, Pascal
- 구식언어 : Fortran, Cobol, Lisp, Basic
- low-level 언어 : Assembly language
- 이 챕터에서는 pseudo-code 로 표현함
알고리즘 예시
- Task : 이 주어졌을 때, 주어진 sequence에서 가장 큰 수는?
- 알고리즘
- 임시 변수 를 의 값으로 설정한다.
- sequence 내의 다음 요소 를 참조한다.
- 만약 라면, 임시 변수 를 의 값으로 재할당한다.
- 다음 요소를 봤을 때, sequence에 더 이상 요소가 없을 때까지 2/3단계를 반복한다.
- 를 리턴한다.
알고리즘 실행
- SW를 시작할 때, 우리는 프로그램 or 알고리즘을 실행한다(or 돌린다) 라고 말한다.
- 알고리즘이 있으면, 이를 종이에 써가면서 이를 수행할 수도 있다.
2차 세계대전 이전에, 컴퓨터는 알고리즘을 수행하는 사람을 의미했다..!
알고리즘의 특성
- 알고리즘의 중요한 특성 7가지 :
- 입력 : 들어가는 정보 혹은 데이터
- 출력 : 나오는 정보 혹은 데이터
- 명확함 : 각 단계는 명확하게 정의 되어야 한다.
- 정확성 : 입력 값의 각 집합에 대해 정확한 출력 값 을 만들어야 한다.
- 유한성 : 영원히 실행되면 안된다. (반드시 끝나야 한다.)
- 효율성 : 각 단계는 유한한 시간내에 수행되야 한다.
- 일반성 : 특정한 입력이 아닌 모든 가능한 입력에 대해서 동작해야 한다.
Pseudo-code Language (의사코드 언어)
아래의 코드는 기본적인 의사코드 선언문을 정리한 것이다.
procedure
name(argument: type)
variable := expression
informal statement
begin statements end
{comment}
if condition then
statement [else
statement]
for variable := initial value
to final value
statement
while condition statement
procname(arguments)
Not defined in book:
return expressionprocedure procname(arg: type)
-
다음의 문장들을 선언
- procedure(함수): procname로 명명된 procedure(함수)
- arg: arg로 명명된 arguments(인자)
- type : 자료형
-
예시:
-
procedure maximum(L: list of integers)
[statements defining maximum... ]
-
variable := expression
- 할당문은 표현식(expression)을 계산한다. 그런 다음, 변수(variable)에 결과값을 재할당한다.
- ex) v := 3x+7 ( 만약 변수 x의 값이 2라면, 변수 v를 13으로 바꿈.)
- 의사코드에서 표현식은 비형식적일 수도 있다:
- x := 배열 L에서 가장 큰 정수
informal statement
- "x를 찾는 알고리즘을 기술하라"고 했는데, "find x"라고 하는 것은 충분하지 않다..!
- 알고리즘을 세부적인 단계로 기술해야 한다!!
- 결국, 알고리즘을 쓰고 이를 구현해야 한다.
- 그러나, "swap x and y." 처럼 그 의미가 명확하고 정밀하다면, 이러한 비형식적 선언을 쓸 수도 있다.
begin statements end
아래처럼 선언문들을 묶는 역할을 한다.
begin
statement 1
statement 2
⋯
statement n
end{ comment }
- 아무런 동작도 하지 않는다.
- 인간이 코드를 읽는데 도움이 되도록 설명해주는 것으로,
자연어이다. - 어떤 프로그래밍 언어에서는
remark라고도 불린다
If condition then statement
- 명제적인 표현식으로 나타난 조건(condition) 을 검사한다.
- 만약 조건이 참이라면, 선언문(statement) 을 실행하고, 그렇지 않다면 그냥 스킵하고 다음 선언문으로 넘어간다.
- ex)
if 조건 then 선언문1 else 선언문2에서 조건이 거짓이면, 선언문1을 스킵하고 선언문2로 넘어간다.
while condition statement
-
명제적인 표현식으로 나타난 조건(condition)을 검사한다.
-
만약 조건이 참이라면, 선언문(statement)을 실행한다.
-
조건을 검사했을 때 거짓이 될 때까지 위 두 과정을 계속해서 반복한다; 그 후, 다음 선언문으로 넘어간다.
-
ex) while은 if조건문을 엄청나게 써서 구현할 수도 있다. but, 설마~?
if condition
begin
statement
if condition
begin
statement
⋯(계속 중첩된 if문을 사용)
end
endfor var := initial to final statement
- 초기값(initial)은 정수로 표현.
- 마지막값(final)은 또다른 정수로 표현.
- 처음에 var := initial 을 하여 변수(variable)에 초기값(initial)을 지정한다.
- 그런다음 var := initial+1을 하고, var := initial+2를 하는 것 처럼 이 과정을 계속해서 반복하는데 var := final 까지 반복한다.
- for은 아래처럼 while문으로 대체될 수 있다.
begin
variable := initial
while variable ≤ final
begin
statement
var := var + 1
end
end procedure(argument)
-
procedure call 선언문은 procedure로 명명된 함수를 call 한다. (단 인자값(argument)를 입력값으로 먼저 준 후에)
-
다양한 프로그래밍 언어들이 procedure를 다음과 같이 부르기도 한다.
- function (procedure call notation이 함수 f(x)와 비슷하게 동작하기 때문에)
- subroutine, subprogram, or method.
-
ex ) 최댓값 찾는 프로시저를 의사코드로 표현
procedure max(a_1,a_2,⋯,a_n: integers)
v := a_1 {지금까지 가장큰 요소로 가정한 a_1}
for i:=2 to n {요소의 나머지들에 대해..}
if a_i > v then v := a_i {더 큰수를 찾았다면??}
{이 시점에서 변수v의 값은 리스트 중 가장큰 정수값일 것이다.}
return v알고리즘의 창조
- 엄청난 창의성과 직관을 요한다.
- 마치 수학에서의 증명하는 것과 같이..
- 알고리즘을 창조하는 알고리즘 따위는 없다.
- 그저 많은 예를 보고,
- 컴퓨터로 많은 연습을 하고,
- 더 많은 예를 보고,
- 좀 더 많은 연습을 하는 수 밖에 없다.
Searching Algorithm
- 정렬된 리스트에서 주어진 값을 찾아내는, 검색을 수행하는 문제.
- 알파벳, 숫자같이 명확하게 정렬된, n개의 요소를 가진 리스트 L이 주어지고,
- 특정 요소 x도 주어지고,
- x가 주어진 리스트 L에 있는지 없는지 결정한다.
- 만약 있다면, 리스트에서 그것의 인덱스(위치)를 반환한다.
- 프로그래밍을 하는 한 수십 번 이상 마주치는 문제이다..!
- 효율적인 알고리즘을 찾아보자 !
- Linear Search
-
리스트의 첫 번째 요소부터 차례대로 검색하는 방법
-
ex) Find '12' in {3, 6, 9, 12, 15, 18, 21, 24}
procedure linear search
(x: 찾을 정수, a_1, a_2, ⋯, a_n : 서로 다른 정수)
i := 1
while (i≤n ∧ x≠a_i)
i := i+1
if i≤n then index := i
else index := 0
return index {찾은 인덱스 혹은 찾아지지 않은 인덱스 0을 반환}- Linear search는 ordered list뿐만 아니라 unordered list에서도 바르게 동작한다.
- Binary Search
- IDEA: 리스트의 중간에 위치한 값과 비교하여, 작은 값들을 가지는 리스트 혹은 큰 값들을 가지는 리스트 즉, 한쪽 부분에 대해서만 검사를 진행한다.
procedure binary search
(x: 찾을 정수, a_1, a_2, ⋯, a_n : 서로 다른 정수)
i := 1 {왼쪽 끝 지점}
j := n {오른쪽 끝 지점}
while i<j begin {while interval이 한개이상의 요소를 가지고 있는 동안}
m := (i+j)/2 {midpoint}
if x>a_m then i:=m+1 else j:=m
end
if x=a_i then index:=i else index:=0
return index- Binary search는 ordered list에서만 바르게 동작하며 unordered list에서는 바르게 동작하지 않는다.
Sorting Algorithm
-
프로그래밍에서 Search 다음으로 많이 마주치는 문제!
- e.g., spreadsheets, databases ...
-
또한 data-processing 알고리즘에서 subroutine으로서 많이 쓰인다.
-
두가지 쉬운 sorting algorithm
-
Bubble sort
-
Insertion sort
// but, 이 알고리즘은 효율적이지 않으므로, 큰 데이터에 대해서는 사용하지 않아야 함!
-
-
15가지 이상의 sorting algorithms이 존재
- "The Art of Computer Programming" by Donald Knuth 참조
- Bubble Sort
- Sort L = {3, 2, 4, 1, 5}
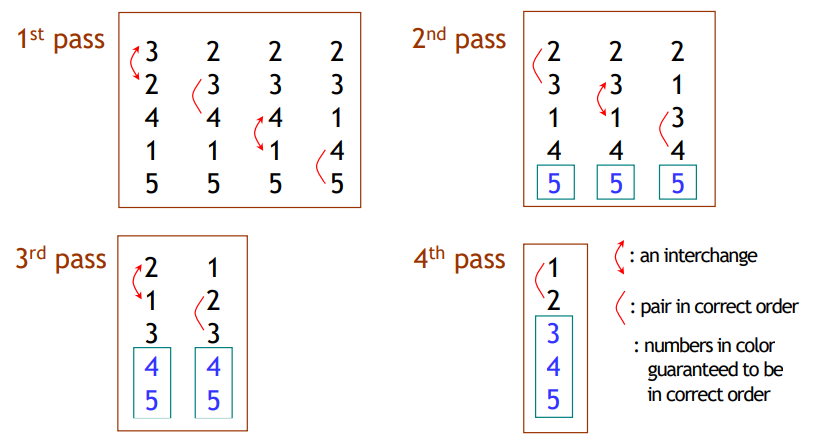
procedure bubble sort(a_1, a_2, ⋯, a_n : 2이상의 정수)
for i:=1 to n-1
for j:=1 to n-i
if a_j>a_j+1 then swap a_j and a_j+1
{a_1, a_2, ⋯, a_n 는 오름차순 정렬.}- Insertion Sort
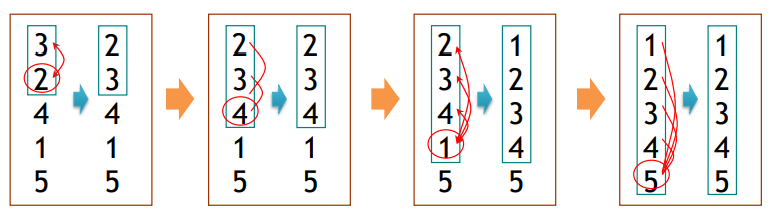
procedure insertion sort(a_1,a_2,⋯,a_n: real numbers with n≥2)
for j:=2 to n
i:=1
while a_j>a_i {a_j의 적절한 index를 찾을 것}
i:=i+1
m := a_j {m에 임시저장}
for k:=0 to j-i-1 {a_j를 적절한 위치에 삽입}
a_j-k := a_j-k-1 {swap}
a_i := m
{a_1,a_2,⋯,a_n 는 오름차순 정렬}Greedy Algorithm
- 가능한 모든 입력값에 대해 최선의 선택을 하는 알고리즘.
- 많은 알고리즘(prim, kruskal⋯ ) 중 우리는 이러한 것들을 공부할 것임:
- 두개의 도시간 가장 적은 비용(최단 경로)이 드는 경로를 찾을 때
- 가능한 한 가장 적은 비트를 이용하는 인코딩 방식을 결정할 때
- 네트워크 노드간 가장 적은 광케이블을 사용하기 위한 광케이블 링크를 찾을 때
- 최적의 문제는 각 단계마다 최선의 선택을 하는 Greedy algorithm으로 풀 수가 있다.
- Greedy Algorithm: 거스름 돈 문제
-
e.g., 아래의 동전으로 구성된 n cents의 거스름 돈에 대한 greedy algorithm을 디자인하시오:
-
quarters (25 cents), dimes (10 cents), nickels (5 cents), and pennies (1 cent)
에 대해 어떻게 해야 가장 적은 갯수의 동전(최소 동전의 수)을 거슬러 줄 것인가?
-
-
IDEA : 각 단계마다 거스름 돈(즉, 거슬러 주어야 하는 돈)을 초과하지 않으면서 가능한 한 가장 큰 값어치를 가지는 동전을 선택한다.
- 만약 n=67 cents라면, 처음에 1 quarter를 고른다.( 67-25 = 42cents ) 그다음 또 1 quarter를 고른다. ( 42-25 = 17cents )
- 그런 다음 1 dime을 고른다. ( 17-10 = 7cents )
- 1 nickel을 고른다. ( 7-5 = 2cents )
- 1 penny을 고른다. ( 2-1 = 1cent ) 또 1 penny를 고른다. ( 1-1 = 0cent )
-
Solution : n cents의 거스름돈에 대한 greedy algorithm. 이 알고리즘은 로 명명된 어느 동전에 대하여 동작한다.
procedure change(c_1,c_2,⋯,c_r: 코인의 종류. 단, c_1>c_2>⋯>c_r; n: 양의정수)
{c_1: quarters, c_2: dimes, c_3: nickels, c_4: pennies}
for i:=1 to r {코인의 종류 큰 것부터 작은것으로..}
d_i := 0 {d_i는 c_i 코인의 개수를 센다.}
while n≥c_i
d_i := d_i+1 {c_i 코인의 총 갯수에 1개를 더한다.}
n = n-c_i