0x01. JOIN에 대해서
LEFT JOIN, RIGHT JOIN은 굴러온돌이 박힌돌에 연결. INNER JOIN은 쌩처음부터 상호합의하에 연결
그냥 JOIN은 Cartesian Product
JOIN ON VS JOIN WHERE : https://blog.leocat.kr/notes/2017/07/28/sql-join-on-vs-where
1.1 foreign key의 개념
반드시 Chapter 3. 관계형 데이터 모델 & DB Sample의 1.6 참조 무결성 제약(외래키)를 이해하고 이 CHAPTER를 보자 !!
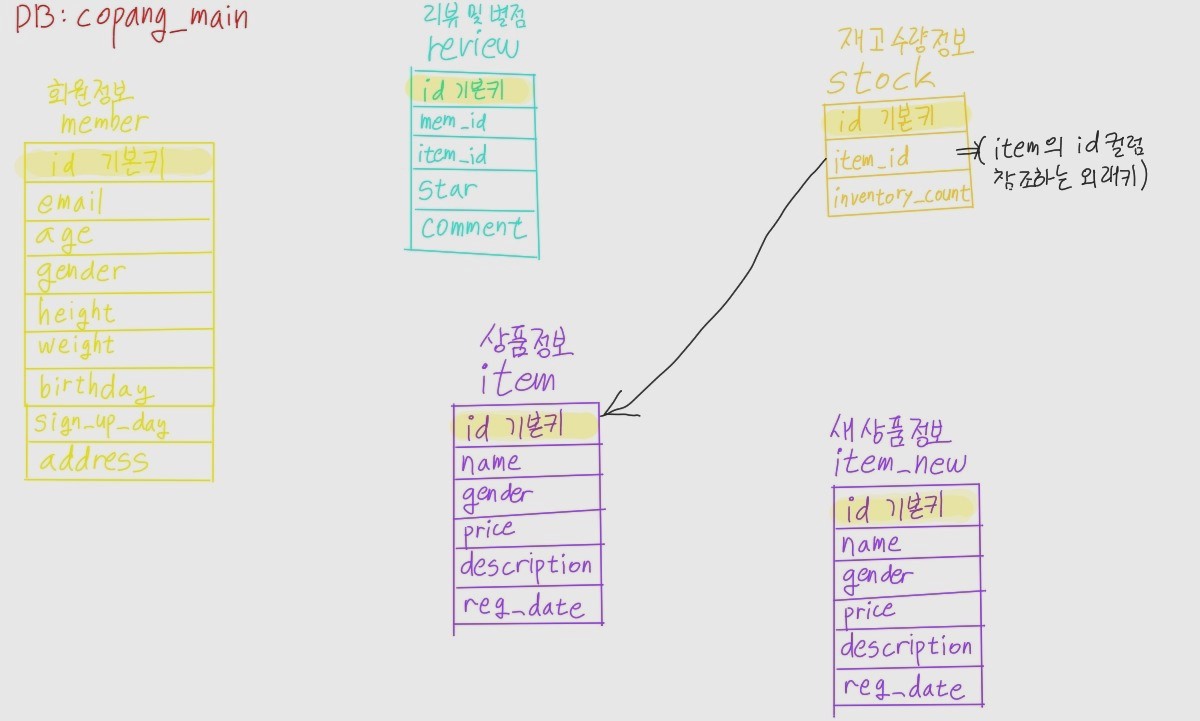
-
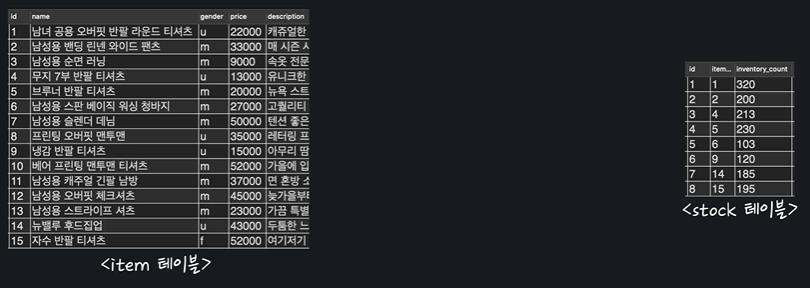
item 테이블(상품정보)
- primary key: id (int){이 컬럼의 값만 알면 특정 상품을 바로 찾을 수 있다}
- name(text, 상품이름)
- gender(text, 성별 m/f/u)
- price(int, 가격)
- description(text, 설명)
- registration_date(date, 상품등록일자)
-
stock 테이블(재고 및 수량정보)
- primary key : id (int) {이 컬럼의 값만 알면 특정 상품을 바로 찾을 수 있다}
- item_id(int, 어떤상품의 재고 수인지 나타내는 상품 id)
- inventory_count(int, 상품의 재고 수)
-
item_new 테이블(새 상품정보)
- primary key: id (int) {이 컬럼의 값만 알면 특정 상품을 바로 찾을 수 있다}
- name(text, 상품이름)
- gender(text, 성별 m/f/u)
- price(int, 가격)
- description(text, 설명)
- registration_date(date, 상품등록일자)
-
review 테이블(상품 구매 후 남긴 리뷰 정보)
- primary key: id (int) {이 컬럼의 값만 알면 특정 상품을 바로 찾을 수 있다}
- mem_id(int, 사용자 id)
- item_id(int, 어떤상품의 재고 수인지 나타내는 상품 id)
- star(int, 별점)
- comment(text, 리뷰)
Stock 테이블의 item_id는 특정상품을 식별하기 위한 컬럼인데, 그러기 위해서는 item_id에 item 테이블의 id 값이 들어가야 한다.
Chapter 3에서 다른 테이블의 특정 row를 식별할 수 있게 해주는 컬럼은 foreign key임을 이미 배웠다. 즉 여기서 item_id는 foreign key로 두어야하는데, 이제부터 foreign key를 설정하는 방법을 아래에서 배울 것이다.
즉, 의미론적으로 서술하면 "item의 id 컬럼과 stock의 item_id는 서로 관계가 있다" 는 것이다. (또한, item.id컬럼은 부모, stock.item_id는 자식인 관계에 있다. 즉, 자식은 부모에 종속된다.)
집합 A와 집합 B가 있을 때, A ⊂ B의 관계에 있는 것이다!!
이렇게 관계를 나타낼 때는 Chapter 3에서도 말했듯이 foreign key(외래키)를 사용한다.
외래키를 설정하는 방법은 다음과 같다:
### 테이블 생성과 동시에 외래키 설정
CREATE TABLE [테이블명] (
...
...
...
[컬럼명] [데이터형식] FOREIGN KEY REFERENCES [테이블명] ([컬럼명])
/* ex) ParentID INT FOREIGN KEY REFERENCES Test1(ID) */
)
### 이미 만들어진 테이블의 컬럼에 외래키 설정
ALTER TABLE [테이블명]
ADD CONSTRAINT [FOREIGN KEY명]
FOREIGN KEY ([컬럼명]) REFERENCES [테이블명] ([컬럼명])
/* ex)
ALTER TABLE Reservation ADD CONSTRAINT CustomerID FOREIGN KEY (ID)
REFERENCES Customer (ID);
*/그렇다면 이 관계는 왜 사용할까?
- 첫번째로, 종속된 관계로서 자식이 부모내에 존재하지 않는 값이 들어갔을 때 오류를 방지시켜준다. 즉, 참조하는 컬럼의 값 ⊂ 참조받는 컬럼의 값 이어야 하고 이를 어기면 오류가 난다.
- 두번째로, 이번에 배울 내용의 핵심이자, 다른 테이블의 내용을 참조해야 할 경우에 필요한 JOIN을 위해 자주 사용한다. (자주 사용한다는 뜻이지 외래키를 기준으로 조인을 해야만 한다는 것은 아니다.)
그럼 이제 JOIN을 배워보자.
단, 그냥 JOIN은 두 테이블 간 관계 고려없이 ㅡㅓ그냥 행을 기준으로 합친다. 교차조인(cross join)이라고 한다.
1.2 JOIN의 개념
JOIN : 여러 테이블을 합쳐서 하나의 테이블인 것처럼 보는 행위. 서로 다른 두 테이블간에 어떤 관계가 존재하는 경우 사용.
(1) LEFT OUTER JOIN
바로 사용 예시를 보는게 낫다.
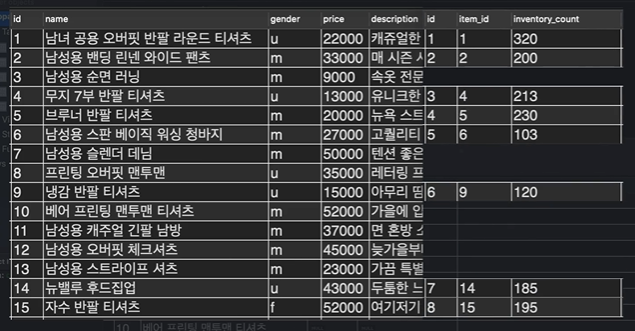
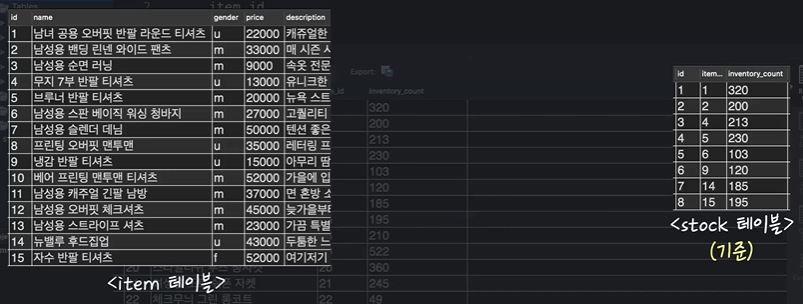
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item LEFT OUTER JOIN stock
ON item.id = stock.item_id위 LEFT OUTER JOIN은 왼쪽 item 테이블에다가 stock 테이블을 합치라는 뜻이다.
But, HOW??? 그 기준은 바로 ON을 기준으로 합친다. 즉, 두 테이블을 합칠 때 item 테이블의 id 컬럼의 값과 stock 테이블의 item_id 컬럼의 값을 비교해서 서로 값이 같은 row끼리 가로 방향으로 연결하라는 뜻이다.
그리고, SELECT문 뒤의
item.id,
item.name,
stock.item_id,
stock.inventory_count
는 JOIN을 해서 생성된 새로운 테이블에서 item 테이블의 id, name 컬럼, stock 테이블의 item_id, inventory_count 컬럼을 보여달라는 뜻이다.
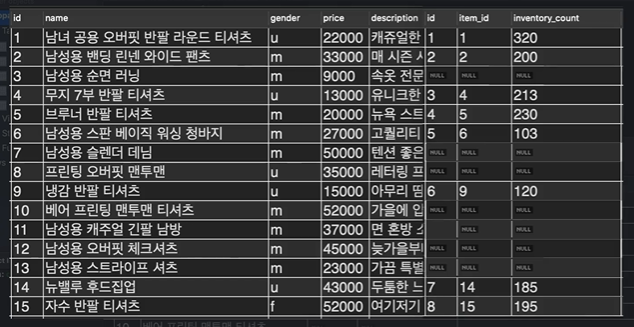
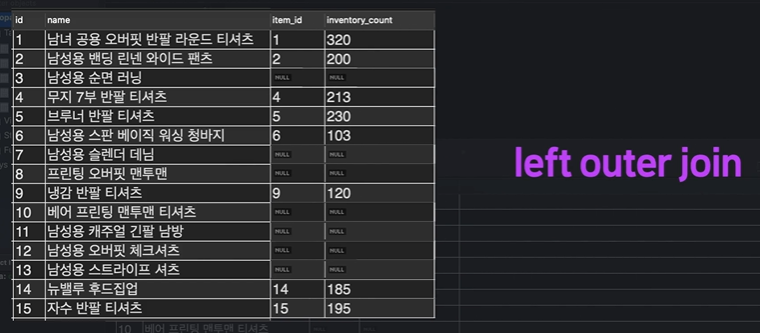
- 실행 결과는 다음과 같다:
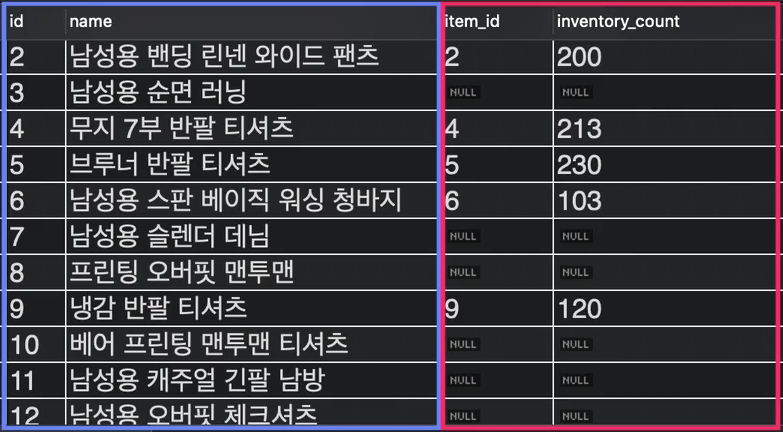
좌측 파란색이 item 테이블, 우측 빨간색이 stock 테이블인데 ON에서 지정해준대로 id의 값과 item_id의 값이 같음을 볼 수가 있다.
그리고 NULL 값도 존재하는데, 이는 자식인 item_id보다 부모인 id가 더 크므로 id에는 있지만 item_id에는 없는 값이 존재하는 것이다.
애니메이션으로 정리해보자.
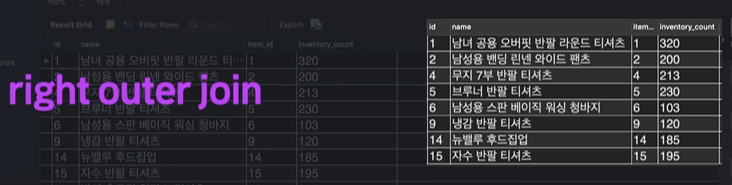
(2) RIGHT OUTER JOIN
오른쪽 테이블 기준으로 합치는 것외에는 LEFT OUTER JOIN과 차이가 전혀 없다.
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item RIGHT OUTER JOIN stock
ON item.id = stock.item_id위 RIGHT OUTER JOIN은 오른쪽 stock 테이블에다가 왼쪽 item 테이블을 합치라는 뜻이다.
결과는 다음과 같다.
모든 row의 id와 item_id가 같다는 점은 LEFT OUTER JOIN과 완전 동일하다.
오른쪽 stock 테이블 기준으로 ON이 적용된다는 사실만 다를 뿐이다.
애니메이션으로 살펴보자.
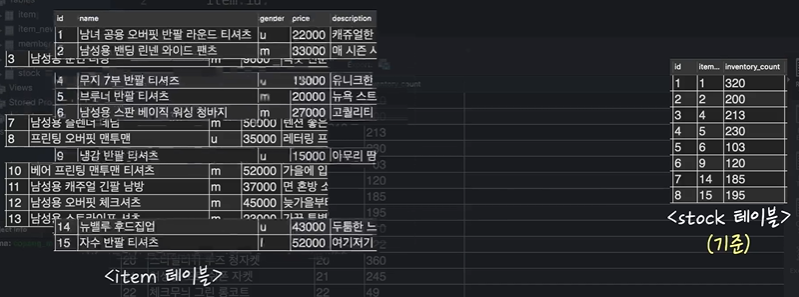
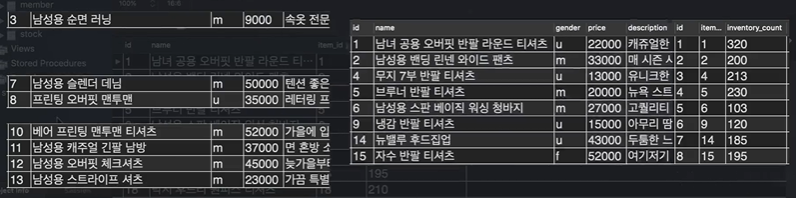
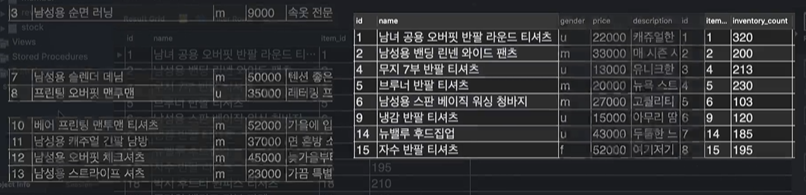
IDEA💡 : JOIN을 합친다고 생각하는 것도 좋지만, 연결한다고 생각하자. LEFT, RIGHT JOIN을 할 경우 기준이 되는 LEFT, RIGHT 테이블은 가만히 있고 거기다가 참조하는 테이블이 기준테이블에다가 연결을 한다고 생각하자.
(3) JOIN할 때 alias 붙이기
컬럼에도 alias를 붙일 수 있었지만, 테이블에도 alias를 줄 수가 있다.
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item AS i RIGHT OUTER JOIN stock AS s
ON item.id = stock.item_id;이렇게 FROM에서 별칭을 주고나면, item테이블은 i로 stock테이블은 s로 가리킬 수가 있다. 다음과 같이 말이다.
SELECT
i.id,
i.name,
s.item_id,
s.inventory_count
FROM item AS i RIGHT OUTER JOIN stock AS s
ON i.id = s.item_id;위 구문과 결과는 완전히 동일하다.
보통 JOIN을 할 때는 alias를 많이 쓰는데 JOIN시에 구문이 길어지므로 조금이라도 보기 편하게 하기 위함이다.
하지만, 두 종류(column, table)의 alias는 약간의 용도 차이가 있다. 일단 컬럼의 alias는 각 컬럼 이름이 실제로 우리에게 그 alias로 변환되어서 보여지게 하기 위한 용도로 쓰인다.
이와 달리 테이블의 alias는 조회 결과에서 보기 위한 게 아니라 SQL 문의 전체 길이를 줄여서 가독성을 높이기 위해 사용된다. 그리고 특히 조인(join)을 할 때, 만약 서로 다른 테이블에 같은 이름의 컬럼이 존재한다면, SQL 문 안에서 그 컬럼을 가리킬 때 무슨 테이블의 컬럼인지를 더 짧게 표현해주기 위해서도 사용된다.
예를 들어, 우리가 배운 member 테이블과 item 테이블에는 둘다 gender라는 컬럼이 있었다.
이때
(1) 전자는 회원의 성별을 나타내기 위한 컬럼이고,
(2) 후자는 상품이 여성용인지 남성용인지, 혹은 남녀공용인지를 나타내기 위한 컬럼인데
이는 우연히도 컬럼 이름이 같은 것이다. 만약 SELECT 절에서 gender 컬럼을 쓰려면 어느 테이블의 컬럼인지를 쉽게 나타내기 위해 테이블에 alias를 붙여주면 좋다.
만약 member 테이블에 m, item 테이블에 i라는 alias를 붙였다면
(1)은 member.gender 대신 m.gender
(2)는 item.gender 대신 i.gender
라고 써주면 된다.
마지막으로 테이블에 alias를 붙였을 때는 주의할 점이 하나 있다.
우리는 FROM 절에서 테이블에 alias를 붙이는데,, 이렇게 한번 alias를 붙였으면, 다른 모든 절에서 그 테이블은 그 alias로만 나타내야 한다는 점이다. 만약 다른 절에서 alias가 아닌 원래의 테이블 이름을 사용하면 오히려 에러가 나게 된다.

(4) INNER JOIN
INNER JOIN : 각 테이블에서 JOIN기준으로 사용된 컬럼들의 일치하는 값이 둘 다 존재하는 row들만 합지는 JOIN이다. LEFT, RIGHT JOIN과 다르게 기준이 되는 테이블이 따로 없다.
단지 두 테이블 모두 기준 컬럼에 일치하는 값이 있는 row들만 합쳐진다.
IDEA💡 : INNER JOIN은 그저 쌩 처음부터 연결한다고 생각하자. 기준이 되는 테이블이 없으므로 아무런 초석없이 처음부터연결을 한다고 생각하자.
쉽게 생각해 두 테이블간에 교집합을 구하는 것과 같다고 생각하면 편하다.
애니메이션을 보자.
item.id컬럼의 값과 stock.item_id컬럼의 값이 같은 row들만 추려서 합침.

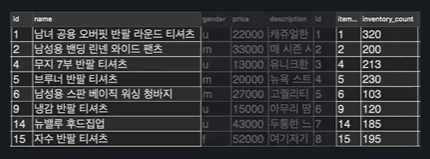
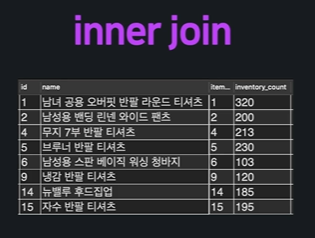
직접 구문을 작성 ㄱㄱ
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item AS i INNER JOIN stock AS s
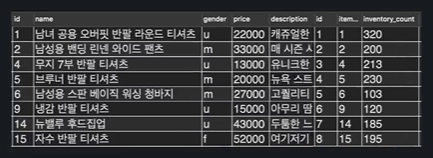
ON item.id = stock.item_id;실행결과 :
실행결과는 RIGHT OUTER JOIN과 동일한데, 조금만 생각해보면 왜 그런지 알 수 있다.
stock의 item_id컬럼의 값은 item의 id컬럼의 값에 포함되어 있으므로 결국 stock.item_id컬럼에 맞춰질 수 밖에 없기 때문이다.
여기서 얻을 수 있는 한가지 사실:
KEY POINT : INNER JOIN은, 외래키가 있는 테이블 기준 JOIN과 같다. 왜냐면 외래키는 어디 종속되는 컬럼이기 때문에 교집합 또한 외래키쪽 테이블이기 때문이다. 컴퓨터 수학을 배웠으면 아래와 비슷하다.
동치종류 법칙 이름 p ∨ T ⇔ T
p ∧ F ⇔ FDomination laws (지배 법칙)
1.3 Foreign key가 아닌 컬럼 기준으로 JOIN 하기
꼭 Foreign Key를 기준으로 조인을 해야만 하는 건 아니다. Foreign Key가 아닌 컬럼을 기준으로 해서 조인할 수도 있다. 그리고 이렇게 하면 보통
(1) LEFT OUTER JOIN
(2) RIGHT OUTER JOIN
(3) INNER JOIN
세 가지 조인의 결과가 모두 달라진다.
잠깐 다음 두 테이블을 보자
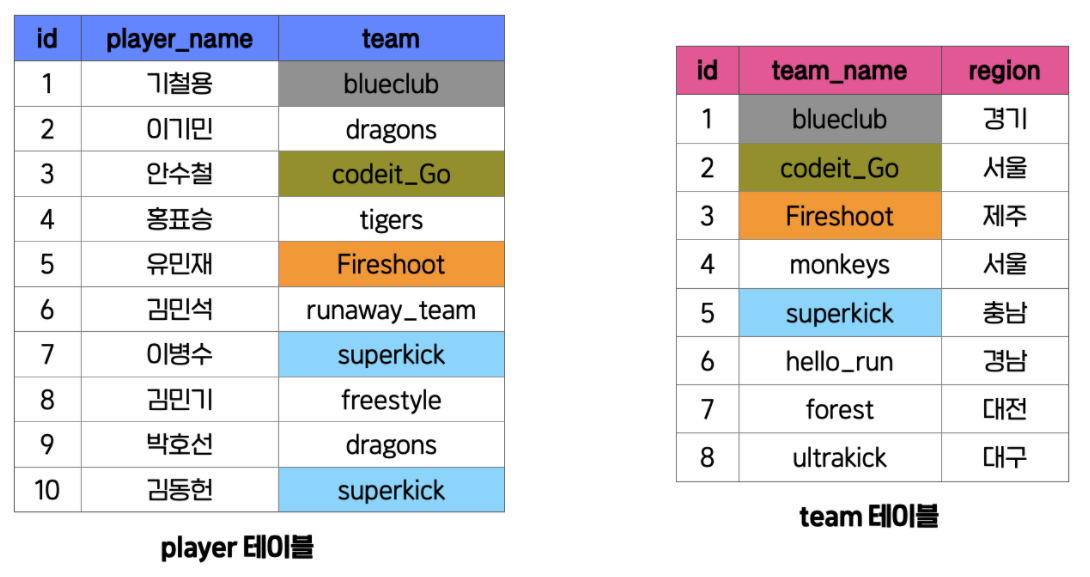
지금 왼쪽의 player 테이블은 축구 선수의 이름과 그 소속팀을 나타내는 테이블이고, 오른쪽의 team 테이블은 각 축구팀이 어느 지역에 속하는지를 나타내는 테이블이다. 지금 player 테이블의 team 컬럼과 team 테이블의 team_name 컬럼이 서로 연관된 컬럼이라는 게 한 눈에 보인다.
하지만 player 테이블의 team 컬럼의 값이 반드시 team 테이블의 team_name 컬럼에 존재하는 것은 아니다. 지금 보면 dragons, tigers, runaway_team, freestyle이라는 팀은 team 테이블에 없다. 그러니까 두 테이블 사이에는 Foreign Key 관계가 없는 것이다. 그래도 조인은 할 수 있다.
Workbench에서 각 테이블의 모습은 다음과 같다.
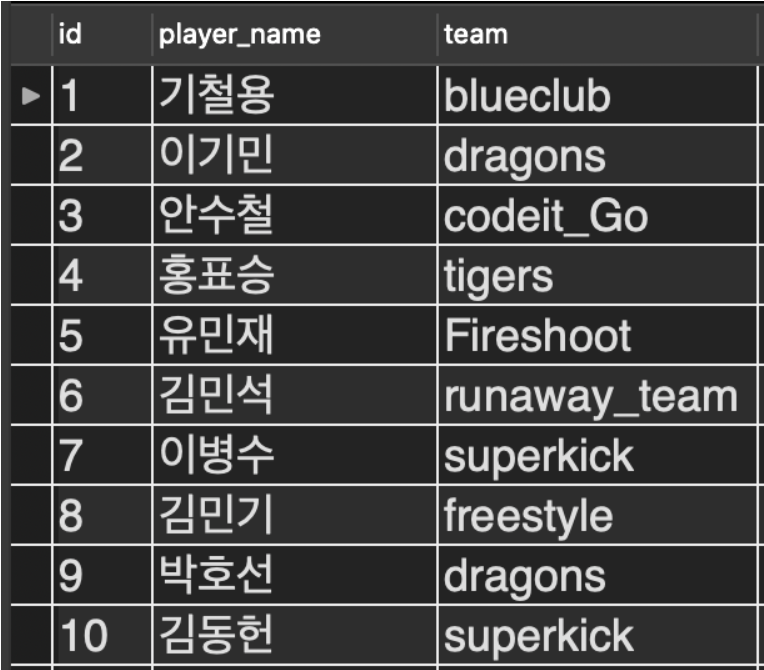
player 테이블
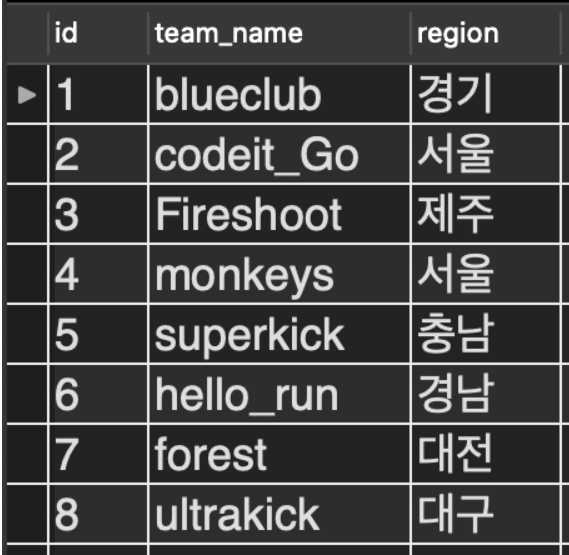
team 테이블
player 테이블의 team 컬럼과, team 테이블의 team_name 컬럼을 기준으로 해서 두 테이블로 이때까지 배운 3가지 조인을 해보자.
1. LEFT OUTER JOIN
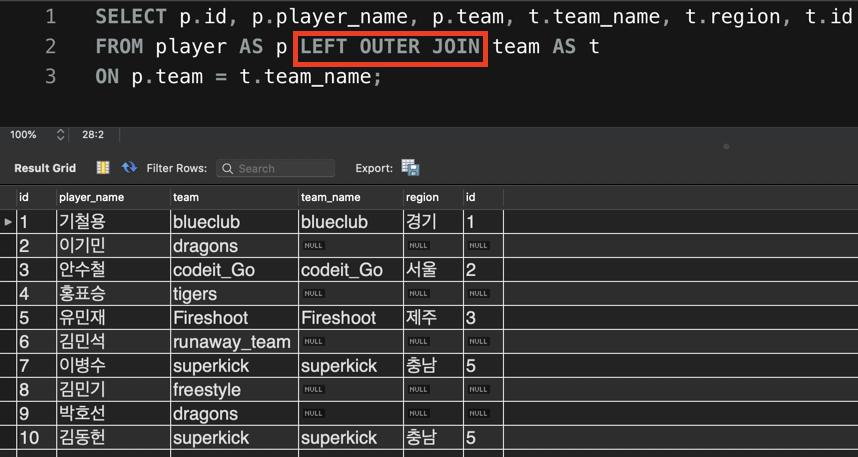
결과를 보니 지금 선수들의 소속팀 중에 아직 지역 정보가 없는 팀들도 있다. 지금 SELECT 절 뒤의 컬럼 순서는 이해를 돕기 위해 적절하게 조정했다.
2. RIGHT OUTER JOIN
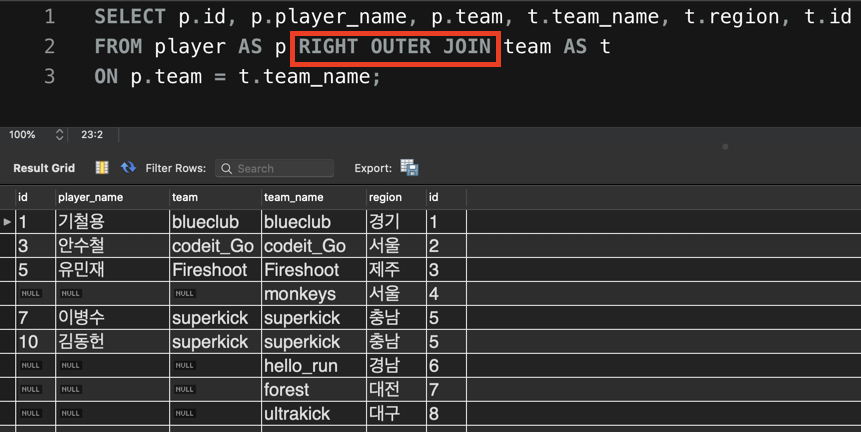
지금 superkick이라는 팀에 속한 선수가 2명 있다. 그리고 아직 그 소속 선수들의 정보가 player 테이블에 없는 팀도 있다.
3. INNER JOIN
IDEA
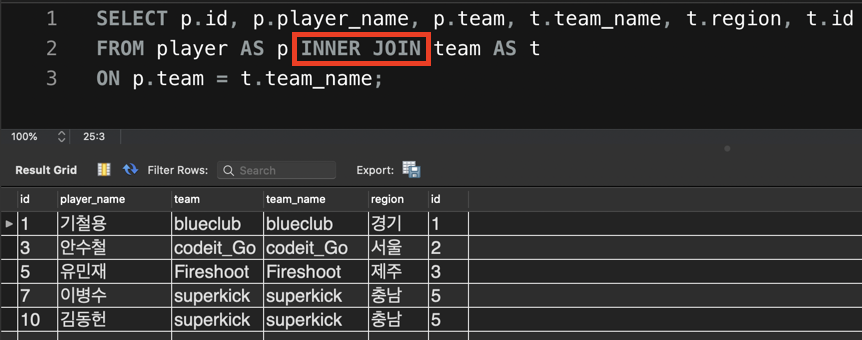
선수 정보와 팀 정보가 둘다 존재하는 것들이 잘 조회된다. 위의 두 OUTER JOIN과는 전혀 다른 결과지 않은가?
정리하자면,
이전 영상에서 item 테이블과 stock 테이블을 조인할 때는 RIGHT OUTER JOIN과 INNER JOIN의 결과가 같았지만, 지금 player 테이블과 team 테이블을 조인할 때는 결과가 다르지 않은가?
다시 한번 말하자면, 이전의
stock 테이블의 경우 그 item_id 컬럼이 item 테이블의 id 컬럼을 참조하는 Foreign Key(외래키)였다. 즉, item_id 컬럼의 값이 id 컬럼에 반드시 존재할 수밖에 없는 관계였다.
하지만 player 테이블의 team 컬럼과 team 테이블의 team_name 컬럼은 그런 관계는 아니었다.
조인을 할 때 보통 Foreign Key를 기준으로 하는 것은 맞지만, 그렇다고 꼭 Foreign Key만을 기준으로 해야하는 것은 아니다. 방금처럼 꼭 Foreign Key가 존재하지 않더라도 서로 같은 의미를 나타내는 컬럼들(team 컬럼, team_name 컬럼)을 기준으로 조인하기도 하다.
꼭 Foreign Key가 아니더라도 서로 연관있는 컬럼을 기준으로 조인을 하는 경우도 많다. 이 사실을 꼭 기억하자.
