데이터 분석에 대한 SQL구문
I. 각종 특성값 구하기
0x01 집계함수(COUNT, MAX, MIN, AVG, SUM, STD)
- COUNT() 함수는 NULL의 갯수를 제외하고 몇개의 row가 있는지 출력한다.
- COUNT(*) 를 쓰면 특정컬럼을 기준으로 row를 구해주는 것이 아니라 SELECT구문에 의해 조회되는 전체의 row 갯수를 알려준다.
/* COUNT 함수 */
### Table의 전체 row 갯수 구하기
SELECT COUNT(*) FROM member;
### email 컬럼에 몇 개의 row가 있는지 구하기
SELECT COUNT(email) FROM member;- 최댓값, 최솟값, 평균값 구하기 (MAX, MIN, AVG)
/* MAX, MIN, AVG 함수 */
### 가장 큰 키를 구하기
SELECT MAX(height) FROM member;
### 가장 가벼운 몸무게를 구하기
SELECT MIN(weight) FROM member;
### 평균 몸무게를 구하기
SELECT AVG(weight) FROM member;
-- AVG함수는 NULL은 제외하고 평균을 구해준다.- 총합, 표준편차 구하기 (SUM, STD)
/* SUM, STD 함수 */
### 나이의 총합 구하기
SELECT SUM(age) FROM member;
### 나이의 표준편차 구하기
SELECT STD(age) FROM member;0x02 산술함수(ABS, SQRT, CEIL, FLOOR, ROUND)
- 절대값 구하기 (ABS)
SELECT ABS(velocity) FROM smartcar;- 제곱근 구하기 (SQRT)
SELECT SQRT(area) FROM test_math;- 올림, 내림, 반올림 하기 (CEIL, FLOOR, ROUND)
### 키 소숫점 올림하기
SELECT CEIL(height) FROM member;
### 키 소숫점 내림하기
SELECT FLOOR(height) FROM member;
### 키 소숫점 반올림하기
SELECT ROUND(height) FROM member;집계함수는 특정 컬럼의 여러 row의 값들을 동시에 고려해서 실행되는 함수이고, 산술 함수는 특정 컬럼의 각 row의 값마다 실행되는 함수이다.
II. NULL을 다루는 방법
0x01 해당 컬럼에 NULL값이 있는지 없는지 확인하는 구문(IS NULL, IS NOT NULL)
### address컬럼에 NULL이 있는 row를 조회
SELECT * FROM member WHERE address IS NULL;
### address컬럼에 NULL이 없는 row를 조회
SELECT * FROM member WHERE address IS NOT NULL;
### height, weight, address중 하나의 컬럼이라도 NULL이 있는 row를 조회
SELECT * FROM member
WHERE height IS NULL
OR weight IS NULL
OR address IS NULL;📌주의사항
SELECT * FROM member WHERE address = NULL;과 같이 적으면 안된다. 이 구문은 아무 row도 출력되지 않는다. 반드시 IS 혹은 IS NOT으로 NULL의 존재여부를 확인해야한다.- NULL에 어떠한 연산을 해도 결국 NULL 그대로이다. NULL은 값이 아니기 때문에 연산의 효과가 없다. 예를 들어
SELECT height+3 FROM member;같은 구문에서 height컬럼의 일반적인 값들은 +3 연산이 되지만, NULL이 있다면 그저 NULL이다.
0x02 NULL의 출력결과를 다른 문자열로 바꾸기(COALESCE)
- 다른직군의 사람들이 NULL을 모를 수 있으므로 NULL을 이해할 수 있는 문자열로 바꿈
### height컬럼을 출력하되, NULL이 있으면 문자열(####)출력
SELECT COALESCE(height, '####') FROM member;0x03 NULL을 포함한 쓰레기값 제외하기
### age에 NULL, 300, -29와 같은 이상한 값을 제외한 나이의 평균값 구하기
SELECT AVG(age) FROM member WHERE age BETWEEN 5 AND 100;
### address에 이상한 주소를 갖는 row들만 출력하기
SELECT * FROM member WHERE address NOT LIKE '%호';III. 컬럼다루기
0x01 컬럼끼리 계산하기
- 지금까지는 하나의 컬럼내에서 데이터를 다뤘었지만, 이제 아래와 같이 컬럼끼리도 연산이 가능하다는 점도 알아두자! 단, 컬럼끼리 산술연산을 할 때 사용가능한 operator는 다음과 같다.
- +
- -
- *
- /
- %
/* 컬럼간의 연산을 통해 가상컬럼 만들기 */
### 컬럼간의 연산을 통해 BMI 구하기
SELECT height, weight, weight / ((height/100) * (height/100))
FROM member;
/*
weight / ((height/100) * (height/100))라는 컬럼의 모든 row가
저 연산을 수행한 결과가 된다.
*/weight / ((height/100) * (height/100)와 같은 컬럼은 없지만, 하나의 가상 컬럼으로서 추가해줄 수도 있다. 또한, 각각의 row에 대해 weight 혹은 height중 하나라도 NULL이 있으면 계산이 되지않는데 위에서 보았듯이 NULL은 연산이 불가능하기 때문에 NULL이 포함되어있는 연산의 출력결과는 항상 NULL이 된다.
0x02 컬럼에 alias 붙이기(AS) 와 CONCAT()함수
- 위 컬럼계산에서 BMI를 계산하여 하나의 가상 컬럼으로서 추가해주었는데, 컬럼의 출력결과가 weight / ((height/100) * (height/100)) 그대로 나타나므로 가독성이 떨어진다. 이를 위하여 가상컬럼에다가 별명(alias)을 붙이면 가독성이 좋아진다.
- 가상컬럼뿐만 아니라 일반컬럼에도 alias를 붙일 수 있다.
/* 컬럼에 별명붙이기 */
### 지저분한 BMI연산식을 'BMI'라는 깔끔한 이름의 컬럼으로 개명하기
SELECT height, weight, weight / ((height/100) * (height/100)) AS BMI
FROM member;
### 일반컬럼, 가상컬럼 모두 별명붙이기
SELECT
height AS 키,
weight AS 몸무게,
weight / ((height/100) * (height/100)) AS BMI
FROM member;
/* 사실 아래처럼 AS 없이도 저렇게 별명을 붙일 수가 있지만,
별명을 붙였다는 것을 명시적으로 표현해주기 위해서는 AS를 써주는 것이 좋다. */
SELECT
height 키,
weight 몸무게,
weight / ((height/100) * (height/100)) BMI
FROM member;- AS와 함께 유용하게 사용할 수 있는 CONCAT()이라는 함수가 있다. 이 CONCAT은 산술계산이 아닌 문자열 붙이기를 통해서 새로운 가상컬럼을 만들어낸다.
- AS로 별명을 붙여주지 않으면
CONCAT(height, 'cm', ', ', weight, 'kg')라는 이름의 컬럼이 만들어진다.
- AS로 별명을 붙여주지 않으면
### CONCAT()으로 문자열붙이기 연산을 통해 새로운 가상컬럼을 생성
SELECT
email,
CONCAT(height,'cm',', ',weight,'kg') AS '키와 몸무게',
weight/((height/100)*(height/100)) AS BMI
FROM member;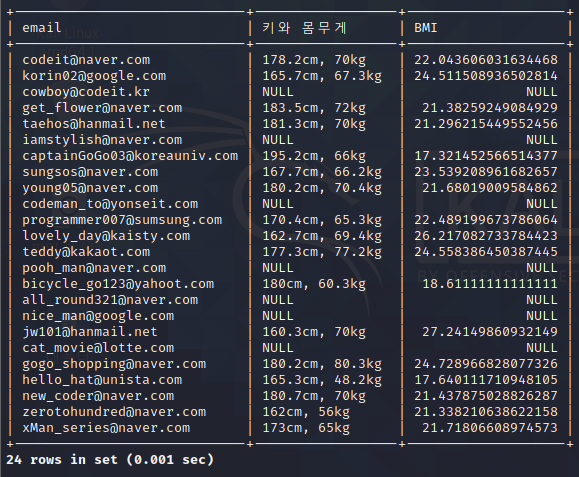
0x03 컬럼의 값을 변환해서 보기(CASE - WHEN~THEN - END)
- CASE ~ END문은 새로운 가상컬럼을 생성하되, 각 경우에 따라 다른 출력결과를 준다.
- CASE함수는 다음과 같이 두가지 종류가 있다
- 단순 CASE 함수 :
- CASE함수는 다음과 같이 두가지 종류가 있다
/* 검색 CASE 함수 */
SELECT
email,
CONCAT(height,'cm',', ',weight,'kg') AS '키와 몸무게',
weight/((height/100)*(height/100)) AS BMI,
(CASE
WHEN weight IS NULL OR height IS NULL THEN '비만여부 알 수 없음'
WHEN weight/((height/100)*(height/100)) >= 25 THEN '과체중 또는 비만'
WHEN weight/((height/100)*(height/100)) >= 18.5
AND weight/((height/100)*(height/100)) < 25 THEN '정상'
ELSE '저체중'
END) AS obesity_check
FROM member;
-- 여기서도 마찬가지로 CASE~END문에 별칭을 붙여주지 않으면
-- 저 긴 구문이 새로운 가상컬럼의 이름이 되므로 꼭 AS로 개명해주자
### 위랑 똑같은 구문이지만 ORDER BY를 통해 obesity_check를 정렬해주었다.
SELECT
email,
CONCAT(height,'cm',', ',weight,'kg') AS '키와 몸무게',
weight/((height/100)*(height/100)) AS BMI,
(CASE
WHEN weight IS NULL OR height IS NULL THEN '비만여부 알 수 없음'
WHEN weight/((height/100)*(height/100)) >= 25 THEN '과체중 또는 비만'
WHEN weight/((height/100)*(height/100)) >= 18.5
AND weight/((height/100)*(height/100)) < 25 THEN '정상'
ELSE '저체중'
END) AS obesity_check
FROM member
ORDER BY obesity_check ASC;IV. GROUP BY
0x01. 그룹화해서 보기
GROUP BY는 컬럼 값을 그룹짓고 이에 대해 건수나 값의 합을 계산할 때 사용된다. 이 GROUP BY는 보통 COUNT, AVG, MIN같은 집계함수와 같이 쓰인다.
집계함수란 그루핑을 통해 생성된 각 그룹의 수치적인 특성을 구하는 함수이다.
멤버테이블에서 남성회원과 여성회원들이 각각 총 몇명인지 구해보자.
그러려면 일단 모든 회원들을 성별기준으로 그룹화해야하는데, 이때 쓰는 구문이 GROUP BY이다.
/* 모든 row에 대해 gender컬럼의 값을 기준으로
같은 값을 갖는 row들은 같은 그룹에 속하게 하여 gender 컬럼을 출력 */
SELECT gender FROM copang_main.member GROUP BY gender;GROUP BY gender기준으로 column's 값이 같아? 한 그룹에 넣어.
DISTINCT와 같아 보이지만, DISTINCT는 중복된 값을 그냥 제거하고, GROUP BY는 컬럼의 같은 값에 대한 모든 row를 집어넣는다. 아래와 같이 말이다.
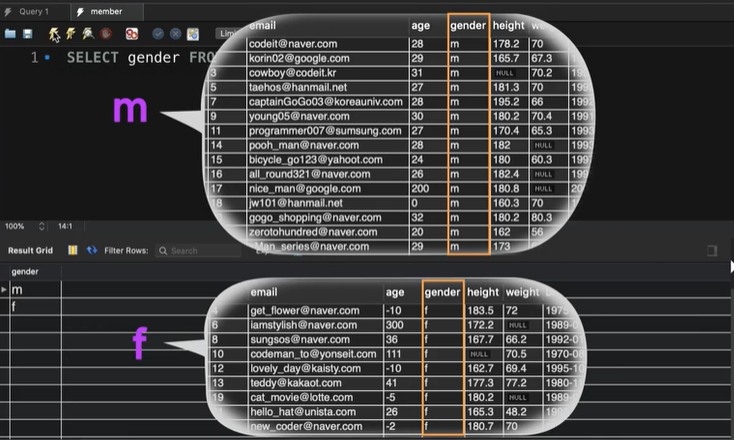
이제 그룹화된걸 기준으로 남자회원, 여자회원이 각각 몇명인지 구해보자.
SELECT gender, COUNT(*) FROM copang_main.member GROUP BY gender;여기서 COUNT(*)는 조회되는 row의 개수를 구해주는 표현식 이다.
그리고 이 COUNT(*)는 전체테이블을 대상으로 실행되는 것이 아니라 아래 그림처럼 남성그룹, 여성그룹을 대상으로 각각 실행되는 것이다.
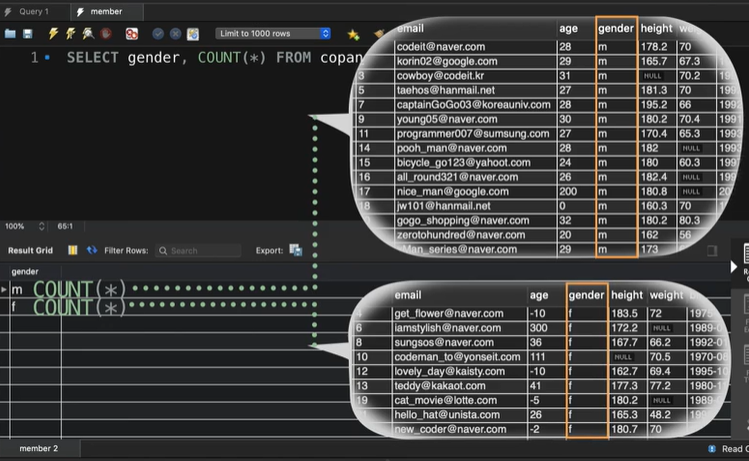
이제는 남성회원의 평균키와 여성회원의 평균키를 구해보자. 다음과 같이 써주면 된다
SELECT gender, COUNT(*), AVG(height) FROM copang_main.member GROUP BY gender;평균값을 구하는 함수 AVG 또한 각 그룹에서 각각 작동하게 된다.
비슷하게 각 성별에서 가장 몸무게가 가벼운 회원의 몸무게를 구해보자.
SELECT
gender,
COUNT(*),
AVG(height),
MIN(weight)
FROM copang_main.member
GROUP BY gender;최솟값을 구하는 함수 MIN 또한 각 그룹에서 각각 작동하게 된다.
GROUP BY에 대해서 한가지 더 설명하면,
GROUP BY를 쓰지 않았을 때는 테이블 하나가 그냥 하나의 그룹으로서 작용했다. 그래서 GROUP BY를 쓰지않고 집계함수를 썼을 경우 테이블의 전체 row가 하나의 그룹이었으므로 그 하나의 그룹에 대해 집계함수가 작동했었는데,
GROUP BY를 쓸 경우 어떤 기준으로 그룹들을 세분화 시켜 여러 그룹을 만든뒤 그 그룹들 각각에 대해 집계함수가 작동하게 되는 것이다.
0x02. 여러그룹을 그룹화하기
이제 각 지역의 사람들이 각각 몇명있는지 보자. 먼저 지역을 그루핑을 하기위해 address 컬럼을 사용하여 그루핑을 해보자. 주의해야 할 점은 SELECT * FROM copang_main.member GROUP BY address;처럼 쓰면 안된다는 것인데, address 컬럼은 이미 row마다 고유한 값을 지니기 때문이다. 따라서 특정 지역을 알기 위해서는 다음과 같이 써야한다.
### 각 지역을 그룹화
SELECT SUBSTRING(address, 1, 2) FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2);
### 각 지역별로 몇명있는지 출력
SELECT SUBSTRING(address, 1, 2) as region,
COUNT(*)
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2);사실 지금까지는 하나의 컬럼으로 그루핑을 해왔지만, 여러 컬럼기준으로 그루핑을 할 수 있다. 아래는 gender라는 기준을 하나 더 추가해준 것이다.
### 각 지역별+성별 기준으로 몇명있는지 출력
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender;이는 좀 더 세부적으로 그룹화할 수 있어 위의 지역별로 그룹화하는 것 보다 특정지역의 남성, 여성을 기준으로 그룹화가 가능함을 의미한다.
0x03 HAVING을 이용한 그룹화하기
GROUP BY를 이용하여 그루핑을 하면 모든 그룹들의 row가 출력되는데 만약 이 중에서도 특정 그룹들만 보고 싶다면 어떻게 해야 할까? 예를들어 주요 지역인 서울의 그룹들만 보고 싶다면??
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING region = '서울'; # HAVING : ~을 가지고 있는즉, 여러 그룹들 중에서 보고싶은 그룹만 선별하려면 HAVING을 쓰면된다.
아래와 같이 HAVING도 여러개의 조건을 가질 수 있다.
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING
region = '서울'
AND gender = 'Male';위 쿼리를 실행해보면 서울에 사는 남성회원그룹만 조회된다.
❓ 여기서 의문점: 보고싶은 그룹을 선별할 때 그냥 SELECT문에서 조건 달 때 쓰는 WHERE문 쓰면 끝 아님??
NO! 👉 WHERE와 HAVING은 그 의미가 비슷해 보이나 엄연히 다른 목적을 가진 구문이다. WHERE는 테이블에서 맨 처음 row들을 조회할 때 조건을 설정하기 위한 구문인 반면,
HAVING은 이미 조회된 row들을 다시 그룹핑했을 때 생성된 그룹들 중에서 다시 필터링을 할 때 쓰는 구문이다.
이제 위 구문을 좀 더 깔끔하게 정렬하기 위해 ORDER BY와 같이 써보자.ㅎㅎ
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM copang_main.member
GROUP BY
SUBSTRING(address, 1, 2),
gender
HAVING
region = '서울'
AND gender = 'Male'
ORDER BY
region ASC,
gender DESC;덧붙여서, GROUP BY를 사용할 때 반드시 지켜야 하는 중요한 규칙이 있는데, 그것은 다음과 같다 :
SELECT 구문에는
(1) GROUP BY 뒤에서 사용한 컬럼들 또는
(2) COUNT, MAX 등과 같은 집계 함수만
쓸 수 있다는 규칙이다. 이건 거꾸로 말해 GROUP BY 뒤에 쓰지 않은 컬럼 이름을 SELECT 뒤에 쓸 수는 없다는 뜻이다.
왜 그런 걸까?
지금까지의 GROUP BY를 썼을 때 나온 각 그룹은 단순한 row 하나가 아니다. 지금 하나의 row는 하나의 그룹을 의미하기 때문에 그 안에 여러 row들이 포함된 걸로 생각해야 한다.
그런데 GROUP BY 뒤에 쓰지 않은, 그러니까 그루핑 기준으로 사용하지 않은 컬럼명을 SELECT 절 뒤에 써서 조회하려고 하면, 각 그룹의 row들 중에서 해당 컬럼의 값을 어느 row에서 가져와야할지 결정할 수가 없다.
예를 들어, 위 SQL 문에서 그루핑 기준으로 사용하지 않은 age라는 컬럼명을 SELECT 문 뒤에 붙이면 어떻게 될까?

각 그룹에 속한 여러 row들에서 어떤 row의 age 컬럼의 값을 출력해야하는지 결정할 수가 없다. 그래서 이 SQL 문을 실행하면 다음과 같은 에러 메시지를 볼 수 있다.
Error Code: 1055. Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'copang_main.member.age' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
이 에러 메시지의 내용을 요약하면, 그루핑 기준으로 사용되지 않은 컬럼(nonaggregated column)이 SELECT 절에 존재하면 안 된다는 뜻이다.
age 컬럼은 그루핑 기준으로 쓰지 않았는데 SELECT 뒤에 써서 그 값을 조회하려고 하니 에러가 난 것이다.
따라서, GROUP BY를 사용할 때는 이 사용 규칙을 반드시 기억해야 한다.
그런데 위 규칙을 보면 (2) COUNT, MAX 등과 같은 집계 함수는 사용할 수 있다는 내용도 있는데
그러니까 이런 사용법은 가능하다.
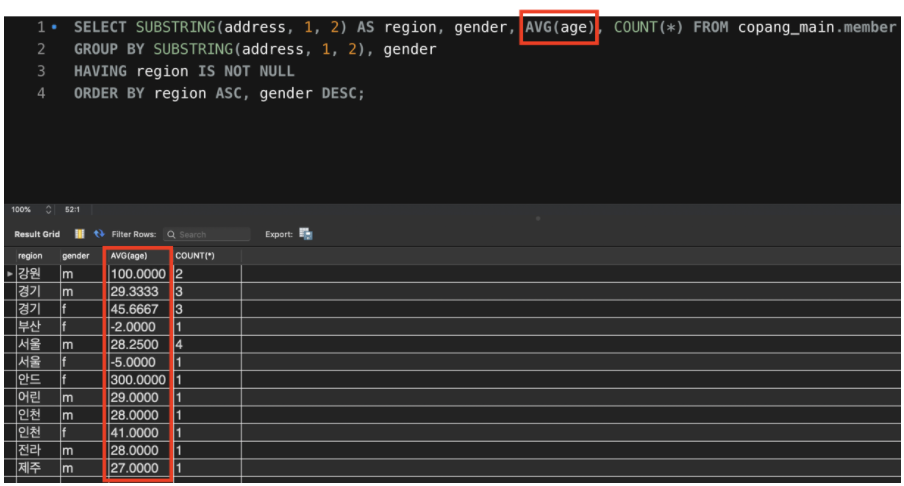
SELECT 절 뒤에 age를 바로 쓰는 건 안 되지만, AVG(age)처럼 집계 함수의 인자로 사용하는 건 괜찮다. 왜냐하면 이렇게 하면 각 그룹에서 특정 row의 age 값을 보여주는 게 아니라 그냥 각 그룹 내 모든 row들의 age 컬럼의 값의 평균값을 구하면 되기 때문이다. 즉, 그루핑 기준으로 사용하지 않은 컬럼이라도 SELECT 절 뒤에서 집계 함수의 인자로는 사용할 수 있는 것이다.
