0x01 웹과 HTTP
(1) 웹 페이지는 객체들로 구성
- 객체는 HTML 파일, JPEG이미지, 자바 애플릿, 오디오 파일 등
(2) 웹 페이지는 기본 HTML 파일과 여러 참조 객체들로 구성
- HTML 파일은 사이사이에 link들이 존재하며, link들이 객체 참조 주소를 가짐
(3) 각 객체는 URL로 지정
-
URL은 객체를 가지고 있는 서버의 호스트 이름과 객체의 경로 이름으로 구성
-
인터넷의 모든 객체는 URL보유
📌 HTTP 개요
HTTP(HyperText Transfer Protocol) : 웹 애플리케이션 계층 프로토콜
-
HTTP는 TCP를 사용
①클라이언트는 80번 포트로 서버에게 TCP연결(소켓 생성)을 시작
②서버는 클라이언트의 TCP연결 요청 수랑
③웹 브라우저와 웹서버 사이에 HTTP 메시지를 교환
-
HTTP는 비상태 프로토콜(Stateless Protocol)
-
서버는 클라이언트의 과거 요청들에 대한 정보를 유지 하지 않음
👉 서버가 client의 state를 저장 하지 않음
참고 : "상태"를 유지하는 프로토콜은 복잡함.
과거의 기록(상태)들을 유지, 관리해야 하기 때문
서버나 클라이언트 중 하나가 깨진 경우 각각의 "상태"가 불일치하게 되어 조정 필요
1.1 비지속/지속 연결
HTTP는 비지속 연결과 지속 연결 2가지 방식 존재 :
(1) 비지속 연결(non-persistent HTTP)
-
요구/응답 쌍이 분리된 tcp연결을 통해 송/수신 👉 객체 1개를 받기 위해 연결 요청 해야 함
-
하나의 tcp 연결로 하나의 객체만 전송
- 시간이 많이 걸려 비효율적임
단점 : 각 객체 당 2RTT 필요 (각 TCP 연결에 대한 OS 오버헤드가 필요하다.)
웹 브라우저는 참조 객체들을 가져오기 위해 종종 병렬 TCP 연결을 시도
RTT(Round-Trip Time): 클라이언트에서 송신된 패킷이 서버까지 간 후 응답이 다시 되돌아 오는데 걸리는 시간
HTML 파일 요청 응답 시간
TCP 연결을 초기화하는 1RTT
HTTP 요청 후 HTTP 응답으로 처음 몇 바이트를 받는데 필요한 1RTT
파일 전송 시간
따라서,
비지속 HTTP의 응답 시간 = 2RTT + 파일 전송 시간
(2) 지속 연결(persistent HTTP)
모든 요구 / 응답 쌍이 같은 tcp 연결 상에서 송수신
- 1번 요청으로 서버에게 여러번의 data 요청 가능
하나의 tcp 연결로 다수의 객체들이 전송
서버는 응답을 보낸 후에 TCP 연결을 유지(일정 시간이 지나면 terminated)
클라이언트 / 서버 간의 이후 HTTP 메시지들은 같은 연결을 통해 송수신
- 연달아서 연결 요청 전송 가능
클라이언트는 객체를 참조하자 마자 요청을 송신(응답대기X)
모든 참조 객체들에 대해 1RTT만 필요
1.2 HTTP 메시지 포맷
HTTP 메시지 포맷에는 2가지 유형이 있다: HTTP request, HTTP response
(1) HTTP request message 포맷
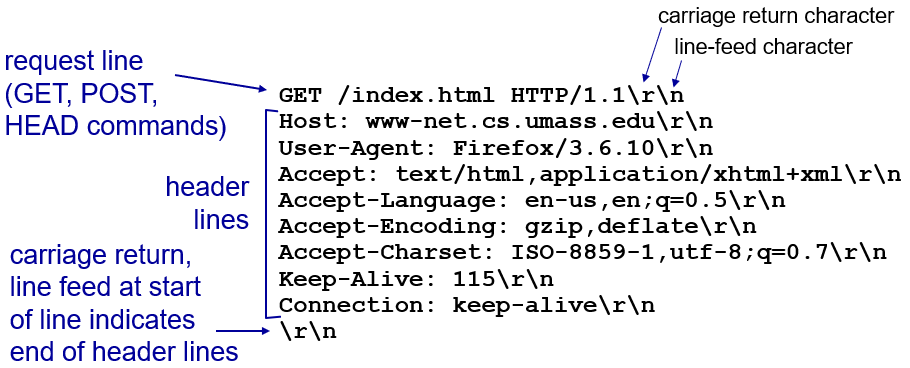
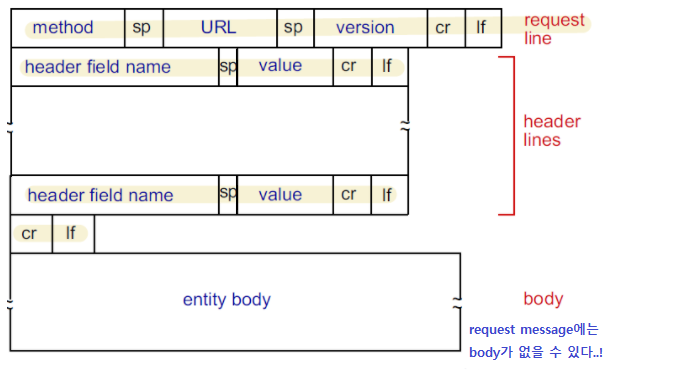
📝 <input> form태그로 업로드
POST Method
- 입력은 url 필드가 아닌 개체 몸체(entity body)로 서버에 업로드
- 크기 제한이 없고 보안성 뛰어남
GET Method(= URL Method)
- 입력은 요청 라인의 URL 필드로 서버에 업로드
- 입력 받을 수 있는 크기에 제한이 있으며, 입력 data가 그대로 들어가므로 보안 취약
📝Method type
HTTP/1.0
-
GET
-
POST
-
HEAD
- GET 방식과 유사하나 서버가 응답 시 요청된 객체 전송 안함
- 즉, HTTP Header 정보만 수신
- GET 방식과 유사하나 서버가 응답 시 요청된 객체 전송 안함
HTTP / 1.1
-
GET, POST, HEAD
-
PUT : URL 필드에 명시된 경로로 개체 몸체 안에 파일 업로드
-
DELETE : URL 필드에 명시된 파일을 삭제
(2) HTTP response message 포맷
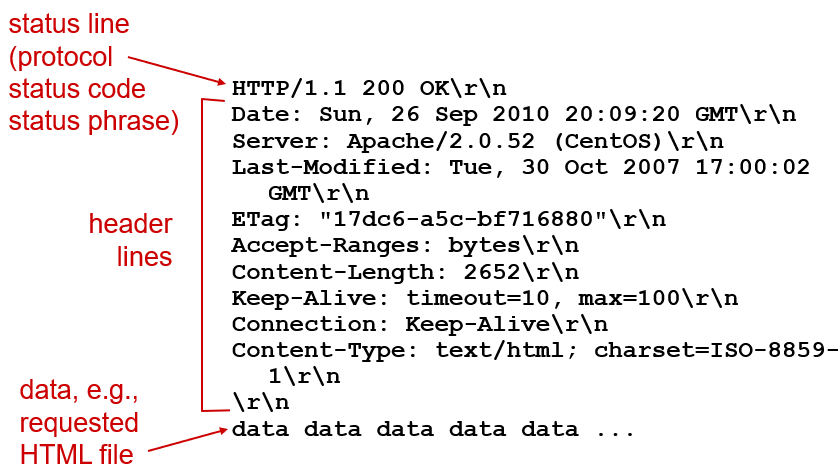
📝 HTTP response status code
웹 서버에서 반환하는 상태값으로, 상태코드는 서버가 클라이언트에게 response message를 돌려줄 때 가장 1번째 라인에 표시됨
- 200 OK : 요청 성공되었고, 요청된 객체가 이 메시지로 보내짐
- 301 Moved Permanently : 요청된 객체가 이동되었고, 새로운 URL은 메시지의 "Location:" 헤더로 표시(redirection)
- 302는 Moved Temporarily
- 400 Bad Request : 서버가 요청을 이해할 수 없다는 일반 오류 코드
- 401 Unauthorized: 인증실패
- 403 Forbidden : 접근금지
- 404 Not Found : 요청된 문서가 서버에 존재하지 않음
- 500 Internal Server Error: 서버에러
- 505 HTTP Version Not Supported : 요청된 HTTP 프로토콜 버전을 서버가 지원 안 함
1.3 사용자와 서버간 상호작용: 쿠키
1.4 웹 캐싱(Web caching)=proxy server
