MySQL에서 사용하는 스토리지 엔진들의 차이점을 비교해보기 위해 조사해보며 정리한 글입니다!
확실하지 않은 내용이 있을 수 있으니 부족한 내용은 댓글로 알려주시면 감사하겠습니다!! 🙇♂️
현재 백엔드 학습을 하며 주로 사용하는 MySQL DB에는 여러가지 스토리지 엔진이 존재합니다.
각 엔진별로 지원하는 기능이 다른데, 별다른 고민 없이 사용하고 있는 것 같아서 정리하고자 글을 작성해봅니다.
데이터베이스 엔진의 종류
보편적이고 알려진 엔진의 종류는 다음과 같다.
- InnoDB 엔진
- MyISAM 엔진
- Memory 엔진
- Archive 엔진
- CSV 엔진
- Federated 엔진
InnoDB 엔진
Inno DB는 MySQL 5.5 부터 기본적으로 사용되는 엔진이다.
트랜잭션 지원
가장 큰 특징으로는 트랜잭션을 지원한다. 커밋과 롤백, 데이터 복구 기능을 제공한다.
ACID 트랜잭션을 지원하므로 결제 정보와 같이 정보의 무결성을 가져야 하고 손실되면 안되는 중요한 데이터를 필요로할 때 사용한다.
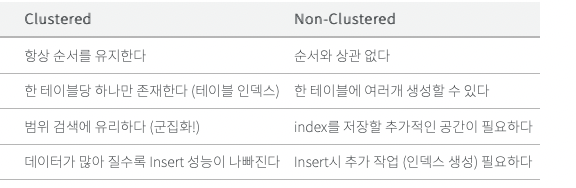
클러스터형 인덱스
또한 클러스터 인덱스 위에 구성되어 있으며 InnoDB의 인덱스 구조는 대부분의 MySQL 스토리지 엔진의 인덱스 구조와는 다르다. PK 기반의 query의 I/O 비용을 줄여준다.
클러스터형 인덱스는 무엇일까? 우선 테이블 당 한개만 생성 가능한 인덱스이다. 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬시킨다. 영어 사전처럼 책의 내용 자체가 정렬돼있기 때문에 인덱스 자체가 책 내용이다.
기본적으로 테이블을 만들고 조회하면 PK인 ID 순으로 조회가 되어있는 이유가 PK를 기반으로 클러스터 인덱스를 만들기 때문이다. 항상 PK를 기준으로 정렬되어있는(clustered) 구조를 가진다. 그렇기 때문에 PK를 통한 조회 속도가 매우 빨라진다.
그렇기 때문에 만약 PK를 중간에 삽입하거나, 변경하는 경우에 소요되는 오버헤드가 클 것이다. 그러므로 테이블 데이터가 자주 업데이트 되지 않거나 읽기 작업이 많을 때 효율적이라고 볼 수 있다.
비 클러스터형 인덱스는 반대로 군집화되어있지 않다. 한마디로 정렬되어 있지 않다. 책의 찾아보기처럼 산발적으로 존재되어 있다. 테이블 데이터와 함께 테이블에 저장되는 것이 아니라 별도의 장소에 저장된다. 그리고 하나의 테이블에 여러개의 논 클러스터형 인덱스를 설정할 수 있다.
비 클러스터형 인덱스의 구조는 데이터의 행에 독립적이다. 비클러스터형 인덱스 키 값이 있고, 각 키 값에는 해당 키 값이 포함된 데이터 행에 대한 포인터가 있다. 비클러스터형 인덱스의 인덱스 행에서 데이터 행으로의 포인터를 행 로케이터라고 한다. 행 로케이터의 구조는 데이터 페이지가 힙에 저장되는지 아니면 클러스터형 테이블에 저장되는지에 따라 다르다. 힙의 경우 행 로케이터는 행에 대한 포인터이고 클러스터형 테이블이랑 행 로케이터가 클러스터형 인덱스 키이다.
where 절이나 join 절과 같이 조건문을 활용하여 테이블을 필터링하거나 데이터가 자주 업데이트되고, 특정 컬럼이 쿼리에서 자주 사용될 때 생성하는 인덱스이다.
row-level locking
그리고 InnoDB는 행 수준의 lock을 지원한다. 그래서 동시 작업이 가능하다고 한다. 이게 무슨 말일까?
이 row-level lock에는 크게 shared lock과 exclusive lock이 있다.
S lock은 read에 대한 lock이다. 일반적인 SELECT 쿼리는 lock을 사용하지 않고 DB를 읽어 들인다. 하지만 SELECT ... FOR SHARE 등 일부 SELECT 쿼리는 read 작업을 수행할 때 InnoDB가 각 row에 S lock을 건다.
X lock은 write에 대한 lock이다. SELECT ... FOR UPDATE나 UPDATE, DELETE 등의 수정 쿼리를 날릴 때 각 row에 걸리는 lock이다.
- 여러 트랜잭션이 동시에 한 row에 S lock을 걸 수 있다. 즉, 여러 트랜잭션이 동시에 한 row를 읽을 수 있다.
- S lock이 걸려 있는 row에 다른 트랜잭션이 X lock을 걸 수 없다. 즉, 다른 트랜잭션이 읽고 있는 row를 수정하거나 삭제할 수 없다.
- X lock이 걸린 row에는 다른 트랜잭션이 S lock과 X lock을 둘 다 걸 수 없다. 다른 트랜잭션이 수정하거나 삭제하고 있는 row는 읽기, 수정, 삭제가 모두 불가능하다.
즉, S lock을 사용하는 쿼리끼리는 같은 row에 접근 가능하다. 반면, X lock이 걸린 row는 다른 어떠한 쿼리도 접근 불가능하다.
이렇게 row 별로 lock을 걸면 동시 작업에 유리하므로 멀티 스레드 환경에 유리하다.
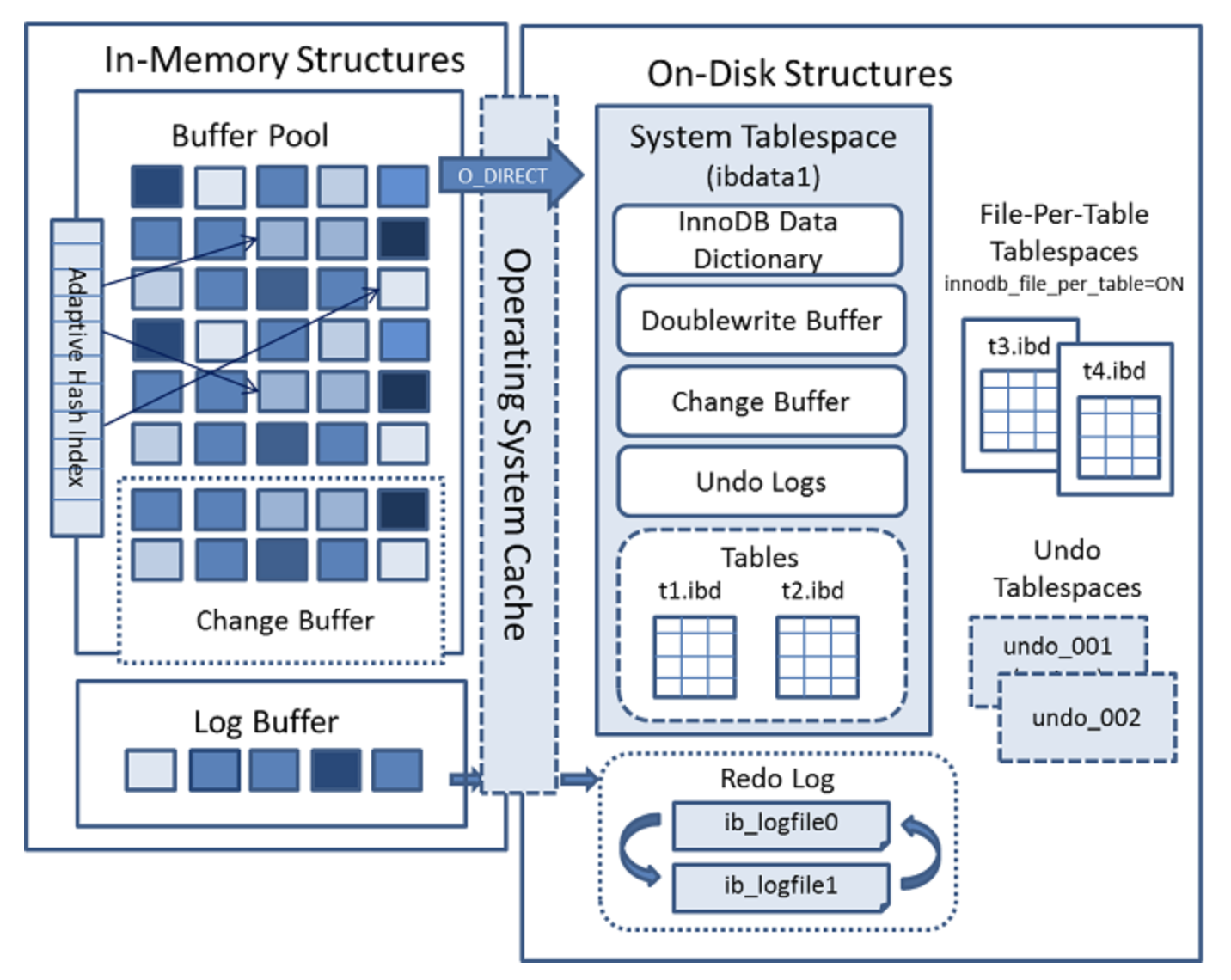
InnoDB의 데이터 구조
InnoDB 테이블의 각 데이터는 page들 안에 나눠져 있고 각 테이블을 구성하는 page들은 B-tree 인덱스라는 트리 데이터 구조안에 정렬되어 있다.
InnoDB에 대한 내용이 길어지는 것 같아서 다음 글에서 이어 적도록 하겠습니다!!
참고 자료
Clustered vs NonClustered (index 개념)
클러스터형 및 비클러스터형 인덱스 소개
[MySQL] MySQL의 스토리지 엔진 비교 (InnoDB, MyISAM, Archive)
Lock으로 이해하는 Transaction의 Isolation Level
