1. Layers and Modules
@Tommy Kim
앞선 내용들을 보면 단일 출력을 가진 선형 모델 중 하나의 뉴런은 일련의 입력을 받고, 해당하는 스칼라 출력을 생성하며, 목표 함수를 최적화하기 위해 업데이트 될 수 있는 일련의 관련 매개변수를 가진다. 이는 여러 출력을 가진 네트워크도 벡터화 연산을 이용하여 단일 뉴런의 특성을 그대로 유지한다. 여기서 더 확장되어 MLP를 도입하였을 때에도, 기본 구조가 유지된다.
MLP를 자세히 살펴보면, 전체 모델과 모든 구성 요소 층이 모두 같은 구조를 공유한다. 각 층에서 입력을 받아 출력을 생성하며, 모든 구성층의 매개변수를 가진다. 여기서 MLP의 층의 개수가 매우 많아지게 되면, 층 하나 하나 직접 구현하기 보다, 특정한 패턴이 존재하는 모듈 단위로 구현하는 것이 훨씬 편해진다. 대표적인 예시로는 ResNet-152가 있고, 해당 아키텍처는 컴퓨터 비전에서 인기 있는 모델이다.
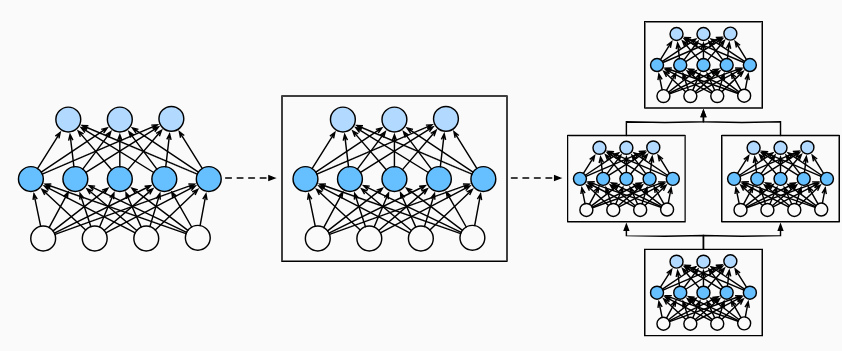
이러한 특징을 가진 모듈은 프로그래밍 관점에서는 class라고 표현한다. class에는 입력을 출력으로 변환하는 propagation method를 정의해야하며, 필요한 매개변수들을 저장해야 한다.
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10))
X = torch.rand(2, 20)
net(X).shape
torch.Size([2, 10])앞서 적용해보았던 nn.Sequential은 PyTorch에서 모듈들의 구성 요소들을 순서대로 유지한다. Pytorch에서 제공하는 모듈은 ‘Module’로 정의되어있고, 위의 예제에서 적용된 두 개의 fully connected layer는 ‘Module’의 하위 클래스인 ‘Linear’ 클래스의 예시이다. 이 예시에서 propagation은 단순하게 작동한다. Sequential 목록 안에 있는 각 모듈들을 연결하여, 각 모듈의 출력을 다음 모듈의 입력으로 전달한다.
Q. net으로 쓰면 파라미터들이 메모리 공유되지 않나?
1) A custom Module
우리는 PyTorch가 제공하는 모듈 외에도, 직접 모듈을 만들 수 있는데, 딥러닝에서 모듈은 다음의 5 가지 조건을 만족해야 한다.
a) forward propagation method를 통해 데이터를 입력 받아야 한다.
→ 여기서 forward propagation method는 단순히 입력 방향이 순방향임을 의미한다.
b) 입력 받은 데이터에 따라 출력을 생성해야 한다. 이 때, 출력의 차원은 입력 차원과 달라도 무방하다 : 위의 코드에서 첫 번째 hidden layer는 입력 데이터에 대해 256개 차원의 출력을 반환했다.
c) 입력에 대한 출력의 gradient가 계산이 필요하다. 이는 back propagation method가 진행됨에 따라 자동으로 계산된다.
d) 필요한 매개변수를 저장하고 이를 제공해야 한다.
e) 필요에 따라 모델의 매개변수를 초기화해야 한다.
다음의 예제는 모듈의 기본적인 조건을 만족 시켜 구현한 모듈의 예시이다.
class MLP(nn.Module):
def __init__(self):
# Call the constructor of the parent class nn.Module to perform
# the necessary initialization
super().__init__()
self.hidden = nn.LazyLinear(256)
self.out = nn.LazyLinear(10)
# Define the forward propagation of the model, that is, how to return the
# required model output based on the input X
def forward(self, X):
return self.out(F.relu(self.hidden(X)))2) The Sequential Module
앞서 나왔던 Sequential은 Module들의 chain 역할을 수행하는데, 나만의 Sequential인 MySequential을 구현하기 위해서는, 두 가지 방법을 정의해야 한다.
- 모듈을 순서대로 하나씩 리스트에 append한다.
- forward propagation method는 입력값을 입력 받은 후에, 데이터들을 리스트에 추가된 순서대로 지나가게(pass) 해야한다.
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
self.add_module(str(idx), module) #순서대로 append
def forward(self, X):
for module in self.children(): #순서대로 입력값 X가 지나가게함
X = module(X)
return X
net = MySequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10))
net(X).shape
torch.Size([2, 10])3) Executing Code in the Forward Propagation Method
Sequential class를 활용하면 모델 구성이 쉬워지고, 새로운 아키텍쳐들을 합치는 것이 가능해진다. 하지만, 모든 아키텍쳐들은 daisy-chain(순서대로 처리되는) 구조가 아니다. 더 유연한 구조가 필요하다면, 우리는 Sequential에 들어갔던 사전 정의된 module들 말고, 우리만의 block을 정의하여 사용해야 한다. 만약, forward propagation method에서 제어 흐름을 조절하거나, 미리 정의된 neural network처럼이 아닌, 임의의 수학 연산들로 정의하고 싶다면, 우리만의 새로운 architecture block을 생성해야 할 것이다.
forward propagation method로 상수 파라미터들로 구현한다고 해보자. 이때의 수식은 다음과 같이 될 것이다.
이때의 가중치 는 상수항으로써, 업데이트 되지 않는다.
이에 따라 새로운 class를 구현하면 다음과 같다.
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
# Random weight parameters that will not compute gradients and
# therefore keep constant during training
self.rand_weight = torch.rand((20, 20))
self.linear = nn.LazyLinear(20)
def forward(self, X):
X = self.linear(X)
X = F.relu(X @ self.rand_weight + 1)
# Reuse the fully connected layer. This is equivalent to sharing
# parameters with two fully connected layers
X = self.linear(X)
# Control flow
while X.abs().sum() > 1:
X /= 2
return X.sum()위의 코드에서 한번 초기화된 가중치들은 업데이트 되지 않는다. 또한, forward 함수에서 가중치 합을 구한후에는 norm이 1보다 작아질때까지 control flow를 반복한다.
우리는 마지막으로 Sequential class을 사용해 새롭게 정의한 우리만의 Module들을 추가해서 사용할 수 있다.
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.LazyLinear(64), nn.ReLU(),
nn.LazyLinear(32), nn.ReLU())
self.linear = nn.LazyLinear(16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.LazyLinear(20), FixedHiddenMLP())
chimera(X)
tensor(0.0679, grad_fn=<SumBackward0>)2. Parameter Mangaement
@리치
학습 루프의 목표는 손실 함수를 최소화 하는 파라미터 값을 찾는 것이다. 학습 후에는 미래 예측을 위해 이러한 파라미터가 필요하다. 또한 다른 상황에서 재사용하기 위해, 파라미터를 추출할 때도 있다.
대부분의 경우, 매개변수를 선언하고 조작하는 방법에 대한 핵심적인 세부 사항은 무시하고 딥러닝 프레임워크에 의존하여 무거운 작업을 처리한다. 하지만 표준 레이어를 사용하는 스택형 아키텍처에서 벗어나면 때때로 파라미터를 선언하고 조작하는 복잡한 과정을 거쳐야 할 때가 있다. 이를 위해 디버깅, 시각화하는 방법과 서로 다른 모델 컴포넌트 간의 매개변수 공유에 대해 알아본다.
# 은닉층이 하나인 MLP에 대해 확인한다.
net = nn.Sequential(nn.LazyLinear(8),
nn.ReLU(),
nn.LazyLinear(1))
X = torch.rand(size=(2, 4))
net(X).shape # torch.Size([2, 1])1) Parameter Access
Sequential 클래스를 통해 모델을 정의하면 먼저 모델을 목록처럼 인덱싱하여 모든 레이어에 액세스할 수 있다. 각 레이어의 파라미터는 해당 속성에서 찾을 수 있다.
net[2].state_dict()
# output
OrderedDict([('weight',
tensor([[-0.1649, 0.0605, 0.1694, -0.2524, 0.3526, -0.3414, -0.2322, 0.0822]])),
('bias', tensor([0.0709]))])완전히 연결된 이 레이어에는 각각 해당 레이어의 가중치와 편향에 해당하는 두 개의 매개변수가 포함되어 있다.
1.1) Targeted Parameteres
각 매개변수는 매개변수 클래스의 인스턴스로 표시된다. 아래 코드는 파라미터 클래스 인스턴스를 반환하는 두 번째 신경망 계층에서 바이어스를 추출하고 해당 파라미터의 값에 추가로 접근한다.
type(net[2].bias), net[2].bias.data
(torch.nn.parameter.Parameter, tensor([0.0709]))매개변수는 값, gradients와 추가 정보를 포함하는 복잡한 객체이다. 따라서, 값을 명시적으로 요청해야한다.
값 외에도 매개변수를 통해 gradient에 접근할 수 있다. (역전파 호출전이라 초기상태임)
net[2].weight.grad == None
True1.2) All Parameters at Once
모든 레이어의 매개변수에 접근할 수도 있다.
[(name, param.shape) for name, param in net.named_parameters()]
[('0.weight', torch.Size([8, 4])),
('0.bias', torch.Size([8])),
('2.weight', torch.Size([1, 8])),
('2.bias', torch.Size([1]))]2) Tied Parameters
여러 레이어에 걸쳐 매개변수를 공유해야 하는 경우가 많다. 완전히 연결된 레이어를 할당하고 해당 매개변수를 사용하여 다른 레이어의 매개변수를 설정한다. 여기서 매개변수에 액세스하기 전에 순방향 전파(X)을 실행해야 한다.
# We need to give the shared layer a name so that we can refer to its
# parameters
shared = nn.LazyLinear(8)
net = nn.Sequential(nn.LazyLinear(8), nn.ReLU(),
shared, nn.ReLU(), # shared가 2번 사용됨
shared, nn.ReLU(),
nn.LazyLinear(1))
net(X)
# Check whether the parameters are the same
print(net[2].weight.data[0] == net[4].weight.data[0]) # 따라서 가중치가 동일함
net[2].weight.data[0, 0] = 100 # 하나를 바꿔도 다른 하나도 바뀜
# Make sure that they are actually the same object rather than just having the
# same value
print(net[2].weight.data[0] == net[4].weight.data[0])
tensor([True, True, True, True, True, True, True, True])
tensor([True, True, True, True, True, True, True, True])이 예는 두 번째와 세 번째 레이어의 매개변수가 묶여 있음을 보여준다. 이 매개변수들은 동일할 뿐만 아니라 동일한 텐서이기 때문에, 매개변수 중 하나를 변경하면 다른 매개변수도 변경된다.
역전파(backpropagation) 과정에서 각 계층에 대한 그래디언트(기울기)가 계산되는데, 현재 매개변수가 공유되게 된다. 따라서, 해당 매개변수에 대한 그래디언트는 모든 공유된 계층에서 누적되고 이 예에서는 두 번째와 세 번째 계층의 그래디언트가 합쳐지게 된다.
3. Parameter Initialization
@Seoyoon.J
매개변수에 대한 적절한 초기화가 필요하며, 딥러닝 프레임워크에서는 디폴트 랜덤 초기화를 제공한다. 종종 다양한 다른 프로토콜에 따라 가중치를 초기화하기도 하는데, 프레임워크는 가장 일반적으로 사용되는 프로토콜을 제공하며, 사용자 정의 초기화를 생성할 수도 있다.
기본적으로 PyTorch는 입력 및 출력 차원에 따라 계산된 범위에서 가중치 및 편향 행렬을 균일하게 초기화한다. PyTorch의 nn.init 모듈은 다양한 초기화 방법을 제공한다.
1) Built-in Initialization
모든 가중치 매개변수를 표준편차 0.01의 가우스 확률 변수로 초기화하는 반면, 편향 매개변수는 0으로 지정한다.
def init_normal(module):
if type(module) == nn.Linear:
nn.init.normal_(module.weight, mean=0, std=0.01)
nn.init.zeros_(module.bias)
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
**# > (tensor([-0.0129, -0.0007, -0.0033, 0.0276]), tensor(0.))**또한 모든 매개변수를 주어진 상수 값(예: 1)으로 초기화할 수도 있다.
def init_constant(module):
if type(module) == nn.Linear:
nn.init.constant_(module.weight, 1)
nn.init.zeros_(module.bias)
net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]특정 층(블럭)마다 다른 초기화 프로그램을 적용할 수도 있다. 예를 들어, Xavier initializer를 사용하여 첫 번째 층을 초기화하고 두 번째 층은 상수 값 42로 초기화할 수 있다.
def init_xavier(module):
if type(module) == nn.Linear:
nn.init.xavier_uniform_(module.weight)
def init_42(module):
if type(module) == nn.Linear:
nn.init.constant_(module.weight, 42)
net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)
**# > tensor([-0.0974, 0.1707, 0.5840, -0.5032])
# > tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])**필요한 초기화 방법이 딥러닝 프레임워크에서 제공되지 않는 경우에는 직접 분포를 정의하여 초기화를 진행할 수 있다.
EX)
def my_init(module):
if type(module) == nn.Linear:
print("Init", *[(name, param.shape)
for name, param in module.named_parameters()][0])
nn.init.uniform_(module.weight, -10, 10)
module.weight.data *= module.weight.data.abs() >= 5
net.apply(my_init)
net[0].weight[:2]
**# > Init weight torch.Size([8, 4])
# > Init weight torch.Size([1, 8])
# > tensor([[ 0.0000, -7.6364, -0.0000, -6.1206],
# > [ 9.3516, -0.0000, 5.1208, -8.4003]], grad_fn=<SliceBackward0>)**또는, 모든 매개변수를 직접 설정할 수도 있다.
net[0].weight.data[:] += 1
net[0].weight.data[0, 0] = 42
net[0].weight.data[0]
**# > tensor([42.0000, -6.6364, 1.0000, -5.1206])**4. Lazy Initialization
@리치
지금까지는 네트워크 설정이 엉성하게 이루어졌다. 특히 아래와 같은 직관적이지 않은 작업을 수행했는데, 이러한 작업은 동작하지 않는 것 처럼 보일 수 있다.
- 네트워크 아키텍처를 정의할 때 입력 차원을 명확하게 지정하지 않았다.
- 이전 레이어의 출력 차원을 지정하지 않고 레이어를 추가했다.
- 모델에 포함해야 할 매개변수 수를 결정하기에 충분한 정보를 제공하기 전에 매개변수를 초기화 하기도 했다.
여기서 프레임워크의 비결은 초기화를 미루고, 모델에 데이터를 처음 전달할 때까지 기다렸다가 각 계층의 크기를 즉석에서 추론 한다는 것이다.
나중에 합성곱 신경망(Convolutional Neural Network)로 작업할 때 입력 차원(이미지 해상도)이 각 후속 레이어의 차원에 영향을 미치기 때문에 이 기술은 편리할 것이다. 따라서 코드를 작성할 때 차원 값을 알 필요 없이 매개 변수를 설정할 수 있어 모델을 지정하고 이후 수정하는 작업을 크게 간소화 가능하다.
우선 MLP를 인스턴스화 해보자. 이 시점에서 네트워크는 입력 차원을 알 수 없기 때문에 입력 레이어의 가중치 차원을 알 수 없다.
net = nn.Sequential(nn.LazyLinear(256), nn.ReLU(), nn.LazyLinear(10))따라서 프레임워크는 아직 매개변수를 초기화 하지 않았다.
net[0].weight
# <UninitializedParameter>이제 네트워크를 통해 데이터를 전달해보자.
X = torch.rand(2, 20)
net(X)
net[0].weight.shape
# torch.Size([256, 20])가중치를 초기화 한 것을 볼 수 있다. 입력 차원인 20을 알면, 프레임워크는 20의 값을 입력하여 첫 번째 레이어의 가중체 행렬의 모양을 식별한다. 이후, 모든 모양을 알 때까지 computational graph를 통해 두 번째 레이어로 이동하는 순서로 진행한다. 현재 예시의 경우 첫 번째 레이어만 Lazy initialization이 필요하지만 프레임워크는 항상 순차적으로 초기화 한다는 점을 유의해야한다. 이제, 모든 파라미터 모양이 알려지면 프레임워크는 파라미터를 초기화 할 수 있다.
아래 방법은 더미 입력을 전달하여 모든 매개변수 모양을 유추하기 위한 Dry run을 수행한 후 매개변수를 초기화 하는 방법이다. 이 방법은 나중에 무작위 초기화를 원하지 않을 때 사용된다!
@d2l.add_to_class(d2l.Module) #@save
def apply_init(self, inputs, init=None):
self.forward(*inputs)
if init is not None:
self.net.apply(init)결론적으로 Lazy initialization은 프레임워크가 매개변수 형태를 자동으로 추론할 수 있어 아키텍처를 쉽게 수정하고 일반적인 오류의 원인을 제거할 수 있어 편리하다!
5. Custom Layers
@Seoyoon.J
광범위한 layer들을 사용하여 다양한 작업에 적합한 아키텍처를 설계할 수 있다. 예를 들어, 이미지, 텍스트 처리, 순차 데이터 반복 및 동적 프로그래밍 수행을 위한 특별한 layer가 있다. 그치만 필요한 layer가 없는 경우, 사용자 정의 layer를 구축해야 한다.
1) Layers without Parameters
자체 매개변수가 없는 사용자 정의 레이어를 구성해보자.
아래 예시는 단순히 입력에서 평균을 빼는 CenteredLayer 클래스로, 기본 레이어 클래스에서 상속하고 순방향 전파 기능을 구현하기만 하면 된다.
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X): # 순방향 전파 기능
return X - X.mean()
layer = CenteredLayer()
layer(torch.tensor([1.0, 2, 3, 4, 5]))
**# > tensor([-2., -1., 0., 1., 2.])**더 복잡한 모델을 구성할 때 정의한 레이어(CenteredLayer)를 구성 요소로 통합할 수 있다.
net = nn.Sequential(nn.LazyLinear(128), CenteredLayer())2) Layers with Parameters
학습을 통해 조정할 수 있는 매개변수를 사용하여 레이어를 정의하는 방법을 알아보자.
내장 함수를 사용하여 매개변수를 생성할 수 있으며, 이는 모델 매개변수에 대한 액세스, 초기화, 공유, 저장 및 로드를 제어한다. 이를 통해 모든 사용자 정의 레이어에 대해 사용자 정의 직렬화 루틴(custom serialization routines)을 작성할 필요가 없어진다.
class MyLinear(nn.Module):
def __init__(self, in_units, units): #parameter : in_units, units
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)
linear = MyLinear(5, 3)
linear.weight
**# > tensor([[ 0.4783, 0.4284, -0.0899],
# [-0.6347, 0.2913, -0.0822],
# [-0.4325, -0.1645, -0.3274],
# [ 1.1898, 0.6482, -1.2384],
# [-0.1479, 0.0264, -0.9597]], requires_grad=True)**사용자 정의 레이어를 사용하여 모델을 구성할 수 있다. 아래 예시와 같이 내장된 완전 연결 레이어처럼 사용할 수 있다.
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))
**# > tensor([[ 0.0000],
# [13.0800]])**6. File I/O
@Seoyoon.J
학습된 모델이 충분히 만족스럽다면 나중에 다양한 상황에서 사용하기 위해 결과를 저장하고 싶을 것이다. 또한, 긴 훈련 프로세스를 실행할 때 중간 결과(체크포인트)를 주기적으로 저장하면 혹시 모를 오류를 대비하는 가장 좋은 방법이다. 따라서 개별 가중치 벡터와 전체 모델을 모두 로드하고 저장하는 방법을 알아보자.
1) Loading and Saving Tensors
개별 텐서(또는 list of 텐서)의 경우 load 및 save 함수를 직접 호출하여 각각 읽고 쓸 수 있다. load 와 save 함수는 이름을 제공해야 하며 저장하려면 저장할 변수를 입력해야 한다.
# save
x = torch.arange(4)
torch.save(x, 'x-file')# load
x2 = torch.load('x-file')
x2
**# > tensor([0, 1, 2, 3])**문자열에서 텐서로 매핑되는 사전을 작성하고 읽을 수도 있다. 이는 모델의 모든 가중치를 읽거나 쓰고 싶을 때 편리하다.
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2
**# > {'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}**2) Loading and Saving Model Parameters
load 와 save 로 개별 가중치 벡터(또는 다른 텐서)를 저장하는 것은 유용하지만 전체 모델(수백 개의 매개변수 그룹을 전체적으로 포함)을 저장하고 로드하려는 경우 시간이 오래 걸릴 수 있다. 이러한 이유로 딥러닝 프레임워크는 전체 네트워크를 로드하고 저장하는 내장 기능을 제공한다. 이 때, 주의할 점은 전체 모델이 아닌 모델 매개변수를 저장한다는 것이다. 매개변수만 저장하는 것은 모델 자체에 임의의 코드가 포함되는 경우 자연스럽게 직렬화될 수 없기 때문이다. 따라서 모델을 복원하려면 코드에서 아키텍처를 생성한 다음 디스크에서 매개변수를 로드해야 한다.
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.LazyLinear(256)
self.output = nn.LazyLinear(10)
def forward(self, x):
return self.output(F.relu(self.hidden(x)))
net = MLP()
X = torch.randn(size=(2, 20))
Y = net(X)
torch.save(net.state_dict(), 'mlp.params') # store the parameters of model모델을 복구하기 위해 원본 MLP 모델의 복제본을 인스턴스화한다. 그리고 모델 매개변수를 무작위로 초기화하는 대신 파일에 저장된 매개변수를 불러온다.
clone = MLP() # 인스턴스화
clone.load_state_dict(torch.load('mlp.params')) # 저장된 매개변수 불러오기
clone.eval()
# > MLP((hidden): LazyLinear(in_features=0, out_features=256, bias=True)
# (output): LazyLinear(in_features=0, out_features=10, bias=True))7. GPUs
@Tommy Kim
GPU는 지난 20년동안 엄청나게 빠른 성장을 보여주었고, 이러한 컴퓨팅 성능을 활용하는 방법에 대한 논의가 이어져 왔다. 우리는 이에 따라 단일 GPU 및 여러 GPU와 서버를 사용하는 방법을 배울 것이다. 특히, NVIDIA GPU에 대한 계산 방법을 배울 것이다. 컴퓨터에 NVIDIA 드라이버와 CUDA를 다운로드 하면, nvidia-smi 명령어를 사용하여 그래픽 카드 정보를 볼 수 있다.
Pytorch에서는 모든 배열이 장치(device)를 가지며, 우리는 이를 종종 context라고 한다. 모든 계산을 지금까지는 CPU에 할당해서 했지만, 일반적으로 context는 GPU가 될 수도 있다. 여러 서버에서 작업을 배포할 때는, 각 서버에 필요한 신경망 모델의 파라미터들을 각 서버의 GPU에 위치시켜야 한다.
1) Computing Devices
저장 및 계산을 위한 장치들로 CPU와 GPU를 지정할 수 있다. 기본적으로 tensor는 CPU가 계산에 사용된다.
Pytorch에서 CPU와 GPU는 torch.device('cpu'),torch.device('cuda') 로 장치를 지정할 수 있다. 처음 CPU로 지정되면 모든 CPU와 메모리를 사용한다. GPU를 장치로 설정하면, 하나의 카드와 하나의 메모리만을 사용한다. 이에 따라 torch.device(f'cuda:{i}') 로 각각의 GPU들을 구분해서 사용할 수 있다.
def cpu(): #@save
"""Get the CPU device."""
return torch.device('cpu')
def gpu(i=0): #@save
"""Get a GPU device."""
return torch.device(f'cuda:{i}')
cpu(), gpu(), gpu(1)
(device(type='cpu'),
device(type='cuda', index=0),
device(type='cuda', index=1))torch 함수를 통해 가용한 GPU의 개수를 알 수도 있다.
def num_gpus(): #@save
"""Get the number of available GPUs."""
return torch.cuda.device_count()
num_gpus()
2사용 가능한 GPU가 없을 때에도 함수를 설정하여 코드가 실행되게 만들 수 있다.
def try_gpu(i=0): #@save
"""Return gpu(i) if exists, otherwise return cpu()."""
if num_gpus() >= i + 1:
return gpu(i)
return cpu()
def try_all_gpus(): #@save
"""Return all available GPUs, or [cpu(),] if no GPU exists."""
return [gpu(i) for i in range(num_gpus())]
try_gpu(), try_gpu(10), try_all_gpus()
(device(type='cuda', index=0),
device(type='cpu'),
[device(type='cuda', index=0), device(type='cuda', index=1)])2) Tensors and GPUs
tensor는 처음 만들어지면 CPU에 위치한다. 또는, CPU가 어디 있는지 함수를 통해 알 수 있다. tensor들끼리는 같은 장치에 있어야 연산이 가능하기 때문에, 각 tensor들이 어디에 위치하는지 아는 것은 매우 중요하다.
x = torch.tensor([1, 2, 3])
x.device
device(type='cpu')a. Storage on the GPU
tensor를 생성할 때 GPU에 저장하는 방법은, 처음 초기화할 때 GPU에 할당하는 것이다.nvidia-smi를 통해 GPU의 메모리 사용량을 알 수 있고, 당연하게도 메모리 허용량을 초과하는 데이터는 저장하지 못한다.
X = torch.ones(2, 3, device=try_gpu())
X
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
Y = torch.rand(2, 3, device=try_gpu(1)) # 두번 째 GPU로 지정
Y
tensor([[0.0022, 0.5723, 0.2890],
[0.1456, 0.3537, 0.7359]], device='cuda:1')b. Copying
위의 X, Y를 살펴보면, 위치한 장치가 다르기 때문에, 둘 사이에서는 연산이 불가능하다. 이때, X를 두번째 GPU로 할당하는 것이 가능하다.
Z = X.cuda(1)
print(X)
print(Z)
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:0')
tensor([[1., 1., 1.],
[1., 1., 1.]], device='cuda:1')그림으로 표현하면 다음과 같다.
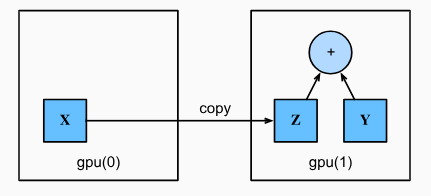
만약 GPU가 중복 호출된다면, GPU 내부에서는 새롭게 메모리를 할당하지는 않고, 기존에 존재하던 인스턴스를 반환하게 된다. 이는 코드상으로 확인이 가능하다.
Z.cuda(1) is Z
Truec. Side Notes
많은 머신러닝 개발자들이 GPU를 쓰는 이유는, 병렬 처리 능력이 뛰어나서 대량의 데이터와 복잡한 연산을 빠르게 처리할 수 있기 때문이다. 하지만 주의할 점은, CPU와 GPU간의 데이터 송수신은 매우 느리다는 점이다. 훈련 데이터를 메모리에서 GPU로 옮기거나, 계산된 결과를 다시 CPU로 가져오는 과정은 계산(computation) 과정보다 더 오래 걸릴 수 있다. 따라서 많은 딥러닝 프레임 워크들은 데이터 이동을 자동으로 수행하지 않고, 개발자들이 명시적으로 필요할때만 수행할 수 있게 만들어 놓았다. 또한, 데이터의 전송은 병렬 처리를 더 복잡하게 만든다. 데이터가 한 장치에서 다른 장치로 전송되는 동안 해당 장치들은 대기 상태에 있어야 하므로, 전체 프로세스의 효율성이 떨어진다. 이에 따라서 작은 단위의 여러 데이터 전송보다는, 큰 단위의 단일 데이터 전송이 더 효율적이다.
→ 반복문으로 요소 하나하나씩 연산하는 것보다, 벡터화나 행렬화하여 계산하는 것이 더 빠른 것과 같은 맥락
Python은 또한 장치에 있는 데이터를 출력하거나, 형식을 바꿀 때(tensor ↔ numpy) 데이터를 먼저 CPU의 메모리로 복사해야한다. 이 과정은 추가적인 오버헤드를 발생시키고, Global Interpreter Lock으로 인해 해당 과정이 끝날때까지 다른 작업이 실행되지 못하는 문제도 발생한다.
GIL: Python의 인터프리터는 한 시점에 하나의 쓰레드에 의해서만 실행될 수 있음 → 병렬 실행이 불가능하다는 의미
3) Neural Networks and GPUs
neural network 모델도 위치할 장치를 설정할 수 있다.
net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize(ctx=try_gpu())
net(X)
array([[0.04995865],
[0.04995865]], ctx=gpu(0))
#앞선 장에서 사용했던 d21 trainer가 GPU를 활용하도록 설정할 수 있다.
@d2l.add_to_class(d2l.Trainer) #@save
def __init__(self, max_epochs, num_gpus=0, gradient_clip_val=0):
self.save_hyperparameters()
self.gpus = [d2l.gpu(i) for i in range(min(num_gpus, d2l.num_gpus()))]
@d2l.add_to_class(d2l.Trainer) #@save
def prepare_batch(self, batch):
if self.gpus:
batch = [a.to(self.gpus[0]) for a in batch]
return batch
@d2l.add_to_class(d2l.Trainer) #@save
def prepare_model(self, model):
model.trainer = self
model.board.xlim = [0, self.max_epochs]
if self.gpus:
model.to(self.gpus[0])
self.model = model