1. From Fully Connected Layers to Convolutions
@Seoyoon.J
고양이와 개를 구별하기 위해 one-mega 픽셀(1million pixels) 이미지를 수집했다 가정하면, 이는 네트워크에 대한 입력이 백만 개의 차원을 갖는다는 것을 의미한다. 은닉층의 차원을 1000으로 확 줄이려면 개의 파라미터를 갖는 fully connected layer가 필요하다. 많은 GPU, 분산 최적화 능력, 엄청난 인내심이 없으면 이 네트워크의 매개변수를 학습하는 것이 불가능할 수 있다.
물론 10만 픽셀이면 충분할 수 있지만, 1000개의 은닉 노드 수 만으로는 이미지의 좋은 표현을 학습하는데 부족하기 때문에 여전히 수십억개의 매개변수가 필요하다. 게다가 너무 많은 매개변수를 적용하여 분류기를 학습하려면 막대한 데이터 세트를 수집해야 할 수도 있다.
다행히 이미지는 기계 학습 모델이 활용할 수 있는 풍부한 구조를 나타내고, CNN(합성곱 신경망)은 이미지의 알려진 구조 중 일부를 활용하기 위해 머신러닝이 채택한 창의적인 방법 중 하나이다.
1) Invariance
이미지 내에서 물체를 인식하기 위해 사용하는 방법이 무엇이 되었든 물체의 정확한 위치에 지나치게 관심을 가져서는 안 된다는 것이 합리적일 것이다. 돼지는 일반적으로 날지 않으며 비행기는 일반적으로 수영하지 않지만 돼지가 이미지 상단에 나타날 수 있다.
각 패치에 점수를 할당하여 패치에 객체가 포함될 가능성을 나타내는 객체 감지기로 이미지를 훑어볼 수 있다. 실제로 많은 객체 감지 및 분할(segmentation) 알고리즘이 이 접근 방식을 기반으로 한다. CNN은 공간 불변성(invariance)에 대한 아이디어를 체계화하여 더 적은 수의 매개변수로 유용한 표현을 학습하는 데 활용한다.
컴퓨터 비전에 적합한 신경망 아키텍처 설계를 위한 구체화(원칙)
1. 초기 레이어에서 네트워크는 이미지의 위치에 관계없이 동일한 패치에 유사하게 반응해야 한다. ( = translation invariance or translation equivariance) - 2)-a
2. 이미지의 한 지점에 대해 초기 레이어는 먼 영역보다는 주변 영역에 초점을 맞춰야 한다. ( = locality principle) 이러한 로컬 표현을 집계하여 전체 이미지 수준에서 예측할 수 있다. - 2)-b
3. 점점 더 깊은 레이어가 이미지의 더 먼 범위의 특징을 캡처할 수 있어야 한다.
2) Constraining the MLP
Input 와 은닉층 출력값(hidden representations) 가 모두 2차원이라고 가정하자. 입력뿐만 아니라 은닉층 값도 공간 구조(spatial structure, 공간 정보)를 가지고 있다고 예상해볼 수 있다.
각 은닉 노드이 각 입력 픽셀로부터 입력을 받도록 하기 위해 매개변수를 4차 가중치 텐서 로 표현하고 에 편향이 포함되어 있다고 하면, fully connected layer는 다음과 같이 표현할 수 있다.
와 는 4차 텐서의 계수 간에 일대일 대응이 있기 때문에 외부 표현만 바뀐 것이라 보면 된다. , 로 치환함에 따라 가 양수, 음수값을 가지며 이미지의 전체 영역을 커버할 수 있게 된다. 위치의 hidden representation 는 를 중심으로 에 의해 가중치가 부여된 의 픽셀을 합산하여 값을 계산함에 따라 구할 수 있다.
단일 레이어에 필요한 총 매개변수 수를 고려해보면, 1000x1000 이미지가 1000x1000 hidden representation으로 매핑됨으로 총 개의 파라미터가 필요하다. 이는 현재 컴퓨터가 다룰 수 있는 크기이다.
a. Translation Invariance
입력 의 이동이 단순히 hidden representation 의 이동으로 이어지는 것을 의미한다. 즉, 입력 위치가 변하면 출력도 위치가 변해서 나오기 때문에 다양한 위치에서 특징 추출이 가능하며 추출된 특징들은 동일하다. 단, 이는 와 가 실제로 에 의존하지 않는 경우에만 가능하다. 를 단순히 정의하면 다음과 같다.
이것이 바로 convolution 이다. 를 얻기 위해 계수 를 사용하여 위치 근처의 에 있는 픽셀에 효과적으로 가중치를 부여한다. 는 더 이상 이미지 내의 위치에 의존하지 않기 때문에 보다 훨씬 적은 계수가 필요하다. 따라서 파라미터의 수는 .
Time-delay neural networks (TDNNs)은 이 아이디어를 활용한 예시 중 일부이다.
하지만 이미지에서 단순히 위치에 상관없이 얼굴의 특징인 눈, 코, 입만 가지고 있다고 얼굴이라 예측하면 안된다. 즉, 이러한 translation invariance learning은 공간 관계를 학습하지 못하는 단점을 가지고 있다.
[Paper Reading2] Transforming Auto-Encoder Background; Translation Equivariance vs Invariance
b. Locality
의 정보를 알고자 관련 정보를 수집할 때 위치에서 아주 먼 영역을 볼 필요는 없다. 이는 곧 또는 범위에서 임을 의미한다. 이에 따라 를 다시 정리하면,
이를 통해 파라미터의 수를 에서 로 줄일 수 있다. 위 식은 곧 ‘convolutional layer’라고 부를 수 있다.
CNN(합성곱 신경망)은 컨볼루션 레이어를 포함하는 특수한 신경망 모델이다. 는 컨볼루션 커널(convolution kernel), 필터(filter) 또는 학습 가능한 매개변수인 레이어의 가중치라고 한다.
3) Convolutions
왜 위 를 ‘convolution(합성곱)’이라 부르는지 알아보자. 두 함수의 합성곱은 다음과 같이 정의된다.
즉, 하나의 함수가 뒤집어지고 x만큼 이동될 때 f와 g 사이의 중첩을 측정한 것이다. 변수가 정수 집합()에 포함되는 이산 값이라고 한다면 다음과 같이 합으로 나타낼 수 있다.
2차원 tensor에 대해서는 다음과 같이 정의된다.
가 로 바뀐 것만 제외하면 는 와 거의 유사함을 알 수 있다. 가 cross-correlation(상호 상관)을 더 적절하게 설명한다.
4) Channels
위에서 말한 ‘객체 탐지기’가 어떤 것인지 살펴보자. 컨벌루션 레이어는 주어진 크기의 창(windows)을 선택하고 필터 에 따라 가중치를 부여한다. 찾고자 하는 객체가 있을 확률을 높여줄 수 있도록 하는 가장 적절한 은닉층 표현을 찾을 수 있도록 모델을 학습하는 것을 목표로 할 수 있다.
앞선 예시에서는 이미지를 2차원으로 바라보며 이미지가 RGB 채널로 구성되어 있다는 사실을 무시했다. 이미지는 높이, 너비 및 채널을 특징으로 하는 3차원 텐서이다. 높이와 너비는 공간 관계에 관한 반면, 채널은 각 픽셀 위치에 다차원 표현을 할당하는 것으로 간주될 수 있다. 즉, 로 표기된다. 필터도 마찬가지로 로 표기된다. Hidden representation도 3차 텐서로 공식화 하는 것은 유용한 아이디어임이 밝혀졌다. 즉, 각 공간 위치에 해당하는 단일 은닉 표현을 갖는 것이 아니라 각 공간 위치에 해당하는 은닉 표현의 전체 벡터로 나타내고자 한 것이다. 은닉 표현을 여러 개의 2차원 그리드로 구성된 것으로 생각할 수 있다. 이는 후속 레이어에 대해 학습된 feature의 공간화된 집합을 제공하므로 ‘feature map’이라고 부른다(또는 종종 channel이라 부르기도 함). 직관적으로 입력에 더 가까운 하위 레이어에서 일부 채널은 가장자리를 인식하도록 특화되고 다른 채널은 텍스처를 인식할 수 있다고 상상할 수 있다. 3차원 채널을 고려하여 식을 다음과 같이 정리할 수 있다. 이때, 는 의 output channel을 의미한다.
후속 컨벌루션 레이어는 계속해서 입력으로 3차 텐서를 취하게 된다. 일반성을 위해 위 식을 여러 채널에 대한 convolutional layer로 정의하여 사용한다.
하지만 아직 해결해야 할 작업들이 많다. 예를 들어, 모든 은닉 표현을 단일 출력으로 결합하는 방법을 알아야 한다(최종적인 객체 등장 여부 파악을 위해) . 또한 효율적으로 계산하는 방법, 여러 계층을 결합하는 방법, 적절한 활성화 함수, 실제로 효과적인 네트워크를 생성하기 위한 합리적인 설계 선택 방법을 결정해야 한다.
2. Convolutions for Images
@Tommy Kim
1) The Cross-Correlation Operation
convolutional(합성곱) 연산은 사실 cross-correlation 연산을 수행하는 것과 동일하다. convolutional layer에서는 입력 텐서와 커널 텐서가 결합되어 교차 상관 연산(cross-correlation operation)을 수행한다.
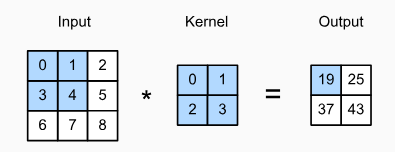
다음의 그림을 살펴보자. 입력 텐서는 3 X 3 크기의 텐서이고, 커널은 2 X 2의 크기이다. 커널 창은 처음에 왼쪽 상단 모서리에 위치하고, 왼쪽에서 오른쪽으로, 위에서 아래로 입력 텐서를 가로 질러 이동시킨다. 커널 창이 특정 위치에 위치할 때, 입력 텐서의 해당 위치와 커널 텐서는 요소별로 곱해져서 단일 스칼라 값이 된다. 위의 예시에 따라 연산을 수행하면, 출력 텐서의 첫번 째 값은 이다. 이렇게 연산을 수행한 출력 텐서의 크기는 입력 크기에서 합성곱 커널의 크기를 뺀 만큼인데, 식으로 표현하면 다음과 같다.
커널의 크기는 1보다 크기 때문에 커널을 이동시킬 충분한 공간이 필요하다. 이 때문에 입력 텐서의 크기가 더 클 수밖에 없고, 커널이 이동할 공간을 더욱 확보하기 위해 주변에 0을 채우는 padding 방법도 존재한다. 아래 코드는 이러한 cross-correlation operation을 구현한 예시이다.
def corr2d(X, K): #@save
"""Compute 2D cross-correlation."""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)
tensor([[19., 25.],
[37., 43.]])2) Convolutional Layers
convolutional layer에서는 위에서 언급된 cross-correlation operation을 적용한 후에 스칼라 값이 bias를 더해 출력을 생성한다. 합성곱 층의 두 매개변수는 커널과 편향이다. fully-connected layer와 마찬가지로 두 파라미터를 훈련시킬 때, 커널과 편향을 무작위로 초기화한다. 위의 corr2d 함수를 기반으로 2차원 합성곱 계층을 구현하면 다음과 같다.
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias3) Object Edge Detection in Images
convolutional layer를 적용한 간단한 예시를 살펴보자. 다음의 예시는 픽셀의 변화의 위치를 찾아 이미지에서 물체의 가장 자리를 감지하는 예시이다. 먼저 6 X 8크기의 이미지( 4개의 중간 열은 검은색(0)이고, 나머지는 흰색(1)) 를 표현한 텐서를 초기화한다.
X = torch.ones((6, 8))
X[:, 2:6] = 0
X
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])다음으로 높이가 1이고, 너비가 2인 커널 k를 초기화한다. 만약 커널의 위치가 라면, 의 연산을 수행한다. 이는 수평으로 인접한 픽셀의 차이를 계산하는 것이다. 이것은 곧 수평 방향의 첫 번째 미분에 대한 이산 근사치이다 : (?).
출력 텐서를 구해보면 다음과 같다.
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
Y
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
#커널을 전치된 이미지에도 적용할 수 있다.
corr2d(X.t(), K)
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])4) Learning a Kernel
위에서 사용한 [1, -1]의 edge detector 커널은 우리가 정확히 찾고 있는 것을 알고 있을 때 유용하다. 하지만, 더 큰 커널을 보고 연속적인 convolutional layer를 고려할 때, 각 상황마다 커널 필터를 지정하는 것은 불가능하다.
그렇다면 입력과 출력의 쌍을 보고 커널을 학습해보자. 먼저 합성곱 층을 구성하고, 해당 층에 사용되는 커널을 무작위 텐서로 초기화한다. 그다음으로, 합성곱 층의 출력과 Y를 비교하기 위해 squared error를 사용할 것이다. 그 다음에 커널을 업데이트 하기 위한 gradient를 계산할 수 있다. 계산의 편의 위해 다음의 예시는 2차원 합성곱 층의 내장 class를 사용하고, bias는 무시했다.
# Construct a two-dimensional convolutional layer with 1 output channel and a
# kernel of shape (1, 2). For the sake of simplicity, we ignore the bias here
conv2d = nn.LazyConv2d(1, kernel_size=(1, 2), bias=False)
# The two-dimensional convolutional layer uses four-dimensional input and
# output in the format of (example, channel, height, width), where the batch
# size (number of examples in the batch) and the number of channels are both 1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # Learning rate
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# Update the kernel
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i + 1}, loss {l.sum():.3f}')
epoch 2, loss 16.481
epoch 4, loss 5.069
epoch 6, loss 1.794
epoch 8, loss 0.688
epoch 10, loss 0.274위에서 알 수 있듯, 10번의 반복만에 loss의 값이 꽤 작은 숫자로 줄어든 것을 확인할 수 있었다. 학습된 커널을 확인해보면 다음과 같다.
conv2d.weight.data.reshape((1, 2))
tensor([[ 1.0398, -0.9328]])학습된 커널은 처음에 사용했던 edge detector와 크게 다르지는 않았다.
5) Cross-Correlation and Convolution
앞서 구현했던 cross-correlation operation을 사용하는 것이 아닌, convolutional layer에서 엄격한 합성곱 연산을 수행한다면 어떻게 될까? 이에 대한 결과를 얻기 위해서는 2차원 커널 텐서를 수평 / 수직으로 뒤집은 다음, 입력 텐서와 교차 상관 연산을 수행하면 된다.
딥러닝의 커널이 데이터로부터 학습되는 과정에서, 합성곱 계층의 출력은 엄격한 연산을 수행하든, 단순 교차 상관 연산을 수행하든 영향을 받지 않는다.
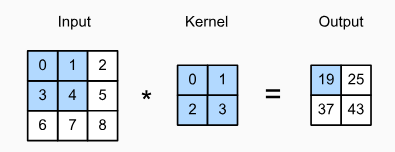
실제로 위의 연산을 strict convolution으로 수행한다고 해보자. 이에 따라 커널 K를 학습한다고 할 때, 학습된 K’은 K와 수평 / 수직으로 뒤집은 것과 동일해질 것이다. 이렇게 학습을 해도 결국 출력 텐서의 값은 같게 된다.
이에 따라서, 연산의 결과가 차이가 없기 때문에 우리는 계속 convolutional operationrhk cross-correlation operation에 차이를 두지 않을 것이고, 각 텐서의 entry를 element(요소)로 정의할 것이다.
6) Feature Map and Receptive Field
앞에서 설명한 바와 같이, 출력 텐서(합성곱 연산의 출력)은 때때로 feature map이라고 부른다. 이는 공간적 차원(너비와 높이)에서 학습된 표현으로, 이후의 layer들에게 영향을 주기 때문이다. CNN에서 특정 요소 에 대해서, receptive field는 이전 layer에서 를 계산할 때 영향을 준 모든 요소들을 말한다. receptive field는 입력 텐서보다 클 수 있다.
위의 합성곱 연산 이미지를 다시 살펴보자. 출력 텐서의 19의 receptive field는 Input tensor에 해당하는 네 개의 요소(0, 1, 3, 4)이다. 여기서 위의 이미지의 Output을 다시 Input()으로 하는 convolutional layer를 하나 더 추가했다고 가정해보자. 이때의 출력을 단일 요소 라고 하면, 의 receptive field는 의 모든 요소이고, 그 이전의 모든 9개의 요소이다. 특정 이미지를 detect(감지)하기 위해 더 넓은 범위의 feature들이 필요하다면, 우리는 더 깊은 네트워크를 만들어 해결할 수 있다.

Field(1987)에서 진행된 연구에 따르면, 이미지 처리를 위해 여섯 가지 다른 유형의 센서를 도입하였다. 이 센서들은 이미지의 다양한 공간적 특징을 감지하기 위해 설계되었다. 그림의 왼쪽 부분은 각각의 채널에 해당하는 여섯 가지 센서의 예시를 보여준다. 그림의 오른쪽 부분은 왼쪽의 센서들과 이미지를 합성곱한 결과이다.
3. Padding and Stride
@리치
만약, 입력의 모양이 이고, 컨볼루션 커널의 모양이 라면, 출력의 모양은 이다. 이때, 컨볼루션 커널은 컨볼루션을 적용할 픽셀이 부족해질 때까지만 이동시킬 수 있다.
예를 들어, 입력 이미지가 5x5 픽셀이고 커널이 3x3 픽셀이라면, 출력 이미지는 3x3 픽셀 크기가 된다. 커널이 이미지의 가장자리를 넘어갈 수 없기 때문에, 각 가장자리에서 1픽셀씩 잘리게 되기 때문이다.
이번 장에서는 출력 크기를 더 잘 제어할 수 있는 패딩(Padding) 및 스트라이드 컨볼루션(Strided Convoultion)을 포함한 여러 가지 기법을 살펴본다. 일반적으로 커널의 너비와 높이가 1보다 크기 때문에, 많은 컨볼루션을 연속적으로 적용한 후에는 입력보다 작은 출력을 얻게 되는 경향이 있다. 240240 픽셀 이미지로 시작할 경우, 55 컨볼루션을 10번 적용하면 이미지는 200*200 픽셀로 줄어들며, 원본 이미지의 경계에 있는 흥미로운 정보가 사라지면서 이미지의 30%가 잘려나간다. 이러한 문제를 해결하기 위해 패딩을 사용한다. 다른 경우에는, 원본 입력 해상도를 다루기 힘들다고 판단될 때 차원을 대폭 줄이고 싶을 수 있다. 이러한 경우에 도움이 되는 인기 있는 기술이 바로 스트라이드 컨볼루션이다.
1) Padding
앞서 말했듯, 컨볼루션 레이어를 적용할 때 까다로운 문제 중 하나는 이미지 경계에서 픽셀이 손실된다는 점이다. 아래 그림을 보면, 모서리에 있는 픽셀이 거의 사용되지 않는다는 것을 볼 수 있다.
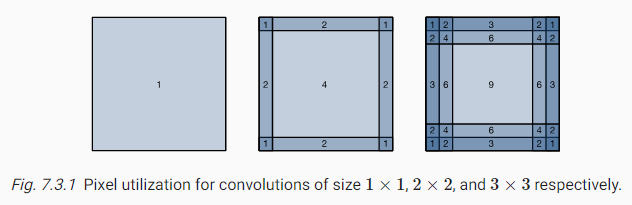
일반적으로 작은 커널을 사용하기 때문에 특정 컨볼루션에 대해 몇 픽셀만 손실될 수 있지만, 연속적인 컨볼루션 레이어를 여러 번 적용하면 손실되는 픽셀이 누적 수 있다. 간단한 해결책은 입력 이미지의 경계에 픽셀을 추가하여 이미지의 유효 크기를 늘리는 것 이다. 일반적으로 추가 픽셀의 값은 0으로 한다. 아래 그림 7.3.2에서는 33입력을 패딩하여 55로 크기를 늘렸다. 이에 출력이 4*4로 증가하게 되었다. 음영 처리된 부분은 첫 번째 출력 요소와 출력 계산에 사용되는 입력 및 커널 텐서 요소이다.:
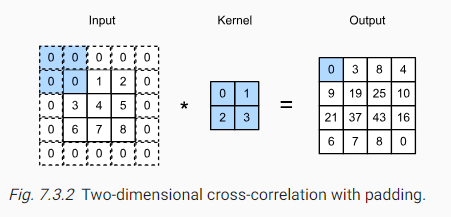
만약 우리가 총 행의 패딩(대략 위와 아래에 절반씩)과 총 의 열의 패딩(대략 왼쪽과 오른쪽에 절반씩)을 추가한다면, 출력의 모양은:
즉, 출력의 높이와 너비가 각각 와 만큼 증가함을 의미한다.
많은 경우에 입력과 출력이 동일한 높이와 너비를 가지도록 과 로 놓는다. 이렇게 하면, 네트워크를 구성할 때 각 레이어의 출력 모양을 예측하기 쉬워진다.
- 가 홀수라면, 높이의 양쪽에 행씩 패딩을 추가한다.
- 가 짝수라면, 입력의 상단에 행, 하단에 행씩 패딩을 추가한다.
CNN은 일반적으로 1,3,5,7과 같이 높이와 너비 값이 홀수인 컨볼루션 커널을 사용한다. 홀수 크기의 커널을 선택하는 이점은 위, 아래, 왼쪽, 오른쪽에 동일한 수의 행과 열을 패딩하여 차원을 유지할 수 있다는 점이다.
이러한 홀수 커널과 차원성을 정확히 유지하기 위한 패딩 사용 방식은 관리상의 이점을 제공한다. 어떤 2차원 텐서 X에 대해, 커널의 크기가 홀수이고 모든 면의 패딩 행과 열의 수가 동일하여 입력과 동일한 높이와 너비를 가진 출력을 생성할 때 출력 Y[i, j]는 입력과 컨볼루션 커널의 교차 상관에 의해 X[i, j]를 중심으로 한 창에서 계산된다는 것을 알 수 있다.
즉, 커널 중심에 정확한 픽셀이 위치하게 된다. (중심점을 기준으로 좌우 대칭이 되도록함) 또한, 일반적으로 33을 많이 사용한다. 이는, 홀수이기도 하며, 55는 너무 넓은 범위이기 때문이다. 또한, 과거에 비해 컴퓨터의 성능이 좋아져 깊이(depth)를 깊게 가져갈 수 있기 때문이다!
아래 예시에서, 높이와 너비가 3인 2차원 컨볼루션 레이어를 만들고, 모든 면에 1픽셀 패딩을 적용한다. 이때, 높이와 너비가 8인 입력을 주어 출력의 높이와 너비가 8로 동일함을 확인할 수 있다.
# We define a helper function to calculate convolutions. It initializes the
# convolutional layer weights and performs corresponding dimensionality
# elevations and reductions on the input and output
def comp_conv2d(conv2d, X):
# (1, 1) indicates that batch size and the number of channels are both 1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# Strip the first two dimensions: examples and channels
return Y.reshape(Y.shape[2:])
# 1 row and column is padded on either side, so a total of 2 rows or columns
# are added
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
# torch.Size([8, 8])당연하게도 컨볼루션 커널의 높이와 너비가 다른 경우, 높이와 너비에 다른 패딩 값을 설정하여 출력과 입력의 높이와 너비를 동일하게 만들 수 있다.
# We use a convolution kernel with height 5 and width 3. The padding on either
# side of the height and width are 2 and 1, respectively
conv2d = nn.LazyConv2d(1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
# torch.Size([8, 8])2) Stride
교차 상관 관계를 계산할 때는 입력 텐서의 왼쪽 위 모서리에 있는 컨볼루션 창에서 시작한 다음 아래쪽과 오른쪽의 모든 위치로 슬라이드 한다. 이전 예제에서는 기본적으로 한 번에 한 요소씩 슬라이딩했다. 그러나 계산 효율성이나 다운 샘플링(downsample)을 하고 싶어서 중간 위치를 건너뛰고 이동하는 경우가 있다. 이는 컨볼루션 커널이 기본 이미지의 넓은 영역을 캡처하기 때문에 커널이 큰 경우에 특히 유용하다.
슬라이드당 이동하는 행과 열의 수를 스트라이드(Stride, 보폭)이라고 한다. 지금까지는 높이와 너비 모두 1인 스트라이드를 사용했다. 그림 7.3.3은 스트라이드가 세로는 3, 가로는 2인 교차 상관 관계 연산을 보여준다. 음영 처리된 부분은 출력 요소와 출력 계산에 사용되는 입력 및 커널 텐서 요소이다:
첫 번째 열의 두 번째 요소가 생성되면 컨볼루션 창이 세 행 아래로 미끄러지는 것을 볼 수 있다. 첫 번째 행의 두 번째 요소가 생성되면 컨볼루션 창은 두 개의 열을 오른쪽으로 슬라이드한다. 컨볼루션 창이 입력에서 오른쪽으로 두 열을 계속 슬라이드하면 입력 요소가 창을 채울 수 없기 때문에 출력이 없다.
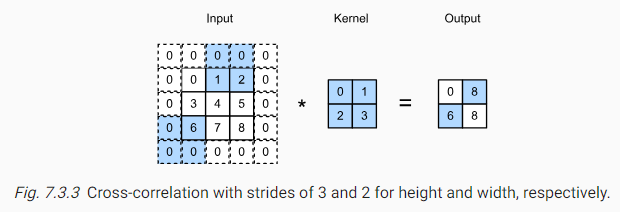
일반적으로, 스트라이드를 위한 높이가 이고 너비가 일 때 출력의 모양은
만약, 우리가 과 로 놓는다면, 출력은 간단하게 이 된다. 더 나아가, 입력의 높이와 너비를 높이와 너비의 스트라이드로 나눌 수 있다면 가 된다.
아래 코드에서는 높이와 너비의 스트라이드를 모두 2로 설정하여 입력 높이와 너비를 절반으로 줄였다.
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
# torch.Size([4, 4])
conv2d = nn.LazyConv2d(1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
# torch.Size([2, 2])패딩을 언제 0이 아닌 것을 사용해야 하는지에 대한 명확한 사례는 없다!
4. Multipe Input and Multiple Output Channels
@Tommy Kim
지금까지 우리는 여러 채널(RGB)와 여러 채널에 대한 convolutional layer보다는 단일 입력과 단일 출력 채널로만 작업하여 모든 예시를 단순화하였다. 이에 따라 입력과 커널, 출력 모두 2차원 텐서라고 간주하여 작업을 진행하였다. 여기에 채널을 추가하면, 3차원 텐서가 된다. 보통의 이미지는 Red, Green, Blue의 3가지 채널을 가지고 있다.
1) Multiple Input Channels
만약, 우리의 입력 데이터가 multiple channels를 가지고 있다면, 우리는 각 채널의 수에 맞게 cross-correlation operation을 수행할 커널을 준비해야 한다. 입력 데이터의 채널 수를 라 하고, 커널의 모양을 라고 하자. = 1이라면 커널은 2차원의 텐서로써 앞 장에서 배웠던 작업과 동일한 작업을 수행한다.
하지만 채널 수가 1보다 크다면, 커널은 3차원 텐서인 가 된다. 3차원 텐서에 대한 작업을 수행할 때 각 채널의 입력 텐서와 그에 대응하는 커널들과 cross-correlation operation을 수행한 다음, 최종 출력 텐서를 표현할 때 각 출력들의 값을 elemenwise로 더한 다음에 2차원 텐서로 반환한다. 다음은 multiple-channel input에 대한 예시이다.
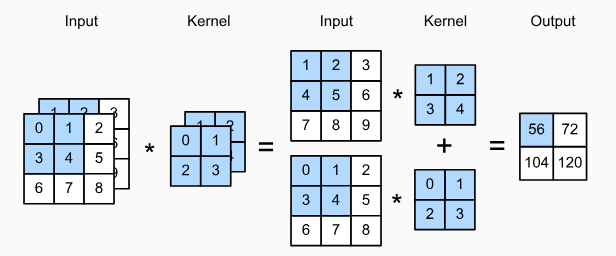
하늘색으로 칠해진 output의 첫번째 요소만 살펴보자면, 다음과 같은 연산을 통해 출력된다.
위의 연산을 코드로 구현하면 다음과 같다.
def corr2d_multi_in(X, K):
# Iterate through the 0th dimension (channel) of K first, then add them up
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
#multiple channel에 해당하는 임의의 입력 텐서와 커널 생성
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)
tensor([[ 56., 72.],
[104., 120.]])2) Multiple Output Channels
위의 1)에서는 하나의 채널만을 갖는 네트워크를 살펴보았지만, 실제 이미지 처리 문제에서는 출력 텐서는 여러개의 채널을 가진다. 가장 인기 있는 neural network는 층이 깊어질 수록 채널의 차원을 늘린다. 이때, 해상도를 줄이는 대신, 채널 깊이를 늘리는 과정은 trade off 관계에 있다. 또한, 채널들은 독립적으로 결과에 mapping된다기보다, 각각이 서로 상호작용하며 학습되며, 채널 간의 공간 정보에서 특정 direction과 특정 edge를 감지할 수 있게 된다.
기존의 커널은 이었는데, 입력 채널 수와 출력 채널 수를 달리할 수 있으므로, 좀더 일반적인 커널의 크기는 가 된다. 입출력 채널 수를 다르게 할 때, cross-correlation function을 다음과 같이 구현할 수 있다.
def corr2d_multi_in_out(X, K):
# Iterate through the 0th dimension of K, and each time, perform
# cross-correlation operations with input X. All of the results are
# stacked together
return torch.stack([corr2d_multi_in(X, k) for k in K], 0) #출력 채널 : k
K = torch.stack((K, K + 1, K + 2), 0) #0은 stack할 dimension을 따로 지정해주지 않은 것
#K + 1, K + 2는 각 커널에 elementwise로 더해준 것
K.shape
torch.Size([3, 2, 2, 2]) # 채널 수 3개, 각 채널마다 dimension은 2씩
corr2d_multi_in_out(X, K)
#하나의 텐서로 합쳐진 것을 알 수 있다.
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])3) Convolutional Layer
convolutional layer는 커널의 높이와 너비가 모두 1인 커널인데, 인접한 픽셀의 영향을 고려하는 일반적인 커널과는 달리 크기가 1인 커널은 큰 의미가 없어보일 수 있지만, 매우 복잡하고 deep한 neural network에서는 꽤나 의미가 있다.
커널의 크기가 1밖에 되지 않기 때문에 높이와 너비 차원에서의 공간적 정보를 반영하는 능력은 잃게 된다. 이 커널의 계산은 유일하게 채널 차원에서만 일어나게 된다.
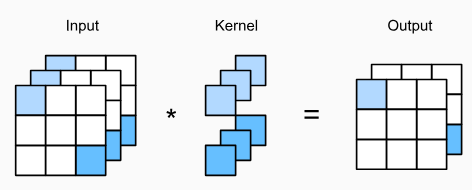
크기가 1이지만, 여전히 커널의 특징을 갖고 있기 때문에, 각 채널에서는 각각의 가중치(bias 포함)가 설정되어있고, 최종 출력을 계산할 때는 같은 위치의 픽셀들의 선형 조합으로 이루어진다. convolutional layer는 출력 채널의 차원을 줄여줄 수 있기 때문에, 다른 합성곱으로는 대체할 수 없는 고유한 기능을 가진다.
https://hwiyong.tistory.com/45
convolutional layer를 사용하면, 채널 수 조절, 계산량 감소, 비선형성 증가(더 복잡한 패턴 학습 가능) 등의 장점이 있다.
convolutional layer를 구현하기 위해, reshape 함수와 완전 연결 층 함수로 구현하면 다음과 같다.
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 완전 연결 계층에서의 행렬 곱셈
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
#cross-correlation은 위의 함수 그대로 사용!
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-65. Pooling
@리치
많은 경우 우리의 궁극적인 작업은 이미지에 대한 전반적인 질문이다. e.g 이미지에 고양이가 있나요? 점진적으로 정보를 집약하여, 점점 더 거친 맵을 생성함으로써 이러한 전반적인 표현을 학습하는 목표를 달성하면서 동시에 처리의 중간 레이어에서 컨볼루션 레이어의 모든 장점을 유지한다. 네트워크의 깊이가 깊어질수록 각 히든 노드가 민감하게 반응하는 수용 영역(receptive field) (입력에 비해)이 커진다. (전역 적인 특징에 민감해진다.) 공간 해상도를 줄이는 것은 이 과정을 가속화한다. 왜냐하면 컨볼루션 커널이 더 큰 효과적 영역을 커버하기 때문이다. (해상도가 줄어든다는 것은, 이미지의 크기가 줄어드는 것이며, 상대적으로 더 큰 영역을 커버하게 된다!)
- 수용필드: 신경망의 노드(뉴런)가 입력 데이터의 어떤 부분에 반응하는지를 나타내는 영역
또한, 낮은 수준의 특징, 예를 들어 가장자리를 감지할 때, 우리는 종종 표현이 이동에 다소 불변하길 원한다. (translation invariance) 예를 들어, 검은색과 흰색 사이에 뚜렷한 구분이 있는 이미지 X를 오른쪽으로 한 픽셀 이동시킨다고 가정하면, 즉 Z[i, j] = X[i, j + 1]이라면, 새 이미지 Z에 대한 출력은 크게 달라질 수 있다. (가장자리가 한 픽셀 이동했을 것이다.) 객체는 거의 같은 위치에 정확히 나타나지 않는다. 삼각대와 정지한 객체를 사용하더라도, 셔터의 움직임으로 인한 카메라의 진동이 모든 것을 한 픽셀 정도 이동시킬 수 있다.
이번 섹션에서는 이러한 컨볼루션 레이어의 위치에 대한 민감도를 완화하고 공간적으로 다운 샘플링된 표현을 완화하는 두 가지 용도로 사용되는 풀링(pooling) 레이어에 대해 소개한다.
1) Maximum Pooling and Average Pooling
합성곱 레이어와 마찬가지로, 풀링 연산자는 스트라이드에 따라 입력의 모든 영역 위로 슬라이드 하는 고정 형태의 윈도우로 구성되며, 윈도우가 통과하는 각 위치에 대해 단일 출력을 계산한다. (pooling window라고도 부른다.) 그러나 컨볼루션 계층에서 입력과 커널의 교차 상관 관계를 계산하는 것과 다르게 풀링 계층에서는 어떠한 파라미터도 포함하지 않는다. (Kernel이 없다.) 대신에, 풀링 연산자는 결정적이며, 일반적으로 풀링의 최대값 혹은 평균값을 계산한다. 이러한 연산을 각각 최대 풀링(maximum pooling, max-pooling)과 평균 풀링(average pooling)으로 부른다.
Average Pooling은 CNN보다 오래된 기법이다. 이 개념은 다운 샘플링과 비슷하다. 저해상도 이미지의 두 번째 픽셀의 값만 취하는 것이 아니라, 인접한 여러 픽셀에 대한 평균을 구해 신호 대 잡음비(signal-to-nosie ratio)가 좋은 이미지를 얻을 수 있다. Max-pooling은 1999년 인지 신경과학의 맥락에서 물체 인식을 위해 정보를 계층적으로 집계하는 방법을 설명하기 위해 도입되었으며, 음성 인식에서는 이미 그 이전 버전이 있었다고 한다. 거의 모든 경우 Average보다 Max-pooling이 좋다!
두 경우 모두 교차 상관 연산자와 마찬가지로 풀링 윈도우는 입력 텐서의 왼쪽 상단에서 시작하여 오른쪽으로, 위에서 아래로 슬라이드 하며 이동하는 것으로 생각할 수 있다. 풀링 윈도우가 닿는 각 위치에서, 서브텐서의 Max 혹은 Average 값을 계산한다.
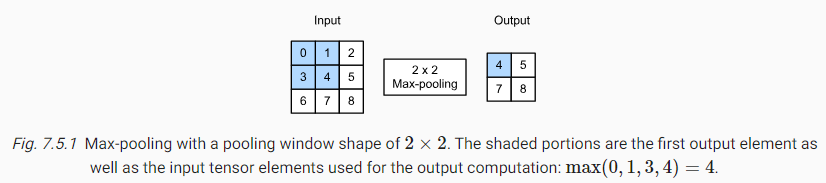
그림 7.5.1의 출력 텐서는 높이와 너비가 모두 2이다. 4개의 요소들은 Max-pooling에 의해서 값이 도출되게 된다.
더 일반적으로, 특정 영역을 집계하여 의 풀링 레이어를 정의할 수 있다. 다시, Edge Detection 문제로 돌아가서, 컨볼루션 레이어의 출력을 Max-pooling의 입력으로 사용한다. 컨볼루션 레이어의 입력을 X로, 풀링 레이어의 출력을 Y로 표시하자. 풀링 레이어는 X[i, j], X[i, j + 1], X[i+1, j] 그리고 X[i+1, j + 1]의 값이 다른지 여부에 관계없이 항상 Y[i,j]를 출력한다. 즉, 컨볼루션 레이어가 인식한 패턴이 세로 또는 가로 방향으로 한 요소(픽셀) 이내로 이동하더라도 이를 감지할 수 있으며 앞서 언급한 Translation Invariance를 제공한다. (특정 특징이 풀링 윈도우 내에서 약간 이동했더라도, 최대값은 변하지 않으므로, 풀링 레이어의 출력도 동일하게 유지?)
아래 코드는 pool2d 함수에서 풀링 레이어의 순방향 전파를 구현했다. (섹션 7.2의 corr2d 함수와 유사) 그러나 앞서 말했듯이 커널이 필요없다.
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2)) # or pool2d(X, (2, 2), 'avg')
# tensor([[4., 5.],
# [7., 8.]])
2) Padding and Stride
딥러닝 프레임워크에 내장된 2차원 최대 풀링 레이어를 통해 패딩과 스트라이드를 사용할 수 있다. 먼저 예제 수(배치 크기)와 채널 수가 모두 1인 4차원 모양을 가진 입력 텐서 X를 구축한다.
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) # batch size, channel, height, width
X
'''
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
'''풀링은 한 영역의 정보를 집계하기 때문에 딥러닝 프레임워크는 기본적으로 풀링 윈도우 크기와 스트라이드를 일치시킨다. 예를 들어, (3,3) 모양의 풀링창이라면 기본적으로 (3,3)의 스트라이드 모양을 얻게 된다.
pool2d = nn.MaxPool2d(3)
# Pooling has no model parameters, hence it needs no initialization
pool2d(X)
# tensor([[[[10.]]]])
pool2d = nn.MaxPool2d(3, padding=1, stride=2) # padding / stride override
pool2d(X)
# tensor([[[[ 5., 7.],
# [13., 15.]]]])
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1)) # arbitrary height and width
pool2d(X)
# tensor([[[[ 5., 7.],
# [13., 15.]]]])padding=(0,1)의 의미: 풀링 레이어에 패딩을 적용할 때 행(세로 방향)에는 패딩을 추가하지 않고, 열(가로 방향)에만 패딩을 1만큼 추가(?)
3) Multiple Channels
Multi-channel의 입력 데이터를 처리할 때 풀링 레이어는 컨볼루션 레이어에서 처럼 채널 별로 입력을 합산하지 않고, 각 입력 채널을 개별적으로 풀링한다. 즉, 플링 레이어의 출력 채널 수는 입력 채널 수 와 동일하다.
X = torch.cat((X, X + 1), 1)
X
'''
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
'''
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
'''
tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])
'''출력의 채널 수가 풀링 뒤에도 동일하게 유지되는 것을 볼 수 있다!
가장 유명한 방법 중 하나는 풀링 윈도우의 사이즈를 로 하여 출력의 공간 해상도를 1/4로 줄이는 것이다. 풀링 외에도 해상도를 낮추는 방법에는 Stochastic pooling, Fractional max-pooling (집계를 무작위 추출과 결합) 등이 있다. 경우에 따라 정확도가 향상될 수 있다. 마지막으로, attention mechanism에서 소개될 query와 representation vector간의 정렬을 사용하는 등 출력에 대해 집계하는 더 정교한 방법도 있다.
6. Convolutional Neural Networks (LeNet)
@Seoyoon.J
이전에 이미지 데이터셋 Fashion-MNIST를 소프트맥스 회귀와 MLP가 포함된 선형 모델에 적용했었다. 이미지 데이터를 처리 가능하게 만들기 위해 28x28 행렬을 고정된 길이 784 차원 벡터로 평탄화한 다음 FC layer에 통과시켰다. 이제는 Conv layer를 다룰 수 있게 됨으로써 이미지의 공간 구조를 유지할 수 있다. 또한, FC layer 대신 Conv layer를 사용함에 따라 훨씬 적은 매개변수를 갖는 모델을 사용하게 된다.
컴퓨터 비전 task에서 성능으로 큰 관심을 끌었던 최초의 CNN 중 하나인 LeNet을 알아보자. 이 모델은 이미지에서 손으로 쓴 숫자를 인식할 목적으로 LeCun에 의해 소개되었고(LeCun et al., 1998), LeCun 팀은 연구를 발전시켜 역전파를 통해 CNN을 성공적으로 훈련시켰다(LeCun et al., 1989).
당시 LeNet은 지도 학습의 주요 접근 방식이었던 SVM의 성능과 일치하는 뛰어난 결과를 달성하여 1% 미만의 오류율을 달성했다. LeNet은 ATM 기계에서 예금을 처리하기 위해 숫자를 인식하는데 사용되었고, 오늘날까지도 일부 ATM에서는 1990년대에 (Yann LeCun과 그의 동료들이) 작성한 코드를 여전히 실행하고 있다.
1) LeNet
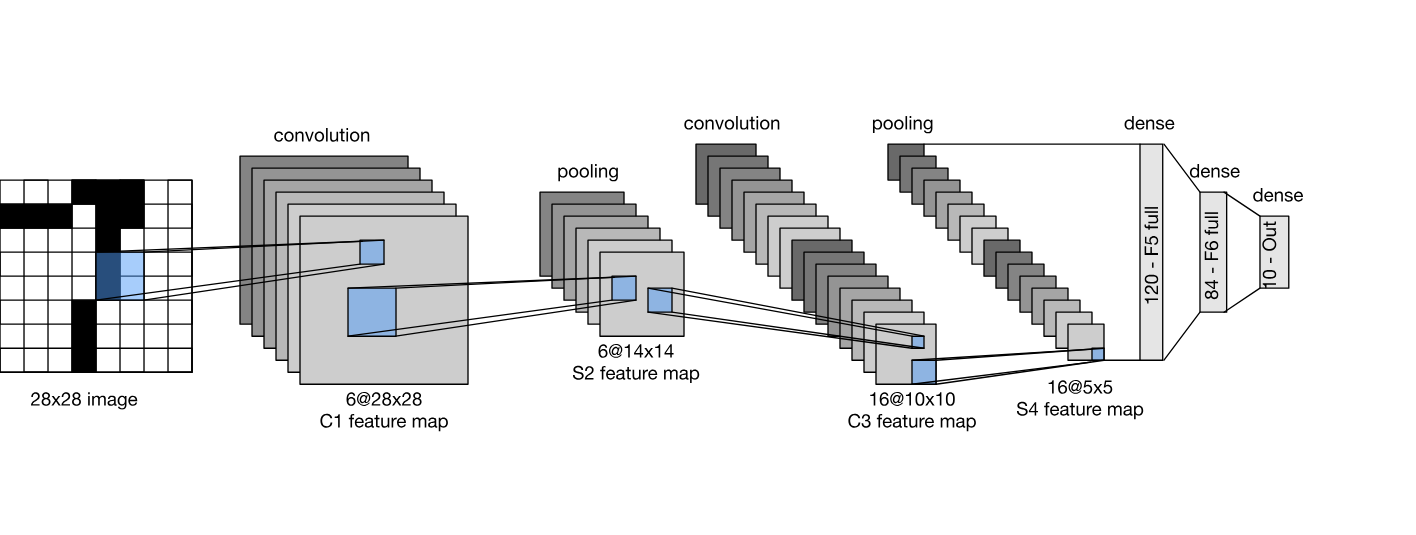
LeNet(LeNet-5)는 총 두 부분으로 구성된다.
1) 두 개의 Conv layer로 구성된 convolutional encoder
2) 3개의 FC layer로 구성된 dense 블록
각 컨벌루션 블록의 기본 단위는 컨벌루션 레이어 + 시그모이드 활성화 함수 + average 풀링 연산이다. (물론, ReLU와 최대 풀링이 더 잘 작동하지만 개발되기 전이였다.) 각 Conv layer는 5x5 커널과 시그모이드 활성화 함수를 사용한다. 이러한 레이어는 공간적으로 배열된 입력을 여러 개의 2차원 feature map에 매핑하여 (일반적으로) 채널 수를 늘린다. 첫 번째 Conv layer에는 6개의 출력 채널이 있고 두 번째 Conv layer에는 16개의 출력 채널이 있다. 각 2x2 풀링 (stride 2)은 공간 다운샘플링을 통해 차원을 4배로 줄입니다. 컨벌루션 블록은 (배치 크기, 채널 수, 높이, 너비)로 지정된 모양의 출력을 내보낸다.
컨벌루션 블록의 출력을 dense 블록으로 전달하려면 미니배치의 샘플을 평면화해야 한다. 즉, 4차원(배치 크기, 채널 수, 높이, 너비) 입력을 FC layer에 입력할 수 있도록 2차원 입력(배치 크기, 샘플의 평면 벡터{flatten})으로 변환해야 한다. LeNet의 dense 블록은 각각 120, 84, 10개의 출력을 갖는 3개의 FC layer를 갖는다. 여기서 마지막 10차원 출력 레이어는 클래스의 수(Fashion-MNIST 분류)를 의미한다.
LeNet 내부에서 무슨 일이 일어나는지에 대해 자세히 이해하는건 쉽지 않지만, 최신 딥러닝 프레임워크를 통해 LeNet 모델을 구현하는 것은 매우 간단하다. Xavier 초기화를 사용하여 Sequential 블록을 인스턴스화하고 적절한 레이어를 함께 연결하면 된다.
def init_cnn(module): #@save
"""Initialize weights for CNNs."""
if type(module) == nn.Linear or type(module) == nn.Conv2d:
nn.init.xavier_uniform_(module.weight)
class LeNet(d2l.Classifier): #@save
"""The LeNet-5 model."""
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.LazyLinear(120), nn.Sigmoid(), # 16 * 25의 입력과 120의 출력
nn.LazyLinear(84), nn.Sigmoid(), # 120의 입력과 84의 출력
nn.LazyLinear(num_classes)) # 84의 입력과 10의 출력위 코드에서는 가우시안 활성화 레이어 대신 구현이 훨씬 단순한 소프트맥스 레이어를 사용했다. (요즘엔 가우스 디코더가 거의 사용되지 않음)

네트워크 내부에서 무슨 일이 일어나는지 보면, 단일 채널(흑백) 28x28 이미지가 layer에 전달되고 각 레이어의 출력이 다음 레이어로 전달되면서 모델이 진행된다.
@d2l.add_to_class(d2l.Classifier) #@save
def layer_summary(self, X_shape):
X = torch.randn(*X_shape)
for layer in self.net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
model = LeNet()
model.layer_summary((1, 1, 28, 28))
**# > Conv2d output shape: torch.Size([1, 6, 28, 28])
# Sigmoid output shape: torch.Size([1, 6, 28, 28])
# AvgPool2d output shape: torch.Size([1, 6, 14, 14])
# Conv2d output shape: torch.Size([1, 16, 10, 10])
# Sigmoid output shape: torch.Size([1, 16, 10, 10])
# AvgPool2d output shape: torch.Size([1, 16, 5, 5])
# Flatten output shape: torch.Size([1, 400])
# Linear output shape: torch.Size([1, 120])
# Sigmoid output shape: torch.Size([1, 120])
# Linear output shape: torch.Size([1, 84])
# Sigmoid output shape: torch.Size([1, 84])
# Linear output shape: torch.Size([1, 10])**컨벌루션 블록의 각 레이어를 통과하면 표현의 높이와 너비가 감소한다. 첫 번째 Conv layer는 5x5 커널로 인해 발생되는 높이와 너비의 감소를 보완하기 위해 패딩의 두 픽셀을 사용한다.
반면, 두 번째 Conv layer에서는 패딩을 생략하므로 높이와 너비가 모두 4픽셀만큼 줄어다. 레이어를 통과할수록 채널 수는 입력의 1에 대해 첫 번째 Conv layer 이후에는 6개, 두 번째 Conv layer 이후에는 16개로 증가합니다. 그러나 각 풀링 레이어는 높이와 너비를 절반으로 줄인다. 마지막으로, 각 FC layer는 차원을 줄여 클래스 수와 차원이 일치하는 출력을 내보낸다.
2) Training
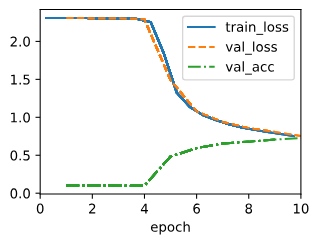
LeNet-5 모델이 Fashion-MNIST에서 어떻게 작동하는지 살펴보자.
CNN은 매개변수 수가 적지만 각 매개변수의 곱셈 연산이 많아지기 때문에 비슷한 깊이의 MLP보다 계산 비용이 더 많이 들 수 있다. GPU에 액세스할 수 있다면 훈련 속도를 높이기 위해 GPU를 실행하는 것이 좋다. 기본적으로 사용 가능한 장치(GPU or CPU …)에서 모델 매개변수를 초기화한다. MLP와 마찬가지로 loss 함수는 교차 엔트로피이며 미니배치 확률적 경사하강법을 통해 loss를 최소화한다. (d2l.Trainer 클래스가 모든 세부 사항을 처리)
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128)
model = LeNet(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], init_cnn)
trainer.fit(model, data)