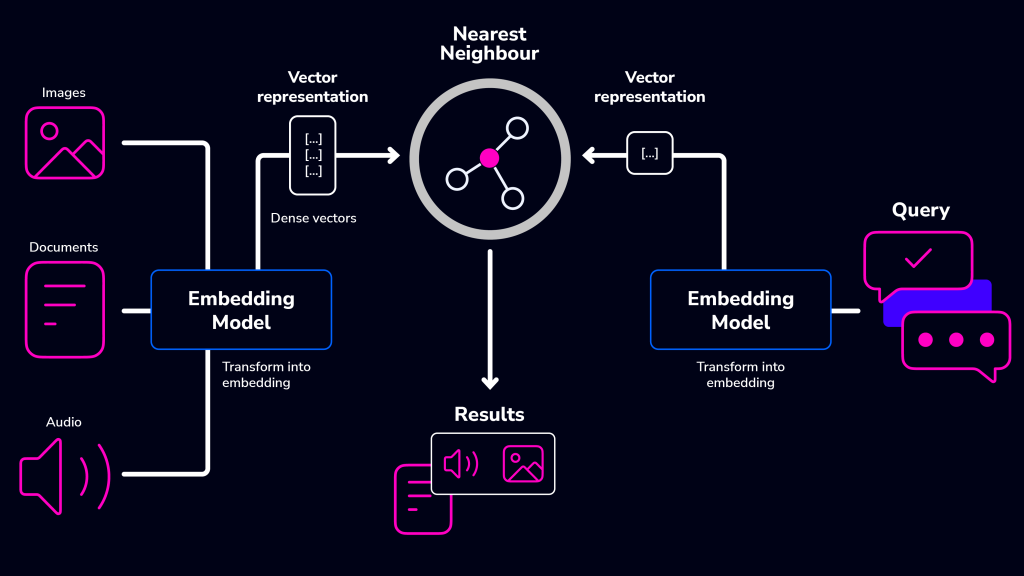
최근 사이드 프로젝트에서 키워드 기반으로 유사한 콘텐츠를 자동으로 추천하는 기능을 구현하고 싶었는데 단순 문자열 매칭이 아닌, 의미 기반의 유사도 검색이 하고싶었습니다. 이를 해결하기 위한 방법으로 pgvector와 Hugging Face의 임베딩 모델을 활용하게 되었습니다. 이 글은 그 과정을 정리하며, 어떤 기술을 선택했고 왜 그렇게 했는지를 개발자 관점에서 자세히 설명하고자 합니다.
1. pgvector란?
pgvector는 PostgreSQL에서 벡터 연산을 지원하기 위해 만들어진 확장(extension)입니다. 일반적으로 텍스트를 임베딩 벡터로 변환하고 이를 데이터베이스에 저장한 뒤, 유사한 벡터를 검색해 의미 기반의 결과를 도출하는 데 사용됩니다. pgvector는 RDB 환경에서 유사도 기반 검색을 가능하게 해주며, 별도의 벡터 검색 엔진을 사용하지 않고도 데이터 정합성과 통합성을 유지할 수 있다는 점에서 매우 유용합니다.
주요 거리 계산 방식
- L2 Distance (Euclidean): 절댓값 거리 측정
- Inner Product: 내적 기반 유사도
- Cosine Similarity: 방향 유사도, 일반적으로 가장 많이 사용됨
2. 벡터 유사도 검색이 필요한 이유
문자열 비교로는 문맥이나 의미까지 비교하기 어렵습니다. 예를 들어 “강아지가 귀엽다”와 “반려동물이 사랑스럽다”는 텍스트는 문자는 다르지만 의미는 유사하죠. 이런 경우를 위해 텍스트를 벡터로 바꾸고, 벡터 간의 유사도를 계산하는 방식이 필요합니다.
이런 검색은 다음과 같은 서비스에 적용됩니다:
- 검색 엔진 (예: 뉴스, 문서 검색)
- 추천 시스템 (예: 비슷한 게시글 추천)
- 챗봇의 질문-응답 매칭
3. 어떤 임베딩 모델을 선택해야 하는가?
임베딩 모델은 입력 텍스트를 고차원의 벡터로 변환합니다. Hugging Face에는 다양한 모델이 존재하며, 각각의 특성과 적합한 상황이 다릅니다. 이번 프로젝트에서 다양한 모델을 테스트하며 성능 차이를 직접 확인할 수 있었습니다.
| 모델명 | 차원 수 | 특징 | 적합한 상황 |
|---|---|---|---|
all-MiniLM-L6-v2 | 384 | 빠르고 경량 | 일반적인 문장 유사도 비교 |
paraphrase-MiniLM-L12-v2 | 768 | 더 높은 표현력 | 복잡한 문장 간 의미 파악 |
BAAI/bge-small-en-v1.5 | 384 | 한글 일부 지원, 키워드 기반 검색에 강함 | 검색, 분류, 추천 시스템 등 |
사용 경험 공유
all-MiniLM-L6-v2 모델은 문장 유사도 비교에서는 꽤 정확한 결과를 보여주었습니다. 하지만 짧은 키워드 검색에서는 유사도 점수가 0.9 이상임에도 불구하고 실제로는 전혀 관련 없는 결과가 나오는 문제가 있었습니다.
그래서 대안으로 bge-small 모델을 적용해보았습니다. 이 모델은 비교적 짧은 키워드에 대한 유사도도 안정적으로 판단하고, 일부 한글도 지원하여 국문 기반 프로젝트에도 잘 어울리는 선택이었습니다.
4. Hugging Face란?
Hugging Face는 다양한 자연어 처리(NLP) 및 LLM 모델을 오픈소스로 제공하는 플랫폼입니다. 텍스트 분류, 감정 분석, 요약, 번역, 임베딩 등 다양한 태스크에 사용할 수 있으며, 특히 sentence-transformers 시리즈는 문장 단위의 의미 기반 임베딩에 특화되어 있습니다.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("BAAI/bge-small-en-v1.5")
texts = ["Redis 분산락 구현 방법"]
embeddings = model.encode(texts)위와 같이 간단하게 텍스트를 벡터로 변환할 수 있으며, 이 벡터를 PostgreSQL에 저장하여 유사도 기반 검색에 사용할 수 있습니다.
5. pgvector에서 지원하는 거리 연산자
pgvector는 다음과 같은 연산자를 제공하여 다양한 방식의 벡터 비교를 지원합니다.
| 연산자 | 계산 방식 | 용도 |
|---|---|---|
<-> | Euclidean 거리 | 절댓값 거리 기반 정렬 |
<#> | Cosine 거리 | 방향 기반 유사도 계산 (일반적) |
<=> | Inner Product | 내적 기반 비교 (주의: 역정렬 가능성 있음) |
실제 실무에서는 대부분 <#> (Cosine 유사도)를 정규화한 벡터와 함께 사용하는 경우가 많습니다.
-- 벡터 정규화 후 저장
UPDATE documents SET embedding = embedding / ||embedding||;
-- 유사도 검색 쿼리 예시
SELECT id, content
FROM documents
ORDER BY embedding <#> '[0.12, 0.22, ..., 0.98]'::vector
LIMIT 5;6. pgvector 설치 및 설정 방법
1. 설치 (macOS 기준)
brew install postgresql
brew services start postgresql2. Docker 사용
docker run -d \
--name pgvector \
-e POSTGRES_PASSWORD=pass \
-p 5432:5432 \
ankane/pgvector3. PostgreSQL 확장 등록
CREATE EXTENSION vector;4. 테이블 생성 예시
CREATE TABLE documents (
id serial PRIMARY KEY,
content text,
embedding vector(384)
);결론 및 정리
이번 사이드 프로젝트를 통해 pgvector + Hugging Face 조합의 강력함을 체감할 수 있었습니다. 단순한 키워드 검색만으로는 부족했던 부분이 벡터 유사도 기반 검색으로 훨씬 풍부하고 직관적인 검색 결과를 제공할 수 있었기 때문입니다.
무엇보다 PostgreSQL 환경에서 별도의 검색 시스템 없이 구현할 수 있다는 점이 가장 큰 장점이었고, LLM 임베딩 모델의 다양성과 성능도 선택에 있어 중요한 기준이 되었습니다.
추천 조합
- 문장 비교 중심 →
all-MiniLM-L6-v2 - 키워드 검색 중심 →
bge-small시리즈
텍스트 유사도 검색이 필요한 서비스라면, pgvector를 기반으로 한 구조를 적극적으로 고려해볼 것을 추천드립니다!