최근 프로젝트에서 대용량 로그 데이터를 분석하는 시스템을 구성하게 되었습니다. 이 과정에서 가장 먼저 고민하게 된 건 바로 데이터베이스 선택이었습니다. 기존에는 PostgreSQL을 기반으로 트랜잭션 처리 위주의 시스템을 구성해왔지만, 이번에는 로그 기반 통계와 대시보드, 보고서 생성을 위한 분석 중심의 아키텍처가 필요했기 때문에 기존 방식으로는 한계를 느낄 수밖에 없었습니다.
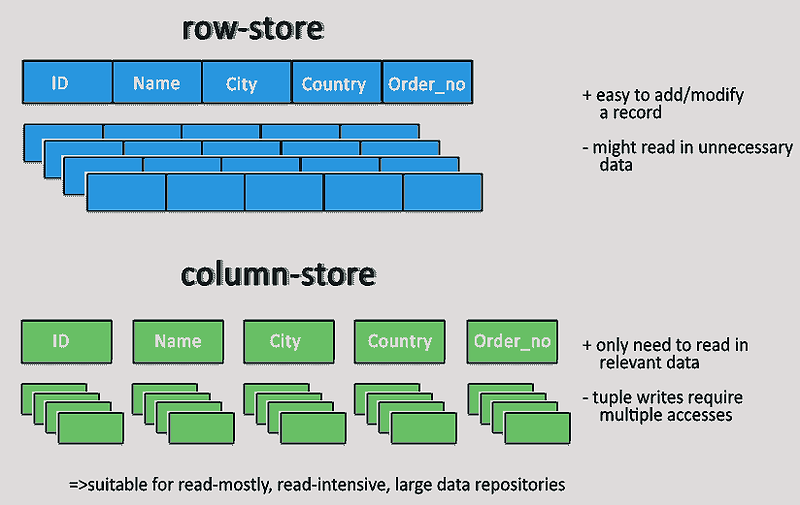
그 과정에서 정리한 것이 바로 행 기반(Row-oriented) vs 열 기반(Column-oriented) DB의 구조와 활용 차이점입니다. 실무에서 이 차이를 모르고 시스템을 구성한다면, 성능 병목은 물론이고 불필요한 리팩토링이 발생할 수 있으므로 반드시 알아두셔야 합니다.
1. 행 기반 데이터베이스(Row-oriented DB)
행 기반 데이터베이스는 데이터를 하나의 레코드(행) 단위로 디스크에 저장합니다. 가장 많이 쓰이는 RDB 구조이며, 일반적인 웹 애플리케이션, 사용자 정보 저장, 트랜잭션 처리 등에 적합합니다.
특징
- 단일 사용자의 전체 정보를 빠르게 읽고 쓸 수 있음
- INSERT, UPDATE, DELETE가 빠름
- OLTP(Online Transaction Processing)에 적합
대표적인 DBMS
- PostgreSQL
- MySQL
- Oracle
예시: 사용자 주문 시스템
| user_id | product_id | order_date |
|---------|------------|-------------|
| 123 | A001 | 2024-04-01 |
| 456 | A003 | 2024-04-02 |
| 789 | A002 | 2024-04-02 |데이터는 다음과 같이 저장됩니다:
[123, A001, 2024-04-01]
[456, A003, 2024-04-02]
[789, A002, 2024-04-02]→ 사용자 단위 처리가 빠름
2. 열 기반 데이터베이스(Column-oriented DB)
열 기반 데이터베이스는 데이터를 컬럼별로 묶어서 저장합니다. 즉, 같은 컬럼의 값들끼리 인접하게 저장되므로, 특정 컬럼만을 반복적으로 조회하는 작업에서 매우 뛰어난 성능을 보입니다.
특징
- 통계, 합계, 평균 등의 집계 쿼리가 빠름
- 데이터 압축률이 높음 (같은 타입, 패턴이 반복되기 때문)
- OLAP(Online Analytical Processing)에 최적화
대표적인 DBMS
- Amazon Redshift
- Google BigQuery
- Apache Druid
- ClickHouse
예시: 실시간 매출 집계
| store_id | amount | sale_date |
|----------|--------|------------|
| S001 | 10000 | 2024-04-01 |
| S002 | 15000 | 2024-04-01 |
| S001 | 20000 | 2024-04-02 |데이터는 다음과 같이 저장됩니다:
[store_id]: [S001, S002, S001]
[amount]: [10000, 15000, 20000]
[sale_date]: [2024-04-01, 2024-04-01, 2024-04-02]→ 특정 컬럼만 선택해서 빠르게 집계 가능
3. 실무 기준 비교표
| 항목 | 행 기반 DB (PostgreSQL 등) | 열 기반 DB (BigQuery 등) |
|---|---|---|
| 저장 구조 | Row 단위 저장 | Column 단위 저장 |
| 쓰기 성능 | 빠름 | 상대적으로 느림 |
| 읽기 성능 | 전체 행 읽기에 유리 | 특정 컬럼 추출에 유리 |
| 트랜잭션 처리 | 강함 | 상대적으로 제한됨 |
| 분석/통계 쿼리 | 느릴 수 있음 | 매우 빠름 |
| 압축 효율 | 낮음 | 높음 |
| 활용 예 | 사용자, 주문, 결제 처리 | 로그, 통계, BI, 리포트 |
4. 실무에서 왜 중요한가?
이번 실무 프로젝트에서는 Google BigQuery를 통해 약 5억 건 이상의 로그 데이터를 3개월치 보관하고, 특정 필터(예: action_type = 'LOGIN') 기준으로 시간대별 사용자 수를 집계하는 기능을 구현했습니다.
처음에는 PostgreSQL에 로그를 적재하고 쿼리했지만, 쿼리 시간이 수 초 이상 걸리고 CPU 점유율도 급등했습니다. 이후 열 기반 구조를 적용하면서 100ms 단위로 집계 결과가 나오는 걸 경험하고, "데이터 구조에 맞는 DB를 써야 한다"는 걸 절실히 느꼈습니다.
이 경험을 통해:
- 단순히 익숙한 DB를 고르는 것이 아닌, 데이터의 사용 목적을 중심으로 DB를 선택해야 한다는 점
- OLTP vs OLAP 구분을 명확히 알고 설계에 반영해야 한다는 점을 실감하게 되었습니다.
5. 마무리
개발자가 DB를 선택할 때 고려해야 할 것은 단지 성능뿐만이 아닙니다. 데이터의 생성, 저장, 사용 방식까지 총체적으로 고려해야 하며, 이 관점에서 행 기반과 열 기반 DB의 선택은 실무의 품질과 효율성을 결정짓는 핵심 요소가 됩니다.
앞으로 로그 기반의 대시보드, 사용자 행동 분석, 운영 지표 집계 등을 설계하신다면 꼭 열 기반 DB도 함께 고려해보시길 추천드립니다.