Threads & Concurrency
◼ Overview
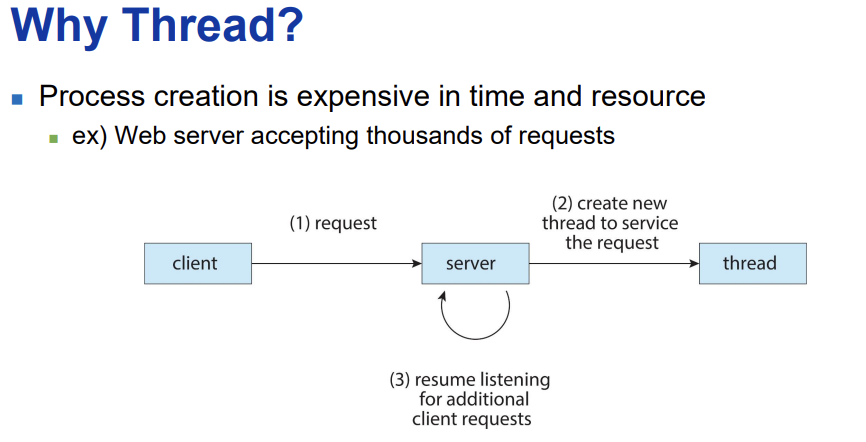
Motivation
멀티스레딩의 동기
- 현대의 많은 응용 프로그램들은 멀티스레드로 구현되어 있습니다. 멀티스레딩은 하나의 응용 프로그램 내에서 여러 개의 스레드가 동시에 실행되도록 하는 기술입니다. 각 스레드는 응용 프로그램 내에서 별도의 작업을 수행할 수 있습니다. 예를 들어, 하나의 스레드는 디스플레이를 업데이트하고, 다른 스레드는 데이터를 가져오며, 또 다른 스레드는 맞춤법 검사를 하거나 네트워크 요청에 답변할 수 있습니다. 이러한 분리는 다음의 이점을 제공합니다.
-
경량 프로세스: 프로세스 생성은 많은 시스템 자원을 소모하는 반면, 스레드 생성은 상대적으로 경량입니다. 스레드는 프로세스 내에서 실행되며, 프로세스가 가진 자원과 메모리 공간을 공유합니다.
-
효율성 증가: 멀티스레딩을 통해 응용 프로그램은 작업을 병렬로 처리할 수 있으므로, 전체적인 실행 속도와 반응성이 향상됩니다.
-
코드 단순화: 특정 작업을 별도의 스레드로 분리함으로써, 코드의 구조를 단순화시킬 수 있습니다. 각 스레드가 하나의 작업에만 집중하므로, 코드의 가독성과 유지보수성이 향상됩니다.
-
커널의 멀티스레딩: 운영 체제의 커널 또한 일반적으로 멀티스레드로 구성되어 있어, 시스템 호출이나 하드웨어 인터럽트 처리 등을 효율적으로 관리할 수 있습니다.
-> 결론적으로, 멀티스레딩은 현대 응용 프로그램의 효율성과 반응성을 높이는 중요한 기술입니다. 다양한 작업을 동시에 처리할 수 있는 능력은 사용자 경험을 크게 향상시키며, 개발자에게는 코드의 구조를 단순화하고 유지보수를 용이하게 하는 이점을 제공합니다.
Overview
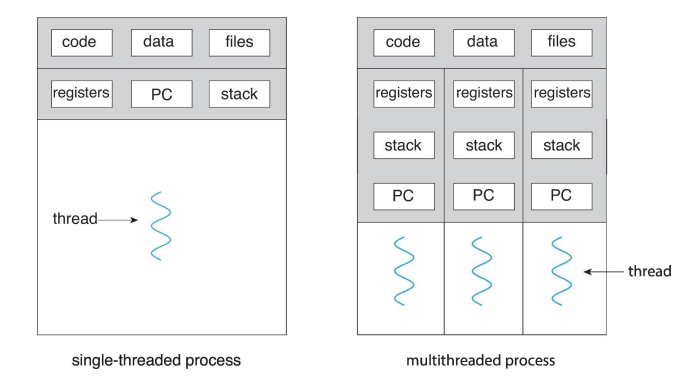
프로세스(Process)
-
정의: 실행 중인 프로그램입니다. 즉, 디스크에서 메모리로 로드되어 실행 상태에 있는 프로그램을 말합니다.
-
자원 할당: 프로세스는 실행에 필요한 다양한 자원(메모리, 파일 핸들, I/O 장치 등)을 할당받습니다. 각 프로세스는 독립적인 메모리 공간(코드, 데이터, 스택 등)을 가지며, 다른 프로세스와 공유하지 않습니다.
-
특징: 프로세스는 시스템 자원을 많이 소모하며, 프로세스 간의 통신(IPC)을 위해서는 특별한 메커니즘이 필요합니다.
스레드(Thread)
-
정의: 프로그램이 자신을 두 개 이상의 동시에 실행되는 작업으로 분할하는 방법입니다. 스레드는 프로세스 내에서 실행되며, 기본적인 CPU 사용 단위입니다.
-
자원 공유: 하나의 프로세스 내에서 생성된 스레드들은 프로세스의 자원(메모리, 파일 핸들 등)을 공유합니다. 이로 인해 스레드 간의 데이터 공유와 통신이 용이해집니다.
-
구성 요소: 스레드는 스레드 ID, 프로그램 카운터, 레지스터 세트, 스택 등으로 구성됩니다. 이러한 구성 요소를 통해 스레드는 독립적인 실행 흐름을 가집니다.
-
특징: 스레드는 프로세스에 비해 생성과 컨텍스트 스위칭이 가벼워 효율적인 병렬 처리가 가능합니다. 하지만, 자원을 공유하기 때문에 동기화 문제가 발생할 수 있습니다.
프로세스와 스레드의 이러한 특성 때문에, 멀티스레딩을 사용하는 현대 응용 프로그램은 효율적인 자원 사용과 빠른 실행 속도를 달성할 수 있습니다. 스레드는 멀티코어 프로세서의 이점을 최대한 활용하여, 동시에 여러 작업을 수행할 수 있게 해줍니다.
스레드 제어 블록(Thread Control Block, TCB)
- 운영 체제 커널 내에 존재하는 데이터 구조로, 스레드를 관리하기 위해 필요한 스레드 특정 정보를 포함하고 있습니다. TCB는 각 스레드에 대한 중요한 정보를 저장하여, 스레드의 생성, 스케줄링, 동기화 및 종료 등을 효율적으로 관리할 수 있도록 합니다.
-> TCB에 포함된 정보의 예시
- 스레드 ID: 각 스레드를 구별하는 고유한 식별자입니다.
- 스레드 상태: 스레드의 현재 상태(실행 중, 준비, 대기, 시작, 완료 등)를 나타냅니다. 이 정보를 통해 운영 체제는 스레드 스케줄링을 결정합니다.
- 스택 포인터: 스레드의 스택 메모리 위치를 가리키는 포인터입니다. 스레드의 함수 호출과 지역 변수 저장에 사용됩니다.
- 프로그램 카운터: 스레드가 다음에 실행할 명령어의 주소를 가리킵니다. 이를 통해 스레드의 실행 흐름을 관리합니다.
- 스레드의 레지스터 값: 스레드의 현재 상태를 나타내는 CPU 레지스터 값들입니다. 컨텍스트 스위칭 시 이 값들이 저장되고 복원됩니다.
- 프로세스 제어 블록(PCB)에 대한 포인터: 스레드가 속한 프로세스의 PCB를 가리키는 포인터입니다. PCB는 프로세스에 대한 중요한 정보를 저장하는 데이터 구조로, 스레드와 프로세스 간의 연관성을 나타냅니다.
TCB는 운영 체제가 스레드를 효율적으로 관리하기 위해 필수적인 정보를 제공합니다. 멀티스레딩 환경에서 각 스레드의 실행 상태, 메모리 위치, 프로세스와의 관계 등을 관리함으로써, 자원의 효율적 사용과 높은 시스템 성능을 달성할 수 있습니다.
Thread의 장점
-
반응성(Responsiveness)
프로세스의 일부가 차단(blocked)되어도, 다른 스레드들이 계속 실행될 수 있기 때문에, 전체 응용 프로그램의 반응성이 향상됩니다. 특히 사용자 인터페이스를 가진 응용 프로그램에서 중요한 이점입니다. 예를 들어, 사용자 입력을 처리하는 스레드가 동작하는 동안, 다른 스레드에서 데이터를 로드하는 작업을 수행할 수 있습니다. -
자원 공유(Resource Sharing)
프로세스 내의 스레드들은 동일한 메모리 공간과 자원을 공유할 수 있습니다. 이는 공유 메모리나 메시지 전달 방식에 비해 훨씬 간단하고 효율적입니다. 스레드 간의 데이터 공유가 용이하기 때문에, 응용 프로그램의 구조를 단순화하고 개발 시간을 단축할 수 있습니다. -
경제성(Economy)
스레드 생성은 프로세스 생성에 비해 비용이 적게 듭니다. 또한, 스레드 간의 전환(switching)은 프로세스 간의 컨텍스트 스위칭(context switching)에 비해 오버헤드가 낮습니다. 이는 시스템 자원을 더 효율적으로 사용할 수 있게 하며, 전체적인 시스템 성능을 향상시킵니다. -
확장성(Scalability)
멀티프로세서(multiprocessor) 아키텍처에서 스레드를 사용하면 프로세스가 여러 CPU 코어를 효율적으로 활용할 수 있습니다. 각 스레드가 다른 프로세서에서 동시에 실행될 수 있기 때문에, 응용 프로그램의 처리 능력이 크게 향상될 수 있습니다. 이는 특히 병렬 처리가 중요한 계산 집약적인 작업에서 큰 이점을 제공합니다.
◼ Multicore Programming
멀티코어 프로그래밍의 한계 및 해결점.
-
활동 분할(Dividing Activities): 전체 작업을 동시에 수행할 수 있는 더 작은 단위로 나누는 것이 필요합니다. 이 과정에서 효율적으로 작업을 분할하여 각 코어가 수행할 작업을 결정하는 것이 중요합니다.
-
균형(Balance): 모든 코어가 비슷한 작업량을 가지고 있도록 작업을 균등하게 분배하는 것이 중요합니다. 일부 코어는 과부하 상태인 반면 다른 코어는 유휴 상태에 있어서는 안 됩니다.
-
데이터 분할(Data Splitting): 전체 데이터 세트를 여러 스레드 또는 프로세스가 처리할 수 있는 작은 단위로 나누는 것입니다. 데이터를 효과적으로 분할하면 병렬 처리의 효율이 크게 향상될 수 있습니다.
-
데이터 의존성(Data Dependency): 병렬 처리 시 데이터 의존성 문제는 성능 저하의 주요 원인이 될 수 있습니다. 한 작업의 결과가 다른 작업의 입력으로 사용되는 경우, 이러한 의존성을 관리해야 합니다.
-
테스팅 및 디버깅(Testing and Debugging): 병렬 프로그램은 디버깅과 테스팅이 더 어렵습니다. 경쟁 상태(race conditions), 교착 상태(deadlocks) 등 병렬 환경에서만 발생하는 문제들을 해결해야 합니다.
병렬성(Parallelism)과 동시성(Concurrency)
병렬성(Parallelism)은 시스템이 실제로 여러 작업을 동시에 수행할 수 있음을 의미합니다. 멀티코어 또는 멀티프로세서 시스템에서는 여러 코어가 동시에 다른 작업을 수행할 수 있습니다.
동시성(Concurrency)은 시스템이 여러 작업을 진행할 수 있음을 의미하지만, 반드시 동시에 수행되는 것은 아닙니다. 단일 프로세서/코어 시스템에서는 스케줄러가 태스크 간에 빠르게 전환함으로써 동시성을 제공합니다.
멀티코어 프로그래밍은 소프트웨어의 성능을 극대화할 수 있는 큰 잠재력을 가지고 있지만, 이를 위해서는 위에서 언급된 도전 과제들을 해결하는 것이 필수적입니다. 효과적인 병렬성과 동시성 관리를 통해, 애플리케이션의 처리 능력과 반응성을 크게 향상시킬 수 있습니다.
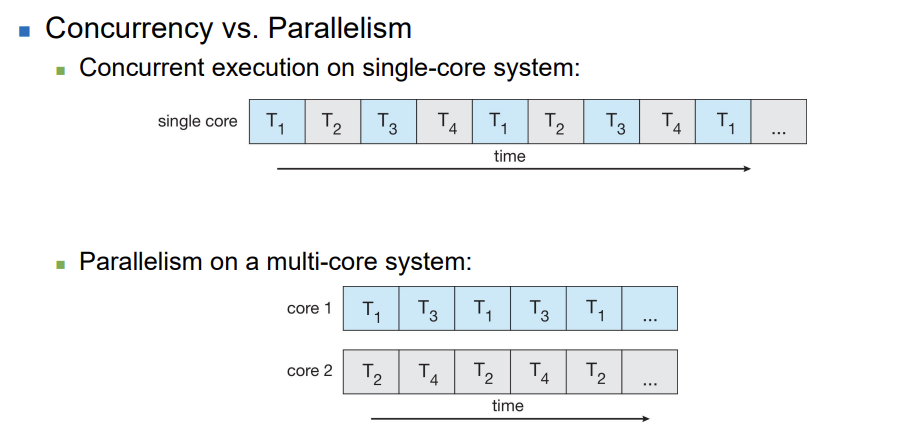
-> 동시성 : 한번에 여러 일을 벌려서 차례차례 처리하는 것
-> 병렬성 : 한 번에 여러 일을 하는 것
Types of Parallelism
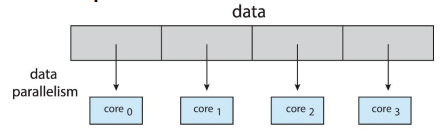
Data parallelism
- 같은 종류의 작업을 많은 데이터에 동시에 적용하는 것을 말해요.
-> 예시) 같은 사진 효과를 여러 사진에 동시에 적용하거나, 같은 계산을 많은 숫자에 대해 동시에 수행하는 것. 이 방식의 장점은 많은 데이터를 빠르게 처리할 수 있다는 것입니다. 데이터 병렬성은 주로 대량의 데이터를 같은 방식으로 처리할 때 유용해요. 예를 들면, 과학 연구에서 많은 양의 데이터를 분석하거나, 대규모 이미지를 처리할 때 많이 사용됩니다.
Task parallelism
- 서로 다른 종류의 작업을 동시에 처리하는 방식입니다.
-> 예시) 한 컴퓨터에서 음악을 재생하면서 문서를 편집하고, 인터넷을 검색하는 것과 같이, 각각 다른 일을 동시에 처리하는 거죠. 이 방식의 장점은 다양한 작업을 동시에 처리하여 시간을 절약할 수 있다는 것입니다. 작업 병렬성은 주로 여러 다른 작업이 동시에 필요할 때 유용해요. 예를 들면, 웹 서버가 다양한 요청을 동시에 처리하거나, 복잡한 프로그램이 여러 하위 작업을 동시에 실행할 때 많이 사용됩니다.
Amdahl’s Law
암달의 법칙(Amdahl’s Law)은 어플리케이션의 성능 향상을 예측하기 위한 이론으로, 어플리케이션이 순차적(serial) 부분과 병렬(parallel) 부분을 모두 포함하고 있을 때, 추가적인 코어를 통해 얻을 수 있는 성능 향상을 식별합니다. 여기서 'S'는 어플리케이션의 순차적으로 실행되어야 하는 부분의 비율을 나타내고, 'N'은 처리 코어의 수를 의미합니다.
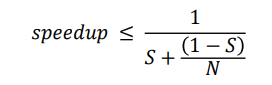
예를 들어, 어플리케이션이 75%가 병렬 처리가 가능하고(25%는 순차적), 코어를 하나에서 두 개로 늘렸을 때, 1.6배의 성능 향상이 발생한다고 합니다. 그리고 코어의 수 'N'이 무한대로 접근할 때, 성능 향상은 순차적 부분의 역수인 1 / S에 접근하게 됩니다.
그러나 순차적 부분은 추가 코어를 통한 성능 향상에 비례해서 큰 영향을 미칩니다. 즉, 순차적 부분이 많을수록 병렬 처리를 통한 이득이 줄어들게 됩니다.
하지만 여기서 중요한 질문은, 암달의 법칙이 현대의 멀티코어 시스템을 고려했는가 하는 것입니다. 실제로 암달의 법칙은 멀티코어 프로세서의 여러 복잡한 요소들을 완전히 고려하지는 않습니다. 예를 들어, 코어 간의 메모리 접근 시간의 차이(NUMA), 캐시 일관성 유지로 인한 오버헤드, 자원 경쟁, 병렬화에 따른 추가적인 오버헤드, 에너지 소비 및 열 분산 문제, 그리고 소프트웨어가 추가 코어를 효율적으로 활용하지 못하는 경우 등이 이에 해당합니다.
따라서 암달의 법칙은 병렬 컴퓨팅의 이점을 이해하는 데 유용한 출발점을 제공하지만, 현대 멀티코어 시스템의 모든 복잡성을 다루지는 않는 단순화된 모델입니다.
◼ Multithreading Models
- 사용자 스레드(User Threads)와 커널 스레드(Kernel Threads)는 멀티스레딩을 구현하는 두 가지 주요 방식입니다. 각각의 특성과 차이점을 이해하는 것은 운영 체제의 스레드 관리와 멀티태스킹의 원리를 파악하는 데 중요합니다.
사용자 스레드(User Threads)
-
정의: 사용자 레벨의 라이브러리에 의해 지원되는 스레드입니다. 이러한 스레드는 운영 체제의 커널이 직접 관리하지 않습니다.
-
생성 및 관리: 사용자 스레드는 라이브러리 함수 호출을 통해 생성되며, 이러한 함수 호출은 시스템 호출이 아닙니다. POSIX 스레드(Pthreads) 라이브러리나 Java 스레딩 라이브러리 같은 사용자 레벨의 스레드 라이브러리가 관리합니다.
-
스케줄링: 사용자 스레드의 스케줄링은 운영 체제의 커널이 아닌, 사용자 레벨의 스레드 라이브러리에 의해 이루어집니다.
-
장점: 사용자 스레드 간의 컨텍스트 스위칭은 커널 스레드에 비해 빠릅니다. 운영 체제의 개입 없이 스레드 관리가 이루어지기 때문입니다.
-
단점: 한 사용자 스레드가 블록되면(예: I/O 작업 대기), 해당 스레드가 속한 전체 프로세스가 블록될 수 있습니다. 커널은 사용자 스레드의 존재를 알지 못하므로, 개별 스레드에 대한 세밀한 스케줄링이 불가능합니다.
커널 스레드(Kernel Threads)
-
정의: 커널에 의해 직접 지원 및 관리되는 스레드입니다. 커널 스레드는 운영 체제의 핵심 부분에 의해 생성, 스케줄링 및 관리됩니다.
-
생성 및 관리: 커널 스레드는 시스템 호출을 통해 생성되며, 커널이 직접 관리합니다.
-
스케줄링: 커널 스레드는 운영 체제의 커널에 의해 스케줄링됩니다. 이를 통해 멀티프로세서 시스템에서의 병렬 실행이 가능합니다.
-
장점: 한 스레드의 블록이 다른 스레드에 영향을 주지 않습니다. 커널이 모든 스레드를 개별적으로 관리할 수 있기 때문에, I/O 작업을 기다리는 스레드가 있어도 다른 스레드는 계속 실행될 수 있습니다.
-
단점: 사용자 스레드에 비해 컨텍스트 스위칭이 더 느립니다. 스레드 간의 전환에 커널의 개입이 필요하기 때문에, 사용자 스레드보다 오버헤드가 더 큽니다.
결론
사용자 스레드와 커널 스레드는 각각의 장단점을 가지고 있으며, 그 사용은 애플리케이션의 요구 사항과 실행 환경에 따라 달라질 수 있습니다. 사용자 스레드는 컨텍스트 스위칭이 빠르고, 스레드 관리가 사용자 수준에서 이루어지기 때문에 라이브러리를 통한 세밀한 제어가 가능합니다. 하지만, 한 스레드의 블록이 전체 프로세스의 실행을 중단시킬 수 있는 단점이 있습니다. 반면, 커널 스레드는 운영 체제의 커널에 의해 직접 관리되므로, 스레드 간의 독립적인 실행이 가능하고 멀티프로세서 환경에서의 병렬 처리에 유리합니다. 그러나, 사용자 스레드에 비해 컨텍스트 스위칭이 느리고 오버헤드가 큰 단점이 있습니다. 따라서, 실시간성이 중요하고 스레드 간의 빠른 전환을 요구하는 애플리케이션에서는 사용자 스레드가 더 적합할 수 있으며, 병렬 처리와 자원 관리의 효율성이 중요한 서버 사이드 애플리케이션 또는 멀티코어 환경에서는 커널 스레드의 사용이 더 바람직할 수 있습니다. 결국, 개발하고자 하는 소프트웨어의 구체적인 요구 사항과 목표에 따라 적절한 스레드 모델을 선택하는 것이 중요합니다.
Multiple Thread Model
다중 스레딩 모델은 사용자 스레드와 커널 스레드 간의 대응 관계를 어떻게 설정하느냐에 따라 구분됩니다. 이러한 모델은 멀티스레드 애플리케이션의 성능과 운영 체제의 스레드 관리 방식에 직접적인 영향을 미칩니다. 각 모델의 특징과 장단점을 이해하는 것은 효과적인 멀티스레딩 전략을 선택하는 데 중요합니다.다대일 모델(Many-to-One)
특징: 여러 사용자 스레드가 하나의 커널 스레드에 매핑됩니다. 장점: 사용자 스레드 간의 컨텍스트 스위칭이 빠릅니다. 단점: 한 사용자 스레드가 시스템 호출을 하여 블록되면, 해당 커널 스레드에 매핑된 모든 사용자 스레드가 실행을 멈춥니다. 멀티코어 시스템에서는 이 모델이 효율적으로 활용되지 못합니다.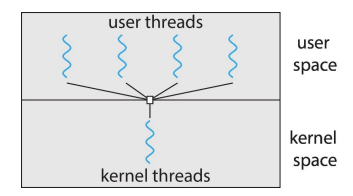
2. 일대일 모델(One-to-One)
특징: 한 사용자 스레드가 하나의 커널 스레드에 매핑됩니다. 장점: 사용자 스레드가 블록되어도 다른 스레드에 영향을 주지 않으며, 멀티코어 시스템에서의 병렬 처리가 가능합니다. 단점: 커널 스레드의 수가 많아질수록 시스템 자원의 소모가 커지고, 스레드 생성에 따른 오버헤드가 증가합니다.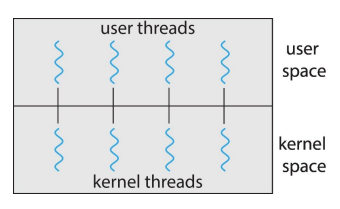
3. 다대다 모델(Many-to-Many)
특징: 여러 사용자 스레드가 여러 커널 스레드에 매핑됩니다. 사용자 스레드와 커널 스레드의 수가 동적으로 조정될 수 있습니다. 장점: 다대일 모델의 단점과 일대일 모델의 단점을 어느 정도 해결합니다. 멀티코어 환경에서 효율적으로 작동하며, 시스템 자원의 소모를 최소화할 수 있습니다. 단점: 구현의 복잡성이 증가하며, 스레드 간의 조정과 스케줄링이 더 어려워질 수 있습니다.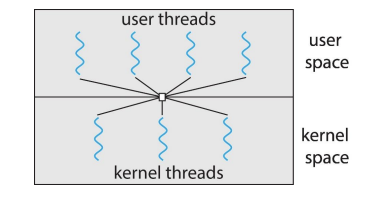
4. 두 단계 모델(Two-level)
특징: 다대다 모델의 변형으로, 일부 사용자 스레드가 직접 특정 커널 스레드에 매핑될 수 있는 유연성을 제공합니다. 장점: 다대다 모델의 장점을 유지하면서 특정 작업에 대해 더 높은 성능을 제공할 수 있는 맞춤화가 가능합니다. 단점: 다대다 모델과 마찬가지로 구현의 복잡성이 증가합니다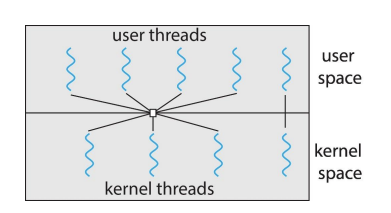
◼ Thread Libraries
스레드 라이브러리는 프로그래머가 스레드를 생성하고 관리할 수 있도록 하는 API를 제공합니다. 스레드 라이브러리를 구현하는 두 가지 주요 방법은 다음과 같습니다:
사용자 수준 라이브러리 (User Level Library) -> user thread와 관련
사용자 수준 라이브러리는 커널의 지원 없이 완전히 사용자 공간에서 작동합니다. 이 방법은 운영 체제의 변경 없이 스레드를 구현할 수 있기 때문에 유연성이 뛰어납니다. 사용자 수준 스레드의 주요 특징은 다음과 같습니다:스케줄링과 관리가 사용자 공간에서 이루어집니다: 커널이 스레드의 존재를 알지 못하며, 모든 스레드 관리 작업(생성, 스케줄링, 동기화)은 사용자 라이브러리에 의해 수행됩니다.
컨텍스트 전환 비용이 낮습니다: 커널 모드로의 전환 없이 사용자 모드에서 직접 스레드 간 전환이 가능하기 때문에, 컨텍스트 전환 비용이 상대적으로 낮습니다.
단일 프로세스 안에서만 작동: 모든 스레드는 동일한 주소 공간을 공유하므로, 하나의 스레드가 시스템 호출을 통해 차단되면 전체 프로세스가 차단될 수 있습니다.
커널 수준 라이브러리 (Kernel-Level Library) -> kernel thread와 관련
커널 수준 라이브러리는 운영 체제에 의해 지원됩니다. 이 방법은 스레드를 직접적으로 커널이 관리하므로, 스레드 간의 전환 및 스케줄링이 운영 체제에 의해 처리됩니다. 커널 수준 스레드의 주요 특징은 다음과 같습니다:커널이 스레드의 생성과 관리를 담당: 스레드는 운영 체제에 의해 직접적으로 지원되므로, 스레드 관리에 대한 부담이 커널에 있습니다.
효율적인 멀티프로세서 활용: 커널 수준 스레드는 멀티프로세서 시스템에서 효과적으로 작동할 수 있으며, 다중 CPU에서 동시에 다른 스레드를 실행할 수 있습니다.
컨텍스트 전환 비용이 높을 수 있음: 스레드 간 전환 시 커널 모드로의 전환을 포함하기 때문에, 사용자 수준 스레드에 비해 컨텍스트 전환 비용이 더 높을 수 있습니다.
각 방법은 장단점을 가지고 있으며, 응용 프로그램의 요구 사항과 실행 환경에 따라 적절한 스레드 라이브러리를 선택해야 합니다.
PThread : C 언어 (user thread / kernel thread)
- Pthreads, POSIX 스레드의 약자로, 다중 스레딩 프로그래밍을 위한 표준 API를 정의합니다.
POSIX(휴대용 운영 체제 인터페이스)는 IEEE 1003.1c 표준의 일부로, 스레드 생성과 동기화를 위한 규격을 제공합니다. Pthreads는 스펙(명세)이며, 구현은 라이브러리 개발에 달려 있습니다. 즉, Pthreads는 어떻게 스레드 라이브러리가 동작해야 하는지를 규정하지만, 실제 동작은 해당 라이브러리를 개발하는 방식에 의존합니다.
Pthreads의 주요 특징
-
사용자 수준 또는 커널 수준에서 제공될 수 있음: Pthreads는 운영 체제의 지원 수준에 따라 사용자 수준 또는 커널 수준에서 구현될 수 있습니다.
-> Pthreads가 다양한 환경에서 유연하게 적용될 수 있음을 의미합니다. -
POSIX 표준 API: Pthreads는 휴대성과 호환성을 고려하여 설계된 표준 API를 제공합니다. 이를 통해 다양한 UNIX 계열 운영 체제에서 일관된 스레딩 프로그래밍이 가능합니다.
-
스펙(명세), 구현은 개발자에게 달려 있음: Pthreads는 API의 동작을 명세하지만, 실제 구현은 라이브러리 개발자의 몫입니다. 이는 개발자가 특정 운영 체제의 특성에 맞추어 최적화된 스레드 라이브러리를 구현할 수 있음을 의미합니다.
-
UNIX 운영 체제에서 널리 사용됨: Pthreads는 Solaris, Linux, Mac OS X와 같은 다양한 UNIX 계열 운영 체제에서 널리 사용됩니다. 이로 인해 UNIX 계열 시스템에서의 크로스 플랫폼 개발이 용이해집니다.
Pthreads의 주요 기능
-
스레드 생성과 종료: Pthreads API를 통해 스레드를 생성하고, 종료할 수 있습니다. 스레드는 동일한 프로세스 내에서 병렬로 실행되는 독립적인 실행 단위입니다.
-
동기화 메커니즘: 뮤텍스(mutexes), 조건 변수(condition variables), 세마포어(semaphores)와 같은 동기화 메커니즘을 제공하여 스레드 간의 동시 접근을 관리하고, 데이터의 일관성을 유지할 수 있습니다.
-
스레드 특정 데이터 (Thread-specific data): 스레드 각각이 고유의 데이터를 가질 수 있도록 지원합니다. 이를 통해 같은 함수 코드를 실행하더라도 각 스레드가 서로 다른 데이터를 처리할 수 있습니다.
-
Pthreads는 멀티스레딩을 구현하고자 하는 개발자들에게 표준화된 접근 방식을 제공함으로써, 휴대성과 호환성을 보장하는 동시에, 운영 체제의 특성을 최대한 활용할 수 있는 유연성을 제공합니다.
pthread_create()
pthread_create() 함수는 새 스레드를 생성하는 데 사용됩니다. 이 함수는 호출하는 프로세스 내에서 새로운 스레드를 시작하며, 성공적으로 스레드를 생성하면 새 스레드의 ID를 특정 변수에 저장합니다
int pthread_create(pthread_t thread, const pthread_attr_t attr, void (start_routine) (void ), void arg);
매개변수 설명
thread: 성공적으로 스레드가 생성되었을 때, 새로운 스레드의 ID를 저장할 변수의 주소입니다.
attr: 스레드 속성을 설정합니다. NULL을 전달하면 기본값으로 설정됩니다. 스레드의 스택 크기, 스케줄링 정책 등을 설정할 수 있습니다.
start_routine: 새 스레드가 생성될 때 실행할 함수의 주소입니다. 이 함수는 void 타입의 인자를 받고 void 타입의 값을 반환해야 합니다.
arg: start_routine에 전달될 인자입니다. 이를 통해 스레드에 필요한 데이터를 전달할 수 있습니다.
반환 값
성공 시: 0
실패 시: 에러 번호. 실패의 원인이 될 수 있는 에러 번호는 errno.h에 정의되어 있으며, 이를 통해 구체적인 에러 원인을 파악할 수 있습니다.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
// 스레드가 실행할 함수
void *print_message(void *threadid) {
long tid;
tid = (long)threadid;
printf("Hello World! It's me, thread #%ld!\n", tid);
pthread_exit(NULL);
}
int main () {
pthread_t thread;
int rc;
long t = 1;
// 스레드 생성
rc = pthread_create(&thread, NULL, print_message, (void *)t);
if (rc) {
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
// 메인 스레드 종료를 막기 위해 생성된 스레드가 종료될 때까지 대기
pthread_join(thread, NULL);
printf("Main: Program completed. Exiting.\n");
pthread_exit(NULL);
}pthread_join()
pthread_join() 함수는 호출하는 스레드가 지정된 스레드가 종료될 때까지 대기하게 합니다. 즉, 이 함수를 사용하면 한 스레드의 실행이 완료될 때까지 다른 스레드의 실행을 일시 중지시킬 수 있습니다. 이는 특정 스레드의 결과를 기다리거나, 스레드들 간의 동기화를 위해 유용하게 사용됩니다.
int pthread_join(pthread_t thread, void **retval);
매개변수 설명
thread: 대기할 스레드의 ID입니다. 이 스레드의 실행이 완료될 때까지 호출하는 스레드는 대기 상태에 들어갑니다. (wait랑 동일!)
retval: 종료된 스레드로부터 반환된 값입니다. 스레드의 start_routine 함수가 void* 타입의 값을 반환하는 경우, 이 인자를 통해 그 값을 받을 수 있습니다. 반환 값을 무시하려면 NULL을 전달하면 됩니다.
반환 값
성공 시: 0
실패 시: 에러 번호. 실패 시 반환되는 에러 번호는 errno.h에 정의되어 있으며, 에러의 원인을 파악하는 데 사용됩니다.
주의 사항
한 스레드에 대해 pthread_join() 함수는 한 번만 호출될 수 있습니다. 이미 join된 스레드에 대해 다시 join을 시도하면 에러가 발생합니다.
모든 자식 스레드들이 종료되었을 때 부모 스레드가 반환되는 것은 아닙니다. 부모 스레드와 자식 스레드는 독립적으로 실행되며, 부모 스레드가 종료되더라도 자식 스레드는 종료되지 않고 계속 실행될 수 있습니다. 따라서, 부모 스레드에서 자식 스레드들의 종료를 기다리려면 명시적으로 pthread_join()을 호출해야 합니다.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
// 스레드가 실행할 함수
void *myThreadFun(void *vargp)
{
sleep(1);
printf("Printing from Thread\n");
return NULL;
}
int main()
{
pthread_t thread_id;
printf("Before Thread\n");
pthread_create(&thread_id, NULL, myThreadFun, NULL);
// 여기서 메인 스레드는 새로 생성한 스레드가 종료될 때까지 대기합니다.
pthread_join(thread_id, NULL);
printf("After Thread\n");
exit(0);
}
// gcc -o program program.c -pthread <- compile sentence..pthread_cancel()
pthread_cancel() 함수는 지정된 스레드에게 취소 요청을 보냅니다. 이 함수를 호출하면 타겟 스레드는 취소 요청을 받게 되며, 이 요청에 대한 반응은 스레드의 취소 가능 상태(cancelability state)와 취소 유형(cancel type)에 따라 달라집니다. 이 두 속성은 스레드가 스스로 제어할 수 있으며, pthread_setcancelstate()와 pthread_setcanceltype() 함수를 사용하여 설정할 수 있습니다.
int pthread_cancel(pthread_t thread);
매개변수 설명
thread: 취소 요청을 보낼 스레드의 ID입니다.
반환 값
성공 시: 0
실패 시: 0이 아닌 에러 번호가 반환됩니다.
취소 가능 상태와 취소 유형
취소 가능 상태(pthread_setcancelstate()): 이 함수를 사용하여 스레드가 취소 요청을 받을 수 있는지 여부를 설정할 수 있습니다. 취소 가능 상태는 두 가지가 있습니다: PTHREAD_CANCEL_ENABLE (취소 가능)과 PTHREAD_CANCEL_DISABLE (취소 불가능).
취소 유형(pthread_setcanceltype()): 이 함수를 사용하여 스레드가 취소 요청을 어떻게 처리할지를 결정할 수 있습니다. 취소 유형에는 PTHREAD_CANCEL_DEFERRED (연기된 취소)와 PTHREAD_CANCEL_ASYNCHRONOUS (즉시 취소)가 있습니다.
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
void *thread_function(void *arg)
{
// 취소 가능 상태와 유형을 설정
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, NULL);
while (1) {
printf("Thread is running...\n");
sleep(1); // 잠시 대기
}
return NULL;
}
int main()
{
pthread_t thread_id;
pthread_create(&thread_id, NULL, thread_function, NULL);
sleep(3); // 메인 스레드에서 잠시 대기
printf("Sending cancel request to the thread...\n");
pthread_cancel(thread_id); // 취소 요청 전송
pthread_join(thread_id, NULL); // 스레드 종료 대기
printf("Thread was canceled.\n");
return 0;
}- java 경우는 기술하지 않고자 함. (Thread, Runnable, lambda ...)
◼ Implicit Threading
암시적 스레딩(Implicit Threading)은 프로그래머가 아닌 컴파일러와 런타임 라이브러리가 스레드의 생성 및 관리를 담당하는 프로그래밍 모델을 말합니다. 이 접근 방식의 주된 목적은 병렬 프로그래밍의 복잡성을 줄이고 개발자가 병렬화를 더 쉽게 활용할 수 있도록 하는 것입니다. 암시적 스레딩에는 여러 가지 방법이 있으며, 여기서는 그 중 세 가지를 탐색합니다: 스레드 풀(Thread Pools), 포크 조인 모델(Fork Join Model), 그리고 OpenMP입니다.
스레드 풀(Thread Pools)
-
스레드 풀에서는 여러 개의 스레드를 생성하여 작업을 기다리게 합니다.
-
장점
1) 기존 스레드를 사용하여 요청을 처리하는 것이 새 스레드를 생성하는 것보다 일반적으로 약간 더 빠릅니다.
2) 응용 프로그램에서 스레드의 수를 풀의 크기에 맞게 제한할 수 있습니다.
3) 수행할 작업을 생성 작업의 메커니즘으로부터 분리함으로써 작업을 실행하기 위한 다양한 전략을 사용할 수 있습니다.
-> 예를 들어, 작업을 일정 시간 지연 후에 실행하거나 주기적으로 실행하도록 예약할 수 있습니다.
정리: 스레드 풀은 사전에 정해진 수의 스레드를 생성하고, 이러한 스레드들은 작업을 받아 처리할 준비가 되어 있습니다. 이는 새로운 요청이 들어올 때마다 매번 새로운 스레드를 생성하는 것보다 효율적입니다. 스레드 풀을 사용함으로써, 시스템의 전체적인 성능을 향상시키고 자원 사용을 최적화할 수 있습니다. 또한, 특정 작업을 실행하는 방식을 유연하게 관리할 수 있어, 예를 들어 특정 작업을 일정 시간 후에 실행하거나 정기적으로 실행하는 등의 다양한 실행 전략을 적용할 수 있습니다. 이는 응용 프로그램의 성능과 반응성을 높이는 데 크게 기여합니다.
- JAVA의 경우는 다음과 같다.

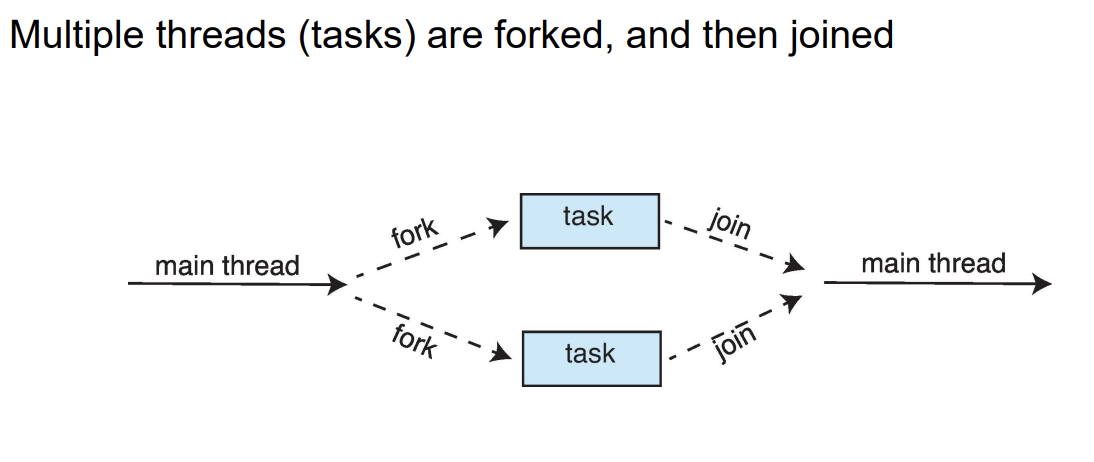
포크 조인 모델(Fork Join Model)
Fork Join Parallelism
ForkJoinTask
- ForkJoinTask는 추상 기본 클래스입니다.
- RecursiveTask와 RecursiveAction 클래스
- RecursiveTask와 RecursiveAction 클래스는 ForkJoinTask를 확장합니다.
- RecursiveTask는 결과를 반환합니다(이는 compute() 메소드의 반환 값을 통해 이루어집니다).
- RecursiveAction은 결과를 반환하지 않습니다.
정리
ForkJoinTask는 자바의 동시성 프로그래밍을 위한 고급 도구 중 하나로, 복잡한 작업을 더 작은 하위 작업으로 나누어 병렬로 처리할 수 있게 해줍니다. 이러한 작업을 분할 정복 방식으로 처리하는 데 있어서 ForkJoinTask는 기본적인 틀을 제공합니다.
RecursiveTask와 RecursiveAction 두 클래스는 ForkJoinTask를 상속받아 구현되며, 둘 다 재귀적으로 작업을 나누고 처리하는 데 사용됩니다. 차이점은 RecursiveTask는 최종적으로 결과를 반환하는 반면, RecursiveAction은 결과를 반환하지 않고 작업만 수행한다는 점입니다.
예를 들어, 큰 데이터 세트를 정렬하거나 검색하는 작업을 수행할 때, 이를 더 작은 단위로 나누어 각각 병렬로 처리한 후 결과를 합치는 방식으로 작업을 효율적으로 완료할 수 있습니다. RecursiveTask는 이러한 과정에서 중간 결과를 반환할 필요가 있을 때 사용되고, RecursiveAction은 단순히 작업을 수행만 하면 되는 경우에 적합합니다.
import java.util.concurrent.*;
import java.util.Arrays;
public class SumTask extends RecursiveTask<Integer>
{
static final int SIZE = 10000;
static final int THRESHOLD = 1000;
private int begin;
private int end;
private int[] array;
public SumTask(int begin, int end, int[] array) {
this.begin = begin;
this.end = end;
this.array = array;
}
protected Integer compute() {
if (end - begin < THRESHOLD) {
// conquer stage
int sum = 0;
for (int i = begin; i <= end; i++)
sum += array[i];
return sum;
}
else {
// divide stage
int mid = begin + (end - begin) / 2;
SumTask leftTask = new SumTask(begin, mid, array);
SumTask rightTask = new SumTask(mid + 1, end, array);
leftTask.fork();
rightTask.fork();
return rightTask.join() + leftTask.join();
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
int[] array = new int[SIZE];
// create SIZE random integers between 0 and 9
java.util.Random rand = new java.util.Random();
for (int i = 0; i < SIZE; i++) {
array[i] = rand.nextInt(10);
}
// use fork-join parallelism to sum the array
SumTask task = new SumTask(0, SIZE-1, array);
int sum = pool.invoke(task);
System.out.println(Arrays.toString(array));
System.out.println("The sum is " + sum);
}
}OpenMP
OpenMP(Open Multi-Processing)는 병렬 프로그래밍을 위한 API로, 포트란, C, C++ 언어를 지원합니다. OpenMP를 사용하면 프로그래머는 병렬 처리를 위한 명시적인 스레드 생성과 관리 없이도 병렬 코드를 쉽게 작성할 수 있습니다. OpenMP는 컴파일러 지시문, 런타임 라이브러리, 환경 변수를 사용하여 작업을 병렬로 분할하고, 스레드를 생성 및 관리합니다. 이는 병렬 루프, 섹션, 작업 분할 등 다양한 병렬 구조를 제공하여 개발자가 효율적으로 병렬 프로그램을 개발할 수 있도록 합니다.
#pragma omp parallel // 각각의 스레드가 다음 문장을 실행
printf("Hello, World!\n");
#pragma omp parallel for // 코어에 루프를 분산하여 실행
for(i=0; i<N; i++) {
c[i] = a[i] + b[i];
}
// #pragma omp parallel 지시문은 다음에 오는 문장을 병렬로 실행할 수 있는 스레드를 생성하라는 지시입니다.
// 이 예에서는 "Hello, World!\n"를 출력하는 printf 문이 병렬로 실행됩니다.
// 즉, 시스템에 있는 코어 수만큼 "Hello, World!" 메시지가 출력될 수 있습니다.
// #pragma omp parallel for 지시문은 for 루프를 병렬로 실행하도록 합니다.
// 이는 for 루프의 반복을 여러 코어에 분산시켜 각 코어에서 일부 반복을 처리하게 함으로써 전체적인
// 실행 시간을 단축시킵니다. 위의 예에서는 배열 a와 b의 각 요소를 더하여
// c 배열에 저장하는 작업을 병렬로 수행합니다.
// 이러한 방식을 통해, 복잡한 계산이나 대량의 데이터 처리 작업을 더 빠르게 수행할 수 있으며,
// 멀티코어 프로세서의 계산 능력을 효과적으로 활용할 수 있습니다.
// OpenMP는 이와 같은 병렬 처리를 위한 강력하고 사용하기 쉬운 도구를 제공합니다.
/////////////////////////////////////////
#include <omp.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
/* sequential code */
#pragma omp parallel // 이 밑에 있는건 모든 thread가 순차적으로 실행.
{
printf("I am a parallel region (thread=%d)\n", omp_get_thread_num());
}
/* sequential code */
return 0;
}
// 순차적 코드
// 이 코드는 main 함수 내에 두 부분의 순차적 코드가 있습니다.
// 첫 번째 부분은 #pragma omp parallel 지시문 이전에 위치하고, 두 번째 부분은 이 지시문 이후에 위치합니다.
// 이 두 부분은 프로그램의 시작과 끝에서 순차적으로 실행됩니다.
// 병렬 영역
// #pragma omp parallel 지시문은 병렬 영역을 정의합니다.
// 이 지시문 바로 다음에 오는 코드 블록은 병렬로 실행될 코드를 포함합니다.
// 이 예제에서는 printf 함수를 사용하여 각 스레드에서 "I am a parallel region (thread=%d)\n" 메시지와
// 함께 해당 스레드의 번호를 출력합니다. 스레드 번호는 omp_get_thread_num() 함수를 호출하여 얻습니다.
// 이 함수는 각 스레드에 대해 고유한 번호를 반환합니다.
// 실행 결과
// 이 프로그램을 실행하면, 시스템에서 사용 가능한 스레드 수만큼 "I am a parallel region (thread=x)"
// 메시지가 출력됩니다. 여기서 x는 스레드의 고유 번호입니다. 실제 출력되는 메시지의 순서와 스레드 번호는
// 실행할 때마다 달라질 수 있습니다.
// 이는 스레드가 운영 체제에 의해 독립적으로 스케줄링되기 때문입니다.
기타 방법
Grand Central Dispatch (GCD): 애플의 macOS 및 iOS 운영 체제에서 사용하는 기술로, 작업 중심의 병렬 처리 및 비동기 실행을 위한 방법을 제공합니다. Microsoft Threading Building Blocks (TBB): C++로 작성된 병렬 프로그래밍 라이브러리로, 휴리스틱 기반의 태스크 스케줄러를 제공하여 CPU 사용률을 최적화합니다.암시적 스레딩은 개발자가 병렬 프로그래밍의 복잡성을 덜어내고, 프로그램의 성능을 향상하는 데 도움을 준다.
◼ Threading Issues
fork()와 exec()
- fork() 함수
-
fork() 함수는 호출한 프로세스의 복사본을 생성하는 시스템 호출입니다. 생성된 복사본을 자식 프로세스라고 합니다.
-
다중 스레드 프로세스에서 fork()를 호출하면, 흥미로운 동작이 발생합니다. UNIX 시스템은 주로 두 가지 버전의 fork()를 제공합니다: fork()와 fork1().
-
fork()는 호출하는 순간의 프로세스 전체를 복사하여 자식 프로세스를 생성합니다. 그러나 POSIX 표준에 따르면, 자식 프로세스에는 호출 스레드만이 복제되고, 다른 모든 스레드는 복제되지 않습니다. 따라서, 표준 fork()의 동작은 운영 체제 및 환경에 따라 다를 수 있습니다.
-
fork1()은 호출 스레드만 복제하는 것이 명확하게 정의된 함수입니다. 즉, 자식 프로세스에는 호출 스레드만 존재하게 됩니다.
-
fork() 호출 후, 일반적으로 자식 프로세스에서 exec() 함수를 사용하여 새로운 프로그램을 실행합니다.
fork()랑 fork1()은 모두 동일한 결과를 만들어. 그런데 fork()를 한 경우, 현재 실행중인 thread에 대해서 fork()되었음을 의미하는데, 이에 혼동이 있을 수 있기 때문에 fork1()을 만들었다.
- exec() 함수
- exec() 함수는 현재 프로세스를 새로운 프로그램으로 대체하는 시스템 호출입니다. 이 함수는 프로세스의 코드, 데이터, 힙, 스택 등을 새로운 프로그램으로 교체하지만, 프로세스 ID는 유지됩니다.
- 다중 스레드 프로세스에서 exec()를 호출하면, 프로세스 내의 모든 스레드가 새로운 프로그램으로 대체됩니다. 즉, exec() 호출 시 실행되던 모든 스레드는 사라지고, 새로운 프로그램의 메인 함수가 실행됩니다.
Thread Cancellation
스레드 취소(Thread Cancellation)는 멀티스레딩 환경에서 중요한 이슈 중 하나입니다. 스레드 취소는 특정 스레드의 실행을 중단시키는 작업을 말합니다. 하지만 스레드가 다른 스레드와 리소스를 공유하는 환경에서 스레드를 취소하는 것은 여러 문제를 야기할 수 있습니다.
스레드 취소의 문제점
리소스 공유 문제: 프로세스는 각각 독립된 리소스를 가지고 있지만, 스레드는 같은 프로세스 내에서 실행되기 때문에 리소스를 공유합니다. 따라서, 하나의 스레드가 공유 데이터를 업데이트하는 도중에 취소되면, 데이터 일관성 및 무결성 문제가 발생할 수 있습니다.
스레드 취소의 일반적인 접근 방법
-
비동기 취소(Asynchronous cancellation): 대상 스레드를 즉시 종료시킵니다. 이 방법은 스레드를 빠르게 취소할 수 있다는 장점이 있지만, 공유 리소스를 업데이트하는 중간에 스레드를 종료시키므로 데이터의 일관성을 해칠 수 있는 큰 단점이 있습니다.
-
지연 취소(Deferred cancellation): 대상 스레드가 주기적으로 취소 여부를 확인하고, 안전한 지점에서 스레드의 실행을 중단시킵니다. 이 방법은 스레드가 공유 리소스의 업데이트를 완료하고, 데이터의 일관성을 유지할 수 있는 지점에 도달했을 때만 스레드를 종료시키므로 안전합니다. 하지만, 취소 요청이 즉각 반영되지 않을 수 있다는 단점이 있습니다.
결론
스레드 취소는 멀티스레딩 환경에서 고려해야 할 중요한 요소 중 하나입니다. 특히, 공유 리소스를 다룰 때는 데이터의 무결성과 일관성을 유지하는 것이 중요합니다. 따라서, 스레드를 취소할 때는 가능한 지연 취소 방법을 사용하여 안전한 지점에서만 스레드의 실행을 중단시키는 것이 권장됩니다. 이를 통해 멀티스레드 프로그램의 안정성과 신뢰성을 높일 수 있습니다.
스레드 취소 요청을 발생시키는 것은 해당 스레드에 취소 요청을 보내는 것을 의미하지만, 실제 취소가 이루어지는지 여부는 스레드의 상태에 따라 달라집니다.
스레드 취소 요청의 처리 과정
취소 요청 발생: 스레드 취소 요청이 발생하면, 해당 스레드는 취소 요청을 받았다는 상태로 전환됩니다. 하지만, 실제 취소가 즉시 이루어지는 것은 아니며, 스레드의 현재 상태와 설정에 따라 처리 방법이 달라집니다.취소 비활성화 상태: 스레드가 취소를 비활성화한 상태에서 취소 요청을 받으면, 이 요청은 대기 상태로 남게 됩니다. 취소 요청이 처리되기 위해서는 스레드가 취소를 다시 활성화할 때까지 기다려야 합니다.
지연 취소의 기본 설정: POSIX 스레드의 기본 취소 유형은 지연 취소(Deferred Cancellation)입니다. 이는 스레드가 명시적인 취소 지점(Cancellation Point)에 도달했을 때만 취소가 발생한다는 것을 의미합니다. pthread_testcancel() 함수는 스레드가 취소 요청을 받았는지 확인하는 취소 지점의 한 예입니다. 이 지점에 도달하면, 스레드는 취소 처리 과정을 시작합니다.
청소 핸들러(Cleanup Handler) 호출: 스레드가 취소되기 전에, 등록된 청소 핸들러가 호출됩니다. 이는 스레드가 사용했던 자원을 정리하고, 열려 있는 파일을 닫는 등의 작업을 수행하기 위한 것입니다.
리눅스 시스템에서의 스레드 취소: 리눅스 시스템에서는 스레드 취소가 시그널을 통해 처리됩니다. 특정 시그널이 스레드에 전달되면, 그 시그널을 처리하는 방식에 따라 스레드가 취소될 수 있습니다.
-> 시그널에 대한 부분은 차후에 학습함.

결론
스레드 취소는 멀티스레딩 프로그래밍에서 중요한 개념 중 하나입니다. 스레드에 대한 취소 요청은 해당 스레드의 상태와 설정에 따라 처리되며, 대부분의 경우 지연 취소 방식을 사용합니다. 이를 통해 스레드는 자원을 안전하게 정리하고, 필요한 청소 작업을 수행한 후에 중지될 수 있습니다. 리눅스 시스템에서는 시그널을 통한 스레드 취소 처리도 중요한 역할을 합니다.
Thread-Local Storage(TLS) in pthread
멀티스레딩 프로그래밍에서의 사용: TLS는 멀티스레딩 환경에서 각 스레드가 데이터의 자체 복사본을 가질 수 있도록 하는 기술입니다. 이를 통해 스레드 간의 데이터 충돌 및 동기화 문제를 방지할 수 있습니다.
이는 다수의 스레드가 동일한 글로벌 변수에 접근할 때 발생할 수 있는 데이터 공유와 관련된 문제를 해결해 줍니다.
간단 정리 : TLS(Thread-Local Storage)는 간단히 말해 멀티스레딩 환경에서 각 스레드에게 고유한 저장 공간을 제공하는 기술입니다. 이를 통해, 각 스레드는 다른 스레드와 데이터를 공유하지 않고 자신만의 데이터를 독립적으로 관리할 수 있게 됩니다.
- TLS의 특징과 장점
스레드별 데이터 복사본: 프로세스 내의 모든 스레드는 글로벌 변수를 공유하지만, TLS를 사용하면 각 스레드는 데이터의 자신만의 복사본을 유지할 수 있습니다. 예를 들어, __thread int tls; 선언을 통해 각 스레드는 자체 'int tls' 변수를 가집니다.
로컬 변수와의 차이: 로컬 변수는 단일 함수 호출 동안에만 보이는 반면, TLS 변수는 여러 함수 호출에 걸쳐 보이며, 스레드 내에서 지속적으로 접근 가능합니다.
정적 데이터와의 유사성: TLS는 정적 데이터와 유사하게 동작하지만, 각 스레드는 해당 데이터의 고유한 인스턴스를 가집니다. 이는 스레드 간 데이터 격리를 보장합니다.
스레드 생성 제어 부재시 유용함: 스레드 풀을 사용하는 경우와 같이 스레드 생성 과정을 직접 제어할 수 없는 상황에서 특히 유용합니다. 이런 경우 TLS를 사용하면, 스레드가 작업을 처리하는 동안 필요한 고유한 데이터를 유지할 수 있습니다.
TLS의 활용
TLS는 다양한 멀티스레딩 환경에서 유용하게 사용됩니다. 예를 들어, 웹 서버에서 각 스레드가 다른 클라이언트의 요청을 처리할 때 클라이언트별 세션 정보를 TLS에 저장하여 각 스레드가 자신의 클라이언트 세션 정보에만 접근하도록 할 수 있습니다. 이는 데이터의 안전한 격리와 효율적인 접근을 가능하게 합니다.
결론
TLS는 멀티스레딩 환경에서 데이터 격리와 스레드별 데이터 관리를 위한 강력한 도구입니다. 각 스레드에게 데이터의 고유한 복사본을 제공함으로써, 데이터의 안전한 접근과 관리를 보장합니다. 스레드 생성을 직접 제어할 수 없는 환경에서도 각 스레드가 필요한 데이터를 안전하게 관리할 수 있게 해 줍니다.
// Thread-Local Storage in pthread
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#define THREADS 3
__thread int tls;
int global;
void *func(void *arg)
{
int num = *((int*)arg);
tls = num;
global = num;
sleep(1);
printf("Thread = %d tls = %d global = %d\n",
num, tls, global);
}
int main() {
int ret;
pthread_t thread[THREADS];
int num;
for (num = 0; num < THREADS; num++) {
ret = pthread_create(&thread[num], NULL, &func, (void*)&num);
if (ret) {
printf("error pthread_create\n");
exit(1);
}
}
for (num = 0; num < THREADS; num++) {
ret = pthread_join(thread[num], NULL);
if (ret) {
printf("error pthread_join\n");
exit(1);
}
}
return 0;
}Scheduler Activations
스케줄러 활성화(Scheduler Activations)는 운영 체제가 사용자 수준 스레드와 커널 수준 스레드 사이의 효율적인 통신과 조정을 가능하게 하는 고급 스레딩 모델입니다. 이 모델은 M:M(다대다) 및 두 수준(Two-level) 스레딩 모델에서 필요로 하는, 애플리케이션에 할당된 커널 스레드 수를 적절히 유지하기 위한 통신을 제공합니다.
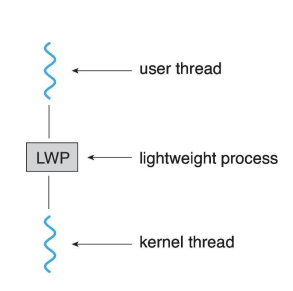
스케줄러 활성화의 주요 개념
경량 프로세스(LWP): 스케줄러 활성화 모델은 사용자 스레드와 커널 스레드 사이에 LWP라는 중간 데이터 구조를 사용합니다. LWP는 가상의 프로세서처럼 보이며, 프로세스는 이 위에서 사용자 스레드를 스케줄링할 수 있습니다. 각 LWP는 커널 스레드에 연결됩니다.
업콜(Upcalls): 스케줄러 활성화는 커널로부터 스레드 라이브러리 내의 업콜 핸들러로의 통신 메커니즘인 업콜을 제공합니다. 이는 애플리케이션이 올바른 수의 커널 스레드를 유지할 수 있도록 합니다.
스케줄러 활성화의 장점
효율적인 자원 사용: 애플리케이션의 요구에 따라 커널 스레드의 수를 동적으로 조정함으로써, 시스템 자원을 보다 효율적으로 사용할 수 있습니다.
스케줄링 유연성: 사용자 수준 스레드를 더 세밀하게 제어할 수 있으며, 커널의 스케줄링 결정에 직접적으로 영향을 줄 수 있습니다.
성능 최적화: 애플리케이션의 특정 요구 사항에 맞게 스레드 관리를 최적화할 수 있어, 전체적인 시스템 성능을 향상시킬 수 있습니다.
LWP 생성 수 결정
애플리케이션의 성능 요구 사항과 자원 사용 제약을 고려하여 LWP의 적절한 수를 결정해야 합니다. 너무 적은 수의 LWP를 생성하면 스레드의 병렬 실행 가능성이 제한되고, 너무 많은 수의 LWP를 생성하면 컨텍스트 스위칭 오버헤드가 증가할 수 있습니다. 따라서, 애플리케이션의 특성과 시스템의 자원 상황을 고려하여 적절한 균형을 찾는 것이 중요합니다
정리

◼ Signal
시그널(Signal)은 UNIX 시스템에서 특정 이벤트가 발생했음을 프로세스에 알리기 위해 제공되는 메커니즘입니다. 시그널은 프로세스에 다양한 방식으로 발생할 수 있으며, 프로세스는 이를 적절히 처리해야 합니다.
시그널이 생성되는 원인
다양한 소스: 시그널은 운영 체제, 다른 프로세스, 또는 프로세스 자체의 예외 상황 등 다양한 원인으로부터 생성될 수 있습니다.
시그널의 전달 및 처리
프로세스로의 전달: 생성된 시그널은 대상 프로세스로 전달됩니다.
처리 방법:
기본 시그널 핸들러(커널): 각 시그널에 대해 운영 체제가 제공하는 기본적인 처리 방법이 실행됩니다. 예를 들어, 프로세스 종료나 중단 등이 있습니다.
사용자 정의 시그널 핸들러: 프로그래머가 특정 시그널에 대해 특별히 정의한 처리 방법입니다. 프로세스는 이를 이용해 특정 시그널을 원하는 방식으로 처리할 수 있습니다.
시그널의 종류
동기적 시그널(Synchronous): 동일한 프로세스(하나 일 하는 동안, 다른 건 일 못함)에서 발생하는 시그널입니다. 예를 들어, 잘못된 메모리 접근이나 0으로 나누기 같은 예외 상황이 이에 해당합니다.
비동기적 시그널(Asynchronous): 외부 소스(동시성 가능)로부터 오는 시그널입니다. 예를 들어, 사용자가 키보드로 <Ctrl>-C를 입력하여 인터럽트 신호를 보내는 경우가 이에 해당합니다.
시그널은 UNIX 및 유닉스 계열 운영 체제에서 프로세스 간 통신(IPC)의 한 형태로 사용됩니다. 시그널을 통해 프로세스는 비동기적으로 외부 이벤트나 시스템의 예외 상황에 반응할 수 있습니다. 프로그래머는 시그널 핸들러를 정의함으로써 특정 시그널에 대한 특수한 반응을 구현할 수 있으며, 이를 통해 프로그램의 안정성과 유연성을 높일 수 있습니다.
시그널 처리 방법(Disposition)은 특정 시그널이 프로세스에 전달될 때 프로세스의 반응을 결정하는 방식을 말합니다. UNIX 및 유닉스 계열 운영 체제에서 각 시그널은 현재 처리 방법을 가지고 있으며, 이는 프로세스가 해당 시그널을 받았을 때 어떻게 동작할지를 결정합니다.
시그널 처리 방법 설정
시그널 핸들러 정의: 특정 시그널이 발생했을 때 호출되는 함수를 제공할 수 있습니다. 이 함수를 시그널 핸들러라고 합니다. 프로그래머는 시그널 핸들러를 정의하여 특정 시그널에 대한 커스텀 반응을 구현할 수 있습니다.
시그널 무시하기: 프로세스가 특정 시그널을 무시하도록 설정할 수 있습니다. 이는 시그널의 처리 방법을 SIG_IGN으로 설정함으로써 가능합니다. 이 설정이 적용되면 해당 시그널이 전달되어도 아무런 조치가 취해지지 않습니다.
기본 처리 방법 설정하기: 시그널의 처리 방법을 기본값으로 설정할 수 있습니다. 이는 시그널의 처리 방법을 SIG_DFL로 설정함으로써 가능합니다. 기본 처리 방법은 시그널마다 다르며, 일반적으로 프로세스의 종료, 중단 등의 동작이 포함됩니다.
// 예시
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
void signalHandler(int signum) {
printf("시그널 %d가 처리되었습니다.\n", signum);
// 시그널 처리 코드
}
int main() {
// SIGINT에 대한 사용자 정의 핸들러 설정
signal(SIGINT, signalHandler);
// SIGTERM을 무시하도록 설정
signal(SIGTERM, SIG_IGN);
// 무한 루프를 돌면서 시그널 대기
while(1) {
sleep(1); // 1초 동안 대기
}
return 0;
}이 코드는 SIGINT 시그널(일반적으로 -C로 생성)을 받았을 때 사용자 정의 핸들러 signalHandler를 호출하도록 설정합니다. 또한, SIGTERM 시그널은 무시하도록 설정합니다. 프로그램은 무한 루프를 돌면서 시그널을 대기하고, 시그널이 발생하면 설정된 처리 방법에 따라 반응합니다.
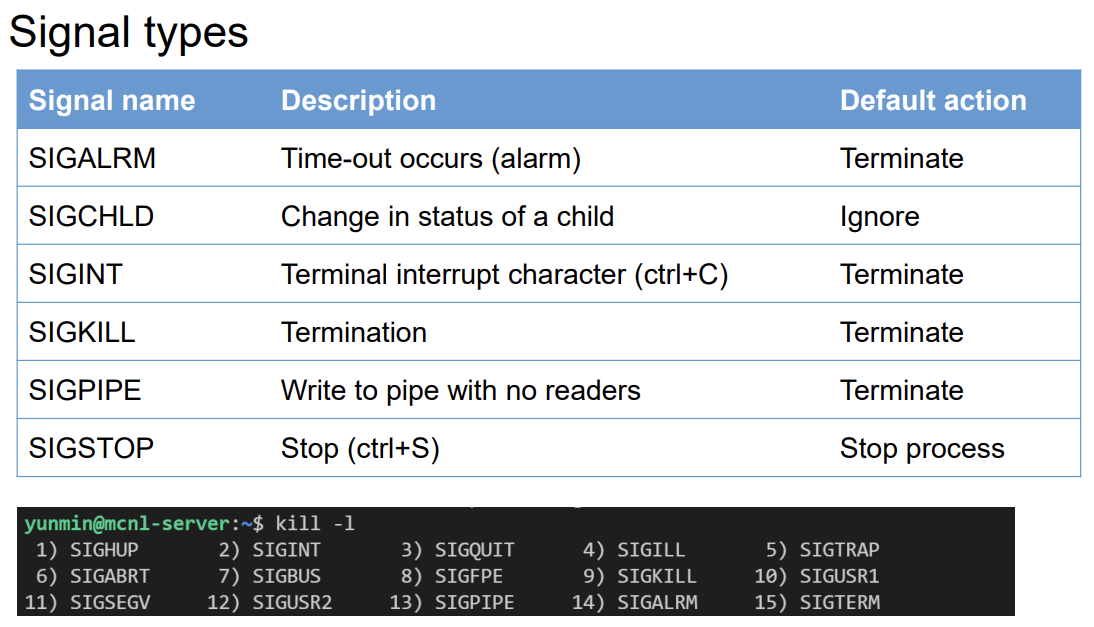
시그널 핸들링에 있어서, 어느 스레드에 시그널이 전달되어야 하는지는 중요한 질문입니다. 이에 대한 가능한 옵션들은 다음과 같습니다:
해당 시그널이 적용되는 스레드에게 전달하기: 특정 동작이나 에러가 발생한 스레드에만 시그널을 전달하는 방식입니다. 예를 들어, 특정 스레드가 잘못된 메모리 접근을 시도했을 때, 그 스레드에만 SIGSEGV 시그널을 전달할 수 있습니다.
프로세스 내의 모든 스레드에게 전달하기: 이 방식은 프로세스 내의 모든 스레드에 시그널을 전달합니다. 예를 들어, SIGINT(Ctrl+C)와 같은 중단 시그널이 발생했을 때, 이를 처리하기 위해 프로세스 내의 모든 스레드에게 시그널을 전달할 수 있습니다.
특정 스레드들에게만 전달하기: 프로세스 내에서 특정 스레드들에게만 시그널을 전달하는 방식입니다. 이는 특정 스레드 그룹이 시그널을 처리하는 방식을 제어할 때 유용할 수 있습니다.
특정 스레드에 모든 시그널을 할당하기: 시그널 처리를 전담할 특정 스레드를 지정하여, 모든 시그널을 그 스레드로 전달하는 방식입니다. 이 방식을 사용하면 시그널 처리 로직을 한 곳에 집중시켜 관리할 수 있습니다.
특정 스레드에 시그널 전달하기: POSIX 표준의 pthread_kill(tid, signal) 함수를 사용하여, 프로그램 코드 내에서 명시적으로 특정 스레드에 시그널을 전달할 수 있습니다. 이 방식을 통해 개발자는 프로그램의 동작을 더 세밀하게 제어할 수 있습니다.
시그널이 어떤 스레드에 전달될지 결정하는 방식은 시그널의 유형이나 프로그램의 요구사항에 따라 달라질 수 있습니다. 어떤 경우에는 특정 시그널이 발생했을 때 모든 스레드에게 알리는 것이 바람직할 수 있으며, 다른 경우에는 특정 스레드에만 시그널을 전달하는 것이 더 적합할 수 있습니다. 따라서, 시그널 핸들링 전략을 결정할 때는 애플리케이션의 특성과 요구사항을 충분히 고려해야 합니다.
◼ Operating System Examples
리눅스에서 스레드는 전통적인 운영 체제의 스레드와는 약간 다른 방식으로 처리됩니다. 리눅스는 스레드를 '작업(task)'이라고 부르며, 프로세스와 거의 동일한 방식으로 관리합니다. 이는 리눅스가 경량 프로세스(Lightweight Process, LWP) 모델을 사용하기 때문입니다.
스레드 생성: clone() 시스템 콜
리눅스에서 스레드(또는 작업) 생성은 clone() 시스템 콜을 통해 이루어집니다. clone()은 fork()의 확장된 버전으로 볼 수 있으며, 부모 작업(프로세스)와 자식 작업(스레드) 간에 어떤 자원을 공유할지를 세밀하게 제어할 수 있게 해줍니다.
주요 특징
주소 공간 공유: clone()을 사용하여 생성된 자식 스레드는 부모 스레드와 주소 공간을 공유할 수 있습니다. 이는 스레드 간의 데이터 공유를 용이하게 하며, 컨텍스트 스위칭 비용을 줄여 성능을 향상시킵니다.
동작 제어 플래그: clone() 시스템 콜은 다양한 플래그를 통해 자식 작업의 동작을 제어할 수 있습니다. 예를 들어, CLONE_VM 플래그는 부모와 자식이 가상 메모리를 공유하도록 하며, CLONE_FS, CLONE_FILES, CLONE_SIGHAND 등의 플래그를 통해 파일 시스템, 파일 디스크립터, 시그널 핸들러 등을 공유할지 여부를 결정할 수 있습니다.
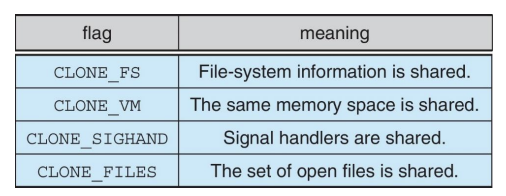
struct task_struct: 리눅스에서 모든 작업(스레드 포함)은 task_struct 구조체로 표현됩니다. 이 구조체는 프로세스의 상태, 메모리 정보, 스케줄링 정보, 열린 파일의 목록, 신호 처리 정보 등 작업에 대한 거의 모든 정보를 포함합니다. 스레드는 이 구조체를 통해 고유한 정보(예: 스레드 ID)를 가질 수 있으며, 필요에 따라 부모 작업과 정보(예: 주소 공간)를 공유할 수 있습니다.
리눅스에서의 스레드 처리 방식은 운영 체제가 프로세스와 스레드를 거의 동등한 시민으로 취급한다는 점에서 독특합니다. 이 접근 방식은 스레드 간의 통신과 자원 공유를 매우 유연하게 만들어 주며, 리눅스의 멀티태스킹 및 병렬 처리 능력의 기반이 됩니다.
