◼ Basic Concepts
Motivation
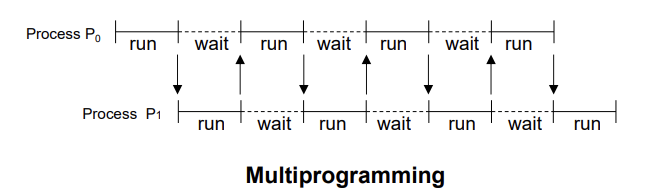
: 멀티프로그래밍과 멀티태스킹을 통해 최대 CPU 활용도를 달성할 수 있습니다.멀티프로그래밍과 멀티태스킹은 컴퓨터 시스템의 효율성을 높이기 위한 기술입니다. 멀티프로그래밍은 여러 프로그램이 동시에 메모리에 적재되어 CPU가 유휴 상태에 빠지지 않도록 하는 기술입니다. 이를 통해 CPU는 항상 작업을 처리할 수 있는 상태를 유지하며, 시스템의 전체적인 효율성이 향상됩니다.
→ 자원(포함된 CPU)은 프로세스 간에 공유됩니다.
컴퓨터 시스템에서는 CPU와 같은 자원들이 여러 프로세스에 의해 공유됩니다. 프로세스는 실행중인 프로그램의 인스턴스로, 시스템의 자원을 사용하여 작업을 수행합니다. 운영 시스템은 스케줄링 알고리즘을 사용하여 CPU 시간을 프로세스 간에 효율적으로 분배합니다. 이를 통해 각 프로세스는 필요한 연산을 수행할 수 있는 충분한 CPU 시간을 얻게 되며, 이는 시스템 전체의 성능과 반응성을 향상시킵니다.
멀티프로그래밍과 멀티태스킹을 통한 자원 공유는 컴퓨터 시스템의 자원을 최대한 활용하여 작업을 더 빠르고 효율적으로 처리할 수 있게 합니다. 이러한 기술은 현대 컴퓨터 시스템의 기본이 되며, 다양한 애플리케이션과 서비스가 동시에 실행될 수 있는 환경을 제공합니다.
CPU-IO Burst Cycle
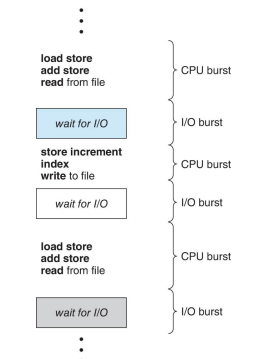
CPU-IO 버스트 사이클은 프로세스 실행의 핵심 개념 중 하나입니다. 이 사이클은 CPU 실행과 I/O 대기의 연속적인 주기로 구성됩니다. 프로세스의 실행은 CPU 버스트로 시작해서 CPU 버스트로 끝나며, 사이에 여러 I/O 대기 시간이 포함될 수 있습니다.CPU 버스트(CPU Burst): 프로세스가 CPU를 사용하여 명령어를 실행하는 시간입니다. 이 시간 동안 프로세스는 계산이나 데이터 처리와 같은 작업을 수행합니다.
I/O 버스트(I/O Burst): 프로세스가 입출력 작업을 위해 대기하는 시간입니다. 이 시간 동안 프로세스는 디스크 액세스, 네트워크 통신, 사용자 입력과 같은 I/O 작업을 기다립니다.
프로세스는 크게 두 가지 유형으로 분류할 수 있습니다.
→ I/O-bound 프로세스:
많은 짧은 CPU 버스트들로 구성됩니다.
이러한 프로세스는 주로 I/O 작업에 더 많은 시간을 소비하며, CPU를 짧게 사용한 후에는 빠르게 I/O 작업으로 전환합니다.
I/O-bound 프로세스는 I/O 작업의 완료를 기다리는 시간이 많기 때문에, 전체 실행 시간 동안 CPU 사용량은 상대적으로 낮습니다.
→ CPU-bound 프로세스:
몇 개의 긴 CPU 버스트로 구성됩니다.
이러한 프로세스는 복잡한 계산이나 데이터 처리와 같은 CPU 집약적인 작업을 수행합니다.
CPU-bound 프로세스는 CPU를 오랜 시간 동안 사용하며, I/O 작업에 비해 CPU 사용 시간이 훨씬 길습니다.
이러한 특성을 이해하고 관리하는 것은 운영체제의 작업 스케줄링과 자원 관리에서 중요한 역할을 합니다. 운영체제는 이러한 특성을 고려하여 프로세스에 CPU 시간을 할당하고, 시스템의 전체 성능을 최적화합니다.
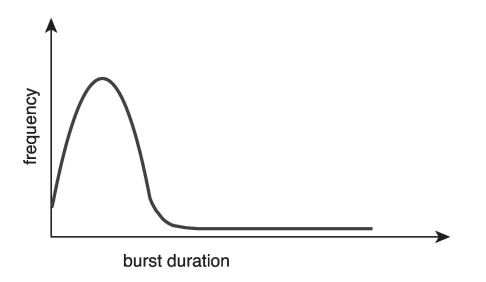
Histogram of CPU-burst Time
히스토그램에서 CPU 버스트 시간 분포는 시스템의 성능과 스케줄링 전략을 이해하는 데 중요한 요소입니다. CPU 버스트 시간의 분포는 일반적으로 다음과 같은 특징을 보입니다:
대부분의 버스트는 짧습니다: 시스템에서 실행되는 대부분의 프로세스는 짧은 CPU 버스트를 가지며, 이는 전체 분포에서 큰 비율을 차지합니다. 이러한 짧은 버스트는 주로 I/O 바운드 프로세스에서 발생하며, 이 프로세스들은 CPU를 짧게 사용한 후 I/O 작업을 위해 대기 상태로 전환됩니다.
긴 버스트는 소수에 불과합니다: 긴 CPU 버스트를 가진 프로세스는 전체 프로세스 중 소수에 불과합니다. 이러한 프로세스는 주로 CPU 바운드 프로세스로, 복잡한 계산이나 데이터 처리와 같은 CPU 집약적 작업을 수행합니다.
이러한 분포는 운영 시스템의 스케줄링 전략에 중요한 영향을 미칩니다. 예를 들어, 짧은 버스트를 가진 프로세스에 우선순위를 주는 스케줄링 알고리즘(예: 단기 작업 우선 스케줄링)은 시스템의 응답성을 향상시킬 수 있습니다. 반면, 긴 버스트를 가진 프로세스를 고려하는 스케줄링 전략(예: 시분할 스케줄링)은 공평한 자원 분배를 목표로 할 수 있습니다.
결론적으로, CPU 버스트 시간의 히스토그램은 프로세스의 특성을 이해하고, 이를 바탕으로 효과적인 스케줄링 전략을 수립하는 데 중요한 정보를 제공합니다. 운영 시스템은 이러한 분포를 분석하여 시스템 자원을 최적화하고, 전체적인 성능과 효율성을 개선할 수 있습니다.
CPU Scheduler
-
CPU scheduler (=short term scheduler)
: 준비 큐에 있는 프로세스 중 하나를 선택하여 CPU 코어를 할당하는 역할을 합니다. 이는 시스템의 효율성과 반응성을 최적화하기 위해 중요한 역할을 수행합니다. -
Implementation of ready queue
: FIFO(First In First Out) 큐: 가장 간단한 형태로, 먼저 준비 큐에 들어온 프로세스가 먼저 CPU를 할당받습니다.
우선순위 큐: 각 프로세스에 우선순위를 부여하고, 가장 높은 우선순위를 가진 프로세스가 CPU를 먼저 할당받습니다.
트리: 트리 구조를 이용해 다양한 스케줄링 조건을 효율적으로 구현할 수 있습니다. 예를 들어, 우선순위에 따라 트리의 각 노드를 할당할 수 있습니다.
정렬된 연결 리스트: 프로세스들이 특정 기준(예: 우선순위, 도착 시간 등)에 따라 정렬됩니다. 이 구조는 우선순위 큐의 변형으로 볼 수 있습니다.

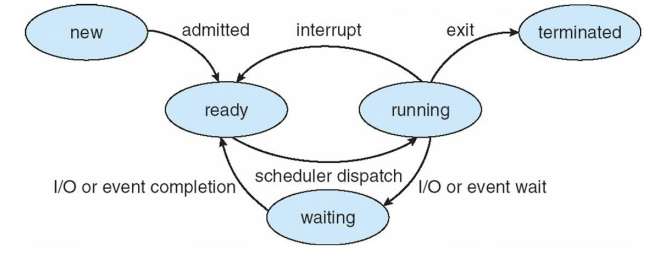
When Scheduling Occurs?
스케줄링이 발생하는 시점에 대해 설명하겠습니다. 운영 체제에서 스케줄링은 프로세스의 상태가 변화할 때 발생합니다. 이러한 상태 변화는 다음과 같은 네 가지 주요 상황에서 발생합니다:
-
실행 상태에서 대기 상태로 전환될 때: 이는 프로세스가 I/O 요청을 하거나 wait() 함수를 호출할 때 발생합니다. 이 상태에서는 프로세스가 CPU를 사용하지 않고, I/O 작업 완료나 다른 이벤트를 기다리게 됩니다.
-
실행 상태에서 준비 상태로 전환될 때: 이는 외부 인터럽트 또는 시간 할당량(time slice)이 끝나는 등의 이유로 현재 실행 중인 프로세스가 중단될 때 발생합니다. 이때 다른 프로세스가 CPU를 할당받을 준비가 됩니다.
-
대기 상태에서 준비 상태로 전환될 때: 이는 프로세스가 I/O 작업 등의 완료로 인해 다시 CPU 할당을 받을 준비가 되었을 때 발생합니다.
-
프로세스가 종료될 때: 프로세스가 작업을 완료하고 종료되면, 시스템은 새로운 프로세스를 실행 상태로 전환시키기 위해 스케줄링을 진행합니다.
이러한 상황 중에서 1번과 4번 상황에서는 스케줄링이 비선점(nonpreemptive) 방식으로 진행됩니다. 비선점 스케줄링은 한 번 CPU를 할당받은 프로세스가 자발적으로 CPU를 반납할 때까지 계속해서 CPU를 사용할 수 있습니다. 반면, 2번과 3번 상황에서는 선점(preemptive) 스케줄링이 가능합니다. 선점 스케줄링은 운영 체제가 현재 실행 중인 프로세스를 중단시키고, 더 우선순위가 높은 프로세스에게 CPU를 할당할 수 있습니다.
이렇게 다양한 상황에서 스케줄링이 발생하며, 이는 시스템의 효율성과 반응성을 최적화하는 데 중요한 역할을 합니다.
Preemptive Scheduling
선점형 스케줄링과 비선점형 스케줄링은 운영 시스템에서 프로세스를 어떻게 관리하고 CPU 시간을 어떻게 분배할지 결정하는 두 가지 주요 방법입니다.
Non-preemptive (or cooperative) scheduling
스케줄링 시점: 프로세스가 실행 상태에서 대기 상태로 전환하거나 프로세스가 종료될 때만 발생합니다(1, 4 상황). 실행 중인 프로세스 중단: 실행 중인 프로세스는 __자발적__으로 CPU 사용을 포기하거나 종료될 때까지 중단되지 않습니다. -> "강제로 내쫓기 불가능" 장점: 간단하고 이해하기 쉬움. 데이터 공유 시 레이스 컨디션 발생 가능성이 낮음. 단점: 높은 우선순위의 프로세스가 CPU를 기다려야 할 수 있으며, 이는 시스템의 반응성과 효율성을 저하시킬 수 있습니다.Preemptive scheduling
스케줄링 시점: 프로세스가 실행 상태에서 대기 상태로 전환, 실행 중인 프로세스가 준비 상태로 전환, 대기 상태에서 준비 상태로 전환, 프로세스가 종료될 때(1, 2, 3, 4 상황) 발생할 수 있습니다. 실행 중인 프로세스 중단: 실행 중인 프로세스는 인터럽트 발생이나 더 높은 우선순위의 프로세스가 준비될 경우 중단될 수 있습니다. -> "강제 종료 가능" 장점: 시스템의 반응성과 효율성을 향상시킵니다. 높은 우선순위의 작업이 빠르게 처리될 수 있도록 합니다. 단점: 하드웨어 지원이 필요하며, 공유 데이터를 다룰 때 레이스 컨디션이 발생할 수 있습니다. 이는 데이터 일관성 유지를 위해 추가적인 동기화 메커니즘이 필요함을 의미합니다. 선점형 스케줄링은 시스템의 효율성과 반응성을 높이는 데 유리하지만, 공유 데이터의 동기화와 레이스 컨디션 문제에 대한 주의가 필요합니다. 비선점형 스케줄링은 이러한 문제에서 자유롭지만, 시스템의 반응성이 비선점형에 비해 떨어질 수 있습니다.Dispatcher
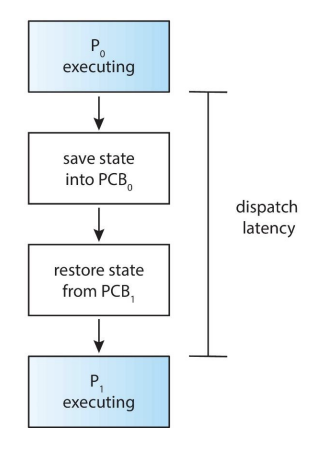
디스패처(Dispatcher)는 단기 스케줄러(Short-term scheduler)에 의해 선택된 프로세스에게 CPU 제어권을 넘겨주는 모듈입니다. 이 과정은 다음과 같은 단계들을 포함합니다:
컨텍스트 스위칭(Context Switching): 현재 실행 중인 프로세스의 상태(컨텍스트)를 저장하고, CPU가 다음에 실행할 프로세스의 상태를 복원합니다. 이렇게 함으로써, 각 프로세스는 자신이 마지막으로 실행되었던 시점부터 실행을 재개할 수 있습니다.
사용자 모드로 전환(Switching to User Mode): 프로세스가 사용자 수준의 코드를 실행할 수 있도록 CPU를 사용자 모드로 전환합니다. 대부분의 운영 체제는 더 높은 보안과 안정성을 위해 커널 모드(운영 체제 코드 실행)와 사용자 모드(사용자 애플리케이션 코드 실행)를 구분합니다.
적절한 위치로 점프(Jumping to the Proper Location): 프로세스가 이전에 중단되었던 정확한 위치로 점프하여 프로그램 실행을 재개합니다. 이는 프로세스의 프로그램 카운터(Program Counter)에 저장된 정보를 사용하여 이루어집니다.
디스패치 지연(Dispatch Latency): 디스패처가 한 프로세스의 실행을 중지하고 다른 프로세스를 실행하기 시작하는 데 걸리는 시간을 말합니다. 디스패치 지연은 시스템의 반응성과 성능에 중요한 영향을 미칩니다. 빠른 디스패치 지연은 시스템이 더 민첩하게 반응할 수 있게 하며, 멀티태스킹 환경에서의 성능을 향상시킵니다. 따라서, 운영 체제 설계에서는 가능한 한 디스패치 지연을 최소화하기 위해 노력합니다.
Scheduling Criteria
스케줄링 기준은 운영체제가 프로세스를 얼마나 효율적으로 관리하고 있는지를 평가하는 데 도움이 됩니다. 여러 스케줄링 기준은 다음과 같습니다:
CPU 사용률(CPU Utilization): CPU가 가능한 한 바쁘게 유지되도록 하는 것입니다. 높은 CPU 사용률은 시스템이 자원을 효율적으로 사용하고 있음을 의미합니다.
처리량(Throughput): 시간 단위당 완료된 프로세스의 수입니다. 높은 처리량은 시스템이 많은 작업을 빠르게 처리할 수 있음을 의미합니다.
반환 시간(Turnaround Time): 프로세스가 제출된 시점부터 완료될 때까지의 시간 간격입니다. 이는 시스템의 효율성을 나타내는 중요한 지표 중 하나입니다.
대기 시간(Waiting Time): 준비 큐에서 대기하는 동안 보낸 시간의 합입니다. 낮은 대기 시간은 프로세스가 CPU를 할당받기 위해 오랜 시간 기다리지 않았음을 의미합니다.
응답 시간(Response Time): 요청을 제출한 시점부터 첫 번째 응답이 나올 때까지의 시간입니다. 대화식 시스템에서는 사용자의 만족도와 직결되는 중요한 요소입니다.
각 기준의 중요성은 시스템의 목적과 환경에 따라 달라집니다. 예를 들어, 배치 처리 시스템에서는 처리량과 반환 시간이 매우 중요할 수 있으며, 대화식 시스템에서는 응답 시간과 대기 시간이 더 중요할 수 있습니다.
스케줄링 성능을 측정하고 최적화하기 위한 방법으로, 평균값, 최소값, 최대값, 분산 등을 사용할 수 있습니다. 평균값은 전반적인 성능을 측정하는 데 유용하며, 최소값과 최대값은 성능의 변동성을 나타내고, 분산은 성능의 일관성을 평가하는 데 도움이 됩니다. 이러한 측정치를 통해 시스템의 성능을 평가하고, 필요한 경우 스케줄링 알고리즘을 조정하여 최적화할 수 있습니다.
◼ Scheduling Algorithms
Scheduling Algorithms
◼ First-come, first-served (FCFS) scheduling
Process that requests CPU first, is allocated CPU first
◼ Non-preemptive scheduling
◼ Simplest scheduling method
◼ Sometimes average waiting time is quite long
◼ CPU, I/O utilities are inefficient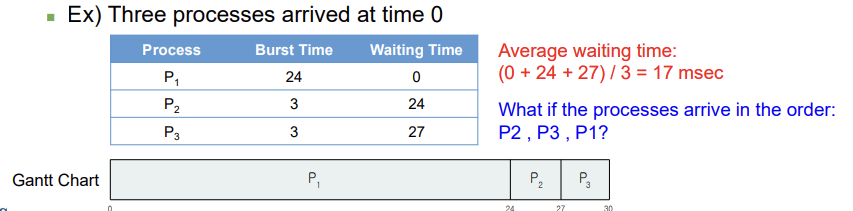
◼ Shortest-job-first (SJF) scheduling
Assign to the process with the smallest next CPU burst


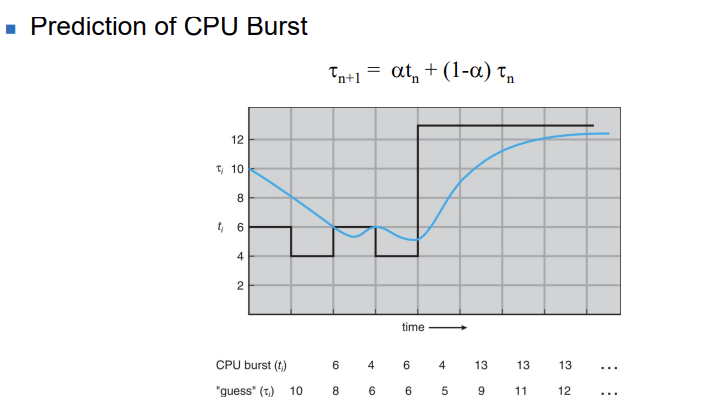
alpha = .5라 가정 할 경우, 위의 계산이 나올 수 있다.
◼ Round-robin scheduling : 시계열분석
비슷한 개념을 가진 스케줄링 알고리즘이지만 선점형 방식을 채택한 것은 'Round Robin (RR)' 스케줄링입니다. 시분할 시스템을 위해 설계된 이 알고리즘은 CPU 사용 시간을 '타임 퀀텀' 또는 '타임 슬라이스'로 나누어 프로세스에 할당합니다. 타임 퀀텀은 일반적으로 10~100 밀리초 사이로 설정되며, 이는 프로세스가 CPU를 점유할 수 있는 최대 시간을 의미합니다. 컨텍스트 스위칭 지연시간은 10 마이크로초로, 타임 퀀텀에 비해 상당히 짧습니다.
RR 스케줄링에서 준비 큐는 순환 큐로 처리되며, CPU 스케줄러는 준비 큐를 돌며 각 프로세스에 최대 1 타임 퀀텀의 CPU 시간을 순차적으로 할당합니다. 이 방식은 프로세스 간의 공정한 CPU 시간 분배를 보장하며, 대화형 시스템에서 높은 반응성을 제공합니다.
Round Robin 스케줄링의 주요 장점은 각 프로세스가 동일한 시간 동안 CPU를 사용할 수 있기 때문에, 모든 프로세스가 공정하게 처리될 수 있다는 점입니다. 그러나 타임 퀀텀의 크기 선택은 성능에 큰 영향을 미칠 수 있습니다. 타임 퀀텀을 너무 작게 설정하면 컨텍스트 스위칭으로 인한 오버헤드가 증가하고, 너무 크게 설정하면 RR 스케줄링이 사실상 FCFS 스케줄링과 유사해져 프로세스 대기 시간이 증가할 수 있습니다. 따라서 타임 퀀텀의 적절한 크기 설정이 중요합니다.
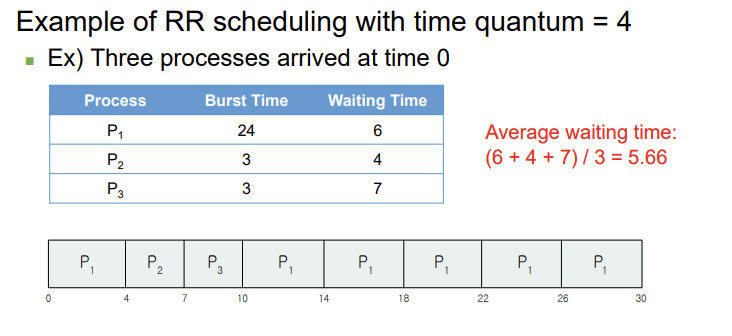
::> P1의 경우, 계속해서 Context switching이 진행되는 것!
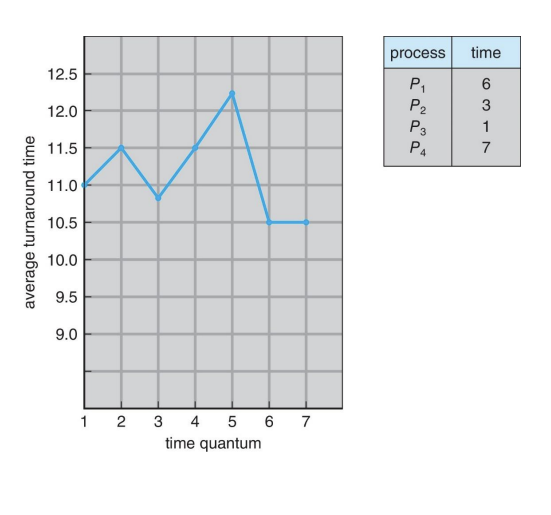
시간 할당량(타임 퀀텀)의 크기는 프로세스의 평균 반환 시간(Turnaround Time)에도 영향을 미칩니다. 평균 반환 시간은 시간 할당량의 크기에 비례하거나 반비례하는 관계가 아닙니다. 대부분의 프로세스가 다음 CPU 버스트를 단일 시간 할당량 내에 완료할 수 있으면 평균 반환 시간이 개선됩니다.
그러나, 너무 긴 시간 할당량은 바람직하지 않습니다. 긴 시간 할당량을 설정하면, 실질적으로 FCFS(First-Come, First-Served, 선입선출) 스케줄링과 유사해져서, 프로세스의 대기 시간이 증가할 수 있습니다. 또한, 시간 할당량이 너무 길면, 시스템의 반응성이 저하될 수 있습니다.
따라서, 시간 할당량의 크기를 결정할 때는 다음과 같은 경험적 규칙을 고려하는 것이 좋습니다: CPU 버스트의 약 80%가 시간 할당량보다 짧아야 합니다. 이 규칙은 시스템의 반응성과 효율성 사이의 균형을 유지하며, 대부분의 프로세스가 한 번의 CPU 할당으로 작업을 완료할 수 있도록 합니다. 이러한 접근 방식은 컨텍스트 스위칭 오버헤드를 최소화하고, 시스템의 전반적인 성능을 향상시킬 수 있습니다.
◼ Priority scheduling
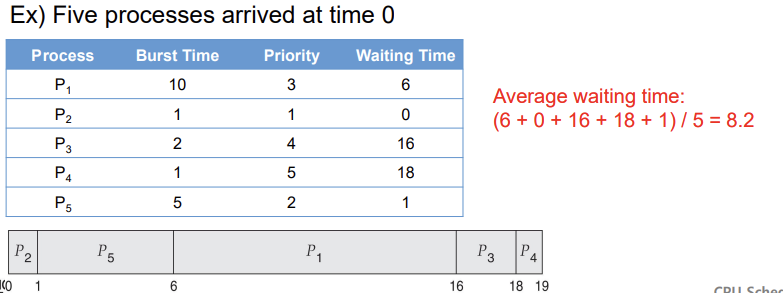
우선순위 스케줄링 알고리즘에서는 프로세스에 우선순위가 할당되고, CPU는 가장 높은 우선순위를 가진 프로세스에 할당됩니다. 만약 같은 우선순위를 가진 프로세스가 여러 개 있다면, 선입선출(FCFS, First-Come, First-Served) 원칙이 적용됩니다. 예를 들어, A, B, C, D, E 다섯 개의 프로세스가 있고, 각각의 우선순위가 2, 1, 4, 1, 3으로 주어졌다면, 우선순위 순서에 따라 B, D(같은 우선순위를 가진 경우 FCFS 원칙에 따름), A, E, C 순으로 CPU 스케줄링이 이루어집니다. 우선순위 스케줄링 메커니즘은 선점형일 수도 있고, 높은 우선순위의 프로세스가 낮은 우선순위의 프로세스를 중단시킬 수 있으며, 비선점형일 수도 있어, 현재 프로세스가 CPU 버스트를 완료할 때까지 다른 프로세스로 교체되지 않습니다.
우선순위 스케줄링에서는 각 프로세스에 우선순위가 부여됩니다. 이 우선순위는 내부적으로나 외부적으로 할당될 수 있습니다.
내부적으로: 프로세스에 할당된 우선순위는 측정 가능한 수량이나 특성에 의해 결정될 수 있습니다. 예를 들면, 시간 제한, 메모리 요구량, 열려 있는 파일의 수, I/O 버스트 대 CPU 버스트의 비율 등이 이에 해당합니다.
외부적으로: 프로세스의 중요도, 정치적 요인 등에 의해 우선순위가 결정될 수 있습니다.
우선순위 스케줄링은 선점형(Preemptive)이거나 비선점형(Non-preemptive)일 수 있습니다. 선점형 스케줄링에서는 더 높은 우선순위의 프로세스가 실행 중인 프로세스를 중단시킬 수 있으며, 비선점형에서는 현재 실행 중인 프로세스가 완료될 때까지 기다립니다.
우선순위 스케줄링의 주요 문제점 중 하나는 낮은 우선순위를 가진 프로세스가 무기한 차단(=기아 상태)될 수 있다는 것입니다. 이러한 문제를 해결하기 위한 한 가지 방법은 '에이징(Aging)'입니다. 에이징은 오랜 시간 동안 대기하는 프로세스의 우선순위를 점차적으로 증가시켜서, 결국 모든 프로세스가 어느 시점에서는 CPU 시간을 할당받을 수 있도록 하는 기법입니다. 이 방법을 통해 시스템은 공정성을 유지하며 모든 프로세스가 실행될 기회를 가질 수 있습니다.

◼ Multilevel queue scheduling
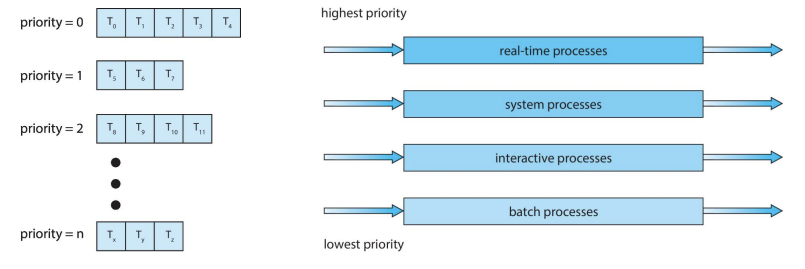
멀티레벨 큐 스케줄링은 프로세스를 여러 그룹으로 분류하고 각 그룹에 다른 스케줄링 알고리즘을 적용하는 방법입니다. 이 방식은 메모리 요구사항, 우선순위, 프로세스 유형 등에 따라 프로세스를 분류할 수 있습니다. 준비 큐는 여러 개의 별도 큐로 분할되며, 각 큐는 자체 스케줄링 알고리즘을 가집니다.
큐 간의 스케줄링은 다음과 같은 방식으로 이루어집니다:
고정 우선순위 선점 스케줄링: 더 높은 우선순위 큐의 프로세스가 모두 완료될 때까지 낮은 우선순위 큐의 프로세스는 실행되지 않습니다. 즉, 높은 우선순위 큐가 비어 있을 때만 낮은 우선순위 큐의 프로세스가 실행될 수 있습니다.
큐 간의 시간 할당: 각 큐에 CPU 시간의 일정 비율을 할당하여 실행합니다. 예를 들어, 전면 큐(대화형 프로세스)에는 CPU 시간의 80%를 라운드 로빈 방식으로 할당하고, 배경 큐(배치 프로세스)에는 남은 20%를 선입선출(FCFS) 방식으로 할당할 수 있습니다.
이러한 멀티레벨 큐 스케줄링 방식을 통해 다양한 유형의 프로세스 요구사항을 효과적으로 관리하고, 시스템의 효율성과 반응성을 높일 수 있습니다. 각 큐에 적합한 스케줄링 알고리즘을 적용함으로써, 시스템 전체의 성능 최적화를 도모할 수 있습니다.
◼ Multilevel Feedback-Queue Scheduling
: 기본은 multilevel queue scheduling이랑 동일. 하지만, feedback을 받아서 반영해줌. -> feedback이란 각 부분에서 처리 가능한 시간을 변경하는 것을 의미함.
다중 레벨 피드백 큐 스케줄링은 다중 레벨 큐 스케줄링과 유사하지만, 프로세스가 큐 사이를 이동할 수 있다는 점에서 차이가 있습니다. 이 방식의 주요 아이디어는 CPU 버스트의 특성에 따라 프로세스를 분류하는 것입니다.
프로세스가 너무 많은 CPU 시간을 사용하면, 낮은 우선순위 큐로 이동합니다.
I/O 바운드 및 인터랙티브 프로세스는 높은 우선순위 큐에 있습니다.
다중 레벨 피드백 큐의 예:
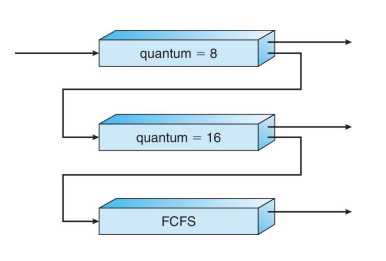
준비 큐는 세 개의 큐(Q0~Q2)로 구성됩니다.
Q0: 시간 할당량(time quantum)이 8밀리초인 RR(Round-Robin)
Q1: 시간 할당량이 16밀리초인 RR
Q2: FCFS(First-Come, First-Served)
새로운 프로세스는 Q0에 배치됩니다. 시간 제한을 초과하면 낮은 우선순위의 큐로 이동합니다.
다중 레벨 피드백-큐 스케줄러를 정의하는 데 필요한 매개변수:
1. 큐의 수
2. 각 큐에 대한 스케줄링 알고리즘
3. 프로세스를 더 높은 우선순위 큐로 승격시킬 때 결정하는 방법
4. 프로세스를 더 낮은 우선순위 큐로 강등시킬 때 결정하는 방법
5. 서비스가 필요할 때 프로세스가 어떤 큐에 들어갈지 결정하는 방법
이 스케줄링 알고리즘은 다른 스케줄링 방식보다 훨씬 복잡하지만, 시스템의 효율성과 반응성을 극대화하기 위해 다양한 유형의 프로세스 요구 사항을 더 잘 관리할 수 있습니다. 프로세스의 실행 특성에 따라 동적으로 우선순위를 조정함으로써, CPU 사용 시간이 많은 프로세스와 인터랙티브한 프로세스 모두에 효과적으로 대응할 수 있습니다.
◼ Thread Scheduling
쓰레드 스케줄링에 관하여, 현대 운영 체제들 대부분에서 스케줄링 되는 것은 프로세스가 아닌 커널 레벨 쓰레드입니다. 사용자 레벨 쓰레드는 쓰레드 라이브러리에 의해 관리되며, CPU에서 실행되기 위해서는 최종적으로 관련된 커널 레벨 쓰레드에 매핑되어야 합니다. 이 매핑은 간접적일 수 있으며, 가벼운 프로세스(Lightweight Process, LWP)를 사용할 수 있습니다.
커널 레벨 쓰레드
커널 레벨 쓰레드는 운영 체제에 의해 직접 관리됩니다. 이는 운영 체제가 모든 쓰레드 스케줄링 및 관리 작업을 담당한다는 것을 의미합니다. 따라서, 커널 레벨 쓰레드는 CPU 자원에 대한 더 나은 제어와 스케줄링을 가능하게 합니다.
사용자 레벨 쓰레드
사용자 레벨 쓰레드는 커널이 직접 관리하지 않고, 쓰레드 라이브러리(예: POSIX 쓰레드)에 의해 관리됩니다. 사용자 레벨 쓰레드는 운영 체제의 커널보다 상위 레벨에서 실행되며, 커널은 이러한 쓰레드의 존재를 인식하지 못할 수도 있습니다. 커널로부터 독립적으로 스케줄링되고 관리되기 때문에, 생성 및 전환 비용이 낮습니다.
LWP(Lightweight Process)
: 사용자 기반 thread가 커널 레벨 thread를 사용하고자 그 중간 다리 역할을 하는 것!
"LWP는 사용자 레벨 쓰레드와 커널 레벨 쓰레드 사이의 중간자 역할을 합니다." 사용자 레벨 쓰레드가 실제로 CPU 자원을 사용하기 위해서는 LWP를 통해 커널 레벨 쓰레드에 연결되어야 합니다. LWP는 커널에 의해 스케줄링되는 동시에, 여러 사용자 레벨 쓰레드를 하나의 LWP에 매핑할 수 있어 유연성을 제공합니다.
이러한 구조는 사용자 레벨 쓰레드와 커널 레벨 쓰레드 간의 효율적인 협력 및 관리를 가능하게 하여, 다양한 어플리케이션 요구 사항에 맞춰 최적의 성능을 발휘할 수 있도록 돕습니다.
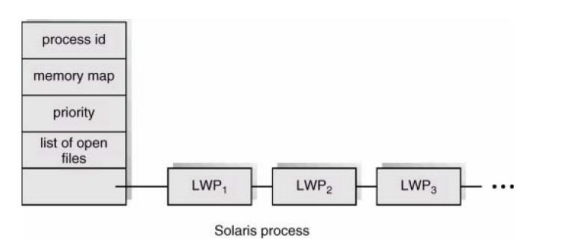
컨텐션 스코프(Contention Scope)는 운영 체제에서 스레딩 및 스케줄링과 관련하여 리소스를 위해 스레드가 경쟁하는 도메인을 의미합니다. 이는 크게 두 가지 주요 카테고리로 나뉩니다: 프로세스-컨텐션 스코프(PCS)와 시스템-컨텐션 스코프(SCS).
PCS는 단일 프로세스의 맥락에서 사용자 스레드들이 경량 프로세스(LWP)를 위해 경쟁하는 것을 말합니다. 이 경쟁은 두 가지 모델 하에서 발생할 수 있습니다: 많은-하나 모델(Many-to-One Model) 및 많은-많은 모델(Many-to-Many Model). 스레드의 우선순위는 프로그래머에 의해 설정되며, 어떤 스레드가 LWP에 접근하는지 결정하는 데 중요한 역할을 합니다.
한편, SCS는 시스템 전체의 모든 프로세스에 걸쳐 커널 레벨 스레드들이 CPU 리소스를 위해 경쟁하는 것을 말합니다. 운영 체제의 스케줄러는 우선순위, 공정성, 특정 스케줄링 알고리즘과 같은 요소를 기반으로 어떤 커널 스레드가 CPU 시간을 부여받는지 결정합니다.
PCS (Process Contention Scope): PCS는 단일 프로세스 안에서 발생하는 스레드 간의 경쟁을 의미합니다. 즉, 하나의 프로그램(프로세스) 내의 여러 스레드가 제한된 수의 LWP(Lightweight Process) 자원을 얻기 위해 경쟁합니다. 이 때문에 같은 프로세스 내의 스레드들이 LWP를 차지하기 위해 서로 경쟁하게 됩니다. 이 경쟁에서 스레드의 우선순위나 다른 기준에 따라 LWP가 할당됩니다.
SCS (System Contention Scope): SCS는 시스템 전체, 즉 여러 프로세스에 걸쳐 있는 커널 스레드들이 CPU와 같은 시스템 자원을 얻기 위해 발생하는 경쟁을 의미합니다. 이는 PCS보다 더 넓은 범위에서 발생하는 경쟁으로, 전체 시스템의 자원을 여러 프로세스의 스레드가 공유하기 때문에 발생합니다.
LWP(경량 프로세스) 자원을 얻게 되면, 그것은 사용자 수준의 스레드가 실제로 CPU에서 실행될 수 있게 해주는 열쇠와 같습니다. LWP는 사용자 수준의 스레드와 커널 수준의 스레드 사이의 일종의 다리 역할을 하며, 실제 하드웨어 자원에 접근할 수 있게 해줍니다. 즉, LWP를 얻는 것은 스레드가 작업을 수행하고 실제로 CPU 시간을 사용하여 코드를 실행할 수 있게 되는 것을 의미합니다.
스레드가 LWP 자원을 확보하면 다음과 같은 일들이 발생합니다:
실행 가능성: 스레드가 CPU에서 실행될 수 있게 되어, 프로그램의 명령을 처리할 수 있습니다.
성능 향상: 여러 스레드가 동시에 또는 병렬로 실행될 수 있게 되어, 작업 처리 속도가 빨라집니다. 특히 복잡하거나 계산이 많은 작업을 수행할 때, 이는 큰 성능 향상을 의미할 수 있습니다.
자원 활용도 증가: LWP를 통해 여러 스레드가 CPU 시간을 공유하면서, 시스템 자원을 보다 효율적으로 사용할 수 있게 됩니다.
LWP 자원에 대한 경쟁이 발생하는 이유는, 이러한 자원이 한정되어 있기 때문입니다. 시스템에는 동시에 실행할 수 있는 LWP의 수가 제한되어 있으며, 이는 동시에 실행할 수 있는 스레드의 수에도 영향을 미칩니다. 따라서, 여러 스레드가 동시에 LWP를 요구할 때, 우선순위나 다른 기준에 따라 자원을 할당받게 됩니다. 이 과정에서 스레드 간의 경쟁이 발생하게 되는 것입니다.
간단 정리 : PCS 는 하나의 process가 기반이고, SCS은 system, 즉 여러 개의 process 기반이라는 거지? 그리고 그 process가 LWP 를 차지하기 위해 서로가 경쟁하는 거!
세부 설명!!
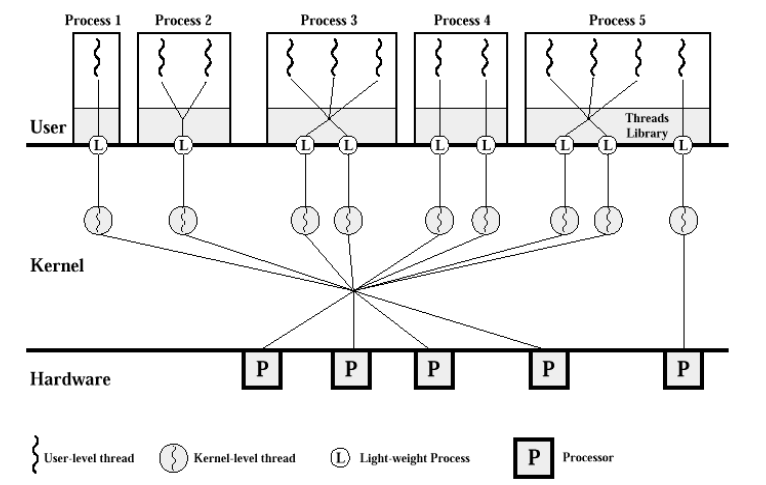
◼ Multiple-Processor Scheduling
멀티프로세서 스케줄링은 여러 CPU가 사용 가능할 때 CPU 스케줄링이 더 복잡해집니다. 멀티프로세서 스케줄링에 대한 많은 시도가 있었으나 일반적으로 최고의 해결책은 존재하지 않습니다. 멀티프로세싱은 다음과 같은 여러 구조 중 하나일 수 있습니다:
멀티코어 CPU
멀티코어 CPU는 단일 컴퓨팅 구성 요소(칩)에 두 개 이상의 처리 단위(코어)를 가지고 있습니다. 이 코어들은 동시에 다양한 작업을 처리할 수 있어 처리 능력이 크게 향상됩니다. 각 코어는 별도의 작업을 동시에 실행할 수 있으며, 이는 병렬 처리를 통해 전체 시스템의 효율성을 높입니다.
멀티스레드 코어
일부 CPU는 멀티스레딩을 지원하여 단일 코어가 동시에 여러 스레드를 실행할 수 있습니다. 이는 하드웨어 수준에서의 멀티태스킹을 가능하게 하며, CPU의 자원을 보다 효율적으로 사용할 수 있게 합니다. 멀티스레딩은 코어의 다운타임을 줄이고, 전반적인 처리량을 개선합니다.
NUMA 시스템
NUMA(Non-Uniform Memory Access) 시스템은 멀티프로세서 컴퓨터 구조에서 메모리에 접근하는 시간이 메모리의 위치에 따라 달라지는 설계를 말합니다. 각 프로세서는 자신의 로컬 메모리를 가지며, 다른 프로세서의 메모리에 접근할 수 있지만, 로컬 메모리에 접근하는 것보다 시간이 더 걸립니다. 이는 메모리 접근 시간을 최적화하여 성능을 개선할 수 있는 방법을 제공합니다.
Heterogeneous multiprocessing (이기종 멀티프로세싱)
이기종 멀티프로세싱은 서로 다른 유형의 프로세서가 함께 작동하는 시스템을 말합니다. 이러한 시스템은 특정 작업에 최적화된 프로세서를 사용하여 효율성을 높일 수 있습니다. 예를 들어, 일부 계산은 전통적인 CPU에서 수행되는 동안, 다른 작업은 그래픽 처리를 위해 GPU에서 수행될 수 있습니다.
각각의 멀티프로세싱 아키텍처는 특정 작업과 환경에 따라 장단점을 가지고 있으며, 최적의 성능을 얻기 위해서는 시스템의 특성과 요구 사항을 잘 이해하고 적절한 스케줄링 전략을 선택해야 합니다.
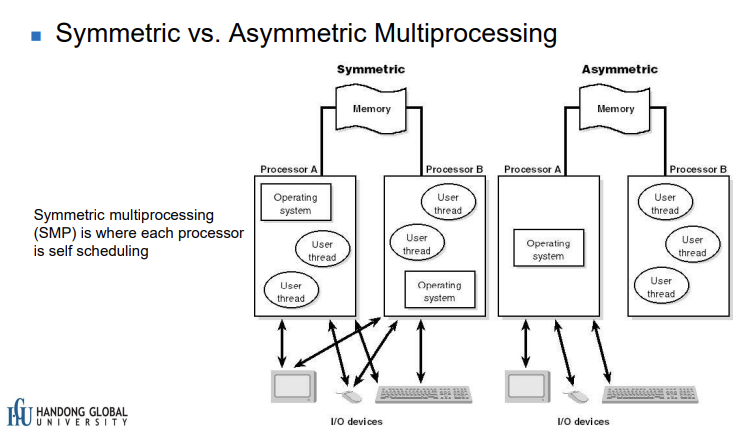
대칭형 멀티프로세싱 (Symmetric Multiprocessing, SMP)
정의: 모든 프로세서가 동등한 역할을 수행하고, 모든 프로세서가 메모리와 I/O와 같은 시스템 자원에 동일한 접근 권한을 가지는 구조입니다.
작업 분담: 운영 체제는 작업을 동등하게 프로세서들 사이에 분배하여, 모든 프로세서가 비슷한 작업량을 가지도록 합니다.
장점: 프로그래밍이 비교적 단순하고, 시스템의 확장성이 용이합니다. 프로세서 중 하나가 실패해도, 다른 프로세서가 그 작업을 인계받아 계속 처리할 수 있어 높은 가용성을 제공합니다.
단점: 모든 프로세서가 동일한 메모리와 I/O 자원을 공유하기 때문에, 자원 접근 시 경쟁이 발생할 수 있으며, 이로 인한 병목 현상이 시스템 성능에 영향을 줄 수 있습니다.
비대칭형 멀티프로세싱 (Asymmetric Multiprocessing, AMP)
정의: 한 프로세서(주 프로세서)가 시스템 관리와 같은 주요 작업을 담당하고, 나머지 프로세서들은 지정된 작업만을 수행하는 구조입니다.
작업 분담: 주 프로세서가 시스템의 전반적인 관리와 스케줄링을 담당하며, 다른 프로세서들은 특정 작업이 할당되어 그 작업만을 처리합니다.
장점: 주 프로세서가 시스템 관리를 담당하기 때문에, 시스템의 관리와 구성이 비교적 단순합니다. 특수 목적의 작업 처리에 효율적일 수 있습니다.
단점: 주 프로세서에 과부하가 발생할 가능성이 있고, 시스템의 확장성이 제한적입니다. 또한, 주 프로세서에 문제가 발생하면 전체 시스템에 영향을 줄 수 있습니다.
종합적으로, SMP는 균형 잡힌 작업 분담과 확장성을 제공하는 반면, AMP는 특정 작업을 효율적으로 처리할 수 있는 구조를 제공합니다. 시스템의 요구사항에 따라 적합한 멀티프로세싱 방식을 선택하는 것이 중요합니다.
Multi-Processor Scheduling
스레드 스케줄링에 있어서 두 가지 가능한 전략은 다음과 같습니다:
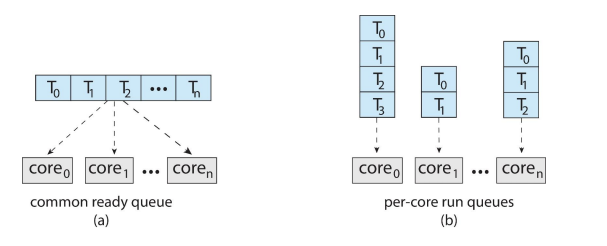
쉬운 설명
1. 첫 번째 방법은 모든 일들, 즉 스레드들을 하나의 큰 줄로 세우는 거야. 여기서 중요한 건, 두 개의 프로세서가 같은 일을 동시에 하려고 하지 않도록 조심해야 해. 그리고 줄에서 일이 빠지지 않도록 잘 살펴봐야 한단다.
2. 두 번째 방법은 각 프로세서마다 자기만의 작은 줄을 가지고 있는 거야. 이렇게 하면 각각의 프로세서가 자기 줄에 있는 일들을 차례대로 할 수 있어. 이 방법은 프로세서마다 어떤 일을 할지 더 쉽게 정할 수 있게 해줘.
공통 준비 큐 사용:
모든 스레드가 하나의 공통 준비 큐에 위치합니다.
이 방법은 스레드 스케줄링 시스템이 두 개 이상의 프로세서가 동시에 동일한 스레드를 선택하지 않도록 보장해야 합니다. 또한, 준비 큐에서 스레드가 손실되지 않도록 관리해야 합니다. 이를 위해, 공통 준비 큐 접근 시 동기화 메커니즘이 필요합니다 (예: 락(lock)을 사용하여 큐 접근을 제어).
장점으로는, 모든 스레드가 동일한 대기열에 있으므로 프로세서 간의 작업 부하를 비교적 쉽게 균형있게 조정할 수 있습니다.
단점으로는, 큐에 대한 동시 접근을 관리하기 위한 동기화로 인해 오버헤드가 발생할 수 있습니다.
프로세서별 개인 큐 사용:
각 프로세서는 자신만의 개인 스레드 준비 큐를 가지고 있습니다.
이 방법은 각 프로세서가 자신의 큐에서 독립적으로 스레드를 선택하고 스케줄링할 수 있기 때문에, 공통 준비 큐에 비해 동기화에 대한 필요성이 크게 줄어듭니다.
장점으로는, 동기화로 인한 오버헤드가 감소하며, 각 프로세서가 자신의 큐를 관리함으로써 더 빠른 응답 시간을 제공할 수 있습니다.
단점으로는, 각 프로세서의 작업 부하 균형을 맞추는 것이 더 어려워질 수 있으며, 특정 프로세서가 과부하 상태인 반면 다른 프로세서는 유휴 상태일 수 있습니다.
각 전략은 장단점이 있으며, 시스템의 특정 요구 사항과 성능 목표에 따라 적합한 전략을 선택해야 합니다. 공통 준비 큐는 작업 부하 균형에 유리하지만 동기화 오버헤드가 있으며, 개인 큐는 동기화 오버헤드가 적지만 작업 부하 균형을 맞추는 데 더 많은 노력이 필요할 수 있습니다.
Multicore Processors
멀티코어 프로세서는 단일 물리 칩에 여러 프로세서 코어가 있는 현대 컴퓨팅 시스템의 일반적인 특징입니다. 이러한 시스템은 각 프로세서가 자체 물리 칩을 가진 시스템보다 빠르고 전력 소비가 적은 것으로 알려져 있습니다. 멀티코어 프로세서의 등장은 컴퓨팅 성능을 향상시키는 주요 방법 중 하나이며, 이는 단일 코어 프로세서의 클록 속도를 증가시키는 것보다 효율적입니다.
멀티코어 프로세서에서의 스케줄링 이슈는 다음과 같습니다:
메모리 스톨(Memory Stall): 멀티코어 프로세서에서는 메모리 접근이 데이터가 사용 가능해질 때까지 상당한 시간을 대기해야 하는 경우가 많습니다. 이러한 메모리 스톨은 캐시 미스(Cache Miss), 버스 대역폭 부족, 메모리 병목 현상 등 다양한 이유로 발생할 수 있습니다. 메모리 스톨은 프로세서의 성능을 크게 저하시킬 수 있기 때문에, 이를 최소화하기 위한 메모리 최적화 기술이 중요합니다.
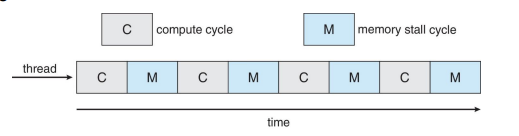
multicore processor의 memory stall 같은 문제를 해결하기 위한 수단(remedy) : multithreaded processor cores
Multithreaded Multicore System
멀티코어 시스템에서는 여러 개의 프로세서 코어가 하나의 칩에 있어서 여러 작업을 동시에 처리할 수 있어요. 그런데 이렇게 여러 작업을 동시에 처리할 때, 일정을 잡는 것(스케줄링)이 어려울 수 있어요. 특히, 메모리에 접근할 때 데이터를 기다리는 시간(메모리 스톨)이 문제가 될 수 있죠.
이런 문제를 해결하기 위한 방법 중 하나가 multithreaded processor cores
를 사용하는 거예요. 이는 각 코어에 두 개 이상의 하드웨어 스레드를 할당하는 것인데, 만약 한 스레드가 메모리 스톨 때문에 멈추면, 다른 스레드로 바꿔서 작업을 계속할 수 있어요.
말 그대로 processor core를 여러개 multithreaded화 시키는 거구나~
그리고 이걸 core를 여러개로 분산한다 해서 chip(core) multi theading (CMT)이라 하는구나~
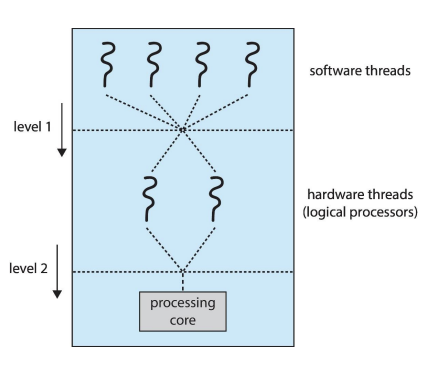
이 기술을 칩 멀티스레딩(CMT)라고 하고, 인텔에서는 이를 하이퍼스레딩(또는 동시 멀티스레딩, SMT)이라고 불러요. 이 방법에는 대략적인 멀티스레딩과 세밀한 멀티스레딩이 있어요. 예를 들어, 하드웨어 스레드가 코어당 2개인 4코어 시스템에서는 운영 시스템이 8개의 논리 프로세서로 보게 돼요.
이런 시스템에서는 스케줄링을 두 가지 수준에서 고려해야 해요. 첫 번째 수준은 운영 시스템이 어떤 소프트웨어 스레드를 논리 CPU에서 실행할지 결정하는 거예요. 두 번째 수준은 각 코어가 물리적인 코어에서 어떤 하드웨어 스레드를 실행할지 결정하는 거죠. 이렇게 두 가지 수준의 스케줄링을 통해 멀티스레드 멀티코어 시스템은 효율적으로 작업을 처리할 수 있어요.
레벨 1: 운영체제가 어떤 소프트웨어 스레드를 논리 CPU(컴퓨터가 처리할 수 있는 가상의 처리 단위)에서 실행할지 결정합니다. 이것은 마치 여러분이 어떤 일을 먼저 할지 결정하는 것과 비슷합니다. 여러분이 할 수 있는 일들(소프트웨어 스레드) 중에서, 어떤 것을 지금 당장 시작할지(논리 CPU에서 실행할지) 운영체제가 결정합니다.
레벨 2: 각각의 코어가 물리 코어(실제로 일을 처리하는 하드웨어의 부분)에서 어떤 하드웨어 스레드를 실행할지 결정합니다. 이것은 여러분이 어떤 도구를 사용하여 일을 할지 결정하는 것과 비슷합니다. 여러분이 사용할 수 있는 여러 도구(하드웨어 스레드) 중에서, 어떤 도구로 작업을 수행할지 각 코어가 결정합니다.
간단히 말해서, 레벨 1은 '어떤 일을 할지', 레벨 2는 '어떤 도구를 사용할지' 결정하는 과정이라고 생각하시면 됩니다.
Load balancing
로드 밸런싱(load balancing)은 모든 프로세서 간에 작업 부하를 고르게 분배하려는 시도입니다. 각 프로세서가 자체 준비 큐를 가지고 있는 시스템에서 필수적이며, 대부분의 현대 운영 시스템에서 이는 사실입니다. 로드 밸런싱은 시스템의 효율성을 높이고, 자원 사용을 최적화하며, 전체적인 시스템 성능을 개선하기 위해 중요합니다.
로드 밸런싱을 구현하기 위한 두 가지 일반적인 접근 방식이 있습니다:
푸시 마이그레이션(Push Migration):
주기적으로 각 프로세서의 부하를 확인하는 작업이 있습니다.
불균형이 발견되면, 과부하된 CPU에서 다른 CPU로 작업을 밀어냅니다.
이 방식은 시스템이 능동적으로 부하 불균형을 감지하고 해결하려고 시도합니다.
풀 마이그레이션(Pull Migration):
유휴 프로세서가 바쁜 프로세서에서 대기 중인 작업을 끌어옵니다.
이 방식은 유휴 상태의 프로세서가 능동적으로 작업을 찾아서 처리합니다.
푸시 마이그레이션과 풀 마이그레이션은 병렬로 구현될 수 있습니다. 이는 시스템이 동시에 두 가지 전략을 사용하여 부하 균형을 조정할 수 있다는 것을 의미합니다.
예를 들어, Linux의 Completely Fair Scheduler(CFS)와 FreeBSD의 ULE 스케줄러는 현대적인 로드 밸런싱 기법을 활용하여 프로세서 간에 작업 부하를 효율적으로 분배합니다. CFS는 각 작업에 공평한 CPU 시간을 할당하려고 하며, ULE 스케줄러는 시스템의 전반적인 성능을 최적화하도록 설계되었습니다. 이러한 스케줄러는 로드 밸런싱의 원리를 활용하여 시스템 자원을 효율적으로 관리하고, 시스템의 응답성과 처리량을 개선합니다.
프로세서 친화도(Processor Affinity)는 프로세스를 한 프로세서에서 다른 프로세서로 이동하는 것에 따른 오버헤드를 최소화하기 위한 기술입니다. 프로세스가 이동할 때마다 캐시의 모든 내용을 무효화하고 재구성해야 하므로, 프로세서 친화도는 프로세스를 가능한 한 동일한 프로세서에서 계속 실행함으로써 이러한 이동 오버헤드를 피하려고 합니다.
소프트 친화도(Soft Affinity): 운영 체제는 프로세스를 가능한 한 동일한 프로세서에서 계속 실행하려고 시도하지만, 필요에 따라 프로세스가 프로세서 간에 이동할 수 있습니다.
하드 친화도(Hard Affinity): 특정 프로세스를 다른 프로세서로 이동하는 것을 방지하여, 프로세스가 특정 프로세서에 고정되도록 할 수 있습니다.
NUMA(Non-Uniform Memory Access)는 다중 프로세서 컴퓨터 시스템에서 메모리 액세스 시간이 모든 프로세서에 대해 균일하지 않은 아키텍처를 설명합니다. 즉, 프로세서는 메인 메모리의 특정 부분에 대해 다른 부분보다 더 빠른 액세스를 가집니다. 이는 프로세서가 자신에게 더 가까운 메모리에 더 빠르게 접근할 수 있음을 의미합니다.
NUMA 아키텍처에서 CPU 스케줄링은 프로세스가 메모리 액세스 시간에 영향을 받지 않도록 관리하는 것이 중요합니다. 이를 위해 프로세서 친화도와 같은 기술을 사용하여 프로세스를 가능한 한 그들이 더 빠르게 접근할 수 있는 메모리에 가까운 프로세서에서 실행하도록 합니다. 이는 시스템의 전반적인 성능을 최적화하고 메모리 액세스 지연을 최소화하는 데 도움이 됩니다.
◼ Real-Time CPU Scheduling
◼ Operating System Example
