비지도 학습 모델(Unsuperviesd)
- 정답이 없는 문제를 푼다
- 스스로 문제를 만들어 문제해결
군집화 모델(Clustering)
K-means clustering
- 알고리즘에 더 가까움
- 학습 단계가 없는 것으로 보임
- 단계를 순차적으로 반복하면서 판별
- 백터 데이터 베이스 알고리즘에 사용
초기화> k개의 군집 중심 랜덤하게 설정 = 몇개로 묶을 것인가
할당 단계> 각 데이터 포인트를 가까운 군집 중심에 할당
업데이트 단계> 각 군집의 중심을 속한 데이터 포인트들의 평균으로 업데이트
반복>
최종적> 데이터들이 k개로 분류 완료- 군집 중심 - 데이터
- 거리측정
- 유클리드 거리-일반적인 거리 측정 방식 (0.0) (10.0) = 10
- 엘보우 방법 - 최적의 k 선택
>k를 증가 시키면서 응집도(관성 inertia)를 계산
>더 이상 의미있게 감소하지 않는 구간 = elbow 포인트로 간주- 모듈 import, 데이터 표준화
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler # 표준화
data = pd.read_csv('/Users/사용자이름/myenv/studynote/kaggle/Mall_Customers.csv')
# 거리를 구하는 것에 의미 있는 데이터만 남김(숫자)
data = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
# 데이터 스케일링
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)- 군집화
# 클러스터링 작업
from sklearn.cluster import KMeans # kmeans
# k값을 증가시켜 가면서 inertia 값을 추출
inertia = []
K = range(1, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state = 42)
kmeans.fit(data_scaled)
inertia.append(kmeans.inertia_)- 시각화
# 시각화
import matplotlib.pyplot as plt # 시각화 도구
import seaborn as sns # 시각화 도구
plt.figure(figsize=(10, 8))
plt.plot(K, inertia, 'bx-') #"bx-" 는 스타일 https://guebin.github.io/DV2023/posts/01wk-2.html
plt.xlabel('k') # x축 이름
plt.ylabel('Inertia') # y축 이름
plt.title('Elbow Method For Optimal k') # 제목
plt.show() # 시각화 후 엘보 포인트 정하기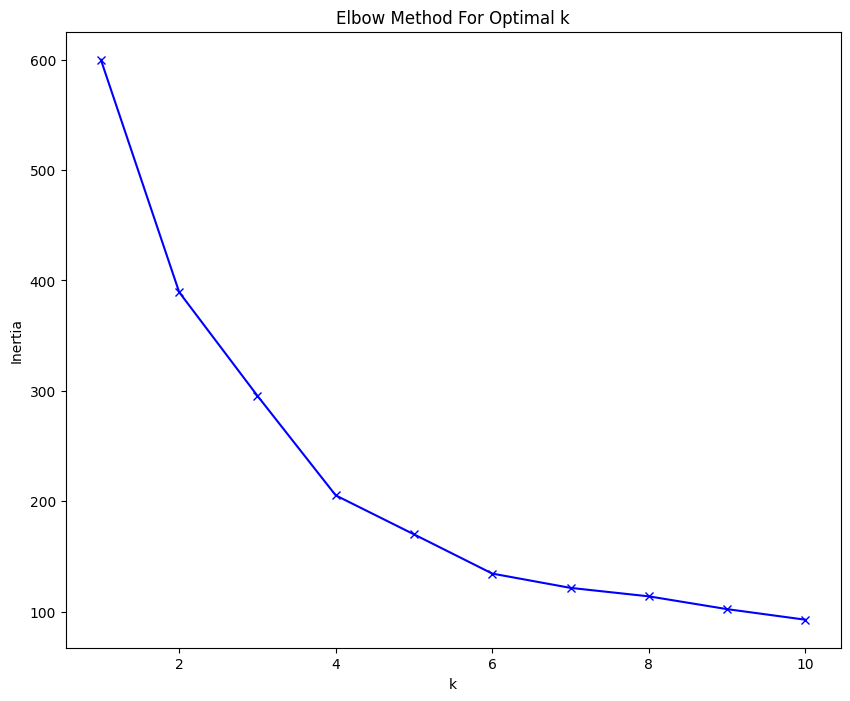
- 모델 생성(elbow point를 k값으로)
# 모델 생성
# 엘보 포인트를 k값으로 모델 생성 및 학습
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(data_scaled)
# 군집 결과 할당 # 각 데이터 포인트가 속한 군집 레이블을 반환
data['Cluster'] = kmeans.labels_- 군집 시각화
# 군집 시각화
# 2차원으로 군집 시각화 (연령 vs 소득)
# hue(색조)=data : 해당 데이터에 따라 색을 다르게 하라
# palette : 색 옵션
plt.figure(figsize=(10, 8))
sns.scatterplot(x=data['Age'], y=data['Annual Income (k$)'], hue=data['Cluster'], palette='viridis')
plt.title('Clusters of customers (Age vs Annual Income)')
plt.show()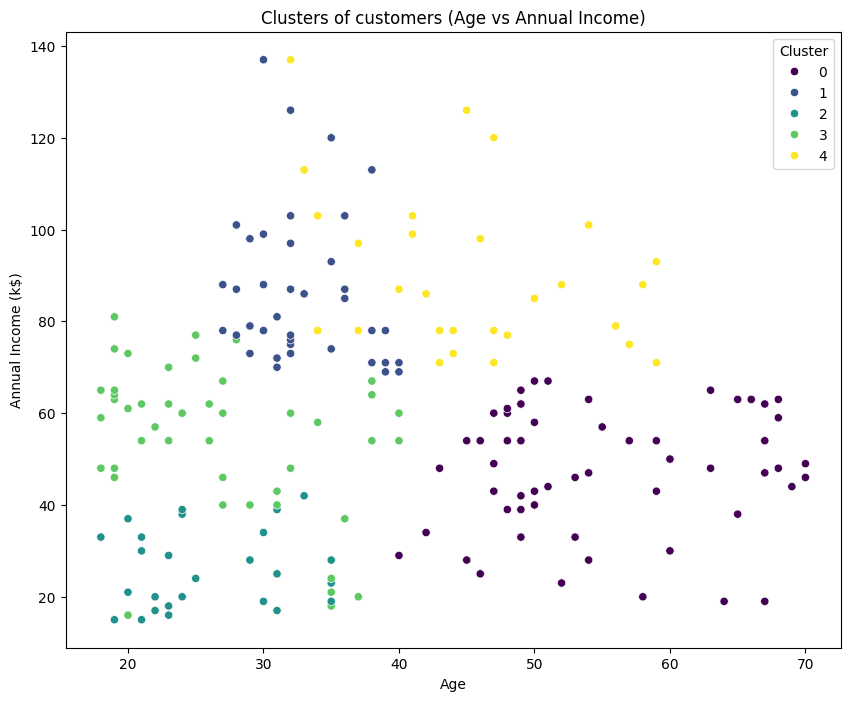
Hierarchical Clustering
- 계층적 군집화
- 데이터포인트를 계층 구조로 그룹화
- 점진적으로 병합하거나 분할하여 군집 형성
- 덴드로그램 생성 : 시각화
- 병합
- 개별 군집으로 시작, 가까운 군집을 병합(agglomerative)
- 단순성: 구현이 비교적 간단
- 계산 비용: 데이터 포인트 수가 많아질 수록 비용 증가- 분할
- 가장 멀리 떨어진 군집 분할(divisive)
- 상대적으로 복잡
- 효율성- 덴드로그램
- linkage :연결법
- ward: ward 연결법 ; 오차 제곱합의 증가분 기반 https://rfriend.tistory.com/227
X = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
import scipy.cluster.hierarchy as sch # 덴드로그램
plt.figure(figsize=(10, 7))
dendrogram = sch.dendrogram(sch.linkage(X_scaled, method='ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distances')
plt.show()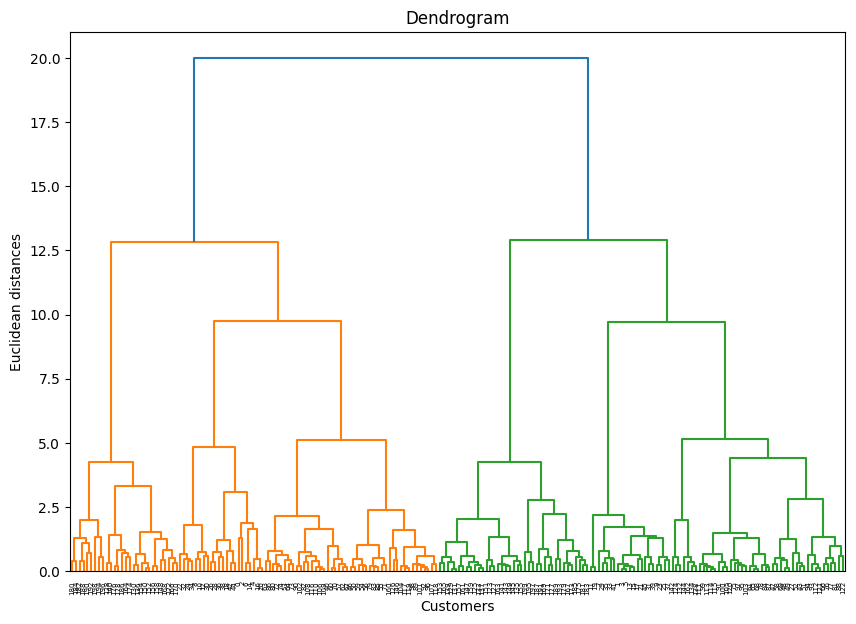
- 계층적 군집화 모델 생성
from sklearn.cluster import AgglomerativeClustering # 병합 군집
hc = AgglomerativeClustering(n_clusters=5, metric='euclidean', linkage='ward')
# 모델 학습 및 예측
y_hc = hc.fit_predict(X_scaled)
# 결과 시각화
plt.figure(figsize=(10, 7))
plt.scatter(X_scaled[y_hc == 0, 0], X_scaled[y_hc == 0, 1], s=100, c='red', label='Cluster 1')
plt.scatter(X_scaled[y_hc == 1, 0], X_scaled[y_hc == 1, 1], s=100, c='blue', label='Cluster 2')
plt.scatter(X_scaled[y_hc == 2, 0], X_scaled[y_hc == 2, 1], s=100, c='green', label='Cluster 3')
plt.scatter(X_scaled[y_hc == 3, 0], X_scaled[y_hc == 3, 1], s=100, c='cyan', label='Cluster 4')
plt.scatter(X_scaled[y_hc == 4, 0], X_scaled[y_hc == 4, 1], s=100, c='magenta', label='Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Age')
plt.ylabel('Annual Income (k$)')
plt.legend()
plt.show()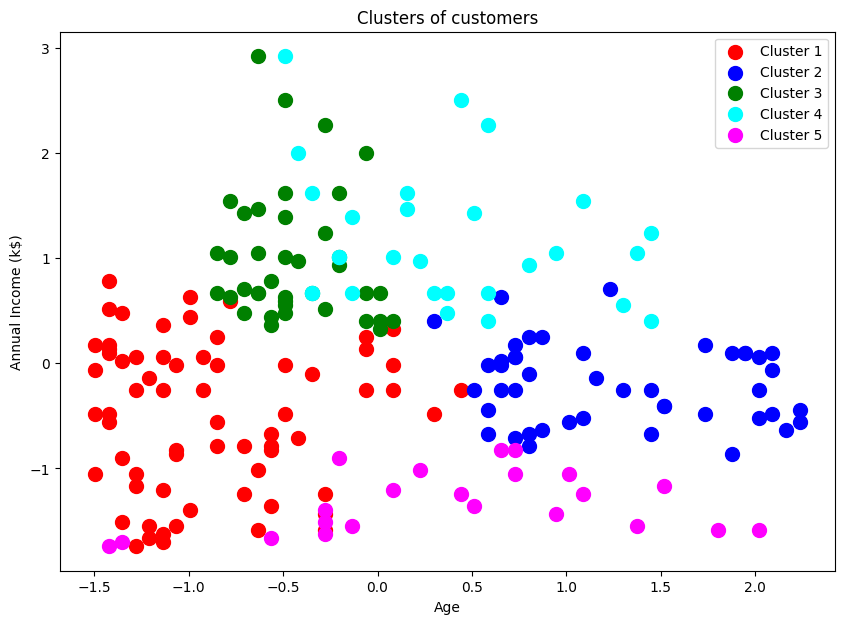
- 평가(silhouette_score)
- 실루엣 점수 계산 (-1 ~ 1)
from sklearn.metrics import silhouette_score
# 실루엣 점수 계산 (-1 ~ 1)
silhouette_avg = silhouette_score(X_scaled, y_hc)
print(f'Silhouette Score: {silhouette_avg}')
#
Silhouette Score: 0.39002826186267214
DBSCAN
Density-Based Spatial Clustering of Applications with Noise
- 밀도 기반 - 밀도가 높으면 군집, 낮으면 노이즈로 처리 - 반복
- 비구형 군집 탐지 / 군집 수 자동 결정 / 노이즈 처리
eps(입실론): 같은 군집이 되기 위한 최대 거리
min_smaples: 한 군집 형성에 필요한 최소 데이터 포인트 수- 모델 생성, 시각화
from sklearn.cluster import DBSCAN
# DBSCAN 모델 생성
dbscan = DBSCAN(eps=5, min_samples=5)
# 모델 학습 및 예측
data['Cluster'] = dbscan.fit_predict(X)
# 군집화 결과 시각화
plt.figure(figsize=(10, 7))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Cluster', data=data, palette='viridis')
plt.title('DBSCAN Clustering of Mall Customers')
plt.show()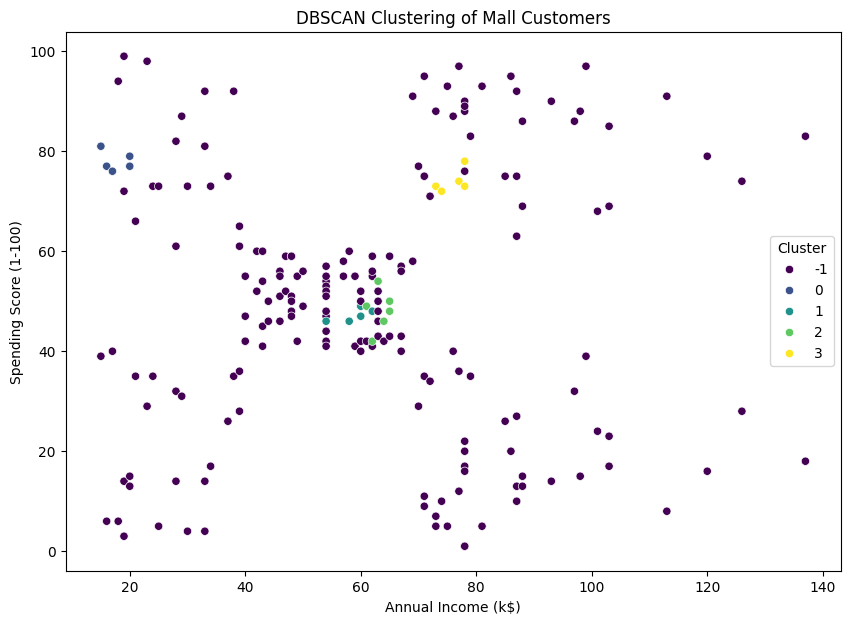
- 다양한 eps, min_sample값 시도
eps_values = [3, 5, 7, 10]
min_samples_values = [3, 5, 7, 10]
for eps in eps_values:
for min_samples in min_samples_values:
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
data['Cluster'] = dbscan.fit_predict(X)
plt.figure(figsize=(10, 7))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Cluster', data=data, palette='viridis')
plt.title(f'DBSCAN Clustering (eps={eps}, min_samples={min_samples})')
plt.show()차원축소 모델(Dimension Reduction)
PCA
Principal Component Analysis, 주성분 분석
- 차원 : 데이터 열의 개수
- 데이터 중심화 : 평균을 0으로
- 공분산 행렬 : 얼마나 같이 움직이는지
- 고유값, 고유 백터 : 분산 정도, 그 방향
- 주성분 선택 : 고유값 큰 순서, 새로운 좌표
- 주성분을 축으로 차원 축소
일반적으로 데이터를 95% 이상 설명하면 선택
예시)
데이터 : 성적
데이터 중심화 : 각 성적에서 평균을 뺴서 평균을 0으로
공분산 : 성적간의 관계 분석 - 국어 점수가 높으면 사회 점수가 높다
주성분 선택 : 국영수를 기준으로 했을 떄 성적 변화가 큼(선택)
음미체를 기준으로 했을 때 변화 적음(무시)- 데이터 셋 불러오기, 표준화
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_openml
# MNIST 데이터셋 불러오기
mnist = fetch_openml('mnist_784', version=1)
# 데이터와 레이블 분리
X = mnist.data
y = mnist.target
# 데이터 프레임의 첫 5행 출력
print(X.head())
print(y.head())
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)- 모델 생성, 학습
from sklearn.decomposition import PCA
# PCA 모델 생성
pca = PCA(n_components=0.95) # 전체 분산의 95%를 설명하는 주성분 선택
# PCA 학습 및 변환
X_pca = pca.fit_transform(X_scaled)# 선택된 주성분의 : 332
print(f'선택된 주성분의 수: {pca.n_components_}')
# 각 주성분이 설명하는 분산 비율
print(f'각 주성분이 설명하는 분산 비율: {pca.explained_variance_ratio_}')
# 누적 분산 비율 #cumsum 누적합
print(f'누적 분산 비율: {pca.explained_variance_ratio_.cumsum()}')- 시각화
# 2차원 시각화 # legend 범례
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 7))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=y, palette='viridis', legend=None)
plt.title('PCA of MNIST Dataset (2D)')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()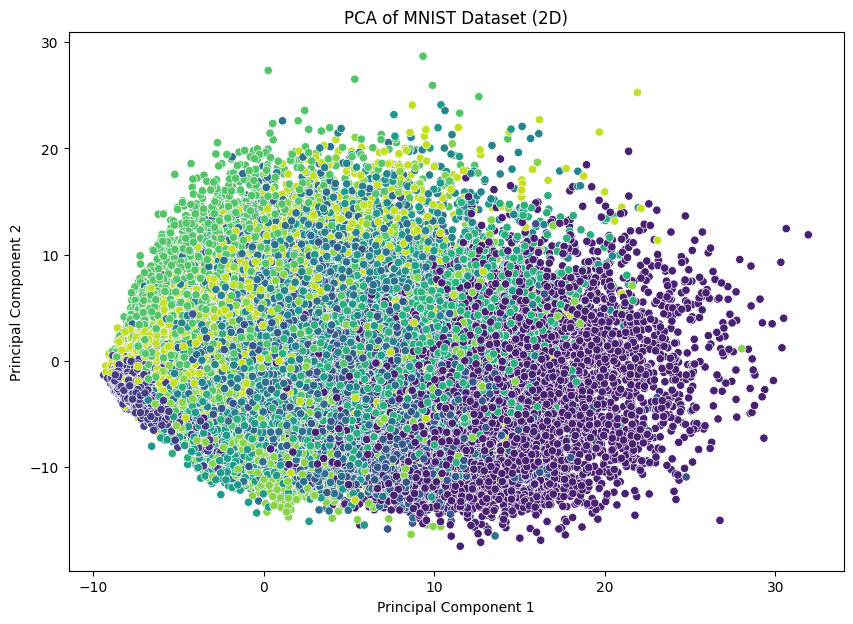
t-SNE
t-Distributed Stochastic Neighbor Embedding
- 유사성 기반 - 2차원 또는 3차원으로 변환
- 데이터 구조와 패턴을 시각적으로 이해 가능
- 고차원에서의 관계가 저차원에서도 유지되도록 데이터 변환
- 비선형 구조 탐지
- 클러스터 시각화
- 고차원 데이터 시각화
고차원 유사성 계산 -> 저차원 유사성 계산 -> 고차원과 저차원 유사성 계산고차원 데이터 - 확률 분포
저차원 데이터 - t-분포
고차원과 저차원 - KL 발산(Kullback-Leibler divergence) 최소화
(경사하강법) - 분산이 떨어진 정도
반복 - 최적화- 모델 생성, 학습
# 진짜 오래걸림
from sklearn.manifold import TSNE
# t-SNE 모델 생성
tsne = TSNE(n_components=2, random_state=42)
# t-SNE 학습 및 변환
X_tsne = tsne.fit_transform(X_scaled)
# 변환된 데이터의 크기 확인
print(X_tsne.shape)
#
(70000, 2)- 시각화
# 2차원 시각화
plt.figure(figsize=(10, 7))
sns.scatterplot(x=X_tsne[:, 0], y=X_tsne[:, 1], hue=y, palette='viridis', legend=None)
plt.title('t-SNE of MNIST Dataset (2D)')
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.show()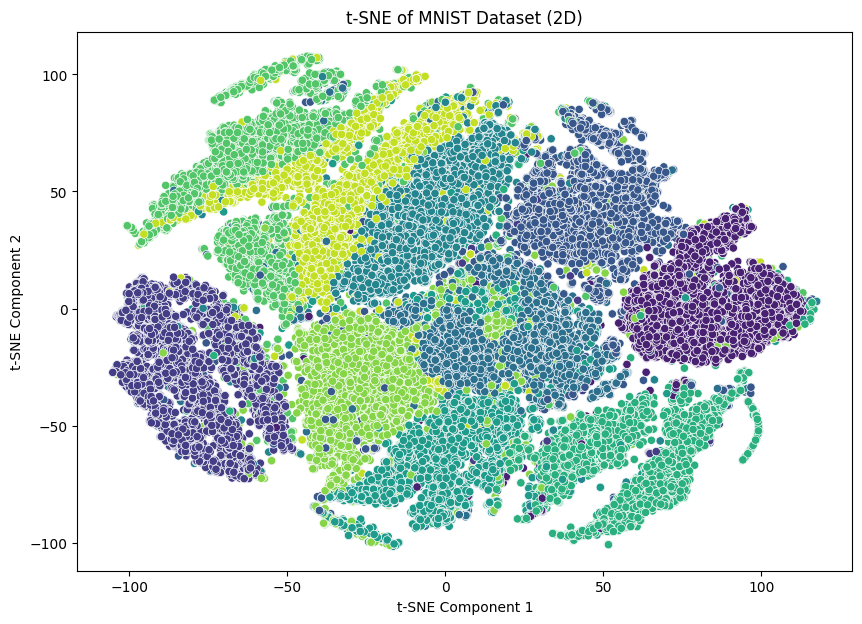
LDA
Linear Discriminant Analysis, 선형 판별 분석
- 차원 축소와 분류를 동시에 진행
- 데이터 클래스 간 분산을 최대화
- 데이트 클래스 내부 분산은 최소화
- 분류에 장점
- 노이즈에 민감
> 클래스 내 분산 행렬 계산
> 클래스 간 분산 행렬 계산
> 고유값 및 고유백터 계산
> 선형 판별 축 선택 - 고유값이 큰 순서
- 고유값이 클수록 해당 선형 판별 축이 클래스 간 분산을 더 많이 설명
- 일반적으로, 클래스의 수 - 1 만큼의 선형 판별 축을 선택
> 데이터 변환 - 축을 기준 - 모델 생성, 학습
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# LDA 모델 생성
lda = LinearDiscriminantAnalysis(n_components=9) # 클래스의 수 - 1 만큼의 선형 판별 축 선택
# LDA 학습 및 변환
X_lda = lda.fit_transform(X_scaled, y)
# 변환된 데이터의 크기 확인
print(X_lda.shape)
#
(70000, 9)- 시각화
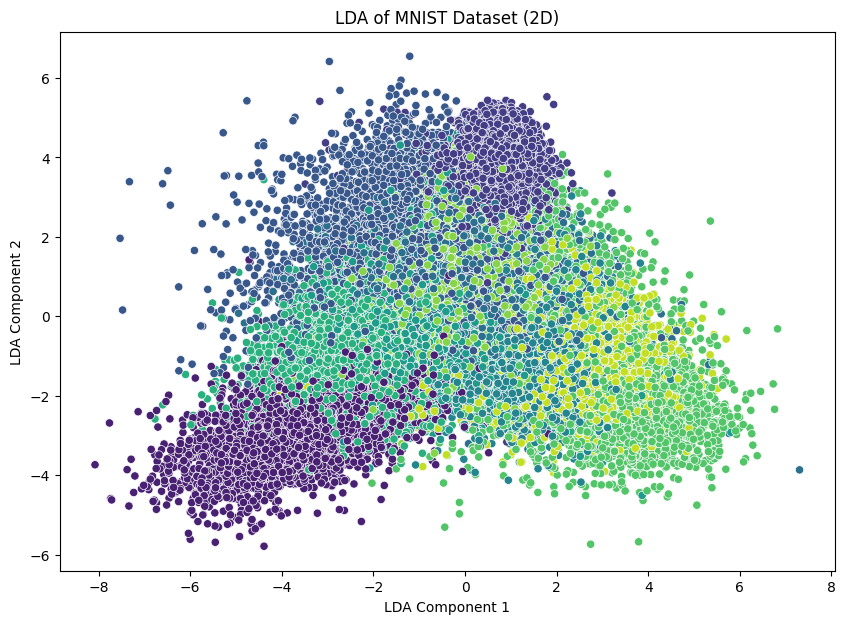
# 2차원 시각화
plt.figure(figsize=(10, 7))
sns.scatterplot(x=X_lda[:, 0], y=X_lda[:, 1], hue=y, palette='viridis', legend=None)
plt.title('LDA of MNIST Dataset (2D)')
plt.xlabel('LDA Component 1')
plt.ylabel('LDA Component 2')
plt.show()