뉴스 본문 링크 가져오는 방법
import requests
from bs4 import BeautifulSoup
response = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
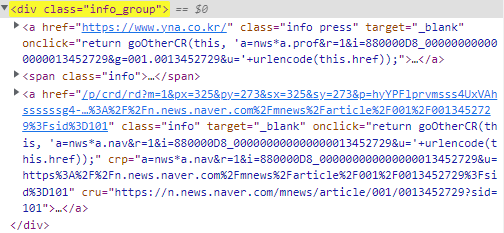
- 네이버에서 기사를 볼 수 있는 경우를 찾아 링크를 저장
- 네이버뉴스 본문이 있을 경우 언론사의 주소와 네이버뉴스 본문의 주소가 각각 담긴 'a' tag의 'info' class가 두 개 존재
- 위와 같은 경우 두번째 'a' tag의 'info' class의 'href'를 추출해서 url에 저장
뉴스 본문 내용 크롤링하는 법
import requests
from bs4 import BeautifulSoup
import time
response = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
content = soup.select_one("#dic_area") # get the body
print(content.text)
time.sleep(0.3)
- 각 url마다 soup 객체를 만들어 뉴스 본문을 크롤링
연예 뉴스 크롤링
import requests
from bs4 import BeautifulSoup
import time
response = requests.get("https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query=%EB%B8%94%EB%9E%99%ED%95%91%ED%81%AC&oquery=%EC%82%BC%EC%84%B1%EC%A0%84%EC%9E%90&tqi=hyYPFlprvmsss4UxVAhssssssg4-385087")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
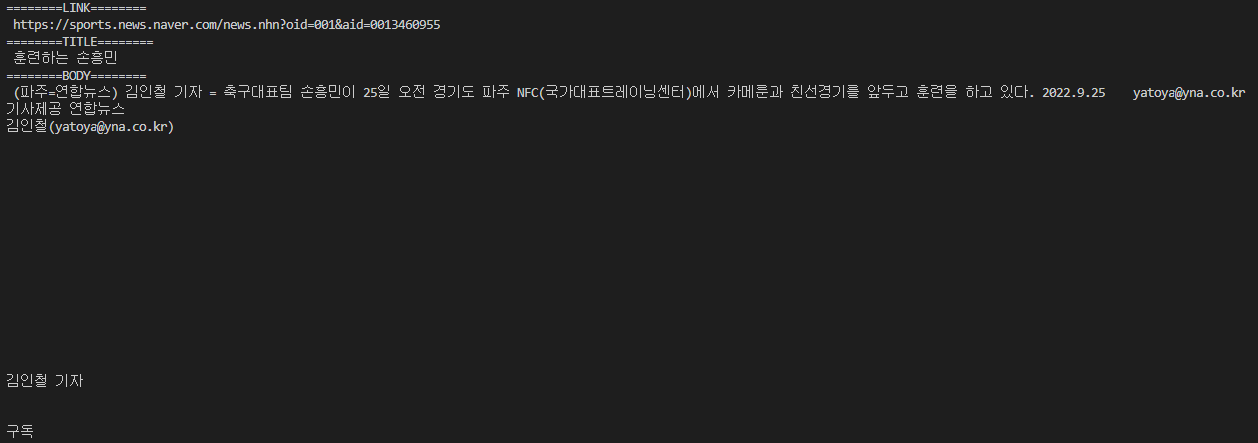
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
time.sleep(0.3)- 연예 뉴스의 경우 url에 'entertain'이 포함됨
- redirection으로 인해 response를 출력했을 때의 url과 실제 url이 바뀌는 상황이 생겨 response.url을 통해 실제 url에 대해 검사
스포츠 뉴스 크롤링
import requests
from bs4 import BeautifulSoup
import time
response = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EC%86%90%ED%9D%A5%EB%AF%BC")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
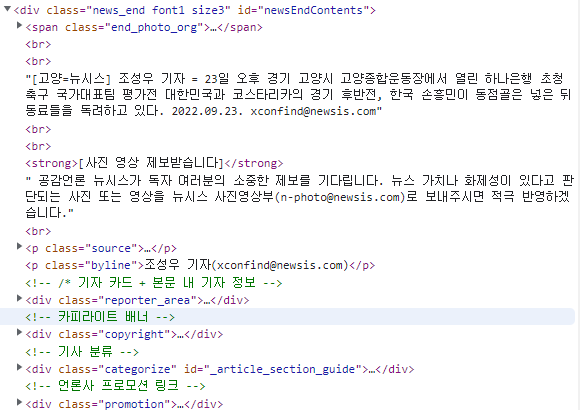
elif "sports" in response.url: # to avoid redirection error
title = soup.select_one("h4.title") # get the title
content = soup.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
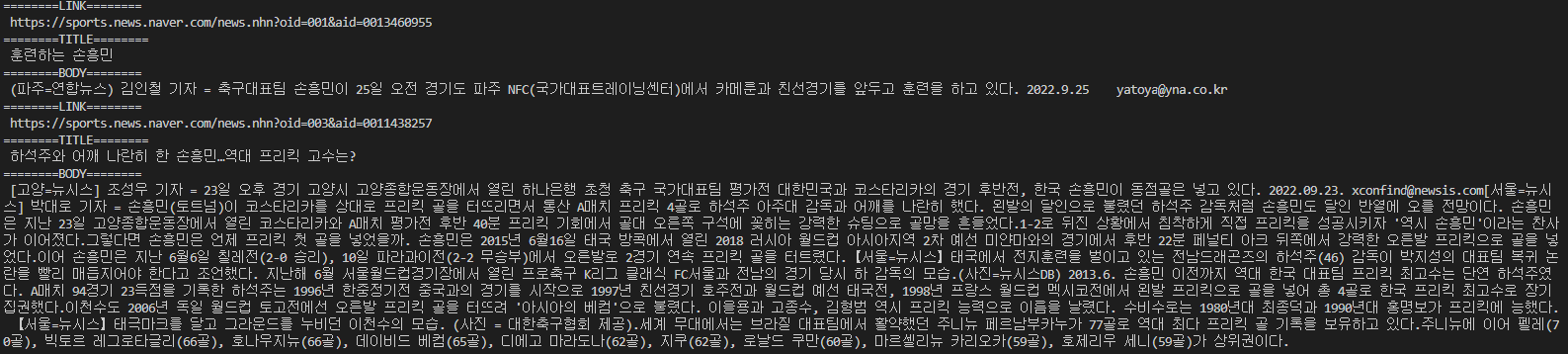
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
time.sleep(0.3)- 연예 뉴스와 비슷하게 스포츠 뉴스의 경우 url에 'sports'가 포함됨
- 분기문을 하나 더 작성해 스포츠 뉴스의 경우도 연예 뉴스처럼 처리하도록 작성
- 스포츠 뉴스의 본문을 크롤링해 올 경우 불필요한 요소가 상당히 많으므로 본문을 감싸고 있는 'div' tag와 'p' tag에 감싸져 있는 본문 내용에서 decompose()를 통해 그러한 요소들을 제거
검색어 변경하기
import requests
from bs4 import BeautifulSoup
import time
import pyautogui
keyword = pyautogui.prompt("keyword")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
title = soup.select_one("h4.title") # get the title
content = soup.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
time.sleep(0.3)- pyautogui.prompt()를 통해 검색할 단어를 입력받음
- 입력받은 단어를 url에서 검색어를 나타내는 query에 반영해 원하는 단어에 대해 뉴스를 검색하도록 설정
여러 페이지 가져오기
import requests
from bs4 import BeautifulSoup
import time
import pyautogui
# user input
keyword = pyautogui.prompt("keyword")
lastpage = int(pyautogui.prompt("page"))
page_num = 1
for i in range(1, lastpage * 10, 10):
print(f"{page_num} page...")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
title = soup.select_one("h4.title") # get the title
content = soup.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
time.sleep(0.3)
page_num += 1- pyautogui.prompt()로 검색어와 페이지수를 입력받고 pyautogui.prompt()는 문자열을 반환하기 때문에 페이지 수의 경우 int로 바꿔서 저장
- 네이버 뉴스의 검색 결과는 한 페이지당 10개의 기사가 나오므로 2개의 페이지를 크롤링한다면 총 20개의 기사를 검사해야하고 1 page에서 2 page로 넘어갈 경우 url의 중간 부분을 살펴보면
query=%EC%86%90%ED%9D%A5%EB%AF%BC&start=1
query=%EC%86%90%ED%9D%A5%EB%AF%BC&start=11
맨 뒤의 start가 page의 번화 증가함에 따라 10씩 증가하므로 range(1, lastpage * 10, 10)를 통해 start에 대입할 수를 가져옴
워드 문서 다루기
python-docx 설치
- 명령 프롬프트 창에서 아래 명령 실행
pip install python-docxpython-docx 사용
from docx import Document
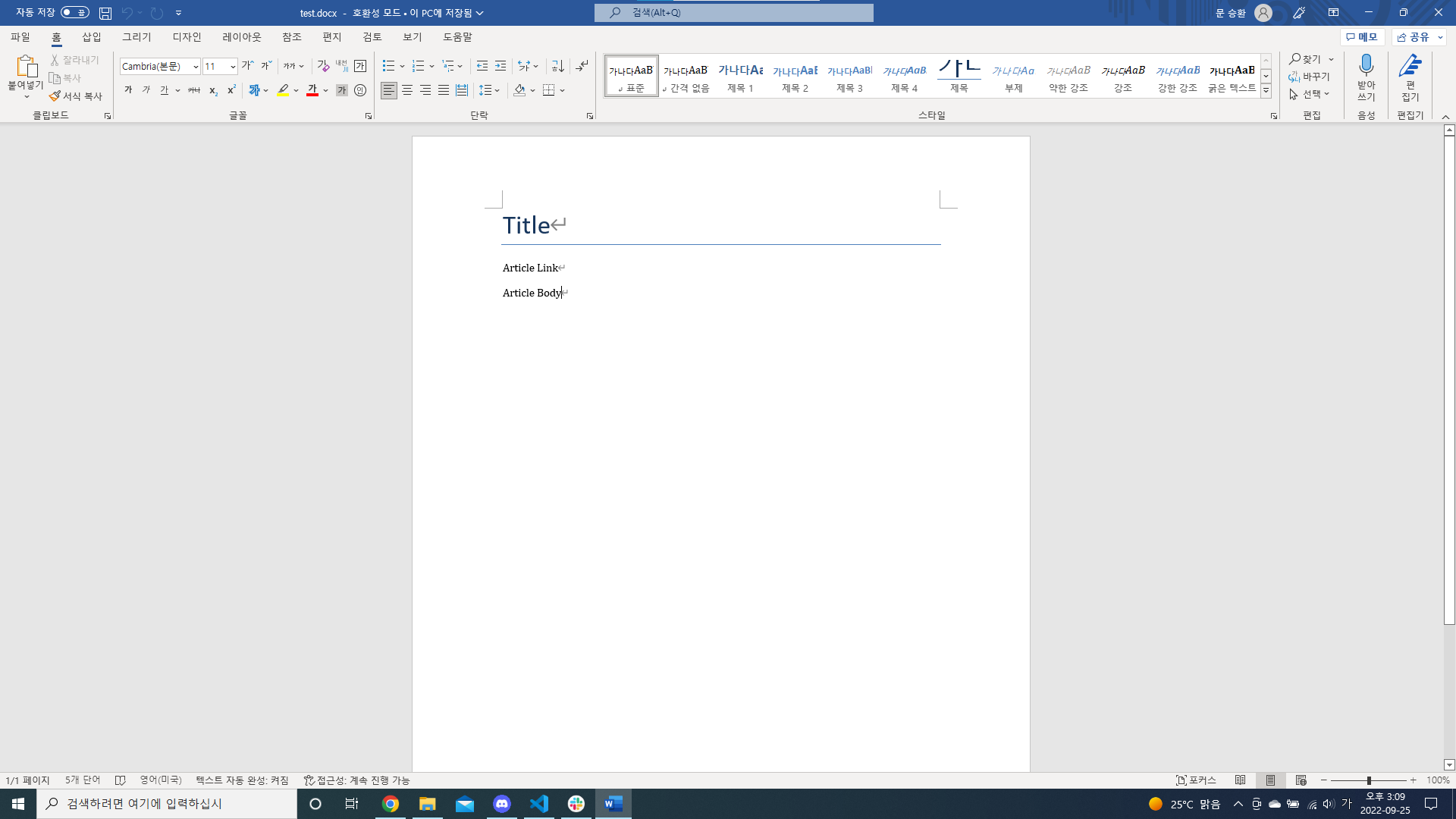
document = Document()
document.add_heading('Title', level=0)
document.add_paragraph('Article Link')
document.add_paragraph('Article Body')
document.save("test.docx")- Document()를 통해 word 객체 생성
- docx 모듈 내의 함수를 사용해 각 요소에 맞게 배치하도록 작성
크롤링 결과 워드에 저장하는 방법
import requests
from bs4 import BeautifulSoup
import time
import pyautogui
from docx import Document
# user input
keyword = pyautogui.prompt("keyword")
lastpage = int(pyautogui.prompt("page"))
# create docx file
document = Document()
page_num = 1
for i in range(1, lastpage * 10, 10):
print(f"{page_num} page...")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
title = soup.select_one("h4.title") # get the title
content = soup.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
# write datas in docx file
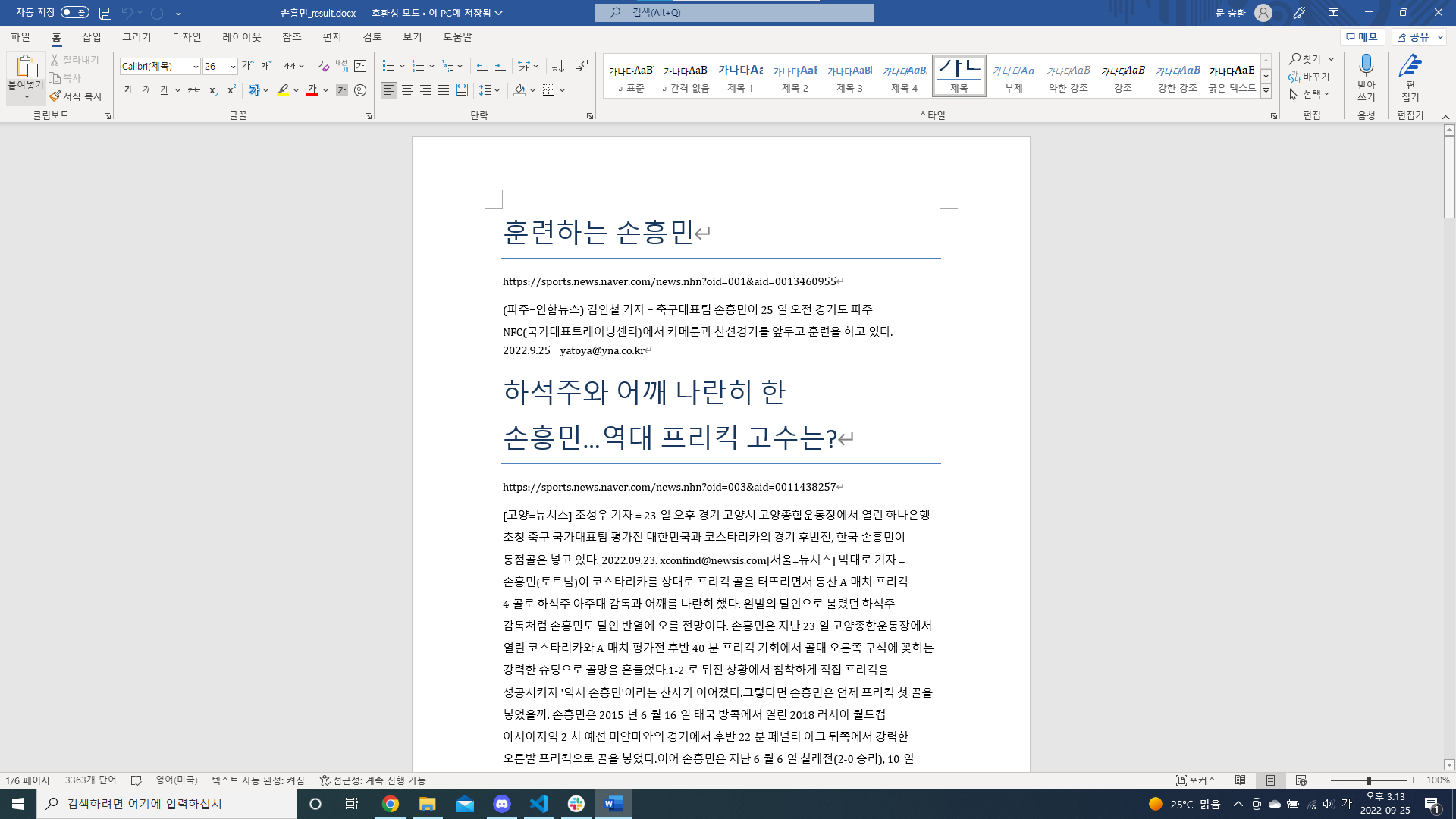
document.add_heading(title.text.strip(), level=0)
document.add_paragraph(url)
document.add_paragraph(content.text.strip())
time.sleep(0.3)
page_num += 1
document.save(f"{keyword}_result.docx")- '워드 문서 다루기'에서 설정한 부분에 따라 기사에서 그에 맞는 요소를 대입해 문서를 작성
- 파일명에 검색한 키워드를 반영해 저장하도록 작성
엑셀 문서 다루기
openpyxl 설치
- 명령 프롬프트 창에서 아래 명령 실행
pip install openpyxlopenpyxl 사용
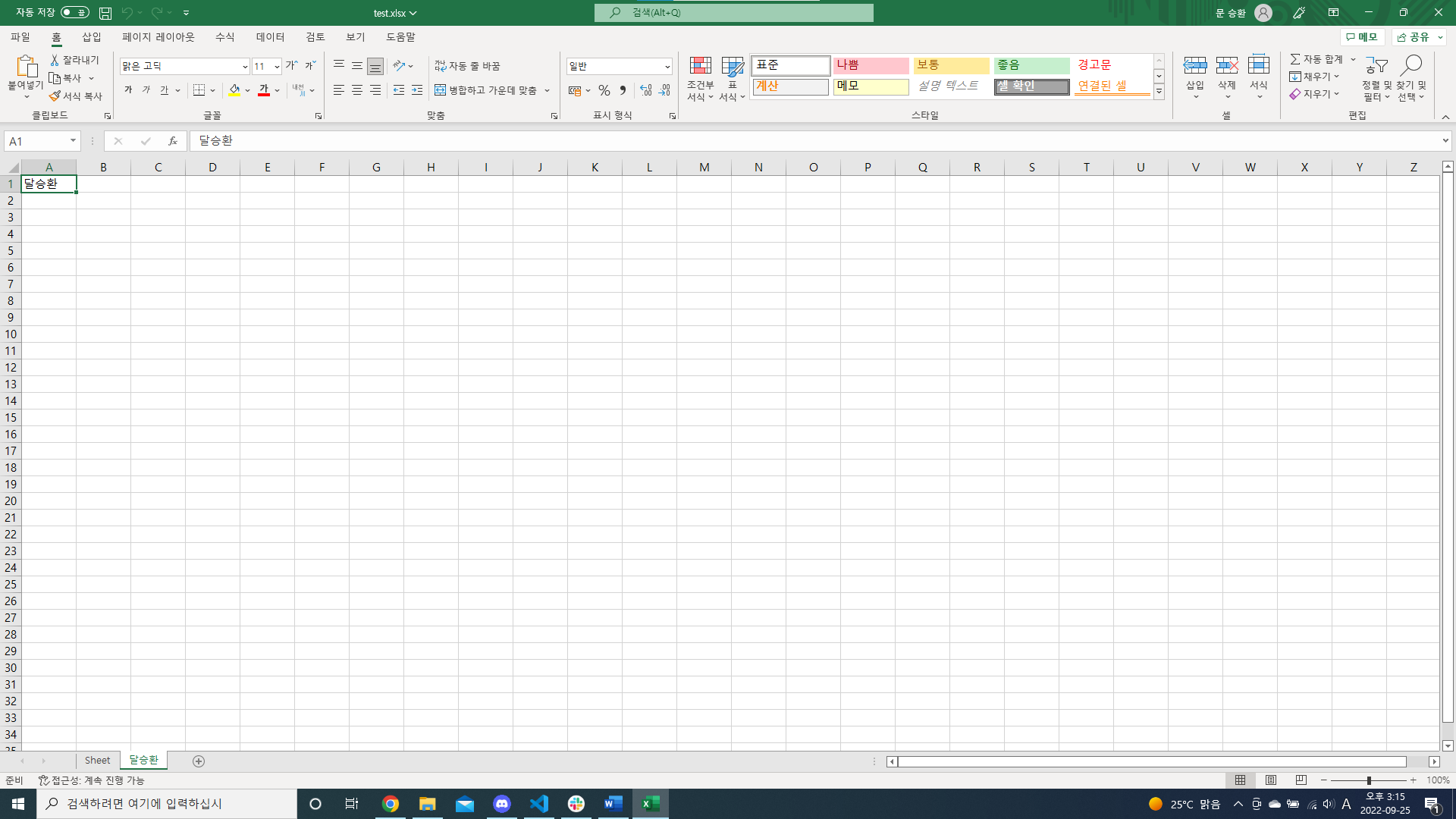
from openpyxl import Workbook
wb = Workbook()
ws = wb.create_sheet("달승환")
ws["A1"] = "달승환"
wb.save("test.xlsx")- Workbook()를 통해 excel 객체 생성
- openpyxl 모듈 내의 함수를 사용해 각 요소에 맞게 배치하도록 작성
크롤링 결과 엑셀에 저장하는 방법
import requests
from bs4 import BeautifulSoup
import time
import pyautogui
from openpyxl import Workbook
from openpyxl.styles import Alignment
# user input
keyword = pyautogui.prompt("keyword")
lastpage = int(pyautogui.prompt("page"))
# create xlsx file
wb = Workbook()
ws = wb.create_sheet(keyword)
ws.column_dimensions['A'].width = 60
ws.column_dimensions['B'].width = 60
ws.column_dimensions['C'].width = 120
# variables
page_num = 1
row = 1
for i in range(1, lastpage * 10, 10):
print(f"{page_num} page...")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup.select_one(".end_tit") # get the title
content = soup.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
title = soup.select_one("h4.title") # get the title
content = soup.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup.select_one(".media_end_head_headline") # get the title
content = soup.select_one("#dic_area") # get the body
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
# write datas in xlsx file
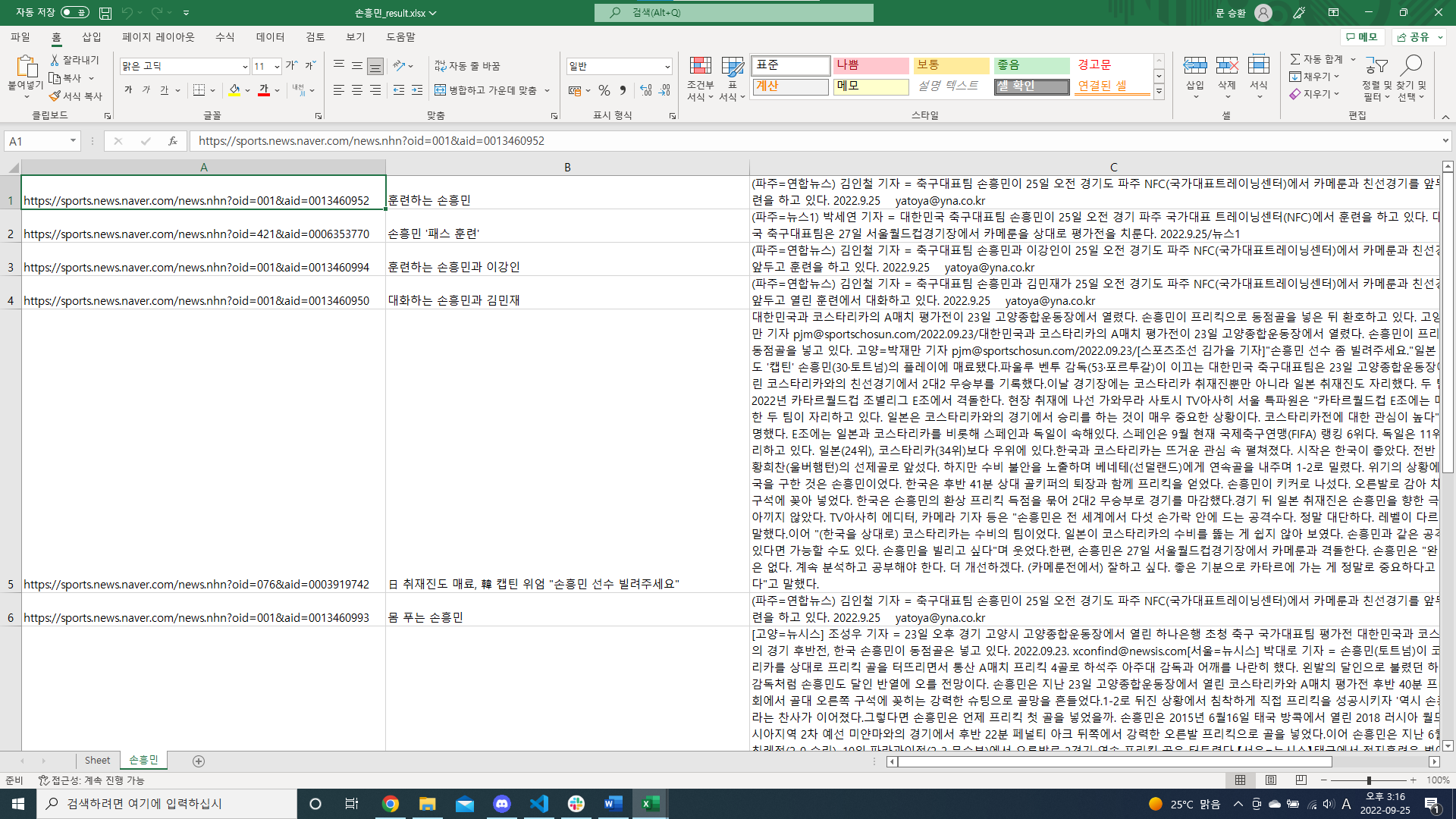
ws[f"A{row}"] = url
ws[f"B{row}"] = title.text.strip()
ws[f"C{row}"] = content.text.strip()
ws[f"C{row}"].alignment = Alignment(wrap_text=True) # line breaking
row += 1
time.sleep(0.3)
page_num += 1
wb.save(f"{keyword}_result.xlsx")- '엑셀 문서 다루기'에서 설정한 부분에 따라 기사에서 그에 맞는 요소를 대입해 문서를 작성
- 각 요소에 따라 셀의 크기를 조정(자세한 내용은 공식문서 참고)
- 파일명에 검색한 키워드를 반영해 저장하도록 작성
마지막 페이지 확인하기
import requests
from bs4 import BeautifulSoup
import time
import pyautogui
# user input
keyword = pyautogui.prompt("keyword")
lastpage = int(pyautogui.prompt("page"))
page_num = 1
for i in range(1, lastpage * 10, 10):
print(f"{page_num} page...")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup_sub = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
title = soup_sub.select_one(".end_tit") # get the title
content = soup_sub.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
title = soup_sub.select_one("h4.title") # get the title
content = soup_sub.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
title = soup_sub.select_one(".media_end_head_headline") # get the title
content = soup_sub.select_one("#dic_area") # get the body
print("========LINK========\n", url)
print("========TITLE========\n", title.text.strip())
print("========BODY========\n", content.text.strip())
time.sleep(0.3)
# checking where the last page is
is_last_page = soup.select_one("a.btn_next").attrs["aria-disabled"]
if is_last_page == "true":
print("last page")
break
page_num += 1- 네이버 뉴스 검색 결과에서 마지막 페이지일 경우 하단에 있는 다음 페이지로 넘어가는 버튼이 비활성화 되는 것을 이용

- html에서 버튼의 tag를 보면 aria-disabled의 값이 활성화가 된 경우 false이고 비활성화가 된 경우 true임을 확인


- soup.select_one("a.btn_next").attrs["aria-disabled"]를 통해 'a' tag의 btn_next 클래스에서 aria-disabled의 값을 가져와 is_last_page에 저장 후 그 값이 true일 경우 반복문을 빠져나오도록 작성
워드 클라우드
module 설치
- 명령 프롬프트 창에서 아래 명령 실행
pip install matplotlib
pip install wordcloud
pip install konlpykonlpy 설치시 유의사항
1. OS와 비트 수가 일치하고 버전이 1.7 이상인 자바 설치
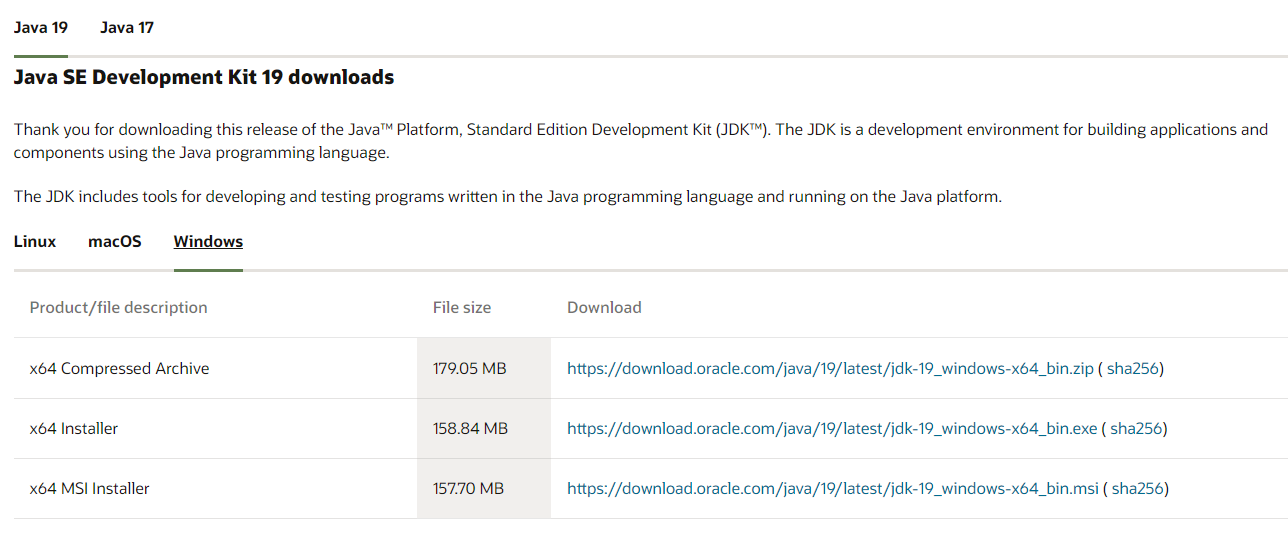
- 링크를 통해 이동시 위와 같은 화면이 나옵니다. Java 19와 Java 17 중 하나를 선택하고 아래에서 installer를 설치하면 됩니다.
2. 시스템 환경 변수에서 JAVA_HOME 설정 - 먼저 설치된 자바의 위치를 확인합니다. (필자의 경우 파일의 위치는 아래와 같음)
C:\Program Files\Java\jdk-17.0.4.1\bin\server- 설정에서 시스템 환경 변수 편집으로 들어갑니다.
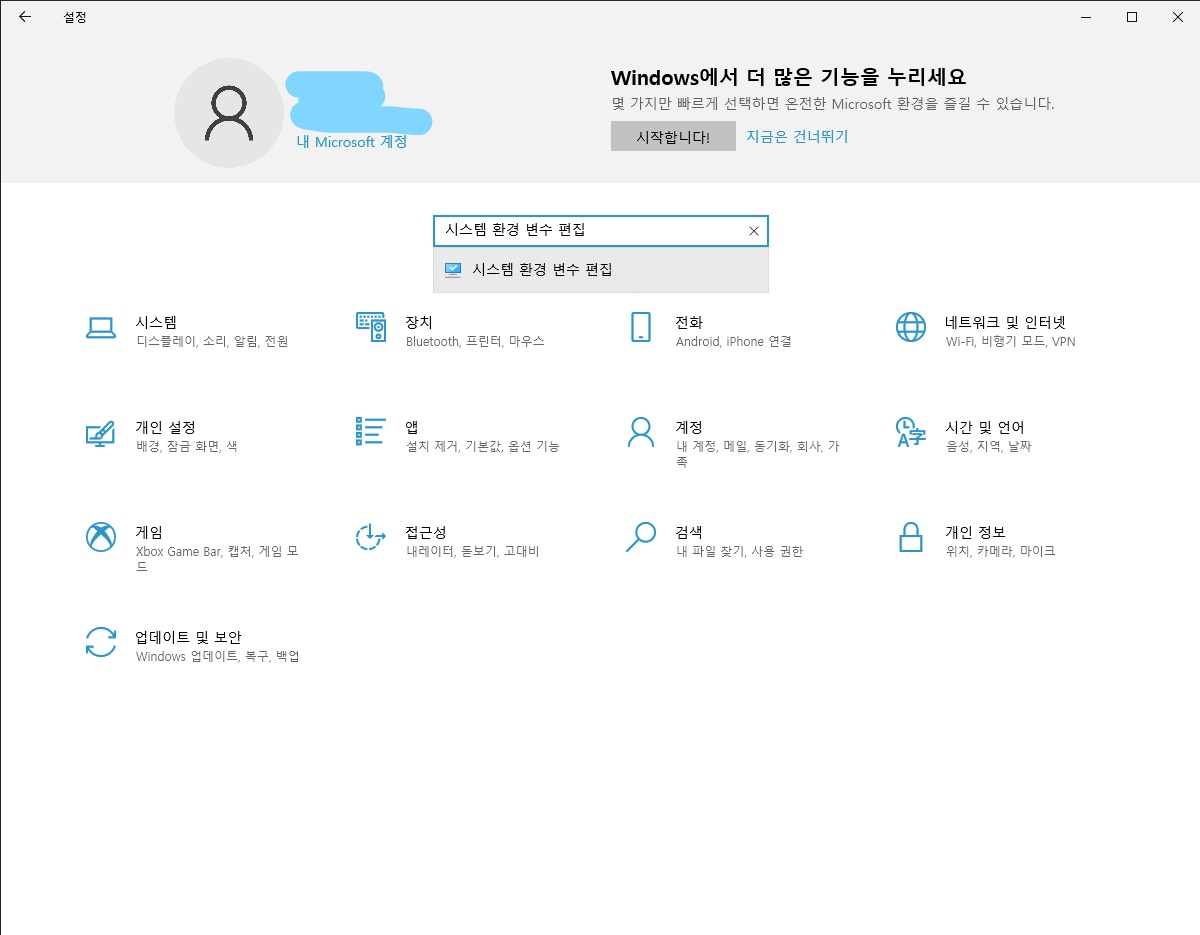
- 우측 하단의 환경 변수을 눌러 진입합니다.
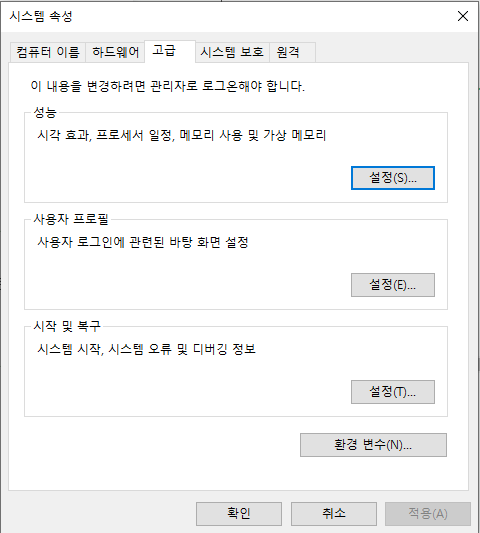
- 위 화면에서 시스템 변수 - 새로 만들기를 통해 아래와 같이 JAVA_HOME과 CLASSPATH를 입력해 설정합니다.
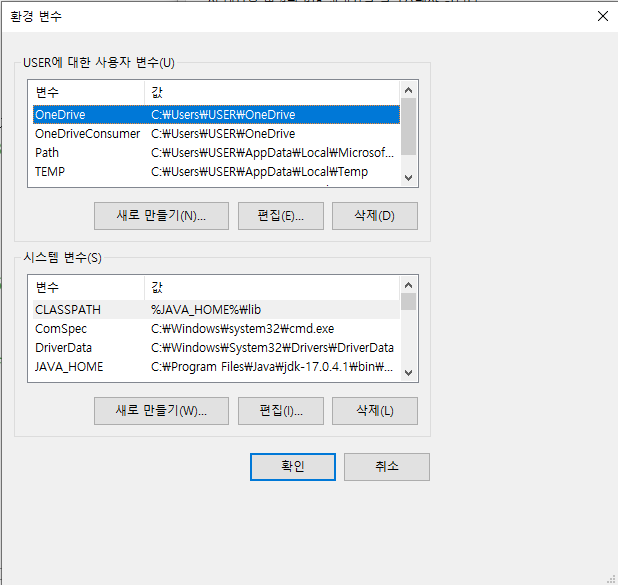
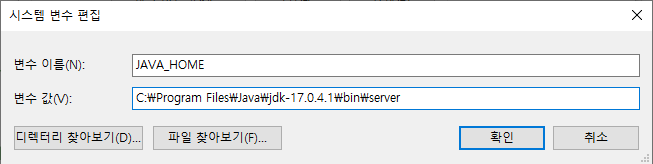
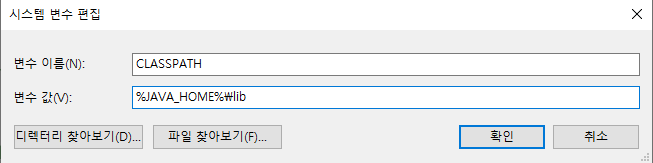
3. OS의 비트 수와 일치하는 JPype1 설치 - 본인의 파이썬 버전과 OS의 비트 수를 확인합니다. (필자의 경우 3.9 version, 64 bit)
- 파이썬 버전과 OS의 비트 수에 맞는 파일을 선택합니다. (필자의 경우 파이썬 버전과 OS 비트에 따라 JPype1‑1.4.0‑cp39‑cp39‑win_amd64.whl를 다운받음)
cp -> pyhton version
win -> OS bit
- 보통 내려받게되면 다운로드 폴더에 저장이되므로 명령 프롬프트 창에서 위 파일을 이용해 설치할 경우 경로를 설정해야하므로 아래와 같이 명령 프롬프트 창에서 진행합니다.
C:\Users\USER>cd Downloads
C:\Users\USER\Downloads>pip install JPype1‑1.4.0‑cp39‑cp39‑win_amd64.whl- pip install 이후에는 본인의 파일명을 확장자까지 복사해 붙여넣기 하면 됩니다.
사용
import matplotlib.pyplot as plt # 생성한 워드클라우드 데이터를 시각화하여 그리기 위해 불러옵니다. (Google Colab 또는 Jupyter Notebook에서 사용)
from wordcloud import WordCloud # 워드클라우드 생성에 필요한 기본 모듈
from konlpy.tag import Okt # 한국어를 처리하는 대표적인 형태소 분석 패키지입니다.
# Okt, Kkma 등 여러가지 패키지들이 존재하는데 형태소 분석기마다 명사, 명사 등의 형태소를 조금씩 다르게 처리합니다.
# 다양하게 사용해본 후, 가지고 있는 문서 특성에 적합한 형태소 분석기를 사용하는 것이 좋습니다.
from collections import Counter # 텍스트를 추출하고, 빈도 수를 추출하기 위해 사용합니다. 기본적으로 워드클라우드는 단어의 출현 빈도가 클수록 더 크게 그려집니다.import requests
from bs4 import BeautifulSoup
import time
import pyautogui
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from konlpy.tag import Okt
from collections import Counter
# user input
keyword = pyautogui.prompt("keyword")
lastpage = int(pyautogui.prompt("page"))
page_num = 1
total_content = ""
article_num = 0
for i in range(1, lastpage * 10, 10):
print(f"{page_num} page...")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.select("div.info_group")
for article in articles:
links = article.select("a.info")
if len(links) >= 2:
url = links[1].attrs["href"]
response = requests.get(url, headers={'User-agent': 'Mozila/5.0'}) # to avoid error use headers
html = response.text # for each url get html
soup_sub = BeautifulSoup(html, "html.parser") # for each html make soup
# separation
if "entertain" in response.url: # to avoid redirection error
content = soup_sub.select_one("#articeBody") # get the body
elif "sports" in response.url: # to avoid redirection error
content = soup_sub.select_one("#newsEndContents") # get the body
# delete unnecessary elements
divs = content.select("div")
for div in divs:
div.decompose()
paragraphs = content.select("p")
for p in paragraphs:
p.decompose()
else:
content = soup_sub.select_one("#dic_area") # get the body
print("========BODY========\n", content.text.strip())
total_content += content.text.strip()
article_num += 1
time.sleep(0.3)
# checking where the last page is
is_last_page = soup.select_one("a.btn_next").attrs["aria-disabled"]
if is_last_page == "true":
print("last page")
break
page_num += 1
print(f"{article_num} articles")
# wordcloud
okt = Okt()
nouns = okt.nouns(total_content)
words = [word for word in nouns if len(word) > 1]
cnt = Counter(words)
wc = WordCloud(font_path="malgun", width=1280, height=720, scale=2.0, max_font_size=250)
gen = wc.generate_from_frequencies(cnt)
plt.figure()
plt.imshow(gen)
wc.to_file(f"{keyword}_wordcloud.png")- 크롤링한 내용을 모두 하나의 문자열로 만들기위해 total_content에 저장
- konply.tag의 Okt()를 사용해 total_content에서 명사들만 추출해 리스트 (nouns)로 반환
- nouns에서 글자 수가 하나인 단어들은 제외하여 새로운 리스트 (words) 생성
- Counter()를 통해 단어의 빈도수를 구하고 이후 작성된 코드에 따라 내용들을 반영
- 검색어를 파일명에 반영하여 워드 클라우드를 png 파일로 저장

아직 모자란 수학과생