RabbitMQ, Kafka를 사용해 실습을 진행해보며 대규모 스트림 처리 방법에 대해 학습하였다.
RabbitMQ
- RabbitMQ는 메시지 브로커로서 데이터(메시지)를 송신자(프로듀서)로부터 수신자(컨슈머)에게 전달하는 중간 매개체 역할을 한다.
- RabbitMQ는 이러한 메시지를 큐(queue)에 저장하고, 필요할 때 적절한 수신자에게 전달한다.
기본 구성 요소
메시지(Message)
- 메시지는 RabbitMQ를 통해 전달되는 데이터 단위이다. 예를 들어, 사용자 등록 정보나 주문 내역이 메시지가 될 수 있다.
프로듀서(Producer)
- 메시지를 생성하고 RabbitMQ에 보내는 역할을 한다. 예를 들어, 웹 애플리케이션이 사용자 등록 정보를 RabbitMQ에 보내는 경우 프로듀서가 된다.
큐(Queue)
- 메시지를 저장하는 장소이다. 메시지는 큐에 저장되었다가 소비자에게 전달된다. 큐는 FIFO(First In, First Out) 방식으로 메시지를 처리한다.
-
컨슈머(Consumer)
- 큐에서 메시지를 가져와 처리하는 역할을 한다. 예를 들어, 이메일 발송 서비스가 큐에서 환영 이메일을 보내는 경우 컨슈머가 된다.
-
익스체인지(Exchange)
- 메시지를 적절한 큐로 라우팅하는 역할을 한다. 프로듀서는 메시지를 직접 큐에 보내지 않고, 익스체인지에 보내며, 익스체인지는 메시지를 적절한 큐로 전달한다.
실습
RabbitMQ
- 도커를 사용하여 RabbitMQ를 설치한다.
**docker run -d --name rabbitmq -p5672:5672 -p 15672:15672 --restart=unless-stopped rabbitmq:management**
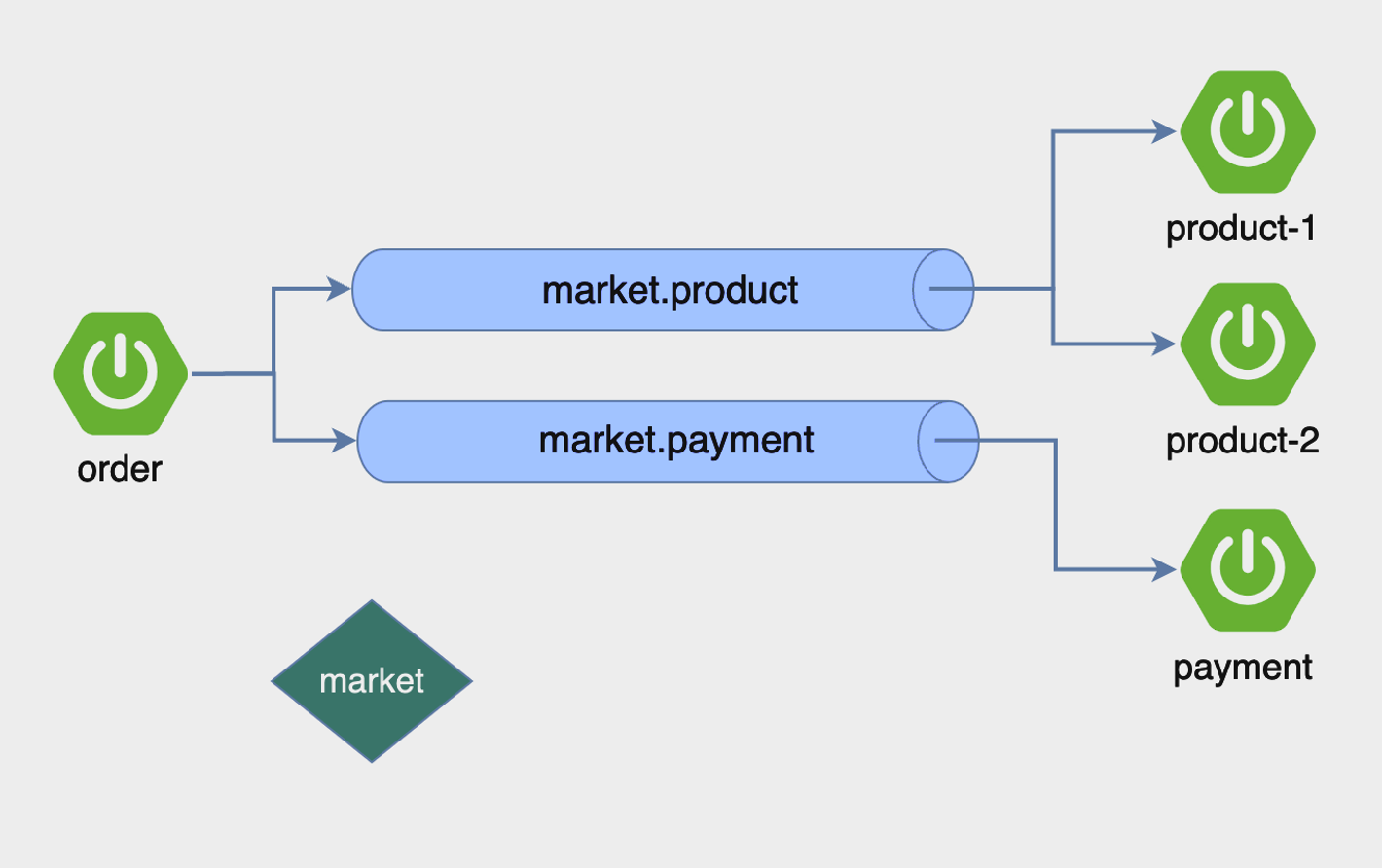
Order Application
- start.spring.io 에 접속하여 프로젝트를 생성한다.
- application.properties
spring.application.name=order message.exchange=market message.queue.product=market.product message.queue.payment=market.payment spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest - OrderApplicationQueueConfig.java
import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.Queue; import org.springframework.amqp.core.TopicExchange; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class OrderApplicationQueueConfig { @Value("${message.exchange}") private String exchange; @Value("${message.queue.product}") private String queueProduct; @Value("${message.queue.payment}") private String queuePayment; @Bean public TopicExchange exchange() { return new TopicExchange(exchange); } @Bean public Queue queueProduct() { return new Queue(queueProduct); } @Bean public Queue queuePayment() { return new Queue(queuePayment); } @Bean public Binding bindingProduct() { return BindingBuilder.bind(queueProduct()).to(exchange()).with(queueProduct); } @Bean public Binding bindingPayment() { return BindingBuilder.bind(queuePayment()).to(exchange()).with(queuePayment); } } - OrderController.java
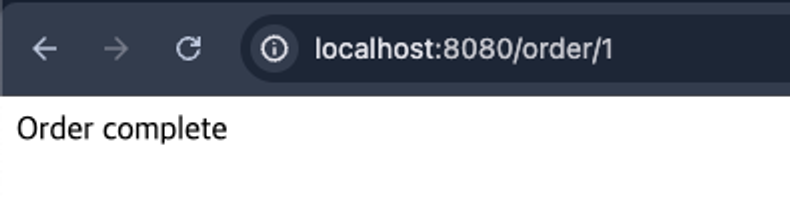
import lombok.RequiredArgsConstructor; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RestController; @RestController @RequiredArgsConstructor public class OrderController { private final OrderService orderService; @GetMapping("/order/{id}") public String order(@PathVariable String id) { orderService.createOrder(id); return "Order complete"; } }
- OrderService.java
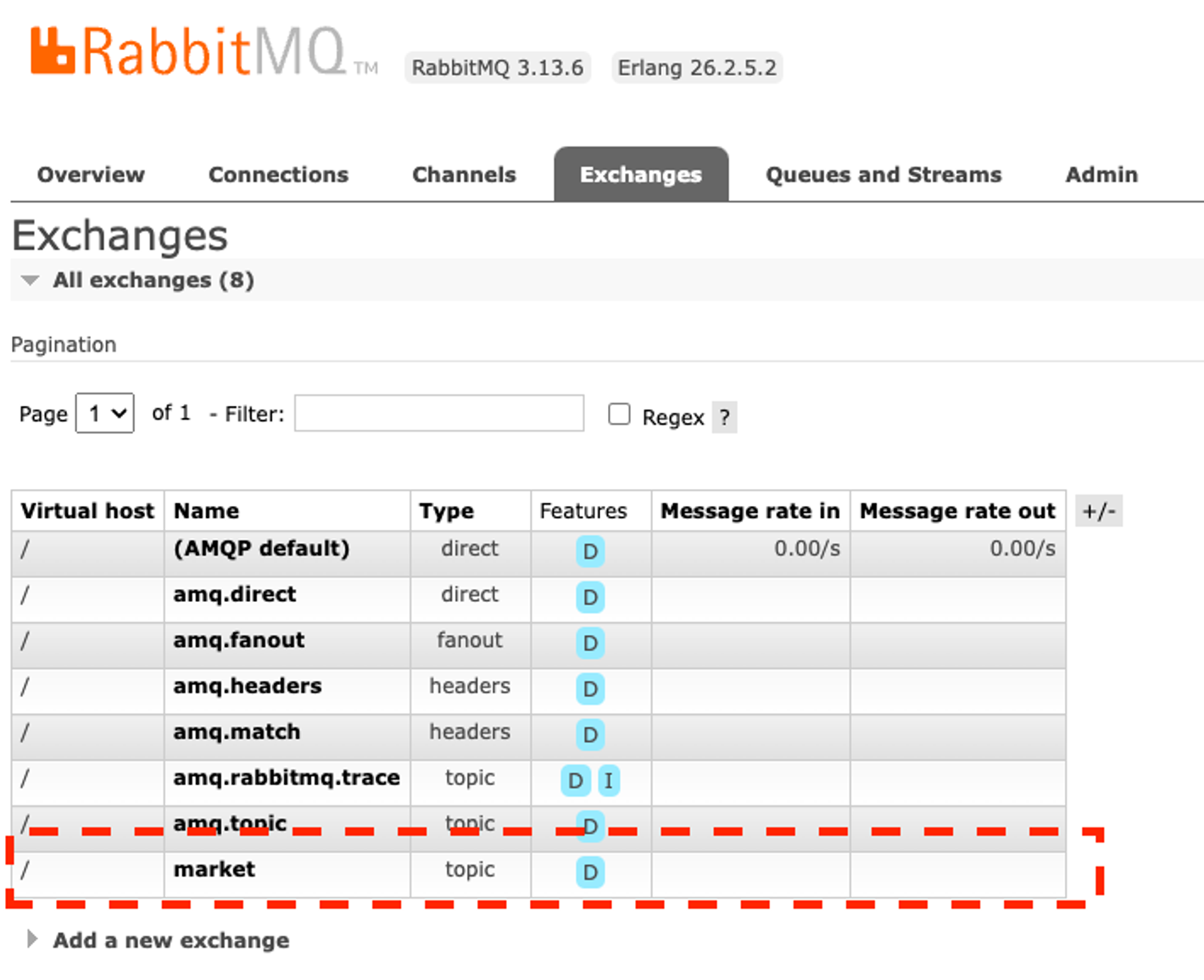
import lombok.RequiredArgsConstructor; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Service; @Service @RequiredArgsConstructor public class OrderService { @Value("${message.queue.product}") private String productQueue; @Value("${message.queue.payment}") private String paymentQueue; private final RabbitTemplate rabbitTemplate; public void createOrder(String orderId) { rabbitTemplate.convertAndSend(productQueue, orderId); rabbitTemplate.convertAndSend(paymentQueue, orderId); } } - 애플리케이션을 런하여 /order/1 로 요청을 보낸다. 그후 http://localhost:15672로 접속하여 RabbitMQ의 Exchange와 Queue 를 확인 할 수 있다.
또한 Queue 에서는 현재 발행된 메시지가 Total 에 쌓여 있는것을 확인 할 수 있다.
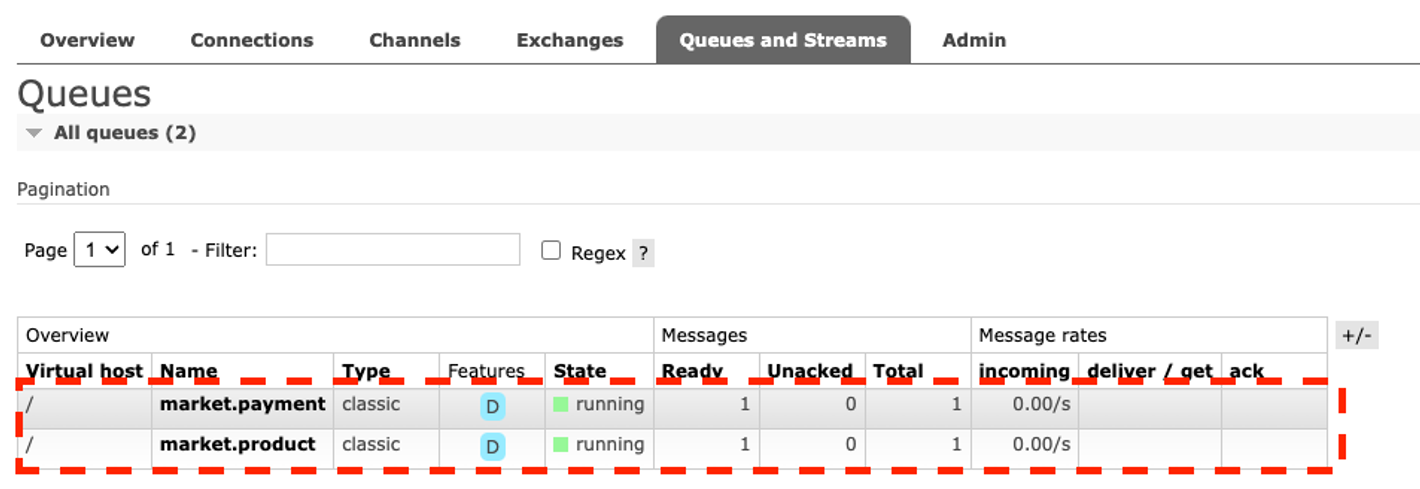
- Queue and Stream 페이지에서 큐 이름을 클릭하여 상세페이지로 이동한 수 스크롤하여 Get Messages섹션으로 가서 Get Message를 클릭하면 현재 큐에 쌓여있는 메시지를 조회 할 수 있다.
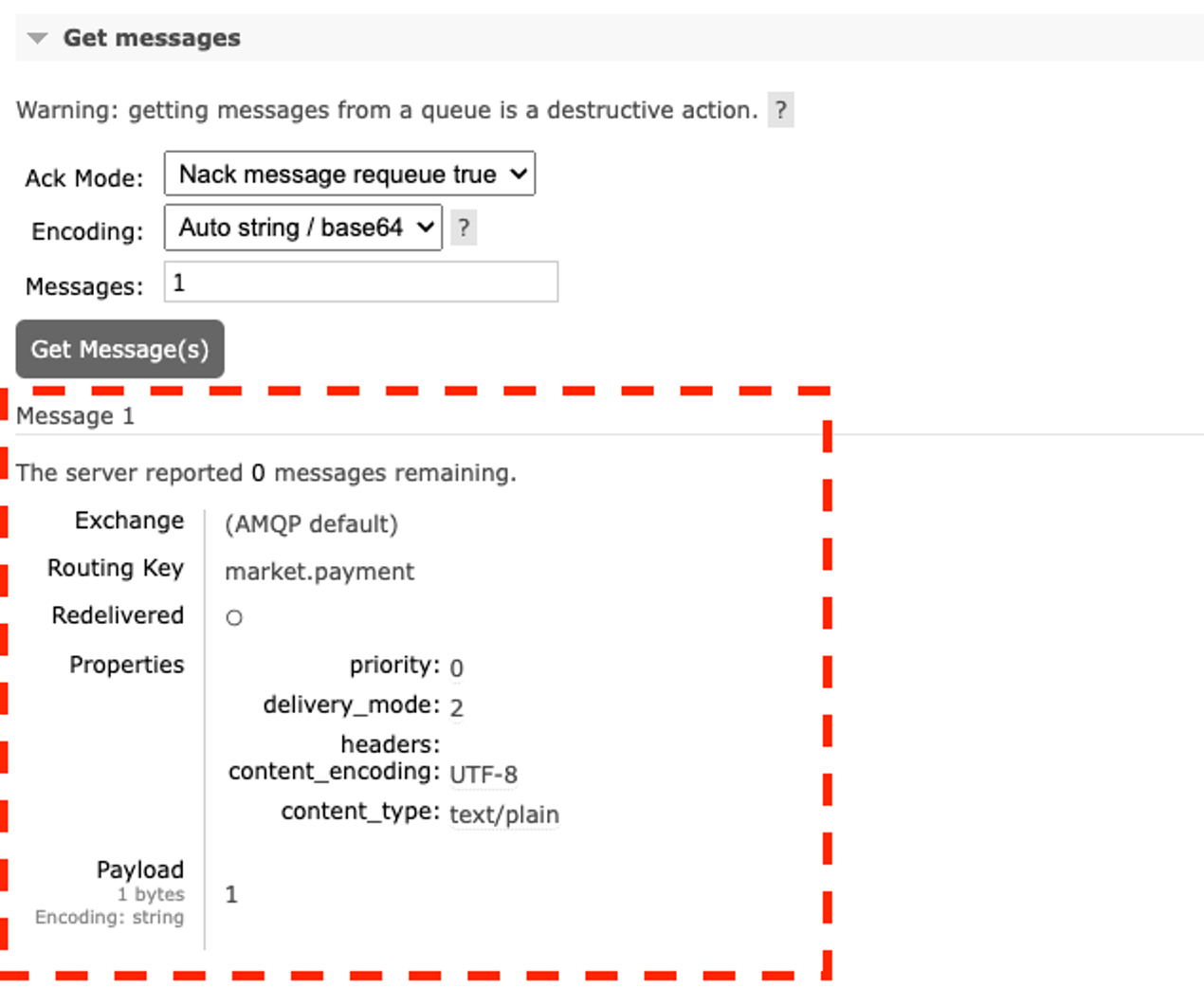
Payment Application
- start.spring.io 에 접속하여 프로젝트를 생성한다.
- application.properties
spring.application.name=payment message.queue.payment=market.payment spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest - PaymentEndpoint.java
import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component; @Slf4j @Component public class PaymentEndpoint { @Value("${spring.application.name}") private String appName; @RabbitListener(queues = "${message.queue.payment}") public void receiveMessage(String orderId) { log.info("receive orderId:{}, appName : {}", orderId, appName); } }
- 애플리케이션을 실행하면 receiveMessage 의 로그가 찍히는것을 확인 할 수 있다. Order 프로젝트에서 발행한 메시지가 Payment Consumer가 실행되자마자 소모 된 것이다.
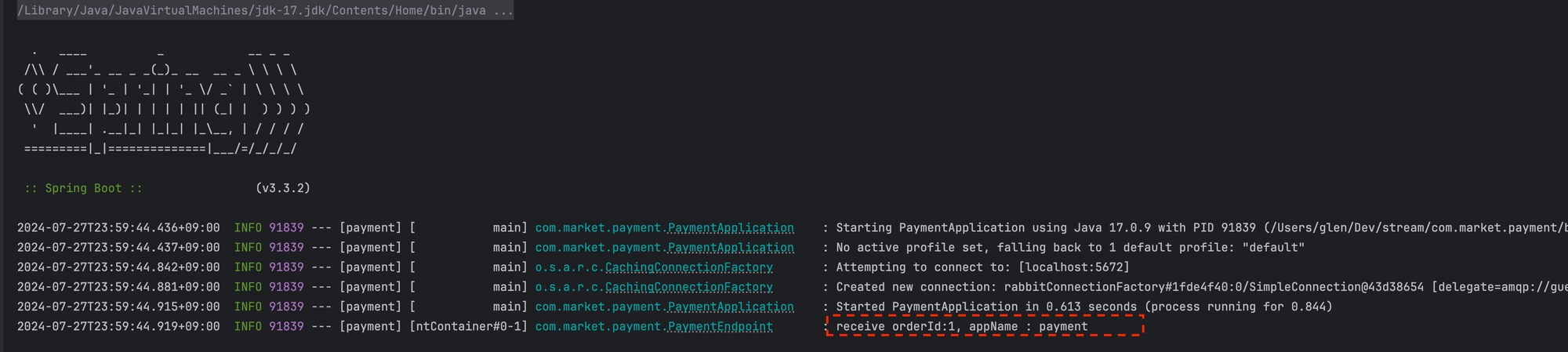

Product Application
- start.spring.io 에 접속하여 프로젝트를 생성한다.
- application.properties
spring.application.name=product message.queue.product=market.product spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest - ProductEndpoint.java
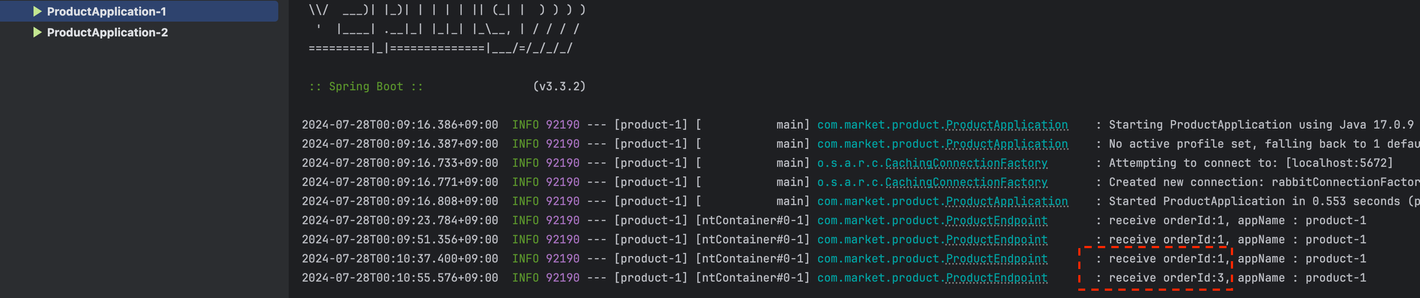
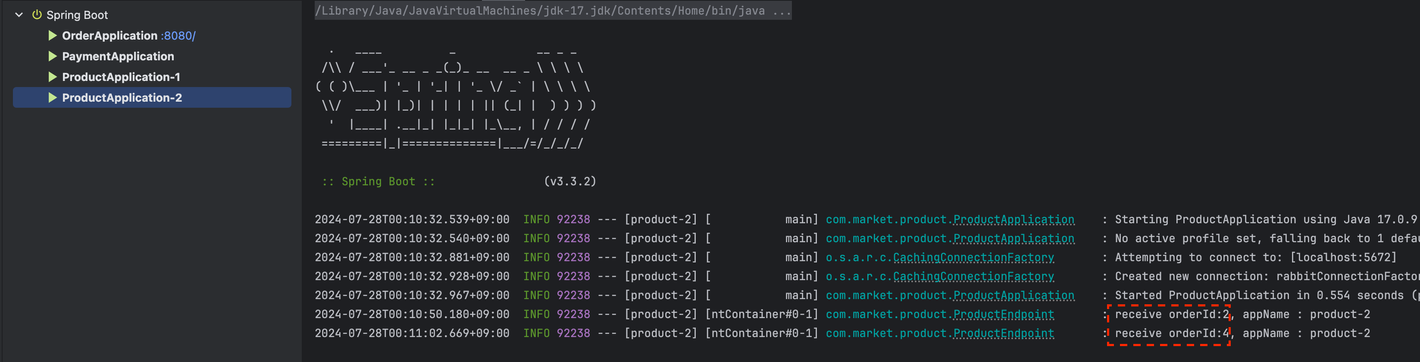
import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.rabbit.annotation.RabbitListener; import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component; @Slf4j @Component public class ProductEndpoint { @Value("${spring.application.name}") private String appName; @RabbitListener(queues = "${message.queue.product}") public void receiveMessage(String orderId) { log.info("receive orderId:{}, appName : {}", orderId, appName); } } - 컨슈머가 라운드로빈으로 메시지를 전달 받는것을 확인하기 위해서 Intellij 에서 구성편집에 들어가 두개의 Product를 생성한다. application.name 옵션을 통해 2를 구분할 수 있도록 한다.
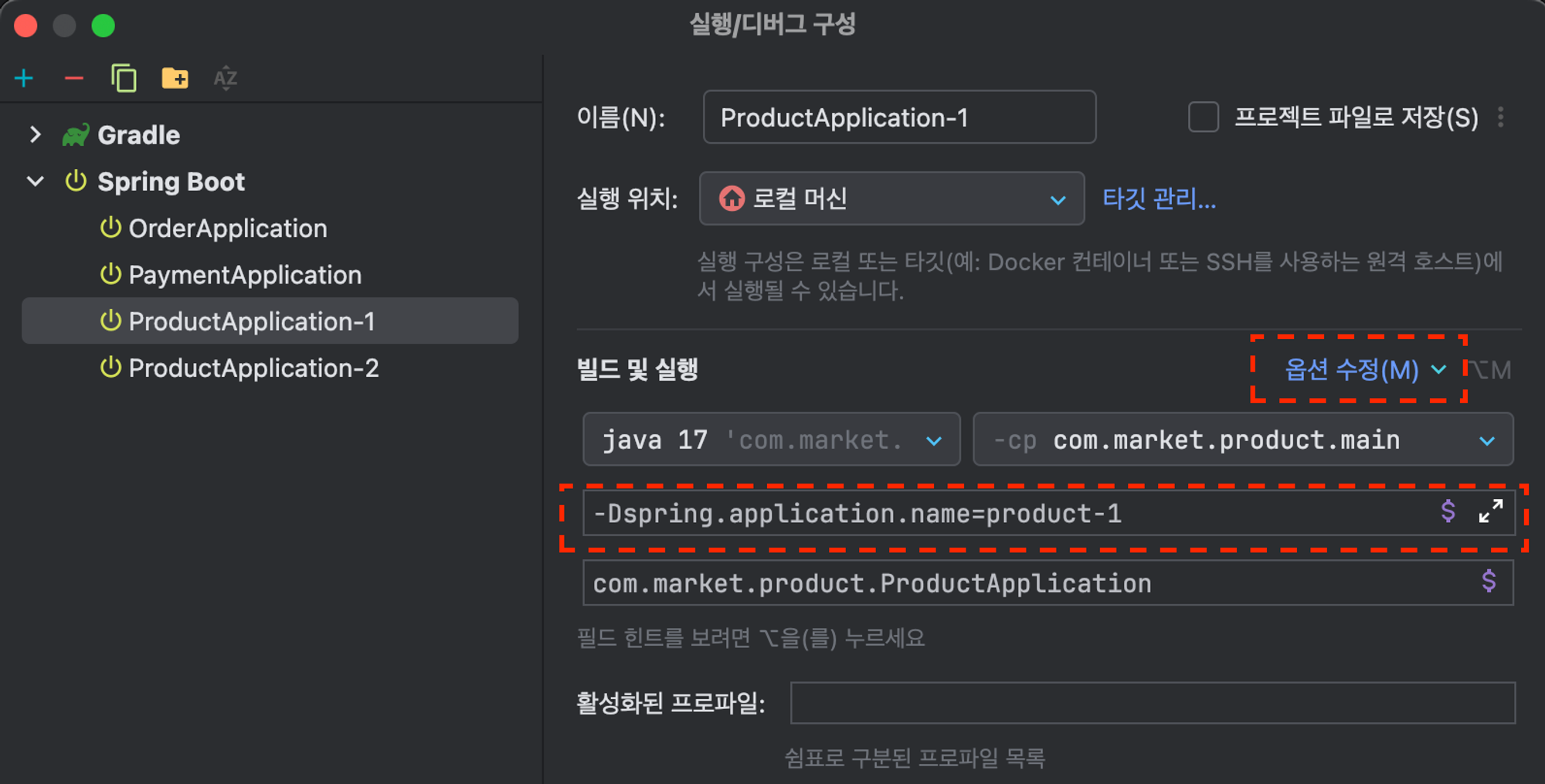
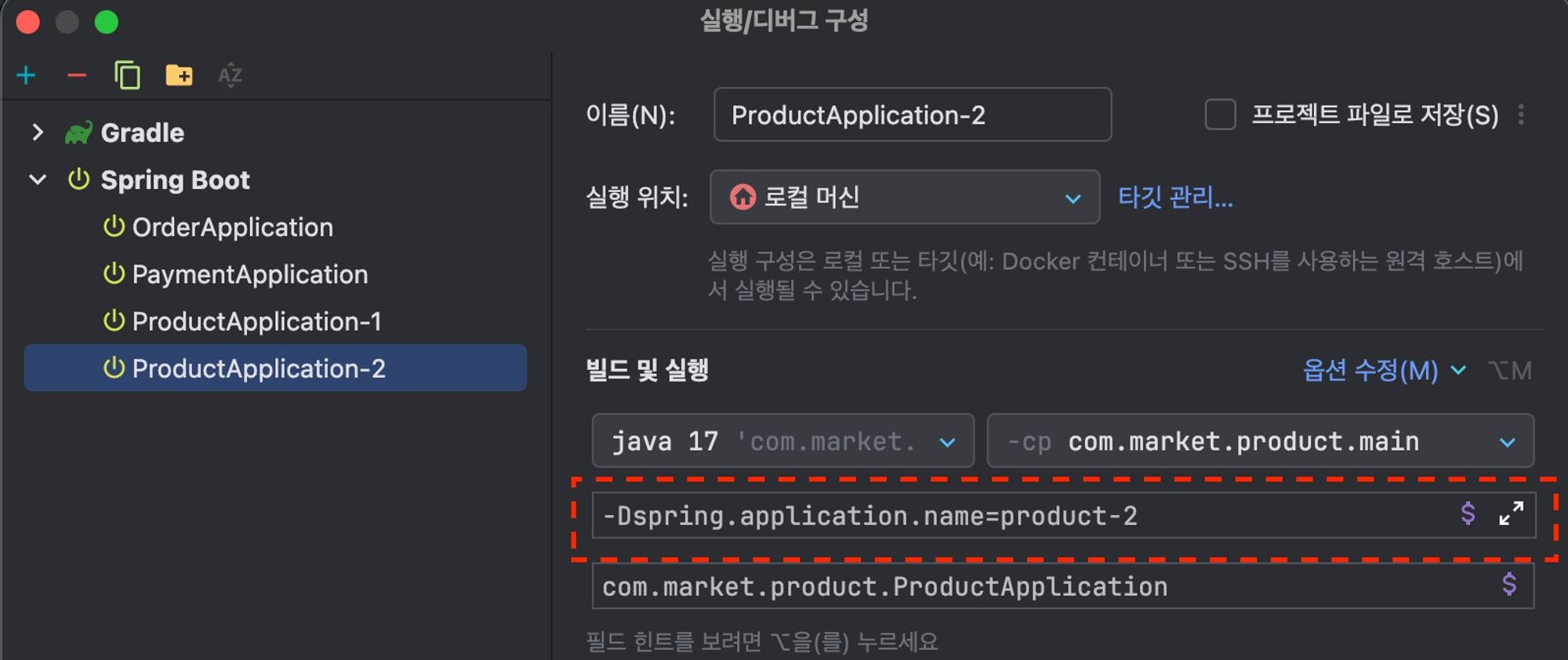
- order에서 요청 할때마다 Product Application이 번갈아 가면서 메시지를 수신 받는것을 확인 할 수 있다.
Kafka
-
Kafka는 분산 스트리밍 플랫폼으로, 주로 실시간 데이터 피드의 빅 데이터 처리를 목적으로 사용된다.
-
Kafka는 메시지 큐와 유사하지만, 대용량 데이터 스트림을 저장하고 실시간으로 분석하거나 처리하는데 중점을 둔다.
-
RabbitMQ는 전통적인 메시지 브로커로, 메시지의 안정적 전달과 큐잉에 중점을 두는 반면 Kafka는 분산 스트리밍 플랫폼으로, 대규모 실시간 데이터 스트림의 저장과 분석에 중점을 둔다.
기본 구성 요소
-
메시지(Message)
-
메시지는 Kafka를 통해 전달되는 데이터 단위이다. 예를 들어, 로그 데이터나 이벤트 데이터가 메시지가 될 수 있다.
-
메시지는 키(key), 값(value), 타임스탬프(timestamp), 그리고 몇 가지 메타데이터로 구성된다.
-
-
프로듀서(Producer)
-
메시지를 생성하고 Kafka에 보내는 역할을 한다. 예를 들어, 웹 애플리케이션이 로그 데이터를 Kafka에 보내는 경우 프로듀서가 된다.
-
프로듀서는 특정 토픽(topic)에 메시지를 보낸다.
-
-
토픽(Topic)
-
메시지를 저장하는 장소이다. 메시지는 토픽에 저장되었다가 소비자에게 전달된다.
-
토픽은 여러 파티션(partition)으로 나누어질 수 있으며, 파티션은 메시지를 순서대로 저장한다. 파티션을 통해 병렬 처리가 가능하다.
-
예: “user-activity”라는 토픽에 사용자의 활동 로그를 저장할 수 있다.
-
-
파티션(Partition)
-
파티션은 토픽을 물리적으로 나눈 단위로, 각 파티션은 독립적으로 메시지를 저장하고 관리한다.
-
각 파티션은 메시지를 순서대로 저장하며, 파티션 내의 메시지는 고유한 오프셋(offset)으로 식별된다.
-
파티션을 통해 데이터를 병렬로 처리할 수 있으며, 클러스터 내의 여러 브로커에 분산시켜 저장할 수 있다.
-
-
키(Key)
-
키는 메시지를 특정 파티션에 할당하는 데 사용되는 값이다.
-
동일한 키를 가진 메시지는 항상 동일한 파티션에 저장된다.
-
예를 들어, 특정 사용자 ID를 키로 사용하여 해당 사용자의 모든 이벤트가 동일한 파티션에 저장되도록 할 수 있다.
-
-
컨슈머(Consumer)
-
토픽에서 메시지를 가져와 처리하는 역할을 한다.
-
컨슈머는 특정 컨슈머 그룹(consumer group)에 속하며, 같은 그룹에 속한 컨슈머들은 토픽의 파티션을 분산 처리한다.
-
기본적으로 컨슈머는 스티키 파티셔닝(Sticky Partitioning)을 사용한다. 이는 특정 컨슈머가 특정 파티션에 붙어서 계속해서 데이터를 처리하는 방식으로, 이는 데이터 지역성을 높여 캐시 히트율을 증가시키고 전반적인 처리 성능을 향상시킨다.
-
-
브로커(Broker)
-
Kafka 클러스터의 각 서버를 의미하며, 메시지를 저장하고 전송하는 역할을 한다.
-
하나의 Kafka 클러스터는 여러 브로커로 구성될 수 있으며, 각 브로커는 하나 이상의 토픽 파티션을 관리한다.
-
-
주키퍼(Zookeeper)
-
Kafka 클러스터를 관리하고 조정하는 데 사용되는 분산 코디네이션 서비스이다.
-
주키퍼는 브로커의 메타데이터를 저장하고, 브로커 간의 상호작용을 조정한다.
-
실습
Kafka 설치
- 도커 컴포즈를 사용하여 kafka 컨테이너를 생성한다. docker-compose.yml 파일을 생성한다.
version: '3.8' services: zookeeper: image: wurstmeister/zookeeper:3.4.6 platform: linux/amd64 ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 kafka: image: wurstmeister/kafka:latest platform: linux/amd64 ports: - "9092:9092" environment: KAFKA_ADVERTISED_LISTENERS: INSIDE://kafka:29092,OUTSIDE://localhost:9092 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT KAFKA_LISTENERS: INSIDE://0.0.0.0:29092,OUTSIDE://0.0.0.0:9092 KAFKA_INTER_BROKER_LISTENER_NAME: INSIDE KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 volumes: - /var/run/docker.sock:/var/run/docker.sock kafka-ui: image: provectuslabs/kafka-ui:latest platform: linux/amd64 ports: - "8080:8080" environment: KAFKA_CLUSTERS_0_NAME: local KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:29092 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181 KAFKA_CLUSTERS_0_READONLY: "false" - docker-compose.yml 파일이 있는 경로에서 도커 컴포즈를 실행한다.
-
버전 관련으로 에러가 발생할 경우 zookeeper의 image를 wurstmeister/zookeeper:latest로 변경
docker compose up -d
-
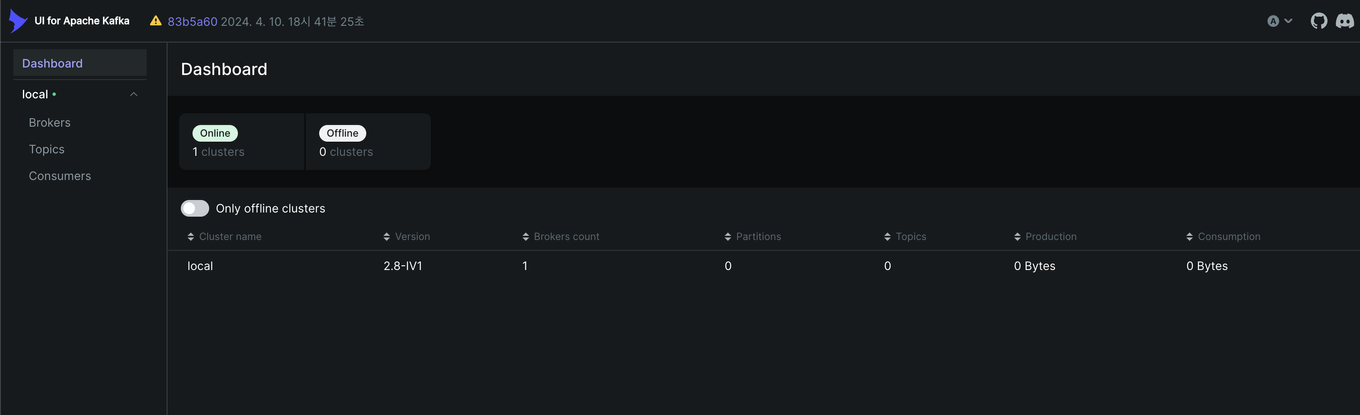
- localhost:8080 에 접속하면 kafka UI 에 접속할 수 있다.
Producer Application
- start.spring.io 에 접속하여 프로젝트를 생성한다.
- application.properties
spring.application.name=producer server.port=8090 spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer - ProducerApplicationKafkaConfig.java
import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.StringSerializer; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.core.DefaultKafkaProducerFactory; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap; import java.util.Map; @Configuration public class ProducerApplicationKafkaConfig { @Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> configProps = new HashMap<>(); configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return new DefaultKafkaProducerFactory<>(configProps); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
- ProducerController.java
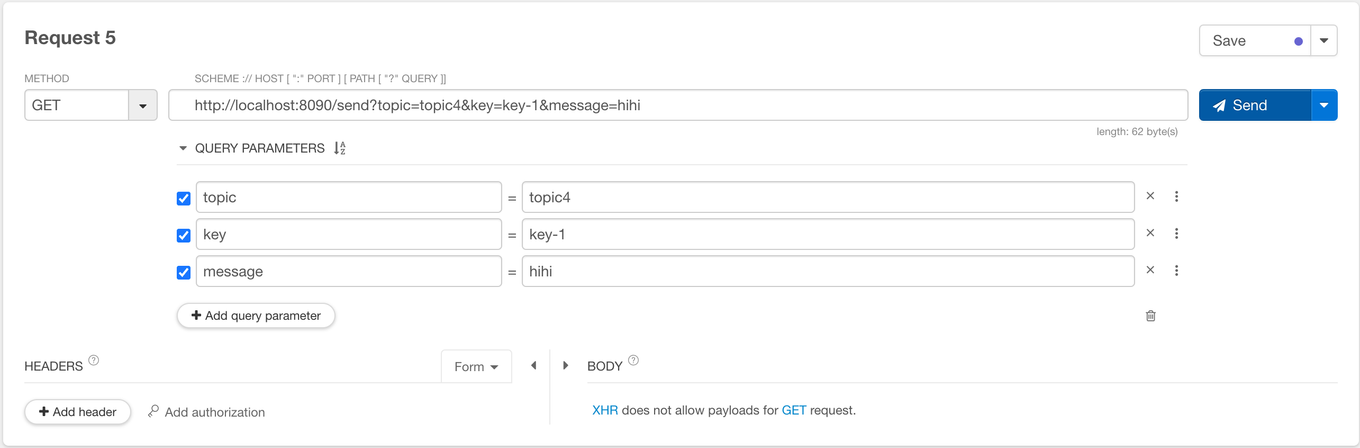
import lombok.RequiredArgsConstructor; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; @RestController @RequiredArgsConstructor public class ProducerController { private final ProducerService producerService; @GetMapping("/send") public String sendMessage(@RequestParam("topic") String topic, @RequestParam("key") String key, @RequestParam("message") String message) { producerService.sendMessage(topic, key, message); return "Message sent to Kafka topic"; } }
- ProducerService.java
import lombok.RequiredArgsConstructor; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Service; @Service @RequiredArgsConstructor public class ProducerService { private final KafkaTemplate<String, String> kafkaTemplate; public void sendMessage(String topic , String key, String message) { for (int i = 0; i < 10; i++) { kafkaTemplate.send(topic, key, message + " " + i); } } }
Consumer Application
- application.properties
spring.application.name=consumer server.port=8091 spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer - ConsumerApplicationKafkaConfig.java
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.StringDeserializer; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import java.util.HashMap; import java.util.Map; // 이 클래스는 Kafka 컨슈머 설정을 위한 Spring 설정 클래스입니다. @EnableKafka // Kafka 리스너를 활성화하는 어노테이션입니다. @Configuration // Spring 설정 클래스로 선언하는 어노테이션입니다. public class ConsumerApplicationKafkaConfig { // Kafka 컨슈머 팩토리를 생성하는 빈을 정의합니다. // ConsumerFactory는 Kafka 컨슈머 인스턴스를 생성하는 데 사용됩니다. // 각 컨슈머는 이 팩토리를 통해 생성된 설정을 기반으로 작동합니다. @Bean public ConsumerFactory<String, String> consumerFactory() { // 컨슈머 팩토리 설정을 위한 맵을 생성합니다. Map<String, Object> configProps = new HashMap<>(); // Kafka 브로커의 주소를 설정합니다. configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // 메시지 키의 디시리얼라이저 클래스를 설정합니다. configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 메시지 값의 디시리얼라이저 클래스를 설정합니다. configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); // 설정된 프로퍼티로 DefaultKafkaConsumerFactory를 생성하여 반환합니다. return new DefaultKafkaConsumerFactory<>(configProps); } // Kafka 리스너 컨테이너 팩토리를 생성하는 빈을 정의합니다. // ConcurrentKafkaListenerContainerFactory는 Kafka 메시지를 비동기적으로 수신하는 리스너 컨테이너를 생성하는 데 사용됩니다. // 이 팩토리는 @KafkaListener 어노테이션이 붙은 메서드들을 실행할 컨테이너를 제공합니다. @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { // ConcurrentKafkaListenerContainerFactory를 생성합니다. ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); // 컨슈머 팩토리를 리스너 컨테이너 팩토리에 설정합니다. factory.setConsumerFactory(consumerFactory()); // 설정된 리스너 컨테이너 팩토리를 반환합니다. return factory; } }
- ConsumerService.java
import lombok.extern.slf4j.Slf4j; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Service; @Slf4j @Service public class ConsumerService { // 이 메서드는 Kafka에서 메시지를 소비하는 리스너 메서드입니다. // @KafkaListener 어노테이션은 이 메서드를 Kafka 리스너로 설정합니다. @KafkaListener(groupId = "group_a", topics = "topic1") // Kafka 토픽 "test-topic"에서 메시지를 수신하면 이 메서드가 호출됩니다. // groupId는 컨슈머 그룹을 지정하여 동일한 그룹에 속한 다른 컨슈머와 메시지를 분배받습니다. public void consumeFromGroupA(String message) { log.info("Group A consumed message from topic1: " + message); } // 동일한 토픽을 다른 그룹 ID로 소비하는 또 다른 리스너 메서드입니다. @KafkaListener(groupId = "group_b", topics = "topic1") public void consumeFromGroupB(String message) { log.info("Group B consumed message from topic1: " + message); } // 다른 토픽을 다른 그룹 ID로 소비하는 리스너 메서드입니다. @KafkaListener(groupId = "group_c", topics = "topic2") public void consumeFromTopicC(String message) { log.info("Group C consumed message from topic2: " + message); } // 다른 토픽을 다른 그룹 ID로 소비하는 리스너 메서드입니다. @KafkaListener(groupId = "group_c", topics = "topic3") public void consumeFromTopicD(String message) { log.info("Group C consumed message from topic3: " + message); } @KafkaListener(groupId = "group_d", topics = "topic4") public void consumeFromPartition0(String message) { log.info("Group D consumed message from topic4: " + message); } }
확인
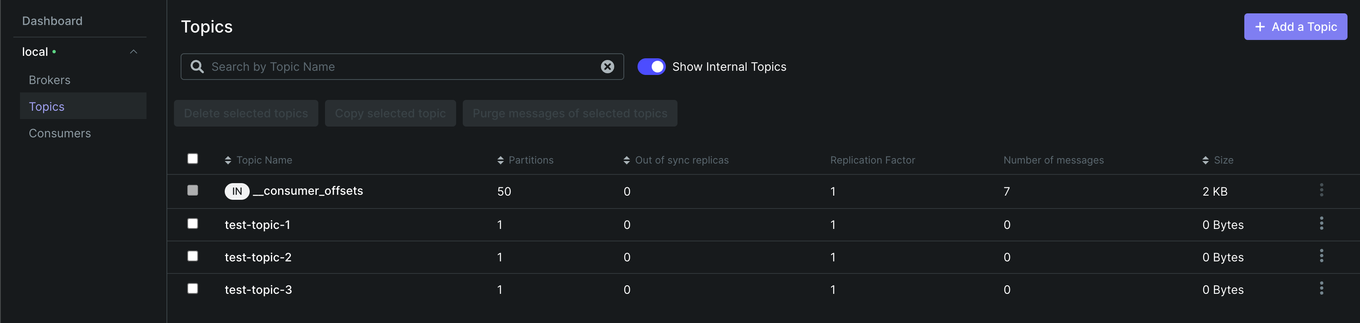
- 두 애플리케이션을 실행하고 Kafka ui 를 확인한다. Topic 탭과 Comsumers 탭을 확인한다.

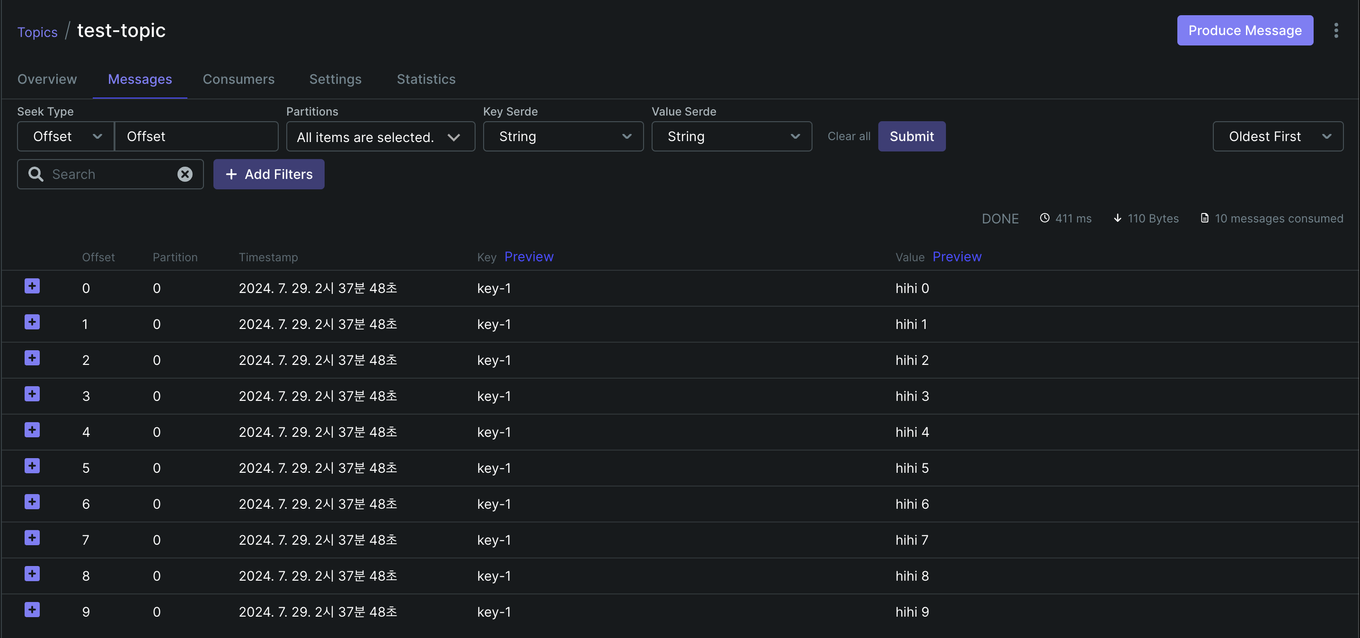
- topic 을 test-topic 으로 지정하고 요청해보자. kafka ui > Topics > Messages 에 접속하면 방금 요청한 토픽으로 발행된 메시지를 볼 수 있다.
- topic 을 topic1 으로 지정하고 요청해보자. 컨슈머 애플리케이션의 로그를 보면 GroupA 와 GroupB가 메시지를 수신한 것을 볼 수 있다. 따라서 같은 토픽을 가지고 그룹이 다르면 메시지를 각 그룹마다 수신한다는 것을 알 수 있다.
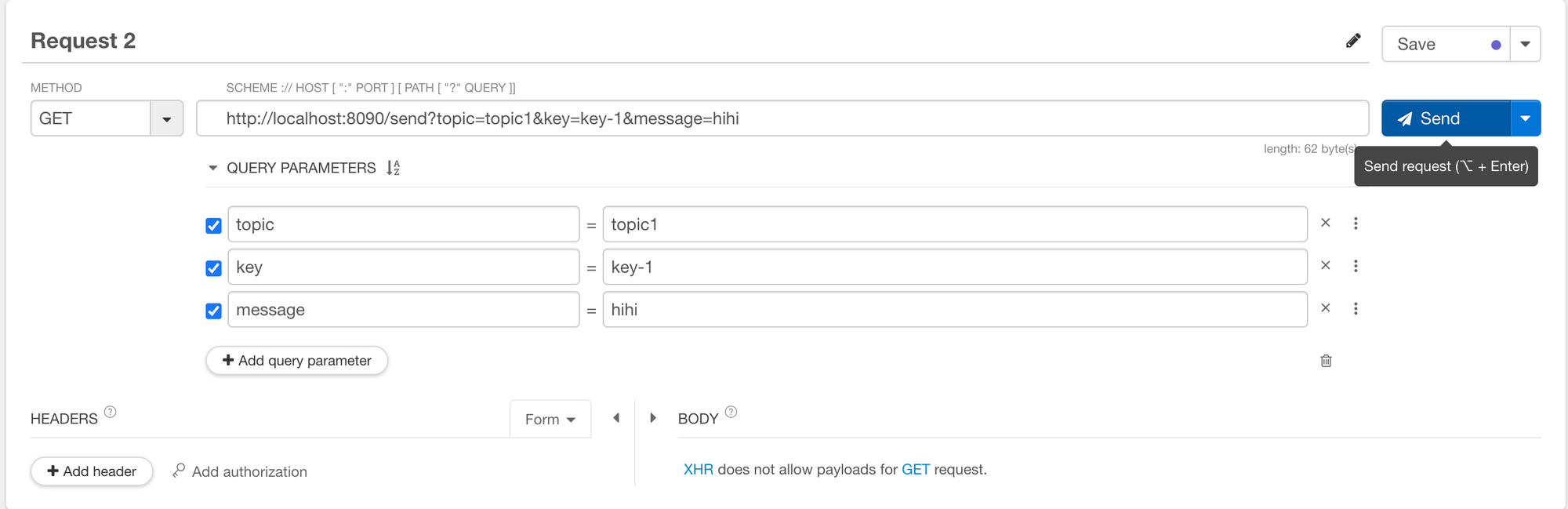
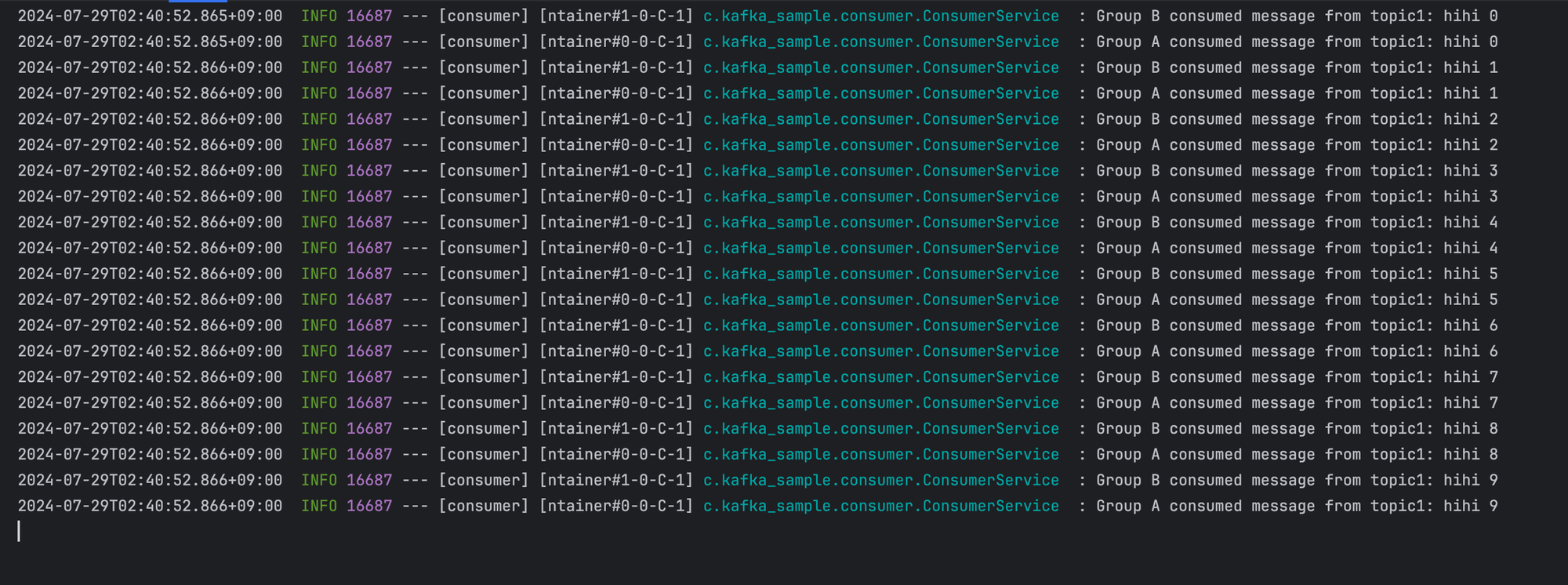
- topic 을 topic2 으로 지정하고 요청해보자. 컨슈머 애플리케이션의 로그를 보면 GroupC이고 topic 이 2 인 리스너가 메시지를 수신한 것을 볼 수 있다.
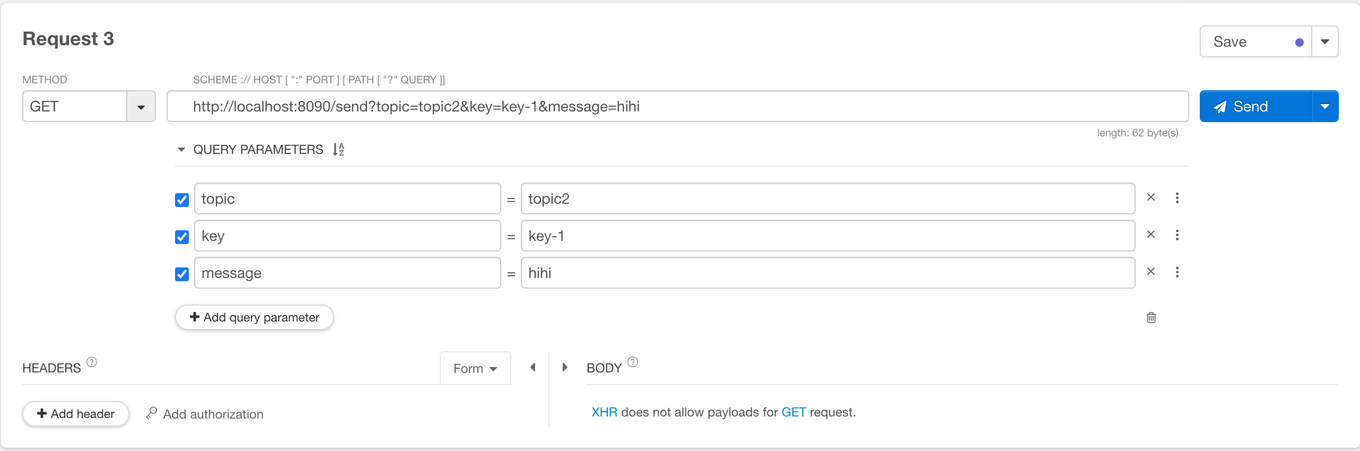

- topic 을 topic3 으로 지정하고 요청해보자. 컨슈머 애플리케이션의 로그를 보면 GroupC이고 topic 이 3 인 리스너가 메시지를 수신한 것을 볼 수 있다.

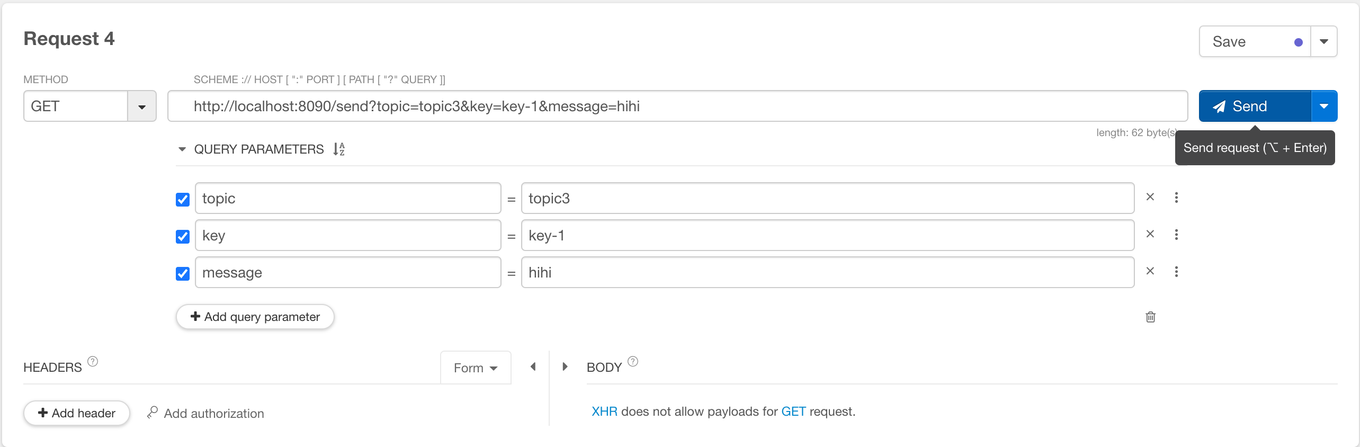
- topic 을 topic4 으로 지정하고 요청해보자. 컨슈머 애플리케이션의 로그를 보면 GroupD이고 topic 이 4 인 리스너가 메시지를 수신한 것을 볼 수 있다.