‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/1706.03762
Title
- Attention Is All You Need
->Attention이 전부다.
Abstract
-
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder.
-> 주요 시퀀스 변환 모델들은 인코더와 디코더를 포함하는 복잡한 순환 신경망(RNN) 또는 합성곱 신경망(CNN)에 기반한다 -
The best performing models also connect the encoder and decoder through an attention mechanism.
-> 최고의 성능을 자랑하는 모델도 인코더와 디코더를 attention 매커니즘으로 연결한다. -
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
-> 우리는 순환 구조와 합성곱 연산을 완전히 배제하고, 오직 attention 메커니즘에 기반한 새롭고 간단한 네트워크 구조인Transformer를 제안한다. -
Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
-> 두 가지 기계 번역 과제에 대한 실험 결과, 이 모델들은 품질 면에서 우수할 뿐 아니라 병렬 처리 가능성이 더 높고 훈련 시간도 현저히 적게 소요되는 것으로 나타났다 -
Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU.
-> 우리 모델은 WMT 2014 영-독 번역 과제에서 28.4 BLEU* 점수를 달성했으며, 이는 앙상블 모델을 포함한 기존 최고 기록보다 2 BLEU 점수 이상 향상된 수치다.- BLEU(Bilingual Evaluation Understudy) :
- BLEU는 기계 번역 시스템의 품질을 평가하는 자동화된 지표로, 0~1(또는 0~100%) 범위로 점수를 매긴다.
- 핵심 원리는 기계가 생성한 번역문과 인간이 작성한 참조 번역문의 n-gram 일치율을 계산하는 것
- BLEU(Bilingual Evaluation Understudy) :
- On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature.
-> WMT 2014 영-프 번역 과제에서 우리 모델은 8개의 GPU로 3.5일간 훈련 후 41.8 BLEU 점수라는 단일 모델 기준 SOTA 기록을 수립했으며, 이는 기존 문헌상 최고 모델들의 훈련 비용에 비해 극히 일부에 불과하다.
- We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
-> 우리는 트랜스포머가 대량의 훈련 데이터와 제한된 훈련 데이터 모두에서 영어 구성 성분 구문 분석에 성공적으로 적용됨으로써 다른 과제에도 일반화됨을 보여준다.
Figures
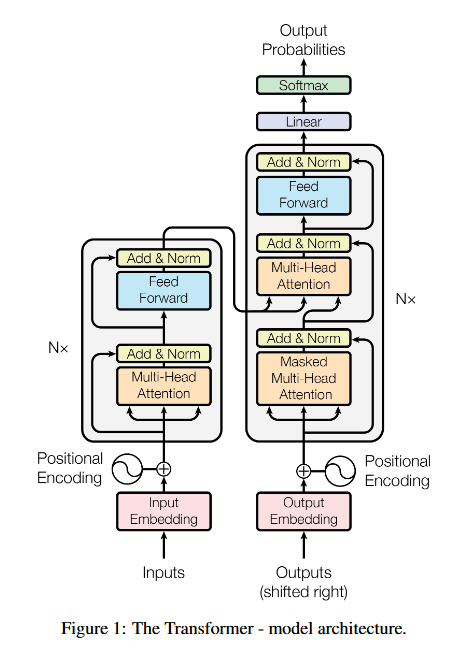
01. 작동 원리
- 인코더-디코더 구조
- 인코더는 입력 시퀀스 (x₁, ..., xₙ)를 연속적 표현 z = (z₁, ..., zₙ)로 매핑한다.
- 디코더는 z를 받아 출력 시퀀스 (y₁, ..., yₘ)를 한 번에 하나의 요소씩 생성한다.
- 각 단계에서 모델은 자기회귀적이며, 다음 출력을 생성할 때 이전에 생성된 심볼을 추가 입력으로 활용한다.
- 트랜스포머는 이 기본 구조를 따르되, 인코더와 디코더에 다층 셀프 어텐션과 위치별 완전 연결 계층을 사용한다.
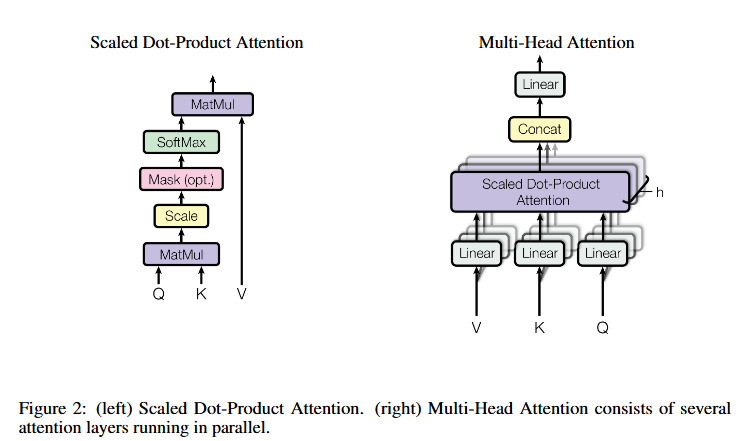
02. Attention
-
Scaled Dot-Product Attention
- Query(Q), Key(K), Value(V) 행렬 연산
- √dₖ(dₖ: 키 벡터 차원)로 스케일링 → 그래디언트 폭주 방지
- 단일 헤드에서의 기본 어텐션 메커니즘
-
Multi-Head Attention
- h개의 독립적 어텐션 헤드 병렬 운영(h=8)
- 각 헤드는 서로 다른 attention(Qᵢ,Kᵢ,Vᵢ) 계산