‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2005.11401
Title
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
-> 지식 집약적 NLP 작업을 위한 RAG(검색 증강 생성)
Abstract
-
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks.
-> 사전 학습 언어 모델은 매개변수에 사실적 지식을 저장할 수 있고, 하위 NLP 작업에 대해 파인튜닝 되었을 때 최고의 성능을 달성하는 것을 보여줬다. -
However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures.
-> 그러나, 모델이 지식에 접근하고 정확하게 조정하는 능력은 여전히 제한적이다. 지식 집약적 작업에 대해 언어 모델의 성능은 해당 작업에 특화된 아키텍쳐에 비해 뒤쳐진다. -
Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems.
-> 추가로, 모델의 결정에 대한 근거를 제공하고 지식을 업데이트하는 것은 여전히 해결되지 않은 연구 과제로 남아있다. -
Pretrained models with a differentiable access mechanism to explicit non-parametric memory have so far been only investigated for extractive downstream tasks.
-> 명시적 비매개변수 메모리에 대한 차별적인 접근 메커니즘을 갖춘 사전 학습 모델은 추출형 다운스트림 작업(데이터 추출, 정보 검색 등)에 대해서만 연구되었다. -
We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained parametric and non-parametric memory for language generation.
-> 우리는 RAG(언어 생성을 위한 사전 학습 매개변수적 메모리와 비매개변수적 메모리가 결합된 모델)를 위한 범용적인 파인튜닝 방법을 탐구한다. -
We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
-> 우리는 RAG 모델(매개변수적 메모리로 사전학습된 seq2seq 모델, 비매개변수 메모리로는 위키백과의 밀집 벡터 인덱스를 사용)을 소개한다. 여기서 비매개변수적 메모리는 사전 학습된 신경망 검색기를 통해 접근한다. -
We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, and another which can use different passages per token.
-> 우리는 두 RAG 구성을 비교한다. 하나는 동일한 구절(passage)을 사용하는 것이고, 다른 하나는 토큰별로 다른 구절을 사용하는 것이다. -
We fine-tune and evaluate our models on a wide range of knowledgeintensive NLP tasks and set the state of the art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures.
-> 우리는 모델을 넓은 범위의 지식 집약적인 NLP 작업에서 파인튜닝과 평가를 진행하고, 세가지 오픈 도메인 QA 작업에서 최신 성능을 달성했다. 이는 매개변수적 seq2seq 모델, 업무에 특화된 검색-추출 아키텍처를 능가하는 수준이다. -
For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
-> 언어 생성 작업에서 RAG 모델이 최신 매개변수 기반 seq2seq 모델보다 더 구체적이고 다양하고 사실적인 언어를 생성하는 것을 확인했다.
Figures
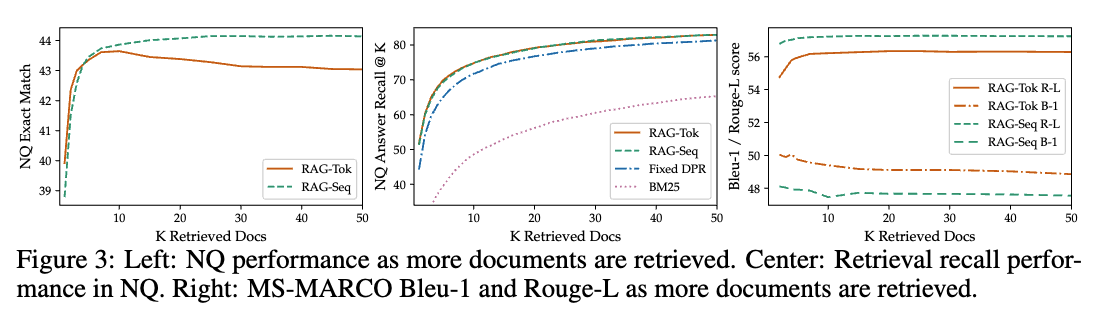
01. 접근 방식 개요
- 사전 학습된 검색기(Query Encoder + Document Index)와 사전 학습된 seq2seq2 모델(Generator)를 결합하고 한번에 파인튜닝한다.
- 쿼리 x 에 대해 최대 내적 탐색(MIPS)을 사용하여 상위 K개의 문서 z를 찾는다.
- 내적 값이 클수록 유사도 높음
- 최종 예측 y를 위해, z를 잠재 변수(latent variable)로 간주하고, 서로 다른 문서가 주어진 상태에서 seq2seq 예측을 주변화(marginalize)한다.
- 잠재 변수 : 관찰되지 않은 변수(hidden) -> 최종 예측에 영향을 미치는 숨겨진 요인으로 작용함
- 주변화 : 특정 변수 하나에 대한 확률값 추정을 위해 나머지 변수를 모두 적분(확률을 합산 or 평균)하여 제거하는 방법(=주변 변수화 한다)
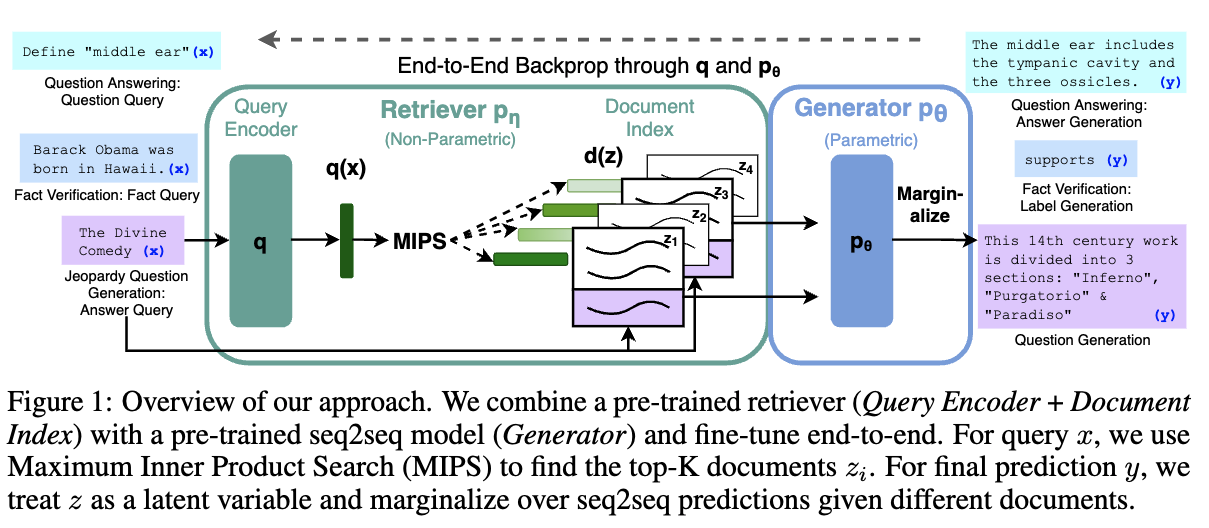
02. RAG-Token 모델의 문서 사후 확률 활용 방식
- Jeopardy 문제를 위해 '헤밍웨이'를 입력하여 검색된 상위 연관 5개 문서로 생성된 각각의 RAG-토큰 문서 사후 확률을 계산함.
- 특정 문서가 해당 토큰 생성에 얼마나 관련성이 있는지 계산
- 문서 1은 'A Farewell to Arms'를 생성할 때 사후 확률이 높았고, 문서 2는 'The Sun Also Rises'를 생성할 때 사후 확률이 높았음.
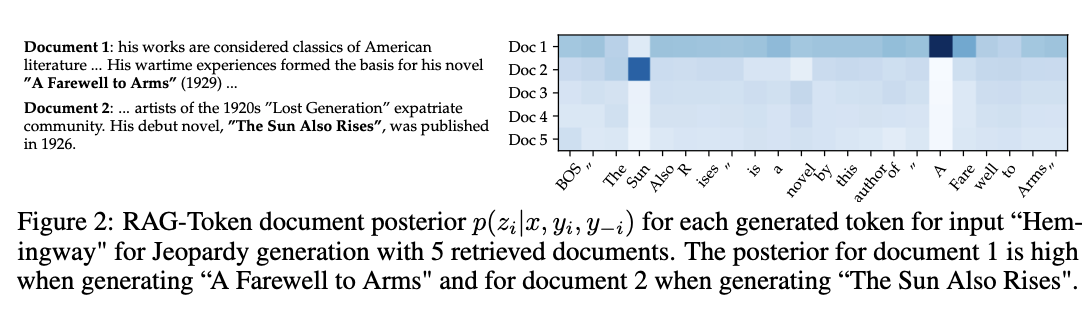
03. 모델 성능 비교
- 왼쪽 : 두 모델의 NQ(Natural Question) 성능 비교(생성 문서 수에 따른)
- 가운데 : 모델별 검색 재현율 성능 비교
- 재현율 : 모델 양성 예측 비율 / 실제 양성 비율
- 오른쪽 : 모델별 MS-MARCO의 Bleu-1 및 Rouge-L 값 비교(생성 문서 수에 따른)