‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2310.11511
Self-RAG: 검색, 생성, 그리고 비평을 학습하는 방법
- SELF-RAG는 검색과 자기 성찰을 통해 대형 언어 모델(LLM)의 품질과 사실성을 향상시키면서도, LLM 고유의 창의성과 유연성을 희생하지 않는 프레임워크이다.
- 우리의 end-to-end 학습 방식은 필요에 따라 검색된 지문을 참고하여 텍스트를 생성하고, 특수 토큰을 생성하는 방법을 학습하여 출력 결과를 비평하도록 한다.
- 이러한 반성 토큰(Table 1)은 검색 필요성을 알리거나 출력의 관련성, 지원 여부, 완전성을 확인하는 역할을 한다.
- 반면, 일반적인 RAG 접근법은 인용된 출처로부터 완전한 지원을 보장하지 않고 무차별적으로 지문을 검색한다.

개요
- 공식적으로, 입력 x가 주어지면, 우리는 M이 여러 세그먼트로 구성된 텍스트 출력 y = [y1, ..., yT]를 순차적으로 생성하도록 훈련시킨다. 여기서 yt는 t번째 세그먼트의 토큰 시퀀스를 의미한다.
- yt에 생성되는 토큰에는 기존 어휘의 텍스트와 반성 토큰(reflection tokens, Table 1 참조)이 모두 포함된다.
추론 과정 개요
-
입력 프롬프트 x와 이전 생성 결과 y<t가 주어질 때마다, 모델은 검색이 필요한지 여부를 판단하기 위해 retrieval token(검색 토큰)을 디코딩한다.
-
만약 검색이 필요 없다고 판단되면, 표준 언어 모델(LM)처럼 다음 출력 세그먼트를 예측한다.
-
만약 검색이 필요하다고 판단되면, 모델은 다음과 같은 과정을 수행한다:
- 검색된 지문의 관련성을 평가하는 critique token(비평 토큰)을 생성
- 다음 응답 세그먼트를 생성
- 응답 세그먼트의 정보가 지문에 의해 지원되는지 평가하는 critique token을 생성
- 마지막으로, 응답의 전체 유용성을 평가하는 새로운 critique token을 생성
-
각 세그먼트를 생성할 때, SELF-RAG는 여러 지문을 병렬로 처리하며, 자체적으로 생성한 반성 토큰(reflection tokens)을 사용해 생성된 작업 출력에 대해 soft constraint(연성 제약, 섹션 3.3) 또는 hard control(강성 제어, Algorithm 1)을 적용한다.
-
예를 들어, Figure 1(오른쪽)에서 첫 번째 시간 단계에서는 검색된 지문 d1이 선택된다. 이는 d2는 직접적인 증거를 제공하지 않아(
ISREL: 관련성 없음), d3는 부분적으로만 지원되지만, d1은 완전히 지원되기 때문이다.
학습 과정 개요
-
SELF-RAG는 임의의 언어 모델(LM)이 반성 토큰(reflection tokens)을 포함한 텍스트를 생성할 수 있도록, 반성 토큰을 확장된 모델 어휘(즉, 기존 어휘 + 반성 토큰)의 일부로 통합하여 다음 토큰 예측 대상으로 삼는다.
-
구체적으로, 생성기 모델 M은 검색기 R이 검색한 지문과 비평가 모델 C가 예측한 반성 토큰이 교차된(interleaving) 정제된 말뭉치로 훈련된다(부록 Algorithm 2 요약).
-
비평가 모델 C는 검색된 지문과 주어진 작업 출력의 품질을 평가하는 반성 토큰을 생성하도록 훈련된다(섹션 3.2.1).
-
비평가 모델을 활용하여, 작업 출력에 반성 토큰을 오프라인으로 삽입하여 학습 데이터를 업데이트한다.
-
이후, 최종 생성기 모델(M)은 표준 언어 모델 목표(섹션 3.2.2)로 훈련되어, 추론 시에는 비평가 모델에 의존하지 않고 스스로 반성 토큰을 생성할 수 있게 된다.
학습
01. Critic model 학습
Critic 모델 데이터 수집
- 각 세그먼트에 대한 반성 토큰(reflection tokens)을 수작업으로 주석 처리하는 것은 비용이 많이 든다.
- GPT-4 같은 상용 LLM에 의존하면 API 비용이 증가하고 재현성이 떨어질 수 있다.
- 우리는 GPT-4를 활용해 반성 토큰을 생성하도록 유도하여 지도학습 데이터를 만들고, 그 지식을 내부 비평가 모델(C)에 전달(지식 증류)한다.
- 각 반성 토큰 그룹마다 원래 학습 데이터에서 무작위로 샘플을 선택한다: {Xsample, Y sample} ∼ {X, Y }.
- 각 반성 토큰 그룹은 고유의 정의와 입력 구조를 가지므로, 각각에 맞는 지시 프롬프트를 사용한다.
- GPT-4에 유형별 지시(“주어진 지시에 대해, 외부 웹 문서를 찾는 것이 더 나은 응답을 생성하는 데 도움이 되는지 판단하라.”)를 입력하고, 몇 가지 예시(few-shot demonstrations)와 원래 작업 입력 x, 출력 y를 함께 주어 적절한 반성 토큰을 텍스트로 예측하도록 한다: p(r|I, x, y).
- 수작업 평가 결과, GPT-4가 예측한 반성 토큰은 인간 평가와 높은 일치도를 보인다.
각 유형별로 4천~2만 개의 지도학습 데이터를 수집하여, 이를 모두 합쳐 C의 학습 데이터로 사용한다.
Critic 모델 학습
-
비평가 학습 데이터 Dcritic를 수집한 후, 비평가 모델 C를 사전 학습된 언어 모델로 초기화하고, Dcritic를 이용해 표준 조건부 언어 모델링 목표(즉, 가능도 최대화)로 학습한다.
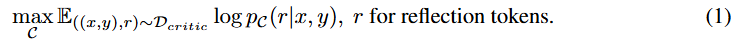
-
여기서 r은 반성 토큰(reflection tokens)이다.
-
초기 모델로는 임의의 사전 학습 LM을 사용할 수 있지만, 본 연구에서는 생성기 LM과 동일한 모델(즉, Llama 2-7B; Touvron et al. 2023)을 C의 초기화에 사용한다.
-
학습된 비평가 모델 C는 대부분의 반성 토큰 범주에서 GPT-4 기반 예측과 90% 이상 일치하는 높은 정확도를 보인다.
02. 생성 모델 학습
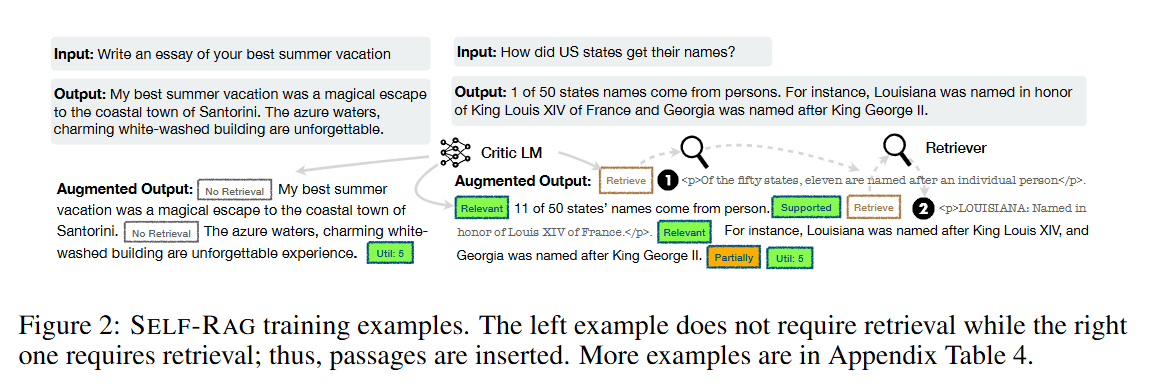
생성기 모델 데이터 수집(Figure 2)
- 입력-출력 쌍 (x, y)이 주어지면, 검색기(retriever)와 비평가(critic) 모델을 활용해 원래의 출력 y를 보강하여, SELF-RAG의 실제 추론 과정을 정확히 모방하는 지도학습 데이터를 만든다.
- 각 세그먼트 yt ∈ y마다, 비평가 모델 C를 실행해 추가 지문이 생성에 도움이 되는지 평가한다.
- 만약 검색이 필요하다고 판단되면,
Retrieve=Yes라는 특수 토큰이 추가되고, 검색기 R이 상위 K개의 지문 D를 검색한다. - 각 지문에 대해, 비평가 모델 C는 해당 지문이 관련성이 있는지 평가하고
ISREL을 예측한다. - 지문이 관련성이 있다면, C는 해당 지문이 모델의 생성 결과를 실제로 지원하는지 평가하여
ISSUP를 예측한다. - 비평 토큰(
ISREL,ISSUP)은 검색된 지문 또는 생성 결과 뒤에 추가된다. - 출력의 마지막(y 또는 yT)에서, C는 전체 유용성 토큰 ISUSE를 예측한다.
- 반성 토큰이 추가된 보강된 출력과 원래 입력 쌍이 생성기 학습 데이터 Dgen에 추가된다.
생성기 모델 학습
- 생성기 모델 M은 반성 토큰이 추가된 정제된 말뭉치 Dgen을 사용해 표준적인 다음 토큰 예측 목표로 훈련된다.
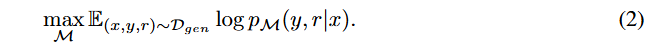
- 비평가 모델 C의 학습(식 1)과 달리, 생성기 모델 M은 목표 출력(y)과 반성 토큰(r) 모두를 예측하는 방법을 학습한다.(식 1에서는 r만 예측)
- 학습 과정에서, 검색된 텍스트 조각(
<p>와</p>로 감싸진 부분, Figure 2 참고)은 손실(loss) 계산 시 마스킹(무시)된다. - 또한, 기존 어휘 V에 반성 토큰 집합 {Critique, Retrieve}를 추가하여 어휘를 확장한다.
03. Self-RAG 추론
- 자신의 출력을 평가하기 위해 반성 토큰(reflection tokens)을 생성하는 것은 SELF-RAG가 추론 단계에서 제어 가능하도록 만들어, 다양한 작업 요구에 맞춰 행동을 조정할 수 있게 한다.
- 사실 정확성(factual accuracy)이 요구되는 작업(Min et al., 2023)에서는, 모델이 더 자주 지문을 검색하여 출력이 이용 가능한 증거와 밀접하게 일치하도록 한다.
- 반대로, 개인 경험 에세이 작성과 같은 보다 자유로운(open-ended) 작업에서는, 검색 빈도를 줄이고 전체적인 창의성이나 유용성 점수에 더 중점을 둔다.
- 임계값을 활용한 적응형 검색.
- SELF-RAG는 Retrieve(검색 필요 여부) 토큰을 예측함으로써 언제 텍스트 지문을 검색할지 동적으로 결정한다.
- 또한, 본 프레임워크는 임계값(threshold)을 설정할 수 있도록 한다.
- 구체적으로, Retrieve 토큰 집합 내 모든 출력 토큰에 대해 정규화된
Retrieve=Yes토큰의 생성 확률이 지정된 임계값을 넘으면 검색이 트리거된다.
- 비평 토큰을 활용한 트리 디코딩
- 각 세그먼트 단계 t에서, 검색이 필요하다고 판단되면(이 조건은 hard 또는 soft 제약에 따라 달라짐), 검색기 R이 K개의 지문을 가져오고, 생성기 M은 각 지문을 병렬로 처리하여 K개의 후속 생성 후보를 만든다.
- 세그먼트 단위 빔 서치(beam size=B)를 수행하여 각 시간 단계 t마다 상위 B개의 세그먼트 후속 문장을 얻고, 최종적으로 가장 좋은 시퀀스를 반환한다.
- 각 세그먼트 yt와 지문 d에 대한 점수는 비평가 점수 S를 더해 업데이트된다.
- 점수 S는 각 비평 토큰 유형(예:
ISREL,ISSUP,ISUSE)의 정규화된 생성 확률의 가중 합(linear weighted sum)이다.
- 점수 S는 각 비평 토큰 유형(예:
- 각 비평 토큰 그룹 G(예:
ISREL)에 대해, t 시점의 점수 sG_t는 해당 그룹에서 가장 바람직한 반성 토큰(예:ISREL=Relevant)의 생성 확률을, 해당 그룹의 모든 토큰의 생성 확률 합으로 나눈 값이다.- 여기서 wG는 추론 시점에 조정 가능한 하이퍼파라미터로, 사용자의 요구에 따라 모델의 행동을 맞춤화할 수 있다.
- 예를 들어, 결과 y가 증거에 의해 충분히 뒷받침되도록 하려면
ISSUP점수의 가중치를 높이고, 다른 점수의 가중치는 낮출 수 있다. - 또는, soft한 보상 함수 대신 hard 제약을 적용하여, 원치 않는 비평 토큰(예:
ISSUP=No support)이 생성되면 해당 세그먼트 후속 문장을 아예 필터링할 수도 있다.
- 여러 선호도 간의 균형은 RLHF 등에서 연구되어 왔으나, SELF-RAG는 추가적인 학습 없이도 모델의 행동을 맞춤화할 수 있다.

