‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2310.11511
Experiments
01. Tasks & Datasets
-
SELF-RAG와 다양한 베이스라인 모델을 여러 다운스트림 과제에서 평가하였다.
-
평가에는 전체적인 정답률, 사실성, 유창성을 측정하는 지표들을 사용하였다.
-
모든 실험은 zero-shot 방식으로 진행되었다.
-
폐쇄형(closed-set) 과제
- 데이터셋 1. 공중보건 관련 사실 검증 데이터셋인 PubHealth(Zhang et al., 2023)
- 데이터셋 2. 과학 시험에서 출제된 객관식 추론 데이터셋인 ARC-Challenge(Clark et al., 2018)
- 두 데이터셋 모두 평가 지표로 정확도(accuracy)를 사용하며, 테스트 세트 결과를 보고한다.
- 정답 후보 클래스별 확률은 두 데이터셋 모두에서 합산하여 사용한다.
-
단답형 생성(short-form generation) 과제
- PopQA : 1,399개의 희귀 엔티티 쿼리(월간 위키피디아 조회수 100 미만)로 구성된 롱테일 서브셋을 사용한다.
- TriviaQA-unfiltered : 공개된 테스트 세트가 없어 이전 연구들의 검증 및 테스트 분할을 따라 11,313개의 테스트 쿼리를 평가에 사용한다.
- 평가 기준은 모델 생성 답변에 정답이 포함되어 있는지를 기준으로 하며, 엄격한 정답 일치(exact matching)를 요구하지 않는다.
-
장문 생성(long-form generation) 과제
- 전기 생성(Biography) : FactScore를 사용
- 장문 QA(ASQA)는 정확성(str-em), MAUVE 기반 유창성, 인용 정확도 및 재현율 지표를 사용
02. Baselines
-
검색 미사용 베이스라인
- 공개 사전학습 LLM: Llama2-7B, 13B
- 지시 튜닝 모델: Alpaca-7B, 13B (Llama2 기반 자체 재현)
- 사설 데이터로 학습 및 강화된 모델: ChatGPT, Llama2-chat13B
- 지시 튜닝 LM의 경우, 공개된 경우 공식 시스템 프롬프트 또는 학습에 사용된 지시문 포맷을 그대로 사용
- CoVE65B: 반복적 프롬프트 엔지니어링을 도입해 LLM 생성 사실성을 개선한 동시 연구 모델과도 비교
-
검색 활용 베이스라인
- 테스트 또는 학습 단계에서 검색을 결합한 모델 평가
- 표준 RAG: Llama2, Alpaca 등 LM이 쿼리와 함께 상위 검색 문서를 입력받아 답변 생성
- Llama2-FT: 검색 문서나 반성 토큰 없이 전체 학습 데이터로 파인튜닝한 Llama2
- 사설 데이터 기반 검색 결합 모델: Ret-ChatGPT, Ret-Llama2-chat, perplexity.ai(InstructGPT 기반 프로덕션 검색 시스템)
- 검색 문서로 함께 학습된 동시 연구 방법:
- SAIL: Alpaca 지시 튜닝 데이터에 상위 검색 문서를 삽입해 LM 튜닝
- Toolformer: API 호출(예: 위키피디아 API)로 LM 사전학습
03. Experimental settings
-
학습 데이터:
- 다양한 지시(instruction)를 따르는 입력-출력 쌍으로 구성됨.
- Open-Instruct 가공 데이터(Wang et al., 2023)와 지식 집약적 데이터셋(Petroni et al., 2021; Stelmakh et al., 2022; Mihaylov et al., 2018)에서 샘플링함.(총 15만 개의 instruction-output 쌍을 사용)
-
모델 설정:
- 생성기(Generator) LM: Llama2 7B, 13B
- 비평기(Critic) LM: Llama2 7B
- 검색기(Retriever) 모델: Contriever-MS MARCO(기성 모델)
- 각 입력에 대해 최대 10개의 문서를 검색
-
추론
ISREL(관련성),ISSUP(지원 여부),ISUSE(완전성) 가중치는 각각 1.0, 1.0, 0.5로 설정한다.- 검색 빈도를 높이기 위해 대부분의 과제에서 검색 임계값을 0.2로, 인용이 필수적인 ALCE 과제에서는 0으로 설정한다.
- 추론 속도 향상을 위해 vllm을 사용한다.
- 각 세그먼트별로 beam width는 2로 설정하고, 토큰 단위 생성에는 greedy decoding을 적용한다.
- Contriever-MS MARCO에서 상위 5개 문서를 기본적으로 사용하며, 전기 생성 및 오픈 도메인 QA에서는 웹 검색 엔진을 통해 추가로 5개 문서를 더 활용한다.
- ASQA 과제에서는 모든 베이스라인에서 GTR-XXL로 저자가 제공한 상위 5개 문서를 사용해 공정성을 확보한다.
Results And Analysis
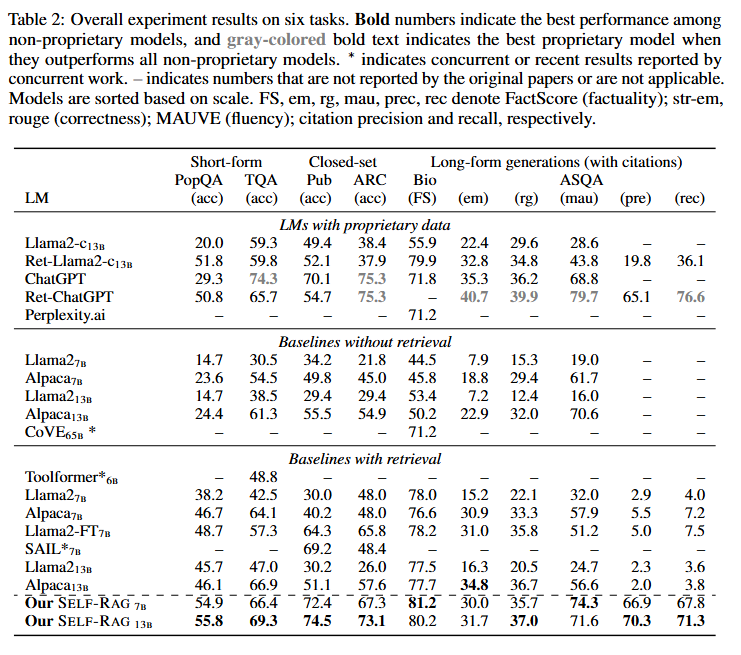
- Table 2 실험 결과 요약
Bold체: 비상용 모델 중 최고 성능회색 Bold체: 상용 모델이 비상용 모델을 능가한 경우∗: 동시 또는 최근 연구 결과, –는 미보고 또는 해당 없음.- 평가지표:
- acc: 정확도(Accuracy)
- FS: FactScore(사실성)
- em: str-em(정확성)
- rg: rouge(정확성)
- mau: MAUVE(유창성)
- pre/rec: 인용 정밀도/재현율
- Baselines without Retrieval 결과
SELF-RAG는 검색을 사용하지 않은 기존 강력한 베이스라인 및 최신 프롬프트 엔지니어링 기반 접근법보다도 전반적으로 높은 성능을 입증했다.
- Baselines with Retrieval 결과
SELF-RAG는 기존 RAG 및 다양한 검색 기반 베이스라인 대비 사실성, 인용 정확도, 전반적 성능에서 일관된 우위를 입증했다.
Analysis
Ablation 실험 결과
-
실험 목적
SELF-RAG 프레임워크의 성능에 기여하는 핵심 요소를 식별하기 위해 다양한 ablation(구성요소 제거) 실험을 수행하였다. -
실험 방법 및 변형 모델
- No Retriever: 검색 문서 없이, 일반적인 instruction-output 쌍만으로 LM을 학습.
- No Critic: 항상 상위 1개 검색 문서만 추가하고, 반영(critique) 토큰 없이 학습. SAIL 방식과 유사.
- No retrieval (추론 시): 추론 단계에서 검색을 비활성화.
- Hard constraints: 적응 임계값 대신, Retrieve=Yes일 때만 검색을 수행.
- Retrieve top 1: 항상 상위 1개 문서만 사용(표준 RAG와 유사).
- Remove
ISSUP: critique-guided beam search에서 ISSUP 점수만 제거.
-
실험 세부사항
- 학습 데이터 5만 개로 실험(효율성 고려).
- PopQA, PubHealth, ASQA 세 데이터셋에서 ablation 수행.
- ASQA는 샘플 150개 사용, 적응/비검색 관련 ablation은 제외.
-
주요 결과 (Table 3a 기반)
- 모든 구성요소가 성능에 중요한 역할을 함을 확인.
- No Retriever, No Critic: SELF-RAG와 큰 성능 차이. 즉, 검색과 비평(critic) 기반 학습이 SELF-RAG의 성능 향상에 크게 기여함을 입증.
- Retrieve top 1: 단순히 상위 1개 문서만 사용하는 방식(표준 RAG)은 PopQA, ASQA에서 성능이 크게 하락.
- Remove
ISSUP: critique-guided beam search에서 ISSUP 점수를 제거하면 ASQA 성능이 저하됨.
-
결론: SELF-RAG는 단순 검색 결과 활용이나 relevance 점수만 의존하는 방식보다, 세밀한 다중 기준(critique, support 등)에 기반한 생성 선택이 훨씬 효과적임을 보여줌.
추론 단계 커스터마이징 효과
SELF-RAG 프레임워크의 주요 장점 중 하나는, 다양한 critique(비평) 유형이 최종 생성 샘플링에 미치는 영향을 사용자가 직접 조절할 수 있다는 점이다.
-
실험 내용
- 7B 모델을 기준으로, ASQA 과제에서 추론 시 ISSUP(생성 결과가 근거 문서로부터 얼마나 잘 뒷받침되는지 평가)의 가중치를 조절하여 결과를 분석함.
- 여러 평가 기준(정확성, 유창성, 인용 정밀도 등)에 미치는 영향을 비교.
-
주요 결과
ISSUP가중치 증가- 인용 정밀도(citation precision)가 향상됨.
- 근거 문서에 의해 충분히 뒷받침되는 출력을 더 선호하게 되어, 인용의 신뢰도가 높아짐.
- ISSUP 가중치가 너무 크면:
- MAUVE(유창성) 점수가 하락.
- 생성이 길고 자연스러워질수록, 인용이 완전히 뒷받침되지 않는 주장이 늘어나는 경향(Liu et al., 2023a와 일치).
-
결론
- SELF-RAG는 추가 학습 없이, 추론 단계에서 파라미터 조정만으로 사용 목적(예: 인용 신뢰도 vs. 유창성)에 따라 모델 행동을 자유롭게 커스터마이징할 수 있다.
- 실무자는 상황에 맞게 critique 가중치를 조절하여 원하는 결과를 얻을 수 있다.
효율성과 정확도의 트레이드오프 요약
SELF-RAG 프레임워크에서는 토큰 확률 기반의 적응 임계값(δ)을 조정하여 검색 빈도를 제어할 수 있다. 이를 통해 사용자는 효율성과 정확도 간의 균형을 맞출 수 있다.
-
실험 내용
- PubHealth와 PopQA 데이터셋에서 임계값 δ를 다르게 설정하여, 검색 빈도와 전체 정확도에 미치는 영향을 평가함.
- δ 값이 커질수록 검색 빈도가 감소(더 적게 검색)함.
-
주요 결과
- δ 값을 조정하면 두 데이터셋 모두에서 검색 빈도가 크게 변함(Figure 3c 참조).- PubHealth: 검색 빈도를 줄여도 성능 저하가 크지 않음(효율성↑, 정확도↓ 폭이 작음).
- PopQA: 검색 빈도를 줄이면 성능 저하가 더 크게 나타남(효율성↑, 정확도↓ 폭이 큼).
-
결론
- SELF-RAG는 사용 목적에 따라 검색 빈도(=연산 비용)와 정확도 사이의 트레이드오프를 쉽게 조절할 수 있다.
- 실무자는 δ 값을 조정해, 효율성이 중요한 상황에서는 검색을 줄이고, 정확도가 중요한 상황에서는 검색을 더 자주 활용하도록 설정할 수 있다.
학습 데이터 규모
-
실험 방법
- 전체 15만 개 학습 데이터에서 무작위로 5천, 1만, 2만, 5만 개씩 샘플링하여 SELF-RAG 7B 모델을 각각 파인튜닝.- 최종 15만 개 전체 데이터로 학습한 SELF-RAG와 비교.
- 평가: PopQA, PubHealth, ASQA(인용 정밀도)에서 성능 비교.
- 결과는 Figure 4a, 4b, 4c에 시각화.
-
주요 결과
- 데이터 크기가 커질수록 전반적으로 성능이 꾸준히 향상됨.- 특히 PopQA와 ASQA에서는 데이터 증가에 따른 성능 향상이 매우 뚜렷하게 나타남.
- 반면, Llama2-FT7B(검색·비평 없이 단순 파인튜닝)는 5만→15만 데이터로 늘려도 성능 향상이 크지 않음.
- 이는 SELF-RAG가 데이터 확장에 더 민감하게, 즉 더 많은 데이터를 활용할수록 성능이 더 크게 개선됨을 시사함.
-
결론
- SELF-RAG의 학습 데이터 규모를 더 늘리면 추가적인 성능 향상을 기대할 수 있음.
- 본 연구에서는 15만 개로 제한했으나, 더 큰 데이터셋 활용 시 성능이 더 높아질 가능성이 큼.
인간 평가 요약
SELF-RAG의 출력과 반영 토큰(reflection token)의 신뢰성을 소규모 인간 평가로 검증하였다.
-
평가 방법
- PopQA와 Biography 결과에서 각각 50개 샘플을 무작위로 추출.
- Menick et al.(2022) 방식을 따라, 평가자는 다음 두 가지를 평가:
- S&P (Plausible & Supported):
- Plausible: 답변이 합리적이고 질문과 관련성이 높은지
- Supported: 제시된 근거가 답변의 타당성을 검증할 만큼 충분한지
- S&P (Plausible & Supported):
- SELF-RAG가 무관하거나 근거 없는 답변을 예측한 경우는 S&P 평가에서 제외.
- 평가자에게
ISREL(관련성)과ISSUP(근거 지원성) 반영 토큰의 예측이 실제 평가와 일치하는지도 확인 요청.
-
주요 결과
- SELF-RAG의 답변은 PopQA(단답형)에서 높은 S&P 점수를 받아, 답변이 합리적이고 근거로 잘 뒷받침됨을 확인.
ISREL,ISSUP반영 토큰 예측도 평가자의 판단과 대부분 일치.- 이는 SELF-RAG의 자동화된 평가 신호가 실제 인간 평가와 잘 부합함을 시사.
-
결론
SELF-RAG는 실제 사용 시에도 신뢰할 수 있는 답변과 근거 제시가 가능하며, 내부 신호(반영 토큰) 역시 인간 판단과 높은 일치도를 보인다.
