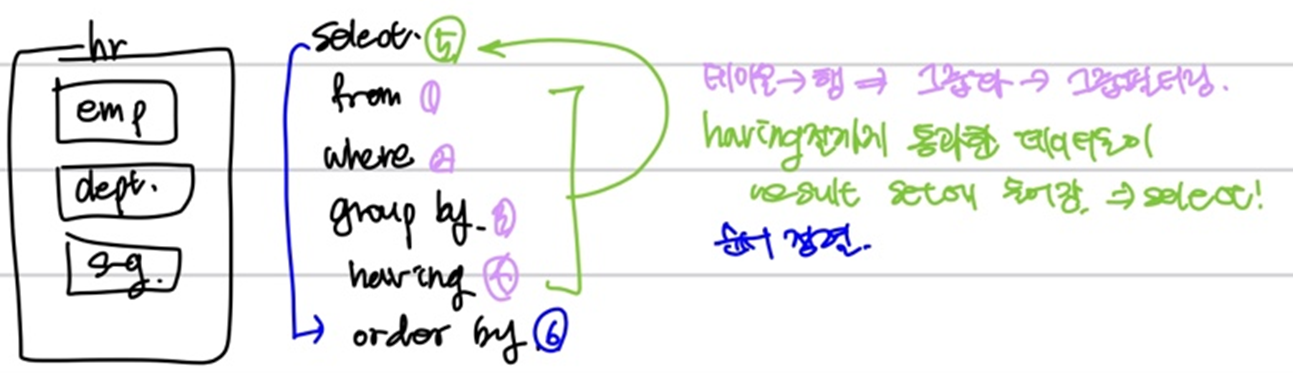
sql 실행순서
select + from으로 컬럼을 선택후 > where로 행을 걸러냄
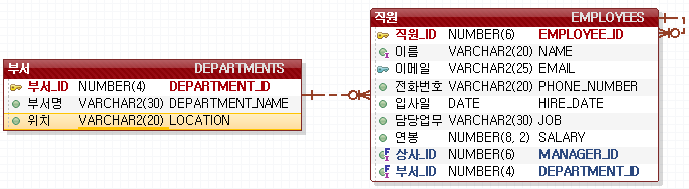
ERD(Entity Relation Dialog)
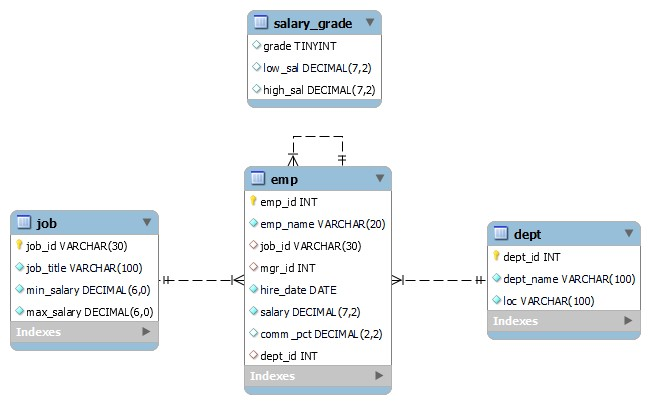
- 어플리케이션 프로그램을 로직을 짜는 것 -> 데이터는 DB에 넣어두고 짜기
Foreign key 제약조건
constraint 제약조건이름 foreign key(컬럼) references 부모테이블(PK컬럼=참조컬럼명) [ON 설정]
- 자식테이블에 의해 참조되는 부모테이블의 행(row)은 삭제 될 수 없다.
- 다른 자식테이블도 그 데이터를 참조 중- [ON설정] : 삭제하고 싶은 경우, 어떻게 처리할 건지 설정
- 부모테이블의 참조 row삭제 시 자식 테이블의 참조 row삭제
1) 자식 테이블의 참조중인 컬럼을 아예 삭제 :on delete cascade
2) 자식테이블의 컬럼 값 NULL 설정(참조중인 행을삭제) :on delete set null(f/k가 null을 허용하는 키여야함)

DROP TABLE IF EXISTS emp; -- drop 데이터베이스 객체 삭제
CREATE TABLE emp(
emp_id INT PRIMARY KEY,
emp_name VARCHAR(20) NOT NULL,
job_id VARCHAR(30),
mgr_id INT,
hire_date DATE NOT NULL,
salary DECIMAL(7,2) NOT NULL,
comm_pct DECIMAL(2,2),
dept_id INT, -- foreign key
CONSTRAINT fk_emp_dept FOREIGN KEY(dept_id) REFERENCES dept(dept_id) ON DELETE SET NULL,
CONSTRAINT fk_emp_job FOREIGN KEY(job_id) REFERENCES job(job_id) ON DELETE SET NULL,
CONSTRAINT fk_emp_mgr FOREIGN KEY(mgr_id) REFERENCES emp(emp_id) ON DELETE SET NULL
);조인(JOIN)
2개 이상의 테이블에 있는 컬럼들을 합쳐서 가상의 테이블을 만들어 조회하는 방식을 말한다.조인시Source 테이블의 데이터 행 은 모두 사용하고 Target table 의 데이터 행 은 조인 조건을 만족하는 행만 나오도록 한다
- 소스테이블 : 내가 먼저 읽어야 한다고 생각하는 테이블. 조회해야하는 주 정보(main information) 테이블
- 타겟테이블 : 소스를 읽은 후 소스에 조인할 대상이 되는 테이블. 조회하는 주정보의 부가정보(sub information) 제공 테이블
- 각 테이블을 어떻게 합칠지를 표현하는 것을 조인 연산이라고 한다.
- 조인 연산에 따른 조인종류
- Equi join , non-equi join
조인의 종류
Inner Join
- 양쪽 테이블에서 조인 조건을 만족하는 행들만 합친다.
- 교집합같은 개념
Outer Join
- 한쪽 테이블의 행들을 모두 사용하고 다른 쪽 테이블은 조인 조건을 만족하는 행만 합친다. 조인조건을 만족하는 행이 없는 경우 NULL을 합친다.
-합 집합과 같은 개념
- 종류 : Left Outer Join, Right Outer Join, Full Outer Join
Cross Join
- 두 테이블의 곱집합을 반환한다. 거의 사용 x, 기준행이 없기 때문에 전체를 합친다
크로스조인
SELECT *
FROM t1 CROSS JOIN t2;예문)
select count(*)
from emp cross join dept;
select count(*) from dept; -- 27
select count(*) from emp; -- 107
select 27 * 107; -- 2889 -- emp와 dept 데이터를 곱한 값
inner join vs outer join
무조건 outer join을 한다 -> outer join은 모든 정보를 불러오기 때문.
정보를 많이 봐서 나쁠 것은 없음.
INNER JOIN
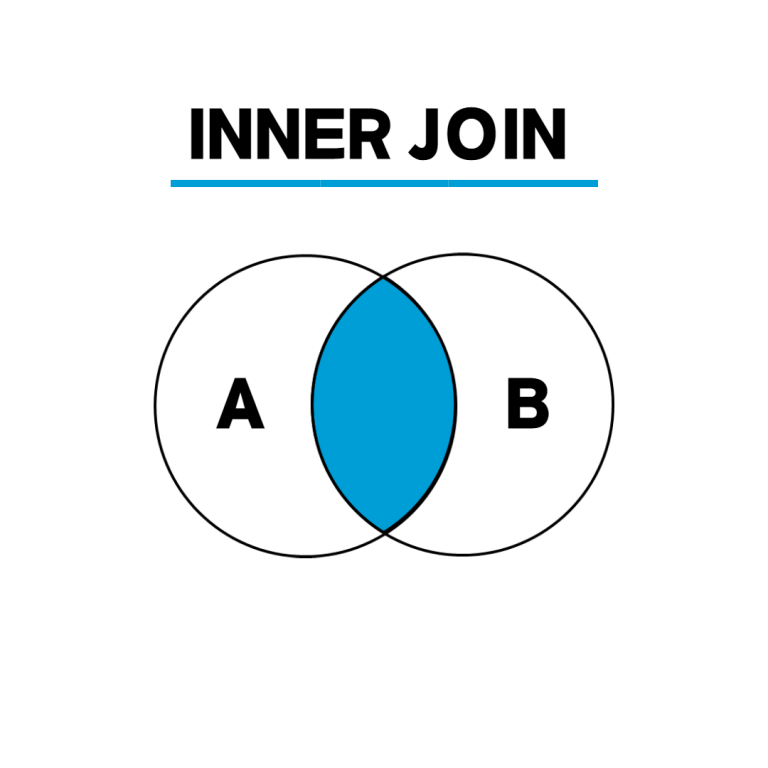
- 양쪽 테이블에서 조인 조건을 만족하는 행들만 합친다.(교집합)
- 타켓테이블이냐 소스테이블이냐는 보통은 메인이되는 정보를 - 조회하려는 주대상이 되는 테이블을 앞에 두고, 서브정보를가진 테이블을 뒤에 두는 것. 정해진 정보가 있는건 아님. 컬럼 순서만 바뀌는 것임
FROM 테이블a [INNER] JOIN 테이블b ON 조인조건 - table 별칭(alias) ⭐
select e.emp_id, e.emp_name, e.hire_date, d.dept_name
from emp e inner join dept d on e.dept_id = d.dept_id; -- 직원의 ID(emp.emp_id)가 100인 직원의 직원_ID(emp.emp_id), 이름(emp.emp_name), 입사년도(emp.hire_date), 소속부서이름(dept.dept_name)을 조회.
select e.emp_name as "직원이름",
e.hire_date as "입사일",
d.dept_name as "부서명"
from emp e join dept d on e.dept_id = d.dept_id
where e.emp_id = 100;- join된 테이블에 한번 더 join
직원_ID(emp.emp_id), 이름(emp.emp_name), 급여(emp.salary),
담당업무명(job.job_title), 소속부서이름(dept.dept_name)을 조회
select e.emp_id,
e.emp_name,
e.salary,
j.job_title,
d.dept_name
from emp e join job j on e.job_id = j.job_id
join dept d on e.dept_id = d.dept_id;
헷갈린 문제)
직원의 ID(emp.emp_id), 이름(emp.emp_name),
급여(emp.salary), 급여등급(salary_grade.grade) 를 조회.
`급여 등급 `오름차순으로 정렬
select e.emp_id,
e.emp_name,
e.salary ,
concat(s.grade, '등급') as "grade"
from emp e join salary_grade s on e.salary between s.low_sal and s.high_sal;
- salary_grade table
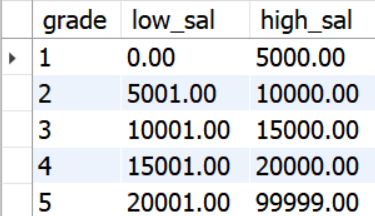
- 결과 테이블
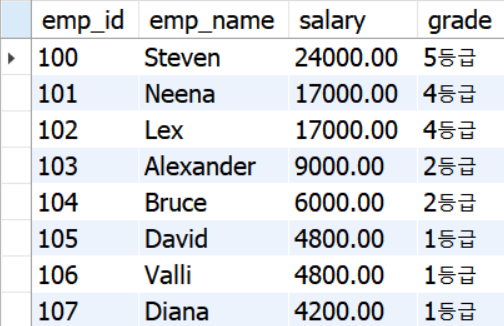
Q. 급여 등급 오름차순으로 어떻게 정렬?
between s.low_sal and s.high_sal을 설정해 e.salary가 low_sal,high_sal어느 범위에 오느냐에 따라 grade를 emp table에 다르게 join하게 된다. 예를 들어 e.salary가 8200이였을 경우, salary_grade table에서 low_sal 5001.00 ~ high_sal10000.00 사이에 값이 존재하므로 해당 열에 2등급이 join된다.
inner 조건 문제(어려웠던 것만)
✔️on 조인 조건을 자꾸 빼먹음
-- TODO 직원 id(emp.emp_id)가 200번대(200 ~ 299)인 직원들의
-- 직원_ID(emp.emp_id), 이름(emp.emp_name), 급여(emp.salary), 소속부서이름(dept.dept_name), 부서위치(dept.loc)를 조회. 직원_ID의 내림차순으로 정렬.
select e.emp_id, e.emp_name, e.salary,
d.dept_name, d.loc
from emp e join dept d on e.dept_id = d.dept_id
where e.emp_id between 200 and 299
order by e.emp_id desc; -- 1 desc
select e.emp_id , e.emp_name, e.salary, d.dept_name, d.loc
from emp e join
TODO 업무(emp.job_id)가 'FI_ACCOUNT'인 직원의 > where 조건
ID(emp.emp_id), 이름(emp.emp_name),업무(emp.job_id),
소속부서이름(dept.dept_name), 부서위치 (dept.loc)를 조회. > select 컬럼, 서로 다른 테이블이므로 Join
직원_ID의 내림차순으로 정렬. > order by
select e.emp_id, e.emp_name, d.dept_name,
d.dept_name, d.loc
from emp e join dept d on e.dept_id = d.dept_id
where e.job_id = 'FI_ACCOUNT'
order by e.emp_id desc;
-- TODO 커미션을(emp.comm_pct) 받는 직원들의
직원_ID(emp.emp_id), 이름(emp.emp_name),
-- 급여(emp.salary), 커미션비율(emp.comm_pct),
소속부서이름(dept.dept_name), 부서위치(dept.loc)를 조회.
직원_ID의 내림차순으로 정렬.
select e.emp_id, e.emp_name, e.salary , e.comm_pct,
d.dept_name, d.loc
from emp e join dept d on e.dept_id = d.dept_id
where e.comm_pct is not null
order by 1 desc;
-- TODO 'New York'에 위치한(dept.loc) 부서의 부서_ID(dept.dept_id), 부서이름(dept.dept_name), 위치(dept.loc),
-- 그 부서에 소속된 직원_ID(emp.emp_id), 직원 이름(emp.emp_name), 업무(emp.job_id)를 조회.
select d.dept_id, d.dept_name, d.loc,
e.emp_id, e.emp_name, e.job_id
from dept d join emp e on d.dept_id = e.dept_id
where d.loc = 'New York';
-- TODO 직원_ID(emp.emp_id), 이름(emp.emp_name), 업무_ID(emp.job_id), 업무명(job.job_title) 를 조회.
select e.emp_id , e.emp_name, e.job_id, j.job_title
from emp e join job j on e.job_id = j.job_id;
-- TODO: 직원 ID 가 200 인 직원의 직원_ID(emp.emp_id), 이름(emp.emp_name),
-- 급여(emp.salary), 담당업무명(job.job_title), 소속부서이름(dept.dept_name)을 조회
-- 테이블 3개를 join
select e.emp_id, e.emp_name, e.salary, -- emp
j.job_title, -- job
d.dept_name -- dept
from emp e join job j on e.job_id = j.job_id
join dept d on e.dept_id = d.dept_id -- 요기까지 조회
where e.emp_id = 200;
-- TODO: 'Shipping' 부서의 부서명(dept.dept_name), 위치(dept.loc),
-- 소속 직원의 이름(emp.emp_name), 업무명(job.job_title)을 조회. 직원이름 내림차순으로 정렬
select d.dept_name, d.loc, e.emp_name, j.job_title
from dept d join emp e on d.dept_id = e.dept_id
join job j on e.job_id = j.job_id
order by e.emp_name desc;
-- TODO: 'San Francisco' 에 근무(dept.loc)하는 직원의 id(emp.emp_id),
-- 이름(emp.emp_name), 입사일(emp.hire_date)를 조회 입사일은 'yyyy년 mm월 dd일' 형식으로 출력
select e.emp_id,
e.emp_name,
date_format(e.hire_date, '%Y년 %m월 %d일') as "hire_date"
from emp e join dept d on e.dept_id = d.dept_id
where d.loc = 'San Francisco'; -- 행을 걸러냄
-- TODO 부서별 급여(salary)의 평균을 조회. 부서이름(dept.dept_name)과 급여평균을 출력. 급여 평균이 높은 순서로 정렬.
select dept_id, avg(salary)
from emp
group by dept_id;
-- 선생님 추가 답 : left join ver
select ifnull(d.dept_name,"미배치"),
avg(e.salary)
from emp e left join dept d on e.dept_id = d.dept_id
group by d.dept_name;
-- TODO 직원의 ID(emp.emp_id), 이름(emp.emp_name), 업무명(job.job_title),
-- 급여(emp.salary), 급여등급(salary_grade.grade), 소속부서명(dept.dept_name)을 조회. 등급 내림차순으로 정렬
select e.emp_id, e.emp_name, j.job_title, e.salary, s.grade, d.dept_name
from emp e join job j on e.job_id = j.job_id
join salary_grade s on e.salary between s.low_sal and s.high_sal
join dept d on e.dept_id = d.dept_id
order by s.grade desc;
-- TODO salary 등급(salary_grade.grade)이 1인 직원들이 부서별로 몇명있는지 조회. 직원수가 많은 부서 순서대로 정렬.
select d.dept_name,
count(*) as "직원수"
from emp e join dept d on e.dept_id = d.dept_id
join salary_grade s on e.salary between s.low_sal and s.high_sal
where s.grade = 1
group by d.dept_name
order by 2 desc;
/* ****
Self 조인
- 물리적으로 하나의 테이블을 두개의 테이블처럼 조인하는 것.
- self join에서는 하나를 부하테이블, 하나를 상사테이블로 생각
- 조직 구조나 계층 구조와 관련된 데이터를 쿼리할 때 유용
직원 ID가 101인 직원의 직원의 ID(emp.emp_id),
이름(emp.emp_name), 상사이름(emp.emp_name)을 조회
select * from emp where emp_id = 101;
select emp_name as 상사이름 from emp where emp_id = 100;
select e.emp_id,
e.emp_name as "직원이름",
m.emp_name as "상사이름"
from emp e join emp m on e.mgr_id = m.emp_id
where e.emp_id = 101;
외부 조인 (Outer Join)
-
불충분 조인:조인 연산 조건을 만족하지 않는 행도 포함해서 합친다
-
합집합 개념
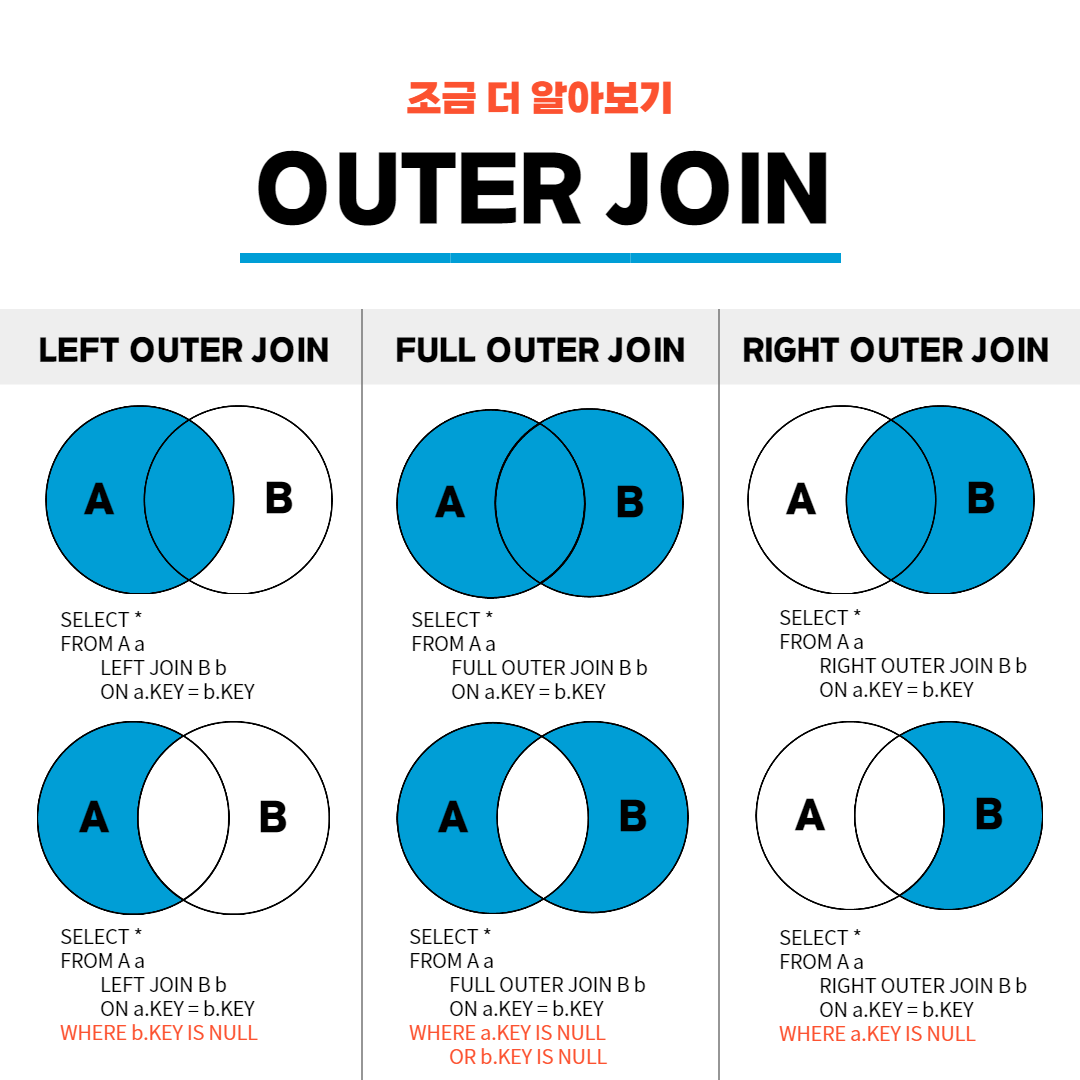
-
종류
left outer join: 구문상 소스 테이블이 왼쪽
right outer join: 구문상 소스 테이블이 오른쪽
full outer join: 둘다 소스 테이블 (Mysql은 지원하지 않는다. - union 연산을 이용해서 구현)
- left join 은 왼쪽에 위치한 소스테이블과 연결된 값만 살리는 것, right join은 이의 반대. full join은 모든 값을 가져옴. 예를 들어 , 나-윈터, 카리나- 닝닝 이렇게 친구사이라고 할 때, left는 나,윈터,카리나 를 가져오고, right는 윈터,카리나,닝닝을 가져오고, full은 모든 사람을 가져옴. -
구문
from 테이블 a [LEFT | RIGHT] OUTER JOIN 테이블b ON 조인조건
- OUTER는 생략 가능.예문)
-- 직원의 id(emp.emp_id), 이름(emp.emp_name), 급여(emp.salary), 부서명(dept.dept_name), 부서위치(dept.loc)를 조회.부서가 없는 직원의 정보도 나오도록 조회. dept_name의 내림차순으로 정렬한다.
select count(*)
from emp e join dept d on e.dept_id = d.dept_id;
select count(*) from emp where dept_id is null;- from emp e left join dept d on e.dept_id = d.dept_id
and d.dept_id = 80; -- and 추가적인 조건
=> where 조건과는 다르다. join조건은 어떤 값들을 붙일 것인가에 대한 조건,where 조건은 다 완성된 테이블에서 어떤 행을 필터링해서 볼 것인가.
-- 모든 직원의 id(emp.emp_id), 이름(emp.emp_name), 부서_id(emp.dept_id)를 조회하는데
-- 부서_id가 80 인 직원들은 부서명(dept.dept_name)과 부서위치(dept.loc) 도 같이 출력한다. (부서 ID가 80이 아니면 null이 나오도록)
# 부서 id가 null -> 직원 테이블이 소스테이블 , 부서테이블이 타겟 테이블
select e.emp_id, e.emp_name, e.emp_id,
d.dept_name, d.loc
from emp e left join dept d on e.dept_id = d.dept_id
and d.dept_id = 80; -- and 추가적인 조건 => where 조건과는 다르다. join조건은 어떤 값들을 붙일 것인가에 대한 조건
-- where d.dept_id = 80;
-- TODO: 직원_id(emp.emp_id)가 100, 110, 120, 130, 140인
-- 직원의 ID(emp.emp_id),이름(emp.emp_name), 업무명(job.job_title) 을 조회. 업무명이 없을 경우 '미배정' 으로 조회
-- inner join
select e.emp_id, e.emp_name, j.job_title
from emp e join job j on e.job_id = j.job_id
where e.emp_id in (100, 110, 120, 130, 140);
-- outer join
select e.emp_id, e.emp_name, j.job_title
from emp e left join job j on e.job_id = j.job_id
where e.emp_id in (100, 110, 120, 130, 140);
-- inner join vs outer join => outer join을 사용한다.
select * from emp where emp_id in (130,140);
-- e.job_id는 null값을 가지고 있기에 join이 되지 않음 => null값을 채워줘야함
-- TODO: 부서 ID(dept.dept_id), 부서이름(dept.dept_name)과 그 부서에 속한 직원들의 수를 조회. 직원이 없는 부서는 0이 나오도록 조회하고 직원수가 많은 부서 순서로 조회.
-- count(*) : 행수
select d.dept_id, d.dept_name, count(e.emp_id) as "직원수"
from dept d left join emp e on d.dept_id = e.dept_id
group by d.dept_id, d.dept_name;
-- 부서 테이블의 모든 내용이 다 들어가야하므로, left join을 해줘야함, emp table에서는 없지만 dept테이블에는 있는 직원이 '직원수 = 1' 로 컬럼에 들어가게됨
-- count(e.emp_id)를 해줘야 사람수 0, count(*) => 행수를 포함해서 출력
-- TODO: EMP 테이블에서 부서_ID(emp.dept_id)가 90 인 모든 직원들의 id(emp.emp_id), 이름(emp.emp_name), 상사이름(emp.emp_name), 입사일(emp.hire_date)을 조회.
-- 입사일은 yyyy/mm/dd 형식으로 출력
select e.emp_id,
e.emp_name,
m.emp_name as "상사이름",
date_format(e.hire_date, '%Y년 %m월 %d일') as 'hire_date'
from emp e left join emp m on e.mgr_id = m.emp_id
where e.dept_id = 90;
-- TODO 2003년~2005년 사이에 입사한 모든 직원의 id(emp.emp_id), 이름(emp.emp_name), 업무명(job.job_title), 급여(emp.salary), 입사일(emp.hire_date),
-- 상사이름(emp.emp_name), 상사의입사일(emp.hire_date), 소속부서이름(dept.dept_name), 부서위치(dept.loc)를 조회.
select e.emp_id,
e.emp_name,
j.job_title,
e.salary,
e.hire_date,
m.emp_name as "상사이름",
m.hire_date as "상사입사일",
d.dept_name,
d.loc
from emp e left join job j on e.job_id = j.job_id
left join dept d on e.dept_id = d.dept_id
left join emp m on e.mgr_id = m.emp_id
where year(e.hire_date) between 2003 and 2005;
-- 한번 outer join -> outer join하지 않으면 값이 사라지므로, 계속 해야함
Q&A
from emp e join dept d on e.dept_id = d.dept_id
1)조인 조건에는 id 만 들어갈 수 있는 것? id가 늘 primary key?
-부모테이블과 자식테이블은 주로 외래키를 기준으로 결합. 그렇지 않으면 데이터 무결성 문제 발생 가능
2)e와 d중에 어떤게 참조하는거고, 어떤게 참조당하는것?
- inner table에서는 상관없음. 순서가 바뀌어도 완성된 테이블의 형태는 같음
3) join은 부모테이블과 자식테이블 개념과는 다른것?
-> 테이블 간의 부모,자식관계가 나이더라도 가능함. emp 테이블과 salary grade테이블은 서로 관계가 없지만, 업무적으로 관계를 설정할 수 있음.
4)소스테이블의 위치
select e.emp_id, e.emp_name, e.dept_id,
d.dept_name, d.loc
from emp e left join dept d on e.dept_id = d.dept_id
=> 왼쪽에 위치한 emp e 가 소스테이블
from emp e right join dept d on e.dept_id = d.dept_id
=> 오른쪽에 위치한 dept d가 소스테이블
5)내부조인은 관계가 있어야만 합치수있음? salary grade같은 경우에는 emp 테이블과 관계가 없으므로 연결 불가능? => 키만 있으면 가능함
