[playdata] 데이터 애널리시스 33기
1.[python] 자료구조 01.List (08.11)
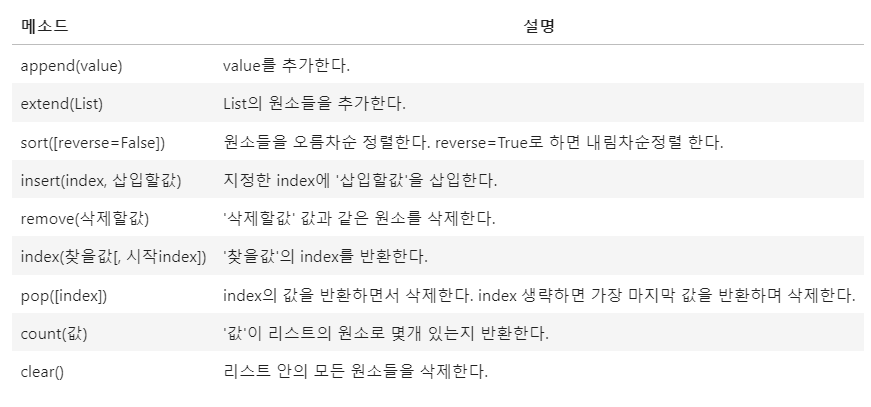
list에서 indexing과 slicing으로 list값을 변경하고 조회하는 방법을 알아보고, list에서 자주 사용하는 매소드를 정리해보자.
2.플레이데이터 애널리시스 33기 2주차 회고

8월 2주차 Weekly 회고
3.[python] 자료구조 02.Tuple,Dictionary,Set (08.14)

1) List : 순서대로, 중복허용,원소 변경 가능2) Tuple : 순서대로 , 중복허용, 원소 변경 불가능3) dictionary : 순서 x, key-value형태, value는 중복된 값을 저장가능 그러나 key는 중복될 수 없음4) Set: ,순서 x, 핵심
4.[python] 제어문 컴프리헨션 01. 제어문(08.14 -16)
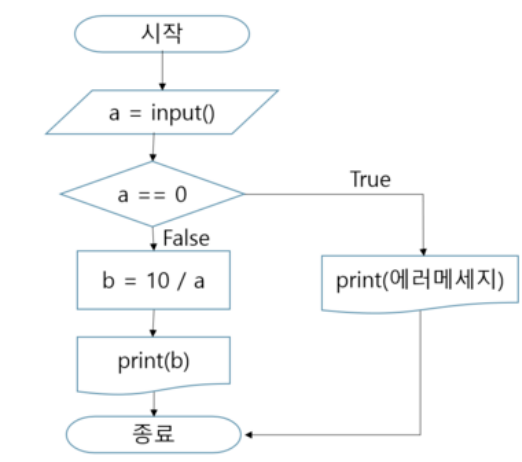
기본적으로 프로그램은 순차구조를 가지는데 그 실행흐름을 제어하는 구문을 만드는 문법이 제어문이다. 제어문의 2가지 종류인 조건문과 반복문에 대해 알아보자. for in 내장함수인 range, enumerate, zip 또한 알아보자
5.[python] 제어문 컴프리헨션 02. 컴프리헨션 + TODO 문제(08.16)
컴프리헨션은 긴 제어문 즉, 긴 조건문과 반복문으로 구성되었던 명령을 간단하게 표현하는 방법이다. 제어문으로 간단하게 iterable의 원소를 생성하여 새로운 자료구조(List, Dictionary, Set)을 생성한다.
6.플레이데이터 애널리시스 33기 3주차(8/14~8/18) 회고
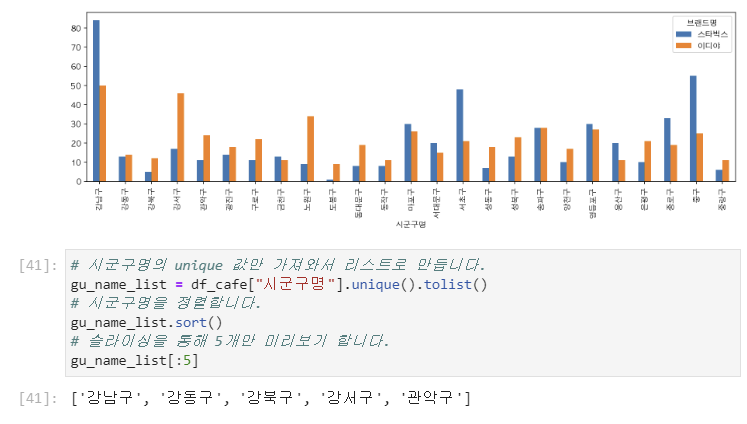
1. 전반적인 느낌(일주일동안 한 일) 데이터 애널리시스 수업 2주차를 마무리했다. python 03. 자료구조, 04. 제어문과 컴프리헨션 , 05.함수, 06.객체지향프로그래밍의 중반까지 진도가 나갔다. 함수 파트까지는 이전에 접해본 내용들이라 흡수가 빨랐는데, 객
7.객체 지향 프로그래밍
객체 지향 프로그래밍의 기초를 배워보자
8.[python] 09. Path - 02.text 데이터 입출력(08.25)
프로그램은 외부자원(IO대상)와 입출력(IO)을 통해 데이터를 주고받는데 이 과정을 stream이라고 한다. 입출력은 모두 파일을 열고 ( input/output stream=> open함수에 경로를 작성), 입출력을 실행하고 , 파일을 닫는 3단계를 거친다.
9.[python] 09. Path - 01. 경로(08.24)
경로(Path) 에서는 python 내장 모듈인 import os를 이용하여, 경로,파일/디렉토리 관련된 여러가지 함수들을 사용해볼 것이다. 파일이 있는지를 조회하고, 현재 working 디렉토리를 변경하며,디렉토리를 생성하고, 디렉토리/파일을 삭제하기 등을 배운다.
10.[python] 09. Path - 03.binary 데이터 입출력, pickle (08.25)
앞서 Text data의 입출력에 대해 알아봤다. 여기서는 text type의 데이터를 제외한 모든 타입의 데이터 = binary data를 어떻게 처리하는지에 대해 알아보고, 데이터의 변환과정을 자동화 시킨 모듈인 pickle의 사용법을 배운다.
11.[python] 09. Path - TODO문제
입출력에 관련한 문제와, csv파일의 입출력 문제 + 튜플 대입, 속성값 모아서 리스트에 담기를 반복문을 통해 코드를 짜보자
12.[python] from A import B
from A import B 일때, A에는 B의 상위 모듈도 올 수있고, 모듈이 저장된 디렉토리명이 올 수 도 있다.
13.플레이데이터 애널리시스 33기 4주차(8/21~8/25) 회고
전반적인 느낌(일주일동안 한 일) 좋았던 점(좋았거나 내가 잘했던 점) 아쉬웠던 점 개선할 점
14.[python]11. 파이썬 정규 표현식(Regular Expression) - 01. 정규표현식 규칙(0828)
텍스트에서 특정한 형태나 규칙을 가지는 문자열을 찾기 위해 그 형태나 규칙을 정의하는 것.파이썬 뿐만 아니라 문자열을 다루는 모든 곳에서 사용된다.정규식, Regexp이라고도 한다.패턴 정규 표현식이라고 한다.문장내에서 찾기위한 문구의 형태에 대한 표현식.메타문자패턴을
15.[SQL] DBMS 구조 + 00. create -테이블 생성
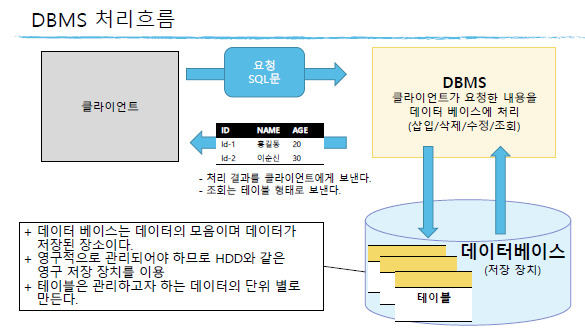
: 데이터베이스 관리 시스템데이터 베이스(지속적으로 유지 , 관리되어야 하는 데이터들의 집합)를 DBMS가 관리데이터 -> 변수 -> FIle=>DB에 저장MySQL, Oracle, MS MS-SQL, DB2 등.행과 열로 이루어진 2차원 표 형식으로 Data를 관리하
16.[SQL] 01.basic_select - 기본구문, WHERE절, ORDER BY절
sql 기초
17.[프로그래머스] 코딩 기초 테스트 Day 4 연산,조건문(230829)
n의 배수 공배수 홀짝에 따라 다른 값 반환하기 조건 문자열 flag에 따라 다른 값 반환하기
18.[SQL] 02. 함수 - 단일 행 함수
결과를 하나씩 넣어서 처리해서 함수를 처리함 함수 단일 행 함수 행 단위로 값 처리하는 함수 단일 행 select, where절 함수 안에 함수를 넣을 수 있음 CHAR_LENGTH(CONCAT('A','B')) 예) 다중 행 함수 여러 행의 값들을 묶어서 한번에
19.[SQL] 03.집계함수 01. 집계함수 (230904)
집계(Aggregation) 함수와 GROUP BY, HAVING >집계함수, 그룹함수, 다중행 함수 인수(argument)는 컬럼. sum(): 전체합계 avg(): 평균 min(): 최소값 max(): 최대값 stddev(): 표준편차 va
20.[SQL] 03. 집계함수 02. group by, having(23.09.04)
group by 절특정 컬럼(들)의 값별로 행들을 나누어 집계할 때 기준컬럼을 지정하는 구문. \- 예) 업무별 급여평균. 부서-업무별 급여 합계. 성별 나이평균구문: group by 컬럼명 , 컬럼명 \- 컬럼: 범주형 컬럼을 사용 - 부서별 급여 평균, 성별 급
21.[SQL] 04. join (23.09.05)
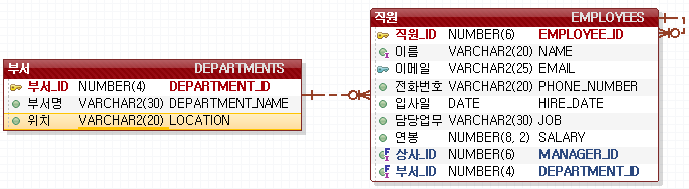
select + from으로 컬럼을 선택후 > where로 행을 걸러냄어플리케이션 프로그램을 로직을 짜는 것 -> 데이터는 DB에 넣어두고 짜기자식테이블에 의해 참조되는 부모테이블의 행(row)은 삭제 될 수 없다. \- 다른 자식테이블도 그 데이터를 참
22.[SQL] 04. join - todo 문제⭐ (23.09.06)

헷갈렸던 문제 위주로
23.[SQL] 05.서브쿼리 - 01. select절, where절,from절

ctrl+Shift+enter : block설정한 부분만 실행쿼리안에서 select 쿼리를 사용하는 것.메인 쿼리 - 서브쿼리select절, from절, where절, having절1) 어느 구절에 사용되었는지에 따른 구분 \- 스칼라 서브쿼리 - select 절
24.[SQL] 05.서브쿼리 - 02. 상관/비상관쿼리 + EXISTS, NOT EXISTS연산자
상관(연관) 쿼리 메인쿼리문의 조회값을 서브쿼리의 조건에서 사용하는 쿼리. 메인쿼리를 실행하고 그 결과를 바탕으로 서브쿼리의 조건절을 비교한다. 메인 쿼리의 where을 실행하면서 subquery가 같이 실행된다. 이때 메인쿼리 where 절에서 비교하는 그 행의 컬
25.[SQL] 06.집합연산자(2023.09.08)
둘 이상의 select 결과를 합치는 연산구문select문 집합연산자 select문 집합연산자 select문 ...컬럼이 3개, 컬럼이 3개있는 행끼리 수직적으로(세로로) 합칠건데 같은 컬럼이니까 행으로 붙을 수있음컬럼의 항목이 같을 필요는 없지만 , type은 같아
26.가상환경 만들기 (23.09.11)
conda create --name da -> y 선택conda create --name da python conda activate (이름)conda activate da -> da 가상환경 실행conda activate base -> base였던 가상환경 실행
27.플레이데이터 애널리시스 33기 6주차(9/4 ~9/10) 회고
전반적인 느낌(일주일동안 한 일) sql 03. 집계함수에서 한 컬럼의 모든 값을 한번에 연산하는 함수들, sum(),avg()등을 배웠고 04. join에서 서로 다른 테이블을 연결한느 방법을 배웠고, 05. 서브쿼리에서는 메인쿼리안에 좋았던 점(좋았거나 내가 잘했
28.[SQL] 07. DML (23.09.07)
INSERT 문 - 행 추가 구문 한행추가 : INSERT INTO 테이블명 (컬럼 [, 컬럼]) VALUES (값 [, 값[]) 모든 컬럼에 값을 넣을 경우 컬럼 지정구문은 생략 할 수 있다. 조회결과(select)를 INSERT 하기 (subque
29.플레이데이터 애널리시스 33기 10월 3주차(10.16 ~ 10.22) 회고

전반적인 느낌 ( 일주일 동안 한 일 ) 좋았던 점(좋았거나 내가 잘했던 점) 아쉬웠던 점 개선할 점 다음 달 계획
30.플레이데이터 애널리시스 33기 10월 2주차(10.10 ~ 10.15) 회고 | 밀린 한달 회고하기🐻
1. 전반적인 느낌(일주일동안 한 일) 근 한달 간 회고를 작성하지 못했다가 오랜만에 작성!!!!!!! 걍 9월 중순 ~ 10월 중순 월간 회고됨. SQL이 끝난 이후 Python에서 데이터 분석에 필요한 pandas, numpy 라이브러리를 배웠고 이후, 본격적으로