- ctrl+Shift+enter : block설정한 부분만 실행
서브쿼리(Sub Query)
- 쿼리안에서 select 쿼리를 사용하는 것.
- 메인 쿼리 - 서브쿼리
서브쿼리가 사용되는 구
- select절, from절, where절, having절
서브쿼리의 종류
1) 어느 구절에 사용되었는지에 따른 구분
- 스칼라 서브쿼리 - select 절에 사용. 반드시 서브쿼리 결과가 1행 1열(값 하나-스칼라) 0행이 조회되면 null을 반환
- 인라인 뷰(inline View)⭐- from 절에 사용되어 테이블의 역할을 한다.
가상테이블을 임시적으로 생성하고 그 테이블에서 select구문을 실행하는 것. 물리적테이블이 아니라 개념적테이블
+ where절 : 행의 조건의 값을 가진 컬럼을 제공한다.(행 수에 따라 단행/다중행 서브쿼리)
2) 서브쿼리 조회결과 행수에 따른 구분
단일행 서브쿼리⭐- 서브쿼리의 조회결과 행이 한행인 것.다중행 서브쿼리⭐- 서브쿼리의 조회결과 행이 여러행인 것.- = 대신
in: 해당 행과 같은 값을 가져온다. - 크기 비교
all/any: 가장 큰(작은)값보다 더 큰(작은)값을 가져올때는,all/any를 >,<부호와 함께 where절에 적어야한다. max/min을 서브쿼리의select에서 사용하면 단일 행 쿼리가 되어, ><를 단독으로 사용가능하다. 그래서 max/min을 더 많이 쓰는 경향
- = 대신
3) 동작 방식에 따른 구분
비상관(비연관) 서브쿼리
서브쿼리에 메인쿼리의 컬럼이 사용되지 않는다.메인쿼리에 사용할 값을 서브쿼리가 제공. 안쪽쿼리(서브쿼리)가 먼저 시행됨
상관(연관) 서브쿼리
서브쿼리에서 메인쿼리의 컬럼을 사용한다. 메인쿼리가 먼저 수행되어 읽혀진 데이터를 서브쿼리에서 조건이 맞는지 확인하고자 할때 주로 사용한다.
비상관 쿼리ex.
select * form emp
where salary > (select avg(salary) from emp);
: 메인쿼리에서 조회한 값을 where절에서 사용(메인쿼리와 서브쿼리가 동시에, 번갈아가면서 시행)- 서브쿼리는 반드시 ( ) 로 묶어줘야 한다.
SELECT절
- 서브쿼리를 하나의 열처럼 사용
emp, dept 테이블 간의 공통값만 매칭하되, dept는 모든 값을 가져오고 emp에서는 gender열만 나오게 하기
-- 서브쿼리
select * , (select gender from emp where on e.member_id = e.member_id) as "gender"
from dept
-- 조인
select d.*, e.gender
from emp e left join dept e on e.member_id = e.member_id;emp테이블에서 gender컬럼만 똑 떼어서 가져오고 싶을 때 사용. select절 서브쿼리는 데이터 양이 맣을 수록 실행속도가 느려져 거의 사용되지 않는 명령어
WHERE절 (+단일 행 쿼리)
- 일반적인 서브쿼리
-- 직원_ID(emp.emp_id)가 120번인 직원과 같은 업무(emp.job_id)를
-- 하는 직원의 id(emp_id), 이름(emp.emp_name), 업무(emp.job_id), 급여(emp.salary) 조회
-- 조회 후 where 절에 조건 설정
select job_id from emp where emp_id = 120;
select emp_id, emp_name, job_id, salary
from emp
where job_id = 'ST_MAN';
-- 서브쿼리로 간단히
select emp_id, emp_name, job_id, salary
from emp
where job_id = (select job_id from emp where emp_id = 120);- pair 방식 서브쿼리. 두개이상 컬럼 비교해도 된다.
-- 직원_id(emp.emp_id)가 115번인 직원과 같은 업무(emp.job_id)를 하고 같은 부서(emp.dept_id)에 속한 직원들을 조회하시오.
-- 조회 후 조건 설정
select job_id, dept_id from emp where emp_id = 115; -- 직원_id(emp.emp_id)가 115번인 직원의 업무와 부서 확인
select * from emp where job_id ='PU_MAN' and dept_id = 30;
select * from emp
where (job_id, dept_id) = (select job_id, dept_id
from emp
where emp_id = 115);
select * from emp
where (job_id, dept_id) = ('PU_MAN', 30);
-- where job_id = 'PU_MAN' and dept_id = 30;- 연습 1) where절 서브쿼리 + 단일행 서브쿼리
-- 직원들 중 급여(emp.salary)가 전체 직원의 평균 급여보다 적은 직원들의
-- id(emp.emp_id), 이름(emp.emp_name), 급여(emp.salary)를 조회.
select avg(salary) from emp;
select emp_id, emp_name, salary
from emp
where salary < (select avg(salary) from emp)
order by 3 desc;-
select avg(salary) from emp 만 실행 > 단일 행 서브쿼리

-
연습2) where절 서브쿼리 + group by
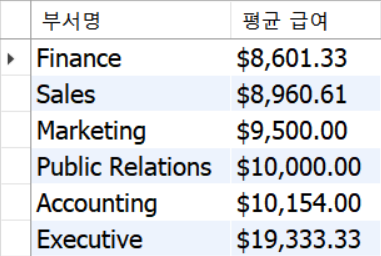
-- 부서직원들의 평균이 전체 직원의 평균(emp.salary) 이상인 부서의 이름(dept.dept_name), 평균 급여(emp.salary) 조회.
-- 평균급여는 소숫점 2자리까지 나오고 통화표시($)와 단위 구분자 출력
select d.dept_name as "부서명",
concat('$', format(a.avg, 2)) as "평균 급여"
from(
select dept_id, avg(salary) as "avg"
from emp
group by dept_id
having avg(salary) > (select avg(salary) from emp)
order by 2) a left join dept d on a.dept_id = d.dept_id; -- a 테이블 형성 후 dept_name을 불러오기 위해 dept 조인- 연습3)
-- TODO: 급여(emp.salary)가장 많이 받는 직원(-> where)이 속한 부서의 이름(dept.dept_name), 위치(dept.loc)를 조회.
-- 헷갈린 문제
select d.dept_name, d.loc
from (select *
from emp
where emp_id = (select emp_id from emp where salary = max(salary)) -- ->직원 정보: 소스테이블로 설정
e left join dept d on e.dept_id = d.dept_id ;
-- 선생님 답1 : 이중 서브 쿼리
select dept_name, loc
from dept
where dept_id = (select dept_id
from emp
where salary = (select max(salary)
from emp));
-- 선생님 답2 : 조인
select d.dept_name,d.loc
from dept d left join emp e on d.dept_id = e.dept_id
where salary = (select max(salary) from emp);- 연습4)
-- TODO: 전체 직원들 중 담당 업무 ID(emp.job_id) 가 'ST_CLERK'인 직원들의 평균 급여보다 적은 급여를 받는 직원들의 모든 정보를 조회.
-- 단 업무 ID가 'ST_CLERK'이 아닌 직원들만 조회.
select *
from emp
where salary < any (
select avg(salary)
from emp
where job_id = 'ST_CLERK') -- 2817.647059
and job_id != 'ST_CLERK'
order by salary desc;
-- 선생님 답
select *
from emp
where salary < any (
select avg(salary)
from emp
where job_id = 'ST_CLERK') -- 2817.647059
and (job_id != 'ST_CLERK'
or job_id is null)
order by salary desc;
-- job_id is null까지 설정 해줘야 job_id가 설정안된 null값이 나옴다중행 서브쿼리(where 절)
-
서브쿼리의 조회 결과가 여러행
-
in 은 =,any all/any ><부호 로 사용됨
-
where절에서의 연산자
-in
- 비교연산자any: 조회된 값들 중 하나만 참이면 참 (where 컬럼 > any(서브쿼리) )
- 비교연산자all: 조회된 값들 모두와 참이면 참 (where 컬럼 > all(서브쿼리) ) -
Join과 서브쿼리를 선택하는 것은 상황에 따라 다르다. 여기서는 서브쿼리 위주로 보자.
예1 : in
-- 'Alexander' 란 이름(emp.emp_name)을 가진 관리자(emp.mgr_id)의
-- 부하 직원들의 ID(emp_id), 이름(emp_name), 업무(job_id), 입사년도(hire_date-년도만출력), 급여(salary)를 조회
select emp_id, emp_name from emp where emp_name = 'Alexander'; -- emp_id 103,115 두 행이 나옴
select emp_id, emp_name, job_id, year(hire_date), salary, mgr_id
from emp
where mgr_id in (select emp_id
from emp
where emp_name = 'Alexander');
-- Subquery returns more than 1 row
-- 에러: 서브쿼리가 1개 이상의 행을 리턴 -> where절에서 서브쿼리랑 연결시, in연산자를 사용해야함. 다중행쿼리에서는 =연산자 사용 x예2 : in
TODO : 부서 위치(dept.loc) 가 'New York'인 부서에 소속된(> where절 조건)
직원의 ID(emp.emp_id), 이름(emp.emp_name),
부서_id(emp.dept_id) 를 sub query를 이용해 조회.
-- 서브 쿼리
select emp_id, emp_name, dept_id
from emp
where dept_id in (select dept_id
from dept
where loc = 'New York');
-- 조인
select e.emp_id, e.emp_name, d.dept_id
from emp e left join dept d on e.dept_id = d.dept_id
where d.loc = 'New York';예3: in
다른 테이블의 결과값 테이블의 컬럼이 메인쿼리에도 있다면 join없이 연결
-- TODO : 최대 급여(job.max_salary)가 6000이하인 업무를 담당하는 직원(emp)의 모든 정보를 sub query를 이용해 조회.
-- 헷갈린 문제
select *
from emp
where job_id in (select job_id
from job
where max_salary <= 6000);- job테이블에서 max_salary 6000이하인 업무만 가져온다(select job_id from job where max_salary <= 6000)

예3 : all
-- 직원 ID(emp.emp_id)가 101, 102, 103 인 직원들 보다 급여(emp.salary)를 많이 받는 직원의 모든 정보를 조회.
select * from emp
where salary > all (select salary
from emp
where emp_id in (101, 102, 103));
-- min,max : all, any는 max, min으로 대체가능.오히려 더 많이 사용
select * from emp
where salary > (select max(salary)
from emp
where emp_id in (101, 102, 103));예4 : any
group by로 부서별 평균값 계산 - any 그중에 가장 작은값보다 적게
부서별 급여의 평균중 가장 적은 부서의 평균 급여보다 보다 많이 받는 직원들의 이름, 급여, 업무를 서브쿼리를 이용해 조회
select emp_name, salary, job_id
from emp
where salary < any (select avg(salary)
from emp
group by dept_id); -- 부서별로 평균값을 계산 -> 그중에 가장 작은 값보다 적게 받아야함 :any부서별 평균값 계산 (select avg(salary) from emp group by dept_id)
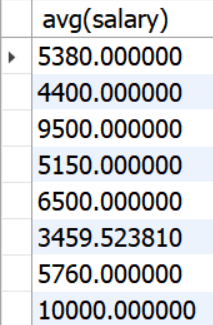
any 처리
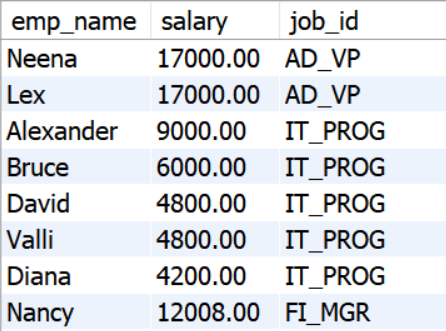
FROM 절
- 하나의 테이블처럼 사용. 열이름과 테이블명을 반드시 명시 해줘야한다.
select 이름
from (select emp_name as "이름", salary from emp) a;
-- alias반드시 사용예1
-- TODO: 급여(emp.salary)가장 많이 받는 직원(-> where)이 속한 부서의 이름(dept.dept_name), 위치(dept.loc)를 조회.
-- 헷갈린 문제
-- 선생님 답1 : 이중 서브 쿼리
select dept_name, loc
from dept
where dept_id = (select dept_id
from emp
where salary = (select max(salary)
from emp));
-- 선생님 답2 : 조인
select d.dept_name,d.loc
from dept d left join emp e on d.dept_id = e.dept_id
where salary = (select max(salary) from emp);예2
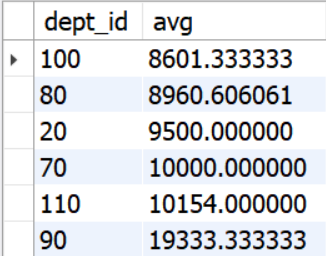
아래 서브쿼리 실행 시 해당 테이블이 생성 -> 이 가상의 테이블이 메인쿼리의from에 들어가 하나의 테이블처럼 쓰임. alias반드시 설정
select dept_id, avg(salary) as "avg"
from emp
group by dept_id
having avg(salary) > (select avg(salary) from emp)
order by 2-- 부서직원들의 평균이 전체 직원의 평균(emp.salary) 이상인 부서의 이름(dept.dept_name), 평균 급여(emp.salary) 조회.
-- 평균급여는 소숫점 2자리까지 나오고 통화표시($)와 단위 구분자 출력
select d.dept_name as "부서명",
concat('$', format(a.avg, 2)) as "평균 급여"
from(
select dept_id, avg(salary) as "avg"
from emp
group by dept_id
having avg(salary) > (select avg(salary) from emp)
order by 2) a left join dept d on a.dept_id = d.dept_id; -- a 테이블 형성 후 dept_name을 불러오기 위해 dept 조인