python의 자료구조 4가지
1) List : 순서대로, 중복허용,원소 변경 가능
2) Tuple : 순서대로 , 중복허용, 원소 변경 불가능
3) dictionary : 순서 x, key-value형태, value는 중복된 값을 저장가능 그러나 key는 중복될 수 없음
4) Set: ,순서 x, 핵심은 중복을 허용하지 않는다는 것, 집합의 개념
- len(자료구조) 함수 :
문자열에서는 글자수를, 자료구조에서는 값들의 개수를 세어줌
2. Tuple
- 리스트처럼 순서대로 원소를 관리, 단 원소를 변경할 수 없음
- 소괄호로 관리되고, 괄호는 생략가능 (value, value,,,,)
예) 튜플 대입 a,b,c = 10,20,30 = (10,20,30) - (50)은 그냥 정수 - 파이썬에서는 괄호를 '연산자 우선수위'를 알려준다고 생각, 그냥 정수로 인식
- (50,) or 50, - 뒤에 쉼표를 붙여줘야 tuple로 인식
Indexing과 Slicing을 이용한 원소(element) 조회
- 조회 과정 자체는 리스트와 동일하지만, 튜플은 조회만 가능하고 원소를 변경할 수 없음
#조회
index
t2 = (10,20,30,40,50,60)
#양수/음수 index
t2[0] -> 10
t2[5],t2[-1] -> 60,60
#범위 조회
t2[1:5] -> 20,30,40,50
t2[1:-2] -> 20,30,40
#새로운 튜플
t1 = (3,4,5)
t1 = (1,2)
t1 > (1,2) #튜플의 값이 바뀐 것이 아니라, 새로운 튜플로 바뀐 것tuple 생성
(value, value, value, ...)- 소괄호를 생략할 수 있다.
- 원소가 하나인 Tuple 표현식
(value,)또는value,- 값 뒤에
,를 붙여준다.,를 붙이지 않으면 ( )가 연산자 우선순위 괄호가 된다.
- 값 뒤에
# 생성
t1 = (10,20,30,40,50) # ()로 감싼다.
print(type(t1))
t2 = 10,20,30,40,50,60 # ()생략 가능
print(type(t2))
t3 = (10,5.2,True,"abc") # 다른 타입들을 모을 수 있다.
t4 = 10,5.2,True,"abc"
print(type(t3), type(t4))
#값 뒤에, 붙이기
t5 = (30) > int type
t6 = (30,) > tuple type원소 조회
-
리스트와 동일(tuple[index])하지만 튜플은 조회만 가능, 변경 불가
-
원소 조회 메소드
-
index
-
count(값)
예)
t = (1,2,3,4,1,2,1,2,1,1,1)
t.count(1)
-> 6
t.index(2,4) #2의 index를 조회, index 4부터 찾아라
-> 5
예)
print(t2[0])
print(t2[5],t2[-1])
예)
t1 = (1,2)
t1 #튜플의 값이 바뀐 것이 아니라, 새로운 튜플로 바뀐 것
예) 범위 조회
t2[1:5]Tuple 연산자
- tuple + tuple
- 두 tuple의 원소들을 합친 tuple을 반환한다.
- tuple * 정수
- 같은 tuple의 원소들을 정수번 합친 tuple를 반환한다.
- in, not in 연산자
- 값 in tuple
- tuple의 원소로 값이 있으면 True, 없으면 False 반환
- 값 not in tuple
- tuple의 원소로 값이 없으면 True, 있으면 False 반환
- 값 in tuple
- len(tuple)
- tuple의 원소 개수 반환
Tuple 대입
- 튜플의 원소들을 각각 다른 변수에 대입하는 표현식.
- 변수의 개수와 튜플의 원소 개수는 동일해야 한다.
예)
v1, v2, v3 = 10, "A", 5.7 #변수 순서에 맞춰 대입
print(v1,v2,v3) 3.Dictionary
- 값을 키(key)-값(value) 쌍으로 묶어서 저장하는 자료구조이다.
(리스트의 값들의 인덱스에 이름을 붙인 형태 - key) - key-value 쌍으로 묶은 데이터 한개를 item 또는 entry라고 한다.
생성
- 구문
{ 키 : 값, 키 : 값, 키 : 값 }- dict(key=value, key=value) 함수 이용
- 키(key)는 불변(Immutable)의 값들만 사용 가능하다. (숫자, 문자열, 튜플) 일반적으로 문자열을 사용한다.
- dict() 함수를 사용할 경우 key는 변수로 정의한다
customer_info = {"name" :"홍길동", "age" : 20, "nickname" : "박명수", "email": "abc@abc.com", "address" : "서울", "hobby" :['게임', '스포츠']} #KEY는 중복 허용 안함. VAlUE는 중복 허용함. d = {"name":"홍길동","nickname": "홍길동"} d2 = {"name":"홍길동", "name" : "유재석", "name":"박명수"} ->{'name': '박명수'} #같은 key가 들어가면 마지막에 추가된 것만 남는다.(변경)
원소 조회 및 변경
- 조회: key값을 식별자로 지정 -> value 출력
- dictionary[ key ]
- 없는 키로 조회 시 KeyError 발생
- 변경
-
dictionary[ key ] = 값
-
있는 key값에 값을 대입하면 변경이고 없는 key 일 경우는 새로운 item을 추가하는 것
#이름 customer_info["name"] # 추가/변경 ## 추가 - item 추가 cutomer_info["tall"] = 182.33 #추가 :없는 키 = 값 cutomer_info ```
-
연산자
- in, not in 연산자
- 값 in dictionary
- dictionary의 Key로 값이 있으면 True, 없으면 False 반환
- 값 not in dictionary
- dictionary의 Key로 값이 없으면 True, 있으면 False 반환
- 값 in dictionary
- len(dictionary)
- dictionary의 Item의 개수 반환
"홍길동" in customer_info -> False #value가 있는 지 확인 불가
# in,not in은 key 가 있는지/없는지 여부
"name" in customer_info -> True
주요 메소드

customer_info =
{'name': '홍길동',
'age': 20,
'nickname': '박명수',
'email': 'abc@abc.com',
'hobby': ['게임', '스포츠']}
customer_info.get("name")
customer_info.get("weight", -1) #-1 : default값(weight키가 없으면 반환할 값을 설정)
#반환하면서 제거
v = customer_info.pop("address") #address의 값을 반환하면서 제거
print(v)
customer_info
#제거
del customer_info['email'] #삭제만
customer_info
customer_info.keys() #key값들만 모아서 반환
customer_info.values() #value들만 모아서 반환
customer_info.items() #key, value를 튜플로 묶어서 반환
customer_info.clear()4. Set
- 구문
- {값, 값, 값 }
- {} 빈 set이 아니라 빈 dictionary를 생성
- {값, 값, 값 }
s2 = {1,1,1,1,1,2,2,2,2,3,3,3,3,4,4,5,5,5,5}
s2 #중복을 허용하지 않아 unique value만 남긴다
>{1, 2, 3, 4, 5}
s2[0] #개별 원소 조회 불가(식별자=index가 없음)연산자
-
in, not in 연산자
- 값 in Set
- Set의 원소로 값이 있으면 True, 없으면 False 반환
- 값 not in Set
- Set의 원소로 값이 없으면 True, 있으면 False 반환
- 값 in Set
-
len(Set)
- Set의 원소의 개수 반환
1 in s2,10 in s2 > (True,False)
메소드
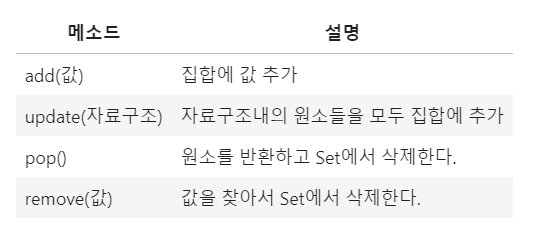
- Set의 원소의 개수 반환
s2.add(6)
s2.update([10,20,30,40])
v = s2.pop()
s2.remove(20)
s2.remove(1000) # 없는 값 삭제 -> 예외(exception) 발생
Set의 집합연산 연산자 및 메소드
- 합집합
- 집합A | 집합B
- 집합A.union(집합B)
- 교집합
- 집합A & 집합B
- 집합A.intersection(집합B)
- 차집합
-
집합A - 집합B
-
집합A.difference(집합B)
set1 = {1,2,3,4,5} set2 = {4,5,6,7,8} #합집합 set3 = set1 | set2 set4 = set1.union(set2) #교집합 set5 = set1 & set2 set6 = set1.intersection(set2) # 차집합 set7 = set1 - set2 set8 = set1.difference(set2)
-
자료구조 변환함수
- list(자료구조)
- tuple(자료구조)
- set(자료구조)
- 대상 자료구조/Iterable을 Set으로 변환
- 다른 자료구조의 원소 중 중복을 빼고 조회
- Dictionary로 변환하는 함수는 없다.
변경할 대상이 Dictionary 일 경우에는 key값들만 모아서 변환
#v = [1,1,1,1,2,2,3,3,3,4,4,4,4,4,4,5,5,2,1]
v = (1,1,1,1,2,2,3,3,3,4,4,4,4,4,4,5,5,2,1)
# v가 무슨 값들로 구성되었는지 확인 - set => list를 set으로 변환
set(v) >{1,2,3,4,5}
t =(1, 2, 3, 4, 5)
#t에 100을 추가 : tuple -> list로 변환 후 값추가 -> tuple
l = list(t)
l.append(100)
t = tuple(l)
list("안녕하세요.") #문자열 : 문자를 모아놓은 iterable
> ['안', '녕', '하', '세', '요', '.']
r = "배 사과 귤 수박 복숭아".split() #띄어쓰기 기준으로 분할
> ['배', '사과', '귤', '수박', '복숭아']
"-".join(r)
#"합칠 때 사용할 구분문자열".join(리스트) -> 리스트이 문자열 원소들을 하나의 문자열로 합친다
>'배-사과-귤-수박-복숭아'
데이터 분석 & 서비스 기획