의뢰 받아 진행한 차 관련 키워드 기반 데이터 수집 및 빈도 분석입니다.
install.packages('pacman')
library(pacman)
p_load('httr','rvest','RSelenium','dplyr','stringr','openxlsx','tm')
remotes::install_github('haven-jeon/KoNLP',upgrade='never',INSTALL_opts=c("--no-multiarch"))
#install.packages('Rcpp')
#library(Rcpp)
library(KoNLP)
make_url<-function(last_page,keyword){
page=1:last_page
url=c()
for(i in page){
url=append(url,paste0('https://www.ppomppu.co.kr/zboard/zboard.php?id=car&page=',i,'&search_type=sub_memo&keyword=',URLencode(keyword),'&divpage=160'))
}
return(url)
}
get_url=function(url){
all_url=c()
for(i in url){
url_data=read_html(i,encoding='cp949') %>% html_nodes('.list_vspace')%>%html_nodes('a') %>% html_attr('href')
url_data[grep('view.php',url_data)]
all_url=append(all_url,url_data[grep('view.php',url_data)])
print(i)
}
all_url=paste0('https://www.ppomppu.co.kr/zboard/',all_url)
return(all_url)
}
page_url=make_url(13,'튜닝')
text_url=get_url(page_url)
data_all=data.frame()
now=1
for(i in text_url){
#제목
title=read_html(i,encoding='cp949') %>% html_nodes('.view_title2') %>% html_text()
#등록일, 조회수
temp=read_html(i,encoding='cp949') %>% html_nodes('.sub-top-text-box') %>% html_text2()
date=str_split(str_extract(temp,'등록일:.*.\n') %>% str_extract('[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+'),' ')[[1]][1]
time=str_split(str_extract(temp,'등록일:.*.\n') %>% str_extract('[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+'),' ')[[1]][2]
temp1=str_extract(temp,'조회수:.*./')
view=gsub('[^0-9]','',temp1)
#본문
body=read_html(i,encoding='cp949') %>% html_nodes('.board-contents') %>% html_text()
#댓글
chat_all=c()
no=gsub('[^0-9]','',str_extract(i,'no=[0-9]+'))
num=1
repeat{
chat_url = paste0('https://www.ppomppu.co.kr/zboard/comment.php?id=car&no=',no,'&c_page=',num,'&comment_mode=')
num=num+1
temp=read_html(chat_url,encoding='cp949') %>% html_nodes('.over_hide')
temp1=temp[grep('commentContent',temp)] %>% html_text()
if(length(temp1)==0){
break
}
chat_all=append(chat_all,gsub(' | @[가-힣a-zA-Z0-9\\.]+','',temp1))
print(chat_url)
Sys.sleep(runif(1,2,3))
}
if(length(chat_all)==0){
chat_all=NA
}
data_all = rbind(data_all,data.frame(title,date,time,body,chat_all))
print(paste0(now,'/',length(text_url)))
now=now+1
Sys.sleep(runif(1,2,3))
}
data_id = data.frame(id=1:nrow(unique(data_all['title'])),title=unique(data_all['title']))
data=right_join(data_id,data_all)
write.xlsx(data,'데이터 수집.xlsx')
useNIADic()
library(tm)
ko.words <- function(doc){
d <- as.character(doc)
pos <- paste(SimplePos09(d))
extracted <- str_match(pos, '([가-힣0-9]+)/[NP]')
keyword <- extracted[,2]
keyword[!is.na(keyword)]
}
################## title frequency
cps <- VCorpus(VectorSource(unique(data$title)))
tdm <- TermDocumentMatrix(cps,
control = list(weighting= weightBin,
tokenize=ko.words,
removePunctuation = T,
removeNumbers = T,
stopwords = c()))
tdm <- as.matrix(tdm)
# View(tdm)
v <- sort(slam::row_sums(tdm), decreasing = T)
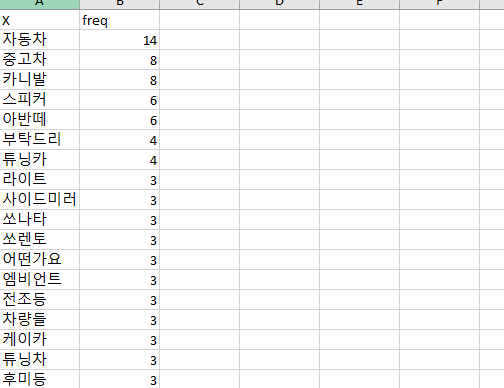
data <- data.frame(X=names(v),freq=v)
write.xlsx(data,'title_frequency.xlsx')
################## body_frequency
cps <- VCorpus(VectorSource(unique(data$body)))
tdm <- TermDocumentMatrix(cps,
control = list(weighting= weightBin,
tokenize=ko.words,
removePunctuation = T,
removeNumbers = T,
stopwords = c()))
tdm <- as.matrix(tdm)
# View(tdm)
v <- sort(slam::row_sums(tdm), decreasing = T)
data1 <- data.frame(X=names(v),freq=v)
write.xlsx(data1,'body_frequency.xlsx')
################## comment_frequency
cps <- VCorpus(VectorSource(data$chat_all))
tdm <- TermDocumentMatrix(cps,
control = list(weighting= weightBin,
tokenize=ko.words,
removePunctuation = T,
removeNumbers = T,
stopwords = c()))
tdm <- as.matrix(tdm)
# View(tdm)
v <- sort(slam::row_sums(tdm), decreasing = T)
data1 <- data.frame(X=names(v),freq=v)
write.xlsx(data1,'comment_frequency.xlsx')

문송 개발자