
의뢰 받아 진행한 특정 키워드 기반 네이버 뉴스 수집, 분석 및 시각화입니다.
데이터 수집 코드
library(rvest)
library(dplyr)
library(RSelenium)
library(openxlsx)
library(httr)
library(stringr)
library(tidyr)
library(utils)
setwd('D:\\R_크롤링\\네이버 뉴스 수집')
data = read.csv('미디어.csv')
data = data[,-3]
data_origin=tidyr::separate_rows(data=data,colnames(data)[2],sep=',')
data_origin[,1]=sapply(data_origin[,1], function(x){str_trim(x)})
data_origin[,2]=sapply(data_origin[,2], function(x){str_trim(x)})
colnames(data_origin)=c('kinds','news')
#본인의 작업 디렉토리 설정
########################################## 원격 서버, 크롬 열기 ################
portn<-as.integer(runif(1,1,5000))
# runif(a,b,c) : b~c사이의 수 하나를 랜덤하게 a 개 뽑는다 (실수 범위)
# as.integer(x) : x를 정수로 바꾼다
#::원격 서버를 열 때 포트 넘버를 넣어주기 위해 1~5000사이의 정수 하나를 랜덤으로 뽑아 portn에 넣어준다
rD<-rsDriver(port=portn, browser='chrome', chromever='91.0.4472.19')
# :: 원격 서버를 여는 함수로 port 넘버, browser, browser의 버전 입력이 필요하다 (자동으로 브라우저가 열림)
#<-크롬버전은 빈칸으로 입력후 에러 발생하면 자신의 크롬 정보에서 크롬 버전을 확인후 에러 창에서 가장 비슷한 버전을 적으면됨
remDr<-rD$client
url ='https://search.naver.com/search.naver?where=news&query=%EB%A6%B0%EB%84%A8&sm=tab_opt&sort=0&photo=0&field=0&pd=0&ds=&de=&docid=&related=0&mynews=1&office_type=1&office_section_code=1&news_office_checked=1032&nso=&is_sug_officeid=0'
remDr$navigate(url)
Sys.sleep(1)
### 언론사 선택창 열기
remDr$findElement('xpath','//*[@id="snb"]/div[2]/ul/li[4]/div/div[1]/a[2]')$clickElement()
### 언론사 종류 리스트 가져오기
list_up=remDr$findElements('xpath','//*[@id="snb"]/div[2]/ul/li[4]/div/div[2]/div/div[1]/div/div/div/ul/li[*]/a')
news_list=data.frame()
num=0
for(i in list_up){
i$clickElement()
Sys.sleep(0.5)
temp1 = remDr$findElements('xpath','//*[@id="snb"]/div[2]/ul/li[4]/div/div[2]/div/div[2]/div/div/div/ul/li[*]/a')
temp2 = remDr$findElements('xpath','//*[@id="snb"]/div[2]/ul/li[4]/div/div[2]/div/div[2]/div/div/div/ul/li[*]')
temp_1 = sapply(temp1, function(x){x$getElementText()[[1]]})
temp_2 = sapply(temp2,function(x){x$getElementAttribute('data-code')[[1]]})
frame = cbind(i$getElementText(), temp_1,temp_2)
news_list = rbind(news_list,frame)
num=num+1
now = paste0(num,'/',length(list_up))
print(now)
}
### 컬럼명 설정
colnames(news_list)=c('kinds','news','code')
### 데이터 속성 변경
news_list=news_list %>% mutate(kinds = as.character(kinds))
news_list=news_list %>% mutate(news = as.character(news))
news_list = news_list %>% mutate(code = as.character(code))
### 제공 받은 리스트와 수집된 데이터 결합해서 code 가져오기
data_to_crawl=left_join(data_origin,news_list,by=c('kinds','news'))
### 제공 받은 리스트의 언론사 이름이 잘못된 것 찾아서 고치기
correction_list=data_to_crawl[which(is.na(data_to_crawl[,3])),1:2]
cor = c('디지틀조선TV', 'KTV국민방송','MTN','YTN사이언스','매일경제TV','레이디경향','allure')
data_to_crawl[which(is.na(data_to_crawl[,3])),2] = cor
### 제공 받은 리스트의 언론사 코드 전체 가져오기
data_info=left_join(data_to_crawl[,1:2],news_list,by=c('kinds','news'))
a.addr = data.frame()
page=seq(1,100000,10)
search_list = c('린넨','친환경의류')
r1=cbind(search_list[1],data.frame(data_info[,1:2]))
r2=cbind(search_list[2],data.frame(data_info[,1:2]))
for(name in search_list){
url_base=paste0('https://search.naver.com/search.naver?where=news&query=',name)
num=0
for(i in 1:nrow(data_info)){
a.addr_r=c()
num=num+1
print(num)
print(data_info[i,2])
num_re = 0
for(j in page){
num_re =num_re+1
now = paste0(name,'-',num,'-',num_re)
print(now)
url=paste0(url_base,'&sm=tab_opt&sort=0&photo=0&field=0&pd=3&ds=2010.01.01&de=2021.07.31&docid=&related=0&mynews=1&office_type=1&office_section_code=1&news_office_checked=',data_info[i,3],'&nso=so%3Ar%2Cp%3Afrom20100101to20210731&is_sug_officeid=0&start=',j)
html_data = read_html(url)
a.addr_text <- html_data %>% html_nodes('.info_group') %>% html_nodes('.info') %>% html_attr('href')
a.addr_re<-a.addr_text[grepl('naver',a.addr_text)]
a.addr_r = append(a.addr_r, a.addr_re)
check = html_data %>% html_nodes(xpath='//*[@id="main_pack"]/div[2]/div/a[2]') %>% html_attr('aria-disabled')
q=try({
if(check=='true'){
break}
},silent=TRUE)
if(is.character(q)==TRUE){break}
}
if(length(a.addr_r)==0){
a.addr_r = '기사 없음'
}
a.ad=cbind(name,data_info[i,1:2],a.addr_r)
a.addr=rbind(a.addr,a.ad)
if(a.addr_r=='기사 없음'){
a.addr_r = c()
}
if(name==search_list[1]){
r1[i,4] = length(a.addr_r)
}else{
r2[i,4] = length(a.addr_r)
}
}
}
title <- c()
article <- c()
web.addr <- c()
date <-c()
for (i in 1:nrow(a.addr)){
data <- a.addr[i,4]
if(data=='기사 없음'){
date<-append(date, '기사 없음')
title<-append(title, '기사 없음')
article<-append(article, '기사 없음')
next
}
body <- read_html(data)
date.temp <- html_nodes(body,'span.t11')
if(length(date.temp)==0){
date.temp <- html_nodes(body,'.author') %>% html_nodes('em')
if(length(date.temp)==0){
date.temp<- html_nodes(body,'.info') %>% html_nodes('span')
date.temp<- html_text(date.temp)[1]
date_text<-date.temp %>% stringr::str_split(' ')
date_re<-date_text[[1]][2]
}else{
date.temp <- html_text(date.temp)[length(date.temp)]
date_text<-date.temp %>% stringr::str_split(' ')
date_re<-date_text[[1]][1]
}
date<-append(date,date_re)
}else{
date.temp <- html_text(date.temp)[length(date.temp)]
date_text<-date.temp %>% stringr::str_split(' ')
date_re<-date_text[[1]][1]
date<-append(date,date_re)
}
title.temp <- body %>% html_nodes('title') %>% html_text()
title_re<-gsub(' : 네이버 뉴스','',title.temp)
if (length(title_re) == 0) title <- append(title, "수동확인")
else title <- append(title, title_re)
article.temp <- html_nodes(body,'div#articleBodyContents')
if(length(article.temp)==0){
article.temp=html_nodes(body, xpath='//*[@id="newsEndContents"]')
}
article.temp <- html_text(article.temp)
article<-append(article, article.temp)
if (length(article.temp) ==0) {
article.temp <- html_nodes(body,'#articeBody') %>% html_text()
article<-append(article,article.temp)
}
web.addr <- append(web.addr, data)
now = paste0(i,'/',nrow(a.addr))
print(now)
}
# 본문의 공백, 줄바꿈 등 쓸떼없는 텍스트를 날림
article <- gsub("\n", "", article)
article <- gsub("\t", "", article)
article <- gsub("//", "", article)
article <- gsub("flash 오류를 우회하기 위한 함수 추가", "", article)
article <- gsub("function _flash_removeCallback()", "", article)
article <- gsub("\\()", "", article)
article <- gsub("\\{}", "", article)
article <- gsub("이미지 원본보기", "", article)
paper <- data.frame(a.addr,date, title, article)
paper1 = unique(paper)
paper2 = tidyr::separate(paper1,date,into=c('year','month','day'),sep='\\.')
write.xlsx(paper2, '수집.xlsx',overwrite=TRUE)
t=na.omit(paper2)
r = t %>% group_by(name,kinds,news) %>% summarise(count=n())
colnames(r1) =c('name','kinds','news')
colnames(r2) =c('name','kinds','news')
r_t=rbind(r1[,1:3],r2[,1:3])
ob=left_join(r_t,r, by=c('name','kinds','news'))
ob[is.na(ob)] = 0
write.xlsx(ob, '관측.xlsx', overwrite=TRUE)
data= read.xlsx('수집.xlsx')
q=sapply(data['article'], function(x){gsub('+[-_ㅣ|a-zA-Z0-9가-힣 ]+[가-힣]{2,4}[ 기자]+[ -_.+a-zA-Z0-9]+[@].+[.][[a-zA-Z0-9]+.*','',x)})
e=sapply(q, function(x){gsub('▶ \\[인터랙티브\\].*','',x)})
w=e[1:10]
w[10]
데이터 분석 코드
ls()
rm(list = ls())
x <- c("rvest", "data.table", "pbapply", "dplyr",
"xml2", "topicmodels", "tm", "quanteda",'quanteda.textstats','quanteda.textplots','quanteda.corpora',
"parallel", "doParallel", "foreach",
"ggplot2", "reshape", "openxlsx", "stm",
"lubridate", "tidyr", "stringr", "igraph",'tidyverse')
#install.packages(x)
lapply(x, require, character.only = TRUE)
#setwd("C:\\Users\\user\\Desktop\\tm")
# path = 'C:\\Users\\sjhty\\Desktop\\r\\text mining'
#path <- "C:\\Users\\user\\Desktop\\tm"
setwd('D:\\R_크롤링\\네이버 뉴스 수집')
data_ALL <- read.xlsx('수집.xlsx')
data_ALL=data_ALL[,c(1,2,3,5,6,7,8,9)]
data_ALL=data_ALL[-which(data_ALL['article']=='기사 없음'),]
data =read.xlsx('단어.xlsx')
data1 = t(data)
data1 = data1[-1,]
data1=gsub('상품','제품',data1)
data1=gsub('고객','소비자',data1)
data1=gsub('서울시','서울',data1)
data1=gsub('서울특별시','서울',data1)
data1=gsub('매일경제','',data1)
stop = c("가운데","가지","갖은","개국","개년","개소","경우","린넨","림픽","매스",
"개월","걔","거기","거리","겨를","군데","그거","그것","그곳",'과연','계세',
"그까짓","그네","그녀","그놈","그대","그래","그래도",'제공',"오늘","경리",
"그서","그러나","그러니","그러니까","그러다가","인터뷰","티엔","임영웅",
"그러면","그러면서","그러므로","그러자","그런","로라","트리","마제","엄태웅",
"그런데","그럼","그렇지만","그루","그리고","그리하여","웨스","김서형",'광고',
"그분","그이","그쪽","근","근데","글쎄","글쎄요","진행","서현진","유연석",
"나름","나위","남짓","냥","너희","대상","네놈","녀석","년도","김희애",
"놈","누구","다른","다만","달러","당신","대로","더구나","더욱이","김예림",
"두세","두어","둥","듯","듯이","등등","등지","올해","대한","이지혜","김필",
"따라서","따름","따위","딴","때문","또","또는","또한","부문","야자","김나라",
"마당","마련","마리","만큼","몇","몇몇","모금","모든","무렵","무슨","무엇","뭐",
"뭣","미터","및","바람","바퀴","발짝","뻔","뿐","서너","세기","세영","노영주",
"쇤네","스무","사람","시간","아냐","아니","아니야","아무","무릅쓰","려면",
"아무개","아무런","아아","아이","아이고","아이구","사실","아시아경제",
"얘","어느","어디","어머","언제","에이","엔","여기","여느",'문도',"조인성",
"여러","여러분","여보","여보세요","여지","역시","오랜","통해","웨스","오히려",
"온갖","왜냐하면","왠","우리","웬","이거","이것","이곳","이놈","이래","이런",
"이런저런","이른바","이리하여","이쪽","일대","임마","자신","민태구","김민서",
"자기","자네","저것","저기","지금","저놈","저런","최대","현재","김정식","저쪽",
"저편","저희","주년",'종종',"주일","즈음","즉","주목","김만","지경","지난",
"쯤","큰","킬로미터","퍼센트","하기야","하긴","성룡","하물며","가기","저작권",
"하지만","한두","한편","허허","배포","작권","혹은","있다","있는","등을","한겨레",
"회장","드된","밝혔다","함께","이번","지난해","가장","한다","면서","가량",
"모바일","재배포","무단전재","무단","전재","것이다","관련","에서","앵커",
"문지영","일까지","때문에","관계자는","만든","이데일리","오전","아래",
"네이버","분양","두산","중공업","서울숲","조감도","랜드마크","오후","등으로",
"저작권자","다시","매일경제","있고","미이","헤럴드","아시아경제","중심으로",
"라는","크게","받았다","전국","달라","모바일","바로","년까지","각각","동시에",
"전체","구독하기","배포","그때",'직접',"머니투데이","이날","쉽게","중이다",
"매년","라고","금지","면서","헤럴드경제","타이가","서울경제","페이스북",
"까지","년간","받고","일이",'아파트',"연간","바탕으로","보인다","있었다",
"앞으로","있게",'나선','이버',"이영자","동생","맞아","기자","월부터",
"아닌","것도","있을","없다","이상의",'보기',"김경희","이미","코리아",
"최고","받은","열린","년부터","높은","네이버","이후","네이버에서","대표",
"원에","채널","한국경제","전했다","더욱","연합뉴스","코리아헤럴드","뉴스",
"관계자","이상","사용","이용","모두","정도","구독","금지","동안","비롯",
"하나","수준","각종","단지","일반","많이","이라는","파이낸셜뉴스","만에",
"대표는",'위해','대해','경향신문','재는','라며','뉴시스','네이버','기사',
'함부러','일부러','박미라','이데일리','동아일보','파이낸셜','비즈스',
'비즈니스','토일','말했다','것으로','했다','이라고','으로','특히','있도록',
'같은','이제','올림픽','제품','것이','많은','하는','등의','따라','등이',
'하고','바로가기','이어','오는','활용한','활용해','있어','와일드플라워린넨',
'마틴','영송','빅뱅','태양','트와일라잇','민효린','웨딩','부동산','오피스텔',
'호텔','시설','주거','규모','예정','가구','앙코르','주택','주상','화재','견본주택',
'가로막','강변북로','고덕','지상','건설','임대','조식','지상')
num=0
for(i in stop){
num=num+1
now = paste0(num,'/',length(stop))
print(now)
data1 = gsub(i,'',data1)
}
data_ALL$text = data1
### 린넨일 경우 '친환경의류'->'린넨' 으로 변경
data_ALL=data_ALL %>% filter(name=='친환경의류')
data_ALL=tidyr::unite(data_ALL,col='date',year,month,day,sep='-',remove=FALSE)
dim(data_ALL)
str(data_ALL)
data_ALL$date2 <- ymd(data_ALL$date)
data_ALL$year <- year(data_ALL$date2)
data_ALL$month <- month(data_ALL$date2)
data_ALL$day <- day(data_ALL$date2)
str(data_ALL)
table(data_ALL$year)
data_2018 <- data_ALL %>%
filter(data_ALL$year==2018)
data_2019 <- data_ALL %>%
filter(data_ALL$year==2019)
table(data_2018$month)
table(data_2019$month)
# rdata <- data_ALL[,c(2:3,5:7)]
#
# q=sapply(rdata['article'], function(x){gsub('+[-_ㅣ|a-zA-Z0-9가-힣 ]+[가-힣]{2,4}[ 기자]+[ -_.+a-zA-Z0-9]+[@].+[.][[a-zA-Z0-9]+.*','',x)})
# e=sapply(q, function(x){gsub('▶ \\[인터랙티브\\].*','',x)})
# rdata['article']=e
# compute diagnostic values for models with different topic numbers
# held-out likelihood: look for the higest value given a topic number
# residuals: look for the lowest given a topic number
# lower bound: look for the lowest given a topic number
# semantic coherence: look for the hightest given a topic number
# rdata$story<-gsub("\n", "", rdata$article)
# rdata$story<-gsub("아니라", "", rdata$article)
# rdata$story<-gsub("있습니다", "", rdata$article)
# rdata$story<-gsub("위하여", "", rdata$article)
# rdata$story<-gsub("대해서", "", rdata$article)
# rdata$story<-gsub("있어서", "", rdata$article)
# rdata$story<-gsub("있도록", "", rdata$article)
# rdata$story<-gsub("☞ .*", "", rdata$article)
# rdata$story<-gsub("▶ .*", "", rdata$article)
# rdata$story<-gsub("ⓒ .*", "", rdata$article)
# rdata$story<-gsub('+[-_ㅣ|a-zA-Z0-9가-힣 ]+[가-힣]{2,4}[ 기자]+[ -_.+a-zA-Z0-9]+[@].+[.][[a-zA-Z0-9]+.*','',rdata$article)
# #불용어 제거 파일 생성
#
write.csv(data_ALL$text, "afstopwords.csv")
#
f <- read.csv("afstopwords.csv", header=T, stringsAsFactors=FALSE)
#
class(f)
## 명사 추출기
# ko.words <- function(doc){
# d <- as.character(doc)
# extractNoun(d)
# }
fcorpus <- corpus(data_ALL$text)
e=tokens(fcorpus,remove_url=TRUE, remove_punct=TRUE,remove_number=TRUE)
# document feature matrix
dfm2 <- dfm(e, verbose = FALSE, tolower = TRUE,
remove_numbers = TRUE, remove_punct = TRUE,
remove_symbols = TRUE, remove_separators = TRUE,
remove = stop)%>%
dfm_select(min_nchar = 2L)
textstat_frequency(dfm2)
word_fre<- textstat_frequency(dfm2)
#write.csv(word_fre, "word_fre_final.csv")
dfm2@Dimnames$features
#write.csv(dfm2,"dfm2.csv")
dfm2.trim <- dfm_trim(dfm2, min_docfreq = 0.001,
max_docfreq = .90,
docfreq_type = "prop")
#memory.size()
#memory.limit()
#x = rep(0, 300000000)
#memory.size()
#y = rep(0, 300000000)
#memory.limit(5000)
#memory.limit()
#y = rep(0, 300000000)
dfm2.stm <- convert(dfm2.trim, to = "stm")
dfm2
f$article <- data_ALL$article
f$news <- data_ALL$news
f[1,1]
f2 <- f[order(data_ALL$text, decreasing = FALSE), ]
f2$year <- data_ALL$year
f2$month <- data_ALL$month
f2$day <- data_ALL$day
f2$kinds <- data_ALL$kinds
colnames(f2)[1:2]=c('documents','vocab')
dfm2.stm$meta <- f2
out <- dfm2.stm
docs <- out$documents
vocab <- out$vocab
meta <- out$meta
#meta
#f <- read.csv("ai_rawdata.csv", sheet = 1)
library(stm)
#메타 데이터 팩터 처리 (연속형 변수 예측을 위해 팩터 처리 하지 않음)
#str(rdata)
#rdata$year <- as.factor(rdata$year)
#rdata$month <- as.factor(rdata$month)
str(data_ALL)
#
K = c(5, 10, 15, 20, 25, 30,35)
kresult <- searchK(out$documents, out$vocab, K,prevalence =~kinds+year, data = meta)
#
x11()
plot(kresult)
### optimal k = 파악 어려움
#optimal k : 15로 설정
#모델 만들기
out <-prepDocuments( docs,vocab, meta)
# model estimation
# agendaPrevFit <- stm(documents = out$documents, vocab = out$vocab,
# K = 15,
# max.em.its = 75, data = out$meta,
# init.type = "Spectral")
agendaPrevFit <- stm(documents = out$documents, vocab = out$vocab,
K = 20, prevalence =~kinds+s(year),
max.em.its = 70,data=out$meta,
init.type = "Spectral")
# model selection
agendaSelect <- selectModel(out$documents, out$vocab, K = 20,
max.em.its = 70,
runs = 20, seed = 8458159)
# Plot of selectModel results
plotModels(agendaSelect, pch=c(1,2,3,4))
# 토픽별 단어
labelTopics(agendaPrevFit,c(3,7,15))
# 토픽별 문서
thoughts3 <- findThoughts(agendaPrevFit, texts = meta$article,
n = 2, topics = 3)$docs[[1]]
thoughts20 <- findThoughts(agendaPrevFit, texts = meta$article,
n = 2, topics = 15)$docs[[1]]
par(mfrow = c(1, 2),mar = c(.5, .5, 1, .5))
plotQuote(thoughts3, width = 30, main = "Topic 3")
plotQuote(thoughts20, width = 30, main = "Topic 20")
out$meta$kinds<-as.factor(out$meta$kinds)
# Estimating metadata/topic relationships
prep <- estimateEffect(1:20 ~kinds+s(year), agendaPrevFit,
meta = out$meta, uncertainty = "Global")
summary(prep,topics=5)
plot(agendaPrevFit, type = "summary", xlim = c(0, .3))
# kinds 변수를 중점으로 stm 구축
poliblogContent <- stm(out$documents, out$vocab, K = 20,
prevalenc= ~ kinds+s(year), content =~ kinds,
max.em.its = 70, data = out$meta, init.type = "Spectral")
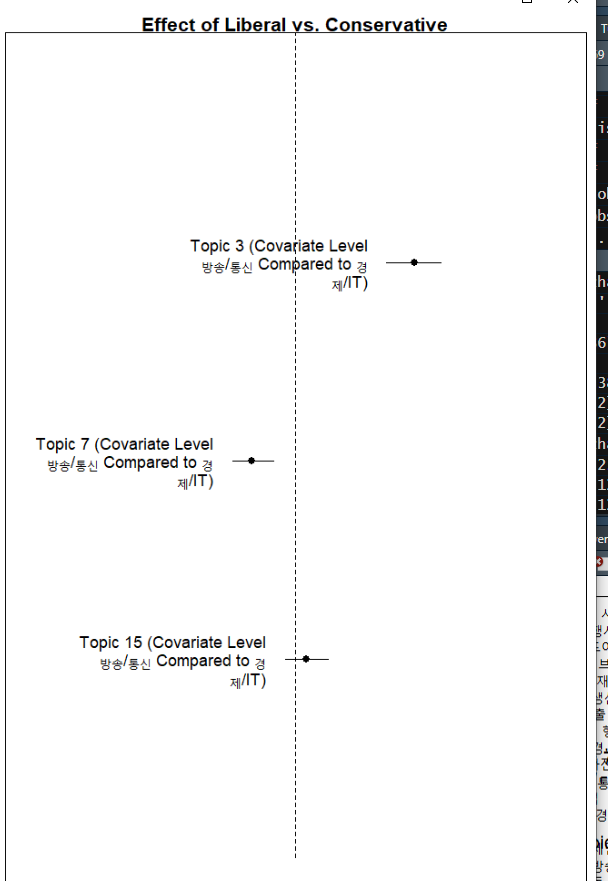
# 방송/통신과 경제/IT 가 토픽에 미치는 영향
plot(prep, covariate = "kinds", topics = c(3, 7, 15),
model = agendaPrevFit, method = "difference",
main = "Effect of Liberal vs. Conservative",
xlim = c(-.1, .1),
cov.value1 = "방송/통신", cov.value2 = "경제/IT"
, xlab = "More 경제/IT ... More 방송/통신")
out$meta$year=as.numeric((out$meta$year))
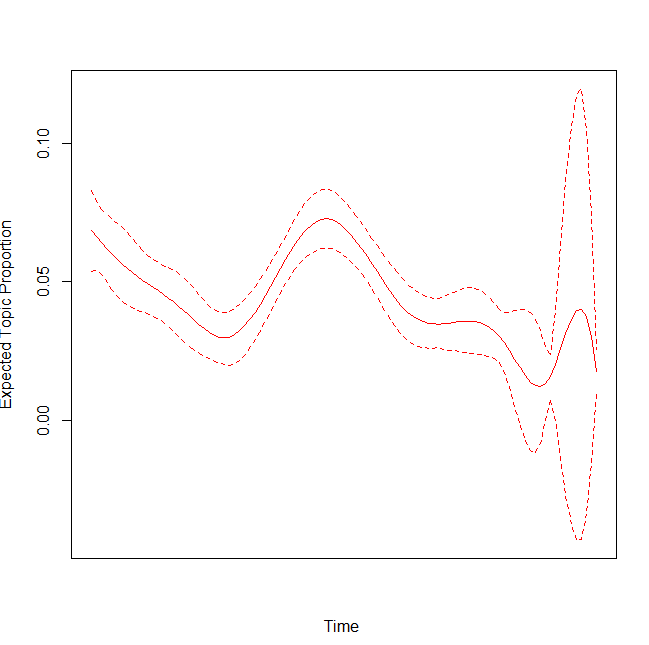
# year 변수가 토픽에 미치는 영향
#excluded가 낮은 year에서 해당 토픽이 peak가 됨
x11()
plot(prep, 'year', method = "continuous", topics = 15,
model = z, printlegend = FALSE, xaxt = "n", xlab = "Time ")
yearseq <- seq(from = as.Date('2010-01-01'), to = as.Date('2021-01-01'), by='year')
yearnames <- year(yearseq)
axis(1,at = as.numeric(yearseq) - min(as.numeric(yearseq)),labels = yearnames)
# 변수 별 단어
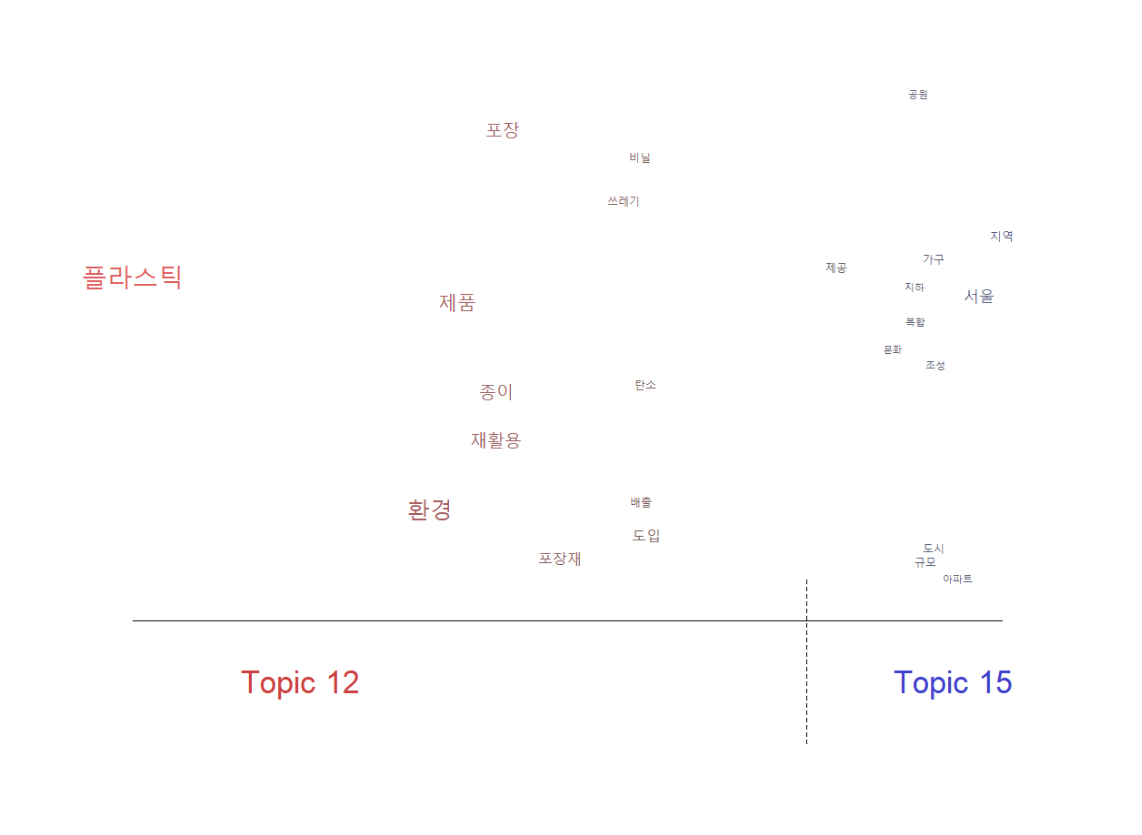
plot(poliblogContent, type= "perspectives", topics=15)
# 토픽 별 단어
plot(agendaPrevFit, type = "perspectives", topics = c(12, 15))
library(tidytext)
library(ggplot2)
library(dplyr)
x11()
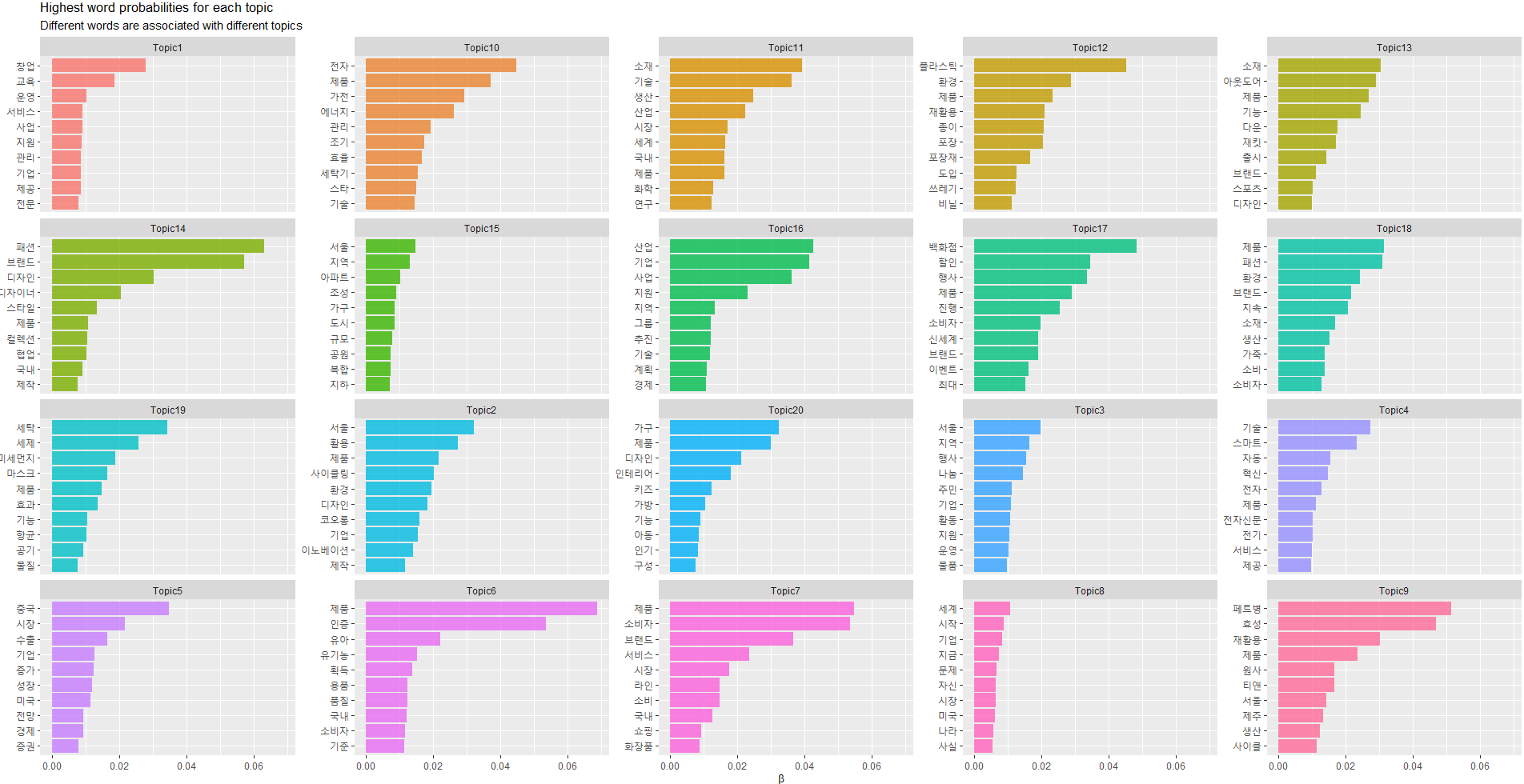
td_beta <- tidy(agendaPrevFit)
td_beta %>%
group_by(topic) %>%
top_n(10 , beta) %>%
ungroup() %>%
mutate(topic = paste0("Topic", topic), term = reorder_within(term, beta, topic)) %>%
ggplot(aes(term, beta, fill = as.factor(topic))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~ topic, scales = "free_y") +
coord_flip() +
scale_x_reordered() +
labs(x = NULL, y = expression(beta), title = "Highest word probabilities for each topic",
subtitle = "Different words are associated with different topics")
## 문서 별 토픽
doc_topic=tidy(agendaPrevFit,matrix='gamma') %>% group_by(document) %>% top_n(1,gamma) %>% ungroup() %>% arrange(document)
doc_topic
data_ALL$topic = doc_topic$topic
#topic correlations
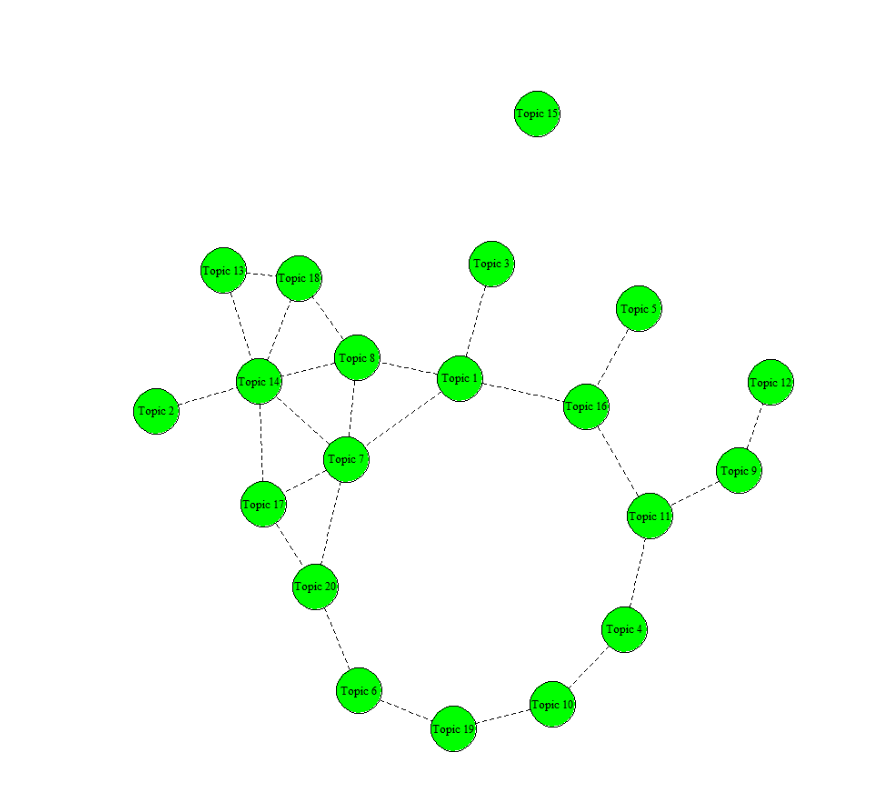
mod.out.corr <- topicCorr(agendaPrevFit)
plot(mod.out.corr)
# criterion: Highest prob, FREX, LIFT, SCORE
df.agenda.prob <- data.frame(t(labelTopics(agendaPrevFit, n = 1)$prob))
df.agenda.frex <- data.frame(t(labelTopics(agendaPrevFit, n = 1)$frex))
df.agenda.lift <- data.frame(t(labelTopics(agendaPrevFit, n = 1)$lift))
df.agenda.score <- data.frame(t(labelTopics(agendaPrevFit, n = 1)$score))
### 워드클라우드
library(Rcpp)
library(wordcloud)
library(wordcloud2)
## 200대 키워드만 선정 토픽 별 워드클라우드 그리기
get_topic_term= function(x){
term=tidy(agendaPrevFit) %>% filter(topic==x)
colnames(term)[2] = 'feature'
colnames(term)[3] = 'frequency'
term= term[,c(2,3)] %>% arrange(-frequency)
term=term[1:200,]
wordcloud2(term, fontFamily="Malgun Gothic", size = 0.5, minRotation=0, maxRotation=0)
}
get_topic_term(1)
get_topic_term(2)
get_topic_term(3)
get_topic_term(4)
get_topic_term(5)
get_topic_term(15)
get_topic_term(20)
# 워드클라우드 그리기
word_fre1 <- word_fre[1:200,]
wordcloud2(word_fre1, fontFamily="Malgun Gothic", size = 0.5, minRotation=0, maxRotation=0)
# 중요 단어 tf_idf
tf_idf=dfm2.trim %>% dfm_tfidf(scheme_tf = "prop", scheme_df = "inverse")
word_fre_2=textstat_frequency(tf_idf,force=TRUE)
word_fre2 = word_fre_2[1:200]
wordcloud2(word_fre2, fontFamily="Malgun Gothic", size = 0.2, minRotation=0, maxRotation=0)





문송 개발자