데이터 모델링 이야기 1
1. 데이터 모델링 관계 정리
- 표는 관계형 데이터베이스 (Relational Database, RDB)의 릴레이션 (relation)을 의미한다.
- 이질적인 정보가 혼재되어 있다면 데이터 간의 종속성을 기준으로 분리, 즉 정규화해야 함을 의미한다.
- 표 사이의 연결고리는 데이터 모델의 관계 (Relationship) 속성에 해당한다.
- 회원번호는 엔터티의 주 식별자 (Primary identifier) 속성에 해당한다.
- 'AUDI'를 '아우디'로 표기하기로 한 것은 데이터 표준화의 개념 중 코드 (Code)와 관련 있다.
2. 업무 데이터의 이해
- 업무 데이터를 이해한다는 것은 기업의 비즈니스를 데이터 측면에서 처음부터 끝까지 조명해보는 것이다. 즉 업무 프로세스나 프로세스 지원 시스템의 기능과는 완전히 분리해서 생각해야 한다.
- 고객과 상품 사이에는 주문이라는 관계가 있다. 한 고객이 여러 상품을 주문할 수 있고 하나의 상품을 여러 고객이 주문할 수 있는 다대다(M:N) 관계다. 이를 관계형 데이터베이스로 구현하기 위해 M:N 관계를 해소 (Resolve)하면 주문이라는 관계 엔터티로 만들어진다. 그리고 주문과 상품은 여전히 다대다 관계이므로, 이것 역시 풀어주면 고객, 주문, 주문상품, 상품이라는 엔터티가 도출된다.
- 이러한 방식은 상당히 모호하며, 데이터 모델링의 기본 원리를 생각할 때 자연스럽지 못한 전개 방식이다.
- "고객이 특정 상품을 평생 단 한 번만 구매할 수 있다"라는 요건이 있다면 구매는 고객과 상품의 관계 엔터티로 볼 수 있다. 그러나 고객이 같은 상품을 여러번 살 수 있도록 하려면 "시간"이라는 개념이 하나 더 관계되어야 한다.
- 주문은 상품보다는 오히려 주문 시각이라는 시간 개념이 절대적으로 개입되는 고객 행위로 보아야 한다. 이처럼 비즈니스 행위, 즉 트랜잭션에는 반드시 시간의 개념이 개입되며, 이는 행위 엔터티의 식별자에 타임스태프와 같은 시각 속성이 존재하는 것에서 확인할 수 있다.
3. 디멘션 (Dimension) 모델링
- 판매량이라는 Fact (사실 값)와 이 값을 정의하는 데 필요한 3가지 표현 방식, 즉 Dimension (차원) X, Y, Z의 좌표로 모형화되었다.
- Fact를 만들기 위한 Dimension은 얼마든지 추가될 수 있으며, 각 Dimension은 Fact를 표현하는 하나의 관점이 된다.
- 이처럼 Dimension은 Fact를 그룹화하거나 한정화 (필터링)하는 목적으로 사용될 수 있다.
- 일반적으로 Dimension 혹은 그룹핑을 위한 논리적인 계층구조는 1:N 형태의 엔터티간 부모-자식 관계를 만든다. Fact를 규정하는 개별 Dimension은 각각 테이블로 만들어져 Fact Table의 상위 테이블이 되어야 하며, Dimension 내의 계층구조를 표현하려면 각 Dimension은 다시 상/하위 테이블로 분리되어야 한다.
- Fact 테이블인 <판매>는 각 Dimension 테이블의 기본 키 (Primary Key, PK)를 외래 키 (Foreign Key, FK)로 하여 서로 관계로 연결된 하위 테이블로 만들어진다.
4. OTLP와 OLAP, 데이터 모델링의 목표
- 어떤 데이터들은 트랜잭션을 데이터베이스에 저장한 거래 처리 데이터이고, 어떤 데이터들은 이미 데이터베이스에 저장된 거래 데이터를 가공한 분석정보이다.
- 거래 처리 영역과 분석 정보 영역은 본질적으로 다른 목적을 가진다. 거래 처리 영역은 비즈니스 활동 자체를 지원한다. 반면 분석 정보 영역은 비즈니스 활동에 대한 측정, 평가, 분석, 예측, 개선 등을 지원한다.
- 데이터는 그 성격과 목적에 따라 거래 처리 데이터와 분석 정보 데이터로 나뉘며, 각각을 별도의 영역에서 관리한다.
- 여기서 거래 처리 영역을 OLTP (On-Line Transaction Processing)라 하고, OLTP에 저장된 운영 데이터를 통합하고 변환하여 분석정보를 생산하는 영역을 OLAP (On-Line Analysis Processing)이라 한다.
- 통상적으로 OLAP는 DBMS나 OLAP 애플리케이션과 같은 정보 분석 도구를 의미하는 용어로 많이 사용되며, OLTP에 대응되는 개념으로는 데이터웨어하우스 (DW)라는 용어를 흔히 사용한다.
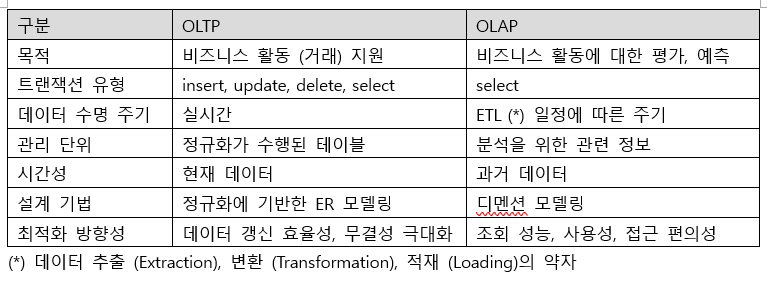
-OLTP는 정규화를 중심으로, OLAP는 분석, 집계의 관점, Dimension을 중심으로 모델링 해야 한다. - OLAP 데이터 모델은 OLTP 데이터 모델보다 정규화가 덜 된 형태일 수 있으니, BI의 초보 설계자는 OLAP의 반정규화 (denormalization)된 모델을 정규화하고 싶은 유혹을 뿌리쳐야 한다.
※ 여기서 잠깐 : 데이터 무결성 (Data Integrity) 이란?
- 데이터 무결성(영어: data integrity)은 컴퓨팅 분야에서 완전한 수명 주기를 거치며 데이터의 정확성과 일관성을 유지하고 보증하는 것을 가리키며, 데이터베이스나 RDBMS 시스템의 중요한 기능이다.
- 데이터 무결성은 일반적으로 일련의 무결성 제한이나 규칙에 의해 데이터베이스 시스템이 강제한다. 이러한 종류들의 무결성 제한들은 관계형 데이터 모델의 기본 기능의 일부로 볼 수 있다.: 개체 무결성, 참조 무결성, 범위 무결성
- 개체 무결성(Entity integrity)은 고유 키(유일 키)의 개념과 관련된다. 개체 무결성은 모든 테이블이 기본 키(primary key)를 가져야 하며 기본 키로 선택된 열은 고유하여야 하며 빈 값은 허용치 않음을 규정한다.
- 참조 무결성(Referential integrity)은 외래 키(외부 키)의 개념과 관련된다. 참조 무결성 규칙은 모든 외래 키 값은 두 가지 상태 가운데 하나에만 속함을 규정한다. 일반적인 상태는 외래 키 값이 데이터베이스의 특정 테이블의 기본 키 값을 참조하는 것이다. 이따금 이는 비즈니스의 규칙에 따라 달라질 수 있으며 외래 키 값은 빈 값을 허용한다.
- 범위 무결성(Domain integrity)은 정의된 범위에서 관계형 데이터베이스의 모든 열이 선언되도록 규정한다.
5. 범주화와 추상화, 엔터티의 본질
- 비즈니스 맥락에서 본질이 되는 개체를 명확히 떼어내는 방법, 결국 엔터티를 모델링하는 연습을 집중적으로 해야 함
- 고객 통합 영역에서 항상 언급되는 동일인 인식 문제
- 본질과 현상 구분
- 본질 : 사람으로서의 근본적인 정보 (물리적으로 유일한 개체인 나)
- 현상 : 논리적 맥락이나 역할 (학생, 교수, 은행원, 고객)
- 범주화 : 유사한 것들을 일정하게 묶는 프로세스
- 추상화 : 문제 영역에서 가장 핵심적인 특성만을 추리는 과정. (서울대 교육학용어사전 : 추상화는 구체적 사물들의 공통된 특징, 즉 추상적 특징을 파악하여 인식의 대상으로 삼는 행위이다. 추상화가 가능한 개체들은 그것들이 소유하고 있는 특성의 이름으로 하나의 집합 class를 이룬다. 그러므로 추상화한다는 것은 여러 개체를 집합으로 파악하는 것과 동일하다.)
- 결국 데이터 모델링이란?
- 엔터티랑 업무 수행에 필요한 데이터를 성격이 유사한 것끼리 모아놓은 집합이다.
- 모델링이란 정보를 담는 최소 단위인 속성의 종속성을 분석하여 유사한 것끼리 모으고 독립적인 것은 분리하는 과정이다.
- 이러한 과정을 통해 속성의 제 위치 (엔터티)를 찾아낼 수 있다.
- 즉, 관계형 데이터 모델은 나의 정보는 내가 집약해서 갖고, 남의 정보는 필요할 때 관계를 통해 찾아서 원하는 뷰를 만들어내는 구조다.
- 데이터 모델링이란 결국 어떤 개체가 속하는 범주를 규명하여 개체 집합을 분리하고 묶는 수준을 고민하는 과정이다.

개발자 궁금해서 왔습니다.