지난 주 웹메이커스 프로젝트를 위해 html, css 를 통해 웹사이트 뼈대를 만들었고, 이제 실제 공시 데이터들을 받아오기 위한 작업을 해보겠다.
Company 별 데이터를 가져와야 하는데, Company의 Primary Key는 Company Ticker (상장코드)로 하겠다.
예를들어 Apple의 Ticker는 "AAPL"이고, Ford의 Ticker는 "F"이다.
https://www.advfn.com/ 라는 곳에서 NASDAQ, NYSE, AMEX Stock Market에 상장된 기업들의 Ticker를 Python으로 스크래핑하여 가져오도록 하겠다.
- 먼저 필요한 라이브러리를 설치한다.
import requests
import pandas as pd
from bs4 import BeautifulSouppandas는 처음 써봤는데 데이터분석을 위해 필요한 라이브러리이다.
- Company name과 Company ticker을 가져오기 위한 list를 생성해주고, 스크래핑하기 위한 기초 작업을 해본다.
먼저 NASDAQ에 상장된 기업들을 가져올 거다.
웹사이트를 검사해보면 다음과 같이 tr0, tr1 각 행을 나타내고, 각 행이 Company Name과 Company Ticker를 담고 있다.
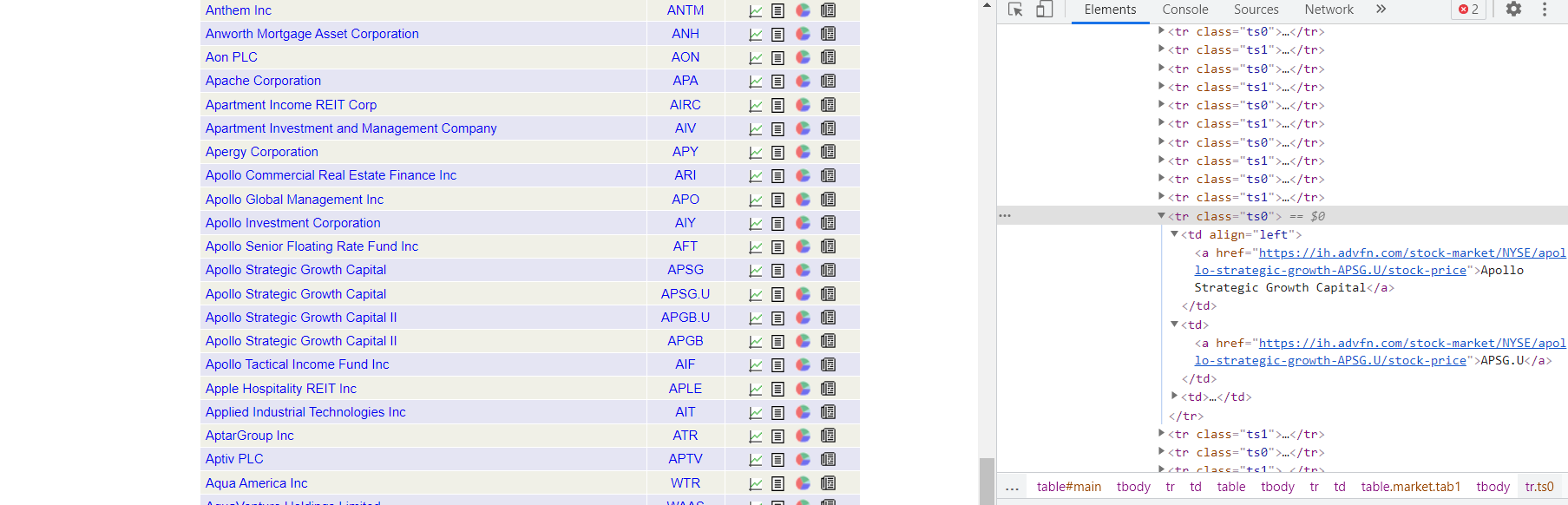
이에 다음과 같은 코드로 스크래핑한다.
company_name = []
company_ticker = []
URL = 'https://www.advfn.com/nyse/newyorkstockexchange.asp?companies=A'
page = requests.get(URL)
soup = BeautifulSoup(page.text, 'html.parser')
odd_rows = soup.find_all('tr',attrs={'class':'ts0'})
even_rows = soup.find_all('tr',attrs={'class':'ts1'})
for i in odd_rows:
row = i.find_all('td')
company_name.append(row[0].text.strip())
company_ticker.append(row[1].text.strip())
for i in even_rows:
row = i.find_all('td')
company_name.append(row[0].text.strip())
company_ticker.append(row[1].text.strip())- 위의 URL을 보면 알겠지만, 해당 URL은 Company 이름이 알파벳 A로 시작하는 회사만 가져온다. A~Z까지 모든 기업을 갖고 오려면 어떻게 해야할까? 알파벳마다 URL을 바꿔서 여러번 반복 작업을 해줘야 할까?
그렇지 않고 다음과 같이 하였다.
def scrape_stock_symbols(Letter):
Letter = Letter.upper()
URL = 'https://www.advfn.com/nyse/newyorkstockexchange.asp?companies=' + Letter
page = requests.get(URL)
soup = BeautifulSoup(page.text, 'html.parser')
odd_rows = soup.find_all('tr', attrs={'class':'ts0'})
even_rows = soup.find_all('tr',attrs={'class':'ts1'})
for i in odd_rows:
row = i.find_all('td')
company_name.append(row[0].text.strip())
company_ticker.append(row[1].text.strip())
for i in even_rows:
row = i.find_all('td')
company_name.append(row[0].text.strip())
company_ticker.append(row[1].text.strip())
return (company_name, company_ticker)
# alphabet의 모든 문자 리스트를 가져옴
import string
string.ascii_uppercase
# 모든 기업의 ticker를 받기위해 모든 alphabet 문자를 Loop through 함
for char in string.ascii_uppercase:
(temp_name, temp_ticker) = scrape_stock_symbols(char)이렇게 가져온 data를 dataFrame으로 만든다.
data = pd.DataFrame(columns=['company_name','company_ticker'])
data['company_name'] = temp_name
data['company_ticker'] = temp_ticker
data = data[data['company_name'='']
print(data)이렇게 하면 다음과 같이 출력된다.
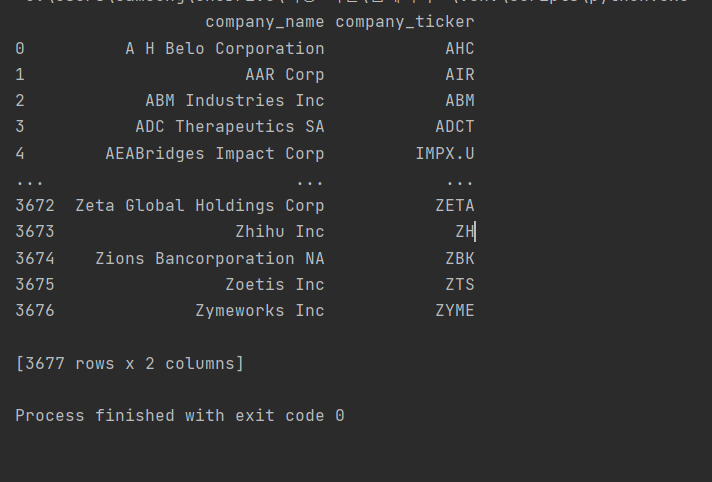
NYSE에 상장된 3676개 기업의 Company name과 company ticker를 가져왔다.
Mongo DB에는 다음 코드로 저장했다.
# Description: This program scrapes stock tickers and their company name from a website
# Import the dependencies
import requests
import pandas as pd
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.company
import string
string.ascii_uppercase
# Create a function to scrape the data
for char in string.ascii_uppercase:
URL = 'https://www.advfn.com/amex/americanstockexchange.asp?companies=' + char
page = requests.get(URL)
soup = BeautifulSoup(page.text, 'html.parser')
odd_rows = soup.find_all('tr', attrs={'class': 'ts0'})
even_rows = soup.find_all('tr', attrs={'class': 'ts1'})
# Loop through every letter in the alphabet to get all of the tickers and company names from the website
for i in odd_rows:
row = i.find_all('td')
company_name = row[0].text.strip() # CompanyName
company_ticker = row[1].text.strip() # CompanyTicker
doc = {
"company_ticker": company_ticker,
"company_name": company_name
}
db.company.insert_one(doc)
for i in even_rows:
row = i.find_all('td')
company_name = row[0].text.strip() # CompanyName
company_ticker = row[1].text.strip() # CompanyTicker
doc = {
"company_ticker": company_ticker,
"company_name": company_name
}
db.company.insert_one(doc)
이렇게 해서 NASDAQ, NYSE, AMEX 합쳐 총 7,213개 기업의 name과 ticker를 저장했다.
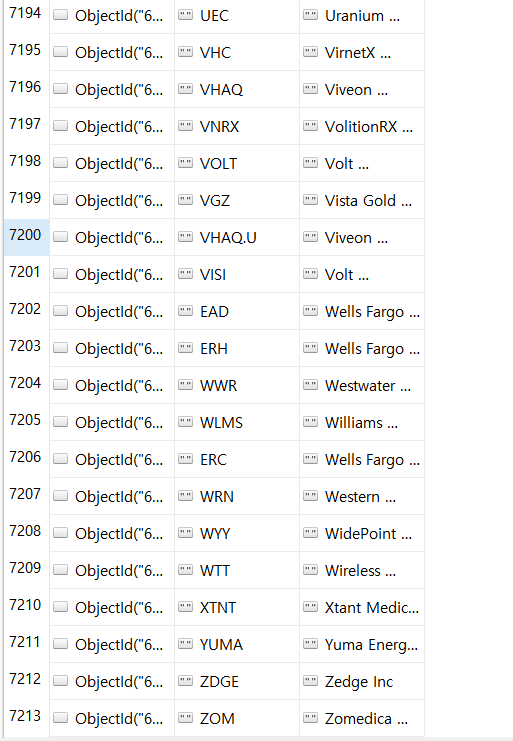
PK를 가져왔으니, PK별 속성 값들을 가져와야 한다.
SEC API를 활용하는 것보다 Yahoo Finance에서 스크래핑 해오는 게 더 쉬울 것 같아서 그렇게 진행하려 한다.
그럼 다음 포스팅에서 보자.
