지난 포스팅에서 7,0000여개의 Company Ticker Symbol을 찾았으니, 이제 각 Company Ticker 별로 기업 상세 페이지를 보여줄 수 있도록 데이터들을 구해오려 한다.
처음에는 sec open api를 가져오려 하였는데, 원하는 데이터를 찾지 못하기도 하였고, 어떻게 할지 조금 막막하였는데, yahoo finance에서 이미 많은 데이터를 내가 원하는 형태로 보여주고 있고, SEC Filings URL도 json data 형태로 제공하고 있어서, 난이도를 낮춰?서 yahoo finance를 scraping 해보기로 했다.
yahoo finance의 AAPL 메인 화면이다.
이 화면에서 오른쪽 마우스 클릭하여 "페이지 소스 보기"를 클릭하면 방대하게 블라블라 뭐라고 쓰인 것이 나온다. (부분 발췌 예시)
여기 작성되어 있는 것을 보면, 이 웹페이지가 적혀있는 여러 javascript 함수로부터 동적으로 데이터를 로딩해 오는 것을 알 수 있다.
데이터들이 javascript 함수에 내재되어 있기 때문에, 다음과 같은 순서로 진행한다.
- script의 tag를 확인한다.
- script내 contents를 추출한다.
- contents를 조금 다듬어서 json format string으로 만들고, python dictionary로 변환해준다.
1.에서 말했듯이 script의 tag를 가져와야 하는데 tag에 특별한 점이 없어서 정규 표현을 활용한다.
그런 다음, 해당 정규 표현과 일치하는 text가 있는 script element를 찾아낸다.
이 script가 우리가 원하는 데이터를 둘러싸고 있기 때문에, 원하는 데이터만 갖고 오기 위해 context의 시작에서 두 번째 글자부터 끝에서 12번째 글자까지만 가져온다.
(사실 지금 내가 무슨 설명을 하고 있는지 잘 모르겠다.
완전히 이해하지 못한 상태인데, 다음 유튜브를 참고했으니 필요한 사람은 가서 보면 될 것 같다. https://www.youtube.com/watch?v=fw4gK-leExw)
이렇게 해서 다음과 같은 코드를 작성하였다.
import re
import json
from bs4 import BeautifulSoup
import requests
response = requests.get(url_financials.format(stock, stock))
soup = BeautifulSoup(response.text, 'html.parser')
pattern = re.compile(r'\s--\sData\s--\s')
script_data = soup.find('script', text=pattern).contents[0]
script_data[:500]
script_data[-500:]
start = script_data.find("context") - 2
json_data = json.loads(script_data[start:-12])위와 같은 기본 코드에서 시작하면 내가 익숙한 json 형태의 data가 나오니, 여기서 부터 데이터를 원하는 대로 가져오면 된다.
가져올 데이터는 총 6개로 나뉜다.
- financials
- profile
- holders
- SEC filings
- price summary
- ESG
1. financials
해당 기업의 2020, 2019, 2018, 2017 4개년의 손익계산서, 재무상태표, 현금흐름표의 데이터를 가져온다.
json 내에 0번째 contents는 2020년이며 1,2,3 순서로 갈수록 연도가 역행한다.
annual_is = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['incomeStatementHistory'][
'incomeStatementHistory']
total_revenue_0 = annual_is[0]['totalRevenue']['raw']
cost_revenue_0 = annual_is[0]['costOfRevenue']['raw']
gross_profit_0 = annual_is[0]['grossProfit']['raw']
operating_expense_0 = annual_is[0]['totalOperatingExpenses']['raw']
operating_income_0 = annual_is[0]['operatingIncome']['raw']
pretax_income_0 = annual_is[0]['incomeBeforeTax']['raw']
net_income_0 = annual_is[0]['netIncome']['raw']
annual_bs = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['balanceSheetHistory'][
'balanceSheetStatements']
total_asset_0 = annual_bs[0]['totalAssets']['raw']
current_asset_0 = annual_bs[0]['totalCurrentAssets']['raw']
noncurrent_asset_0 = int(annual_bs[0]['totalAssets']['raw']) - int(
annual_bs[0]['totalCurrentAssets']['raw'])
total_liab_0 = annual_bs[0]['totalLiab']['raw']
current_liab_0 = annual_bs[0]['totalCurrentLiabilities']['raw']
noncurrent_liab_0 = int(annual_bs[0]['totalLiab']['raw']) - int(annual_bs[0]['totalCurrentLiabilities']['raw'])
total_equity_0 = annual_bs[0]['totalStockholderEquity']['raw']
annual_cf = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['cashflowStatementHistory'][
'cashflowStatements']
operating_cashflow_0 = annual_cf[0]['totalCashFromOperatingActivities']['raw']
investing_cashflow_0 = annual_cf[0]['totalCashflowsFromInvestingActivities']['raw']
financing_cashflow_0 = annual_cf[0]['totalCashFromFinancingActivities']['raw']
changes_cash_0 = int(operating_cashflow_0) + int(investing_cashflow_0) + int(financing_cashflow_0)
capital_expenditure_0 = annual_cf[0]['capitalExpenditures']['raw']
issuance_stock_0 = annual_cf[0]['issuanceOfStock']['raw']2. profile
기업 이름, 주소, 산업, 이사, 웹사이트 등 기본 정보와 다양한 종류의 risk를 나타내는 지표를 가져온다.
이사는 제일 중요한 2명 정도만 가져온다.
# 1. Company Information
profile = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['assetProfile']
summary = profile['longBusinessSummary']
sector = profile['sector']
industry = profile['industry']
employees = profile['fullTimeEmployees']
address = profile['address1']
city = profile['city']
state = profile['state']
country = profile['country']
phone = profile['phone']
website = profile['website']
# 2. Officers
officer1_name = profile[0]['name']
officer1_title = profile[0]['title']
officer1_yearborn = profile[0]['yearBorn']
officer1_pay = profile[0]['totalPay']
officer2_name = profile[1]['name']
officer2_title = profile[1]['title']
officer2_yearborn = profile[1]['yearBorn']
officer2_pay = profile[1]['totalPay']
# 2. Risk
overall_risk = profile['overallRisk']
audit_risk = profile['auditRisk']
compensation_risk = profile['compensationRisk']
shareholder_risk = profile['shareHolderRightsRisk']
board_risk = profile['boardRisk']3. holders
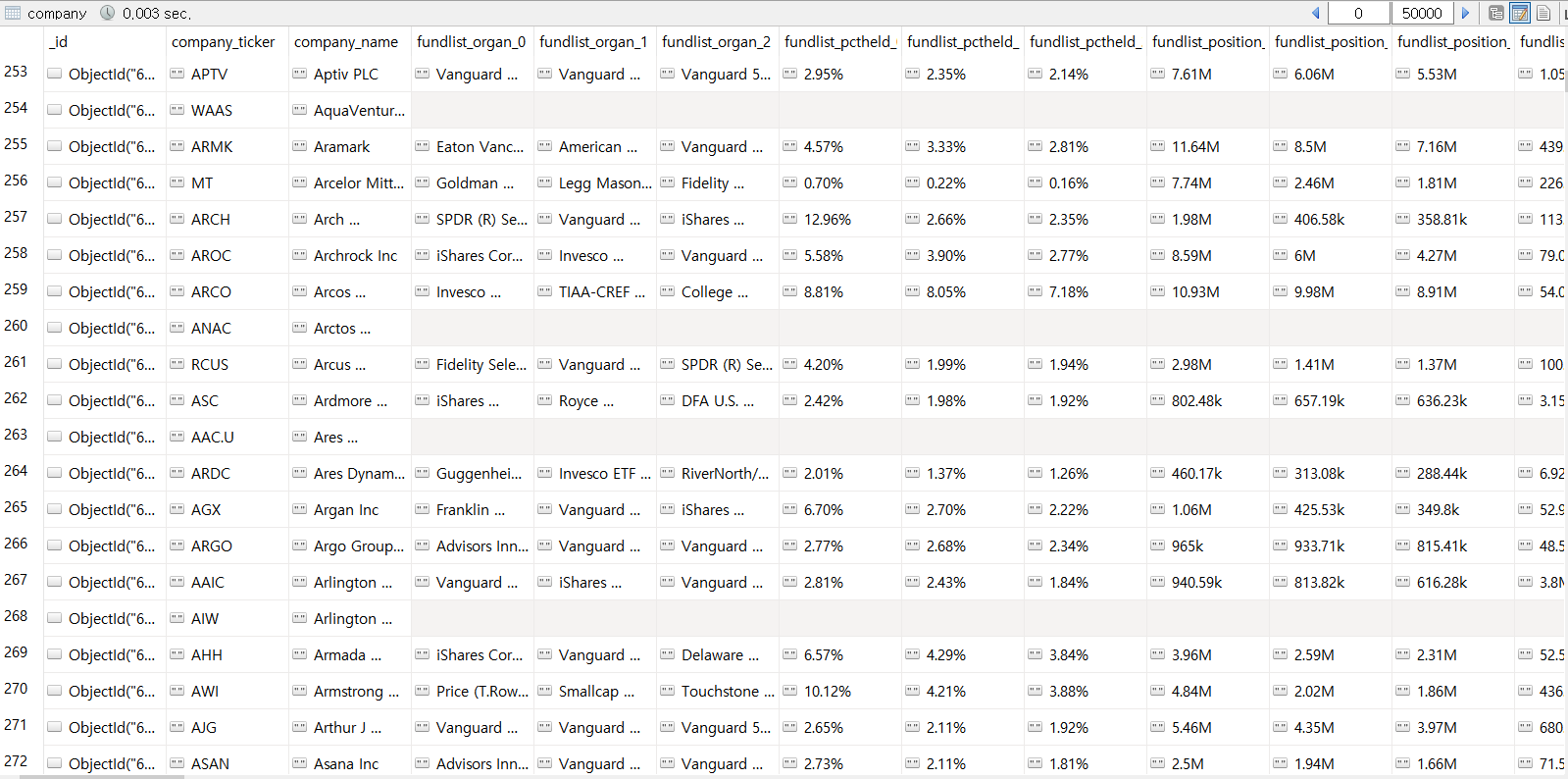
기업의 주주현황을 가져온다. 기업 내부 주주, 외부 기관 주주의 비율과 외부 기관 주주의 수를 시작으로, 주요 기관 투자자 3순위, 주요 펀드 투자자 3순위가 누구인지 가져온다.
# 1. Major Holders
holders = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['majorHoldersBreakdown']
insider_holders = holders['insidersPercentHeld']['fmt']
institutional_holders = holders['institutionsPercentHeld']['fmt']
institutional_float = holders['institutionsFloatPercentHeld']['fmt']
institutional_count = holders['institutionsCount']['raw']
# 2. institutionOwnership
ownerlist = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['institutionOwnership']['ownershipList']
ownerlist_organ_0 = ownerlist[0]['organization']
ownerlist_pctheld_0 = ownerlist[0]['pctHeld']['fmt']
ownerlist_position_0 = ownerlist[0]['position']['fmt']
ownerlist_value_0 = ownerlist[0]['value']['fmt']
# 3. fundownership
fundlist = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['fundOwnership']['ownershipList']
fundlist_organ_0 = fundlist[0]['organization']
fundlist_pctheld_0 = fundlist[0]['pctHeld']['fmt']
fundlist_position_0 = fundlist[0]['position']['fmt']
fundlist_value_0 = fundlist[0]['value']['fmt']4. SEC filings
최근 EDGAR의 주요 SEG filings를 5개 정도 title, data, url로 가져온다.
for i in range(5):
date = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['secFilings']['filings'][i]['date']
title = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['secFilings']['filings'][i]['title']
edgarurl = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['secFilings']['filings'][i]['edgarUrl']
filings = date, title, edgarurl5. price summary
주가 정보인 최근 거래 마감 가격, 200 영업일 평균 가격, 영업일 최고가, 영업일 최저가를 알아보고, 이와 관련된 배당율, beta, PE Ratio, 시가총액, 거래량을 가져온다.
summary = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['summaryDetail']
price_previouseclose = summary['previousClose']['raw']
price_200dayaverage = summary['twoHundredDayAverage']['raw']
price_marketdaylow = summary['regularMarketDayLow']['raw']
price_marketdayhigh = summary['regularMarketDayHigh']['raw']
summary_divdend = summary['dividendRate']['raw']
summary_beta = summary['beta']['raw']
summary_pe = summary['trailingPE']['fmt']
summary_marketcap = summary['marketCap']['fmt']
summary_volume = summary['averageVolume']['fmt']6.ESG
기업의 Total ESG Score과 부문별 (환경, 사회, 지배구조) Score을 가져온다.
esg = json_data['context']['dispatcher']['stores']['QuoteSummaryStore']['esgScores']
esg_total = esg['totalEsg']['fmt']
esg_environment = esg['environmentScore']['fmt']
esg_social = esg['socialScore']['fmt']
esg_governance = esg['governanceScore']['fmt']여기까지 해서 데이터를 추출할 수 있는 기본 코드를 알아보았다.
코드를 보면 알겠지만, 구조가 상당히 단순하고 반복된다.
데이터 field가 좀 많이 생성될 것 같다.
이제 company ticker 별 속성 데이터를 추출할 수 있는 방법을 찾았다. 지난 시간에 가져온 company ticker 데이터들에 대한 scraping을 할 것이다.
아무 기업이 아닌 내 데이터베이스에 있는 company ticker들에 대한 정보를 가져오기 위해 for문을 써서 db에서 company ticker들을 읽어오게 하였다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.company
companies = list(db.company.find({}, {'_id': False}))
for company in companies:
stock = company['company_ticker']
url_profile = 'https://finance.yahoo.com/quote/{}/profile?p={}'
url_financials = 'https://finance.yahoo.com/quote/{}/financials?p={}'
url_holder = 'https://finance.yahoo.com/quote/{}/holders?p={}'
url_summary = 'https://finance.yahoo.com/quote/{}?p={}'
url_esg = 'https://finance.yahoo.com/quote/{}/sustainability?p={}'
company ticker들을 읽어온 후 데이터를 출력한다.
출력한 데이터는 다시 matching되는 company ticker record 행에 대해 field를 생성하여 데이터를 추가해 준다.
이를 위해 update문을 써서 데이터를 추가해 주었다.(아래 예시는 price summary 속성의 데이터들)
db.company.update_one({'company_ticker': stock}, {'$set': {
'price_previouseclose': price_previouseclose,
'price_200dayaverage': price_200dayaverage,
'price_marketdaylow': price_marketdaylow,
'price_marketdayhigh': price_marketdayhigh,
'summary_divdend': summary_divdend,
'summary_beta': summary_beta,
'summary_pe': summary_pe,
'summary_marketcap': summary_marketcap,
'summary_volume': summary_volume
}})이렇게 해서 run을 돌려보면 기업에 따라 KeyError, TypeError, IndexError, Attribute Error가 발생하기도 한다. 근데 이게 왜 발생하는지 알아보기 전에, 일단 받을 수 있는 데이터는 다 받으면 좋을 것 같아서. try / except / continue 문을 활용했다. 그래서 데이터베이스를 보면 중간중간 비워져 있는 데이터들이 생긴다.
try:
except TypeError:
continue
except KeyError:
continue
except IndexError:
continue
except AttributeError:
continue
db.company.update_one({'company_ticker': stock}, {'$set': {
}})
현재 financials를 다 받은 데이터베이스는 다음과 같다.
보면 비워진 행들이 꽤 많다..ㅠ
비워진 행인 기업을 검색해보니, financials이 1개년만 있거나, 년도가 있긴 한데 특정 계정 데이터가 없거나하는데, 이 경우 부분적으로만 받아올 수 있음 좋겠는데 아예 통째로 행이 비워지니 아쉽다.

holdings는 다음과 같이 저장된다.
holdings도 financials 만큼은 아니지만 비워진 곳이 있다.
(근데 지금 한 2000개 정도 데이터를 받았는데, 대부분 기업의 1위 기관투자자가 Blackrock 아님 Vanguard 그룹인게 너무 눈에 띄게 보여서 신기했다.)