
들어가며
지금까지 배운 컴포넌트들과 서킷 등을 이용해서 실제로 CPU를 어떻게 구현하고 CPU가 명령어들을 어떻게 처리하는지를 알아보자.
CPU
Performance
cpu performance에 영향을 주는 요인에는 무엇이 있을가?
- Instruction count : 명령어의 개수는 ISA와 컴파일러에 의해 결정된다.
- CPI : 명령어당 사이클의 갯수인데 이는 CPU가 어떻게 디자인이 되어있는 지에 의해 결정된다. 이번 챕터에서는 Single-cycle에 대해서 다루는데 이는 하나의 명령어가 하나의 사이클을 소비한다는 뜻이다.
- Cycle time : 한 번의 사이클을 도는데에 걸리는 시간이다. CPU의 속도는 clock rate에 의해서 결정되는데 이는 clock의 주기가 얼마나 길고 짧은 지에 의해서 결정된다. clock rate를 결정하는데 있어 Cycle time은 많은 영향을 주는 요소이다.
Construction
cpu는 DataPath와 Control Path로 구성된다. 뒤에서 자세히 알아보겠지만 각 요소에 대해서 간단하게 알아보자.
- DataPath: bus, register, ALU 등으로 구성되며 데이터를 이동하고 데이터를 이용해서 실제 산술, 논리 연산을 수행한다.
- Control path: control unit, PC 등으로 구성되며 명령어를 처리하기 위해서 CPU의 동작은 제어한다.
Instruction Execution
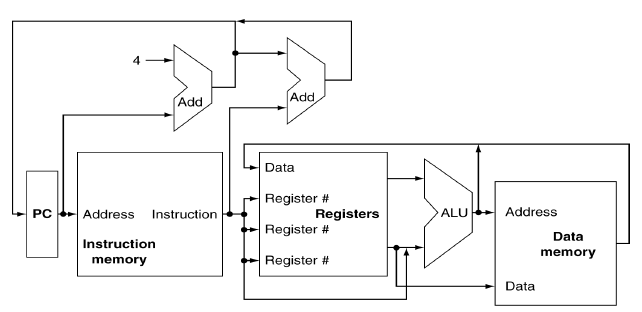
명령어를 실제로 실행하는 과정은 다음과 같다.
- PC값에 위치한 명령어를 Fetch한다.
- Register file(레지스터의 집합체)에서 레지스터의 값을 읽는다.
- ALU를 이용해서 산술, 논리 연산을 하거나 메인메모리에서 데이터를 읽어오는 등 로직을 수행한다.
- PC값을 4만큼 늘린다.(단위는 byte)
DataPath 구성요소
-
Combinational Elements
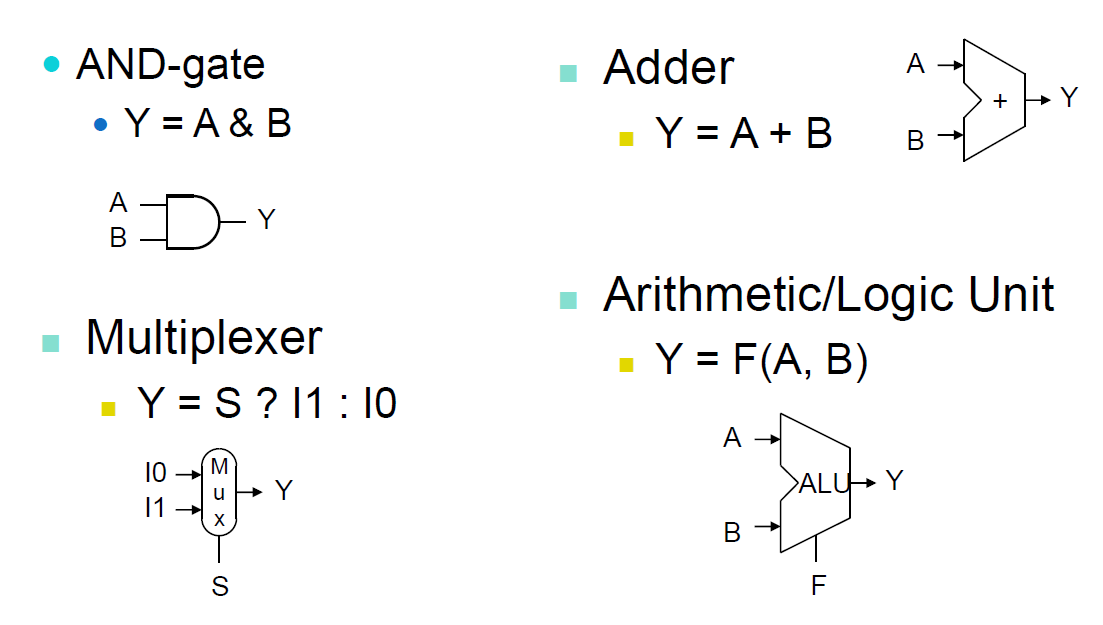
명령어들을 수행하기 위해서 지금까지 알아본 서킷 및 회로를 두고 우리는 Combinational Elements라고 한다. -
State Elements
컴퓨터의 시스템에서 컴퓨터의 현재 상태를 유지 및 저장하기 위해 사용되는 요소이다.
자세히 알아보자.
먼저 State elements를 구성하는 요소에 대해서 알아보자. 먼저 S-R latch이다.
S-R latch
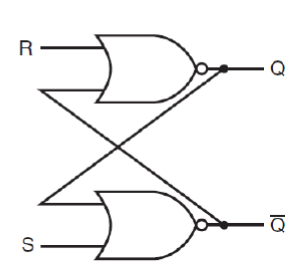
set-reset 자물쇠의 약자로 과거의 상태를 이용해서 다음 상태를 어떻게 유지할 것인지를 결정하는 서킷이다. 보면은 R과 S 앞에 있는 NOR 게이트의 input에 Q와 !Q가 들어가는 것을 볼 수 있다. 이는 이전의 Q값에 대한 정보이다.
Q와 !Q는 서로 같은 값을 가질 수 없으며 같은 값을 가지게 되는 경우에는 input이 거부된다.
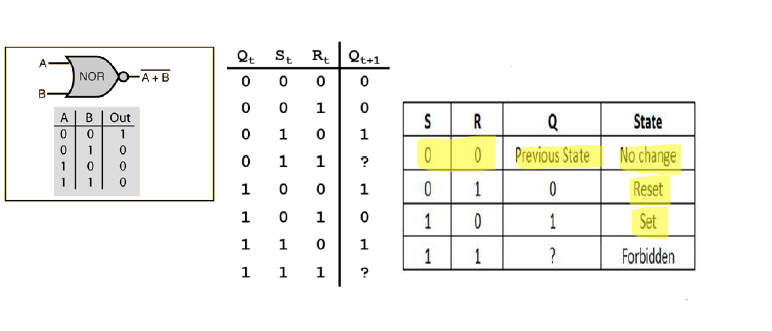
먼저 S와 R에 둘 다 0이 들어가면은 R쪽의 NOR 게이트에는 !Q가 들어가서 output 값으로는 Q가 나오게 되고 S쪽에는 Q가 들어가서 !Q가 나오게 된다.
S, R에 각각 0, 1이 들어가면은 Q값은 무조건 0이 된다. 그럼 그 Q값이 S쪽 NOR에 들어가고 output값은 1이 된다.
둘 다 1이 들어가면은 거부된다.
D latch
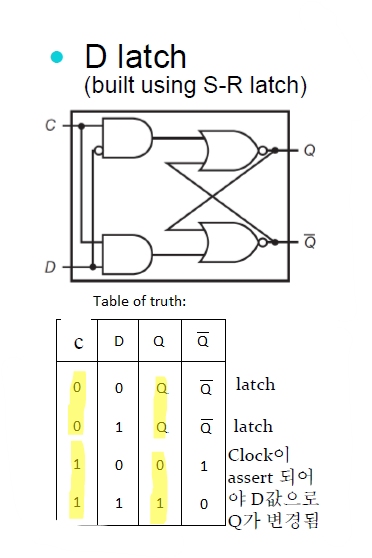
S-R latch에서 각각 S와 R에 1이 들어가면 안된다는 점을 보완한 D latch이다.
C에 0이 인가되면 S-R latch에서 S와 R이 무조건 0이 들어가게 된다. 그래서 이전의 상태를 유지하게 된다.
C에 1이 인가되면 D의 값이 Q값이 된다.
flip-flop
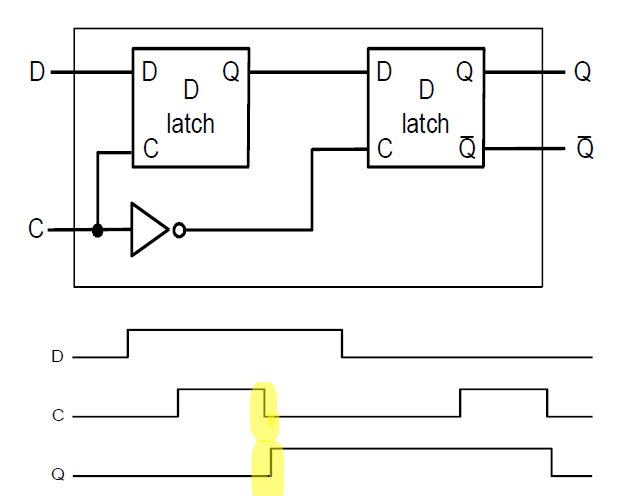
2개의 D-latch를 이용해서 우리는 flip-flop을 만들 수 있다. flip-flop의 특징은 C의 신호가 rising 하거나 falling 할 때 D의 값을 Q의 값으로 가져간다는 특징이 있다.
위 경우에는 C의 신호가 2번째 D latch로 가는 길목에 NOT 게이트가 달려있기 때문에 Falling edge에서 D의 신호가 Q의 신호로 인가된다. Rising edge에 똑같은 기능을 구현하고 싶다면 NOT게이트를 1번째 D-latch로 가는 길에 달아주면 된다.
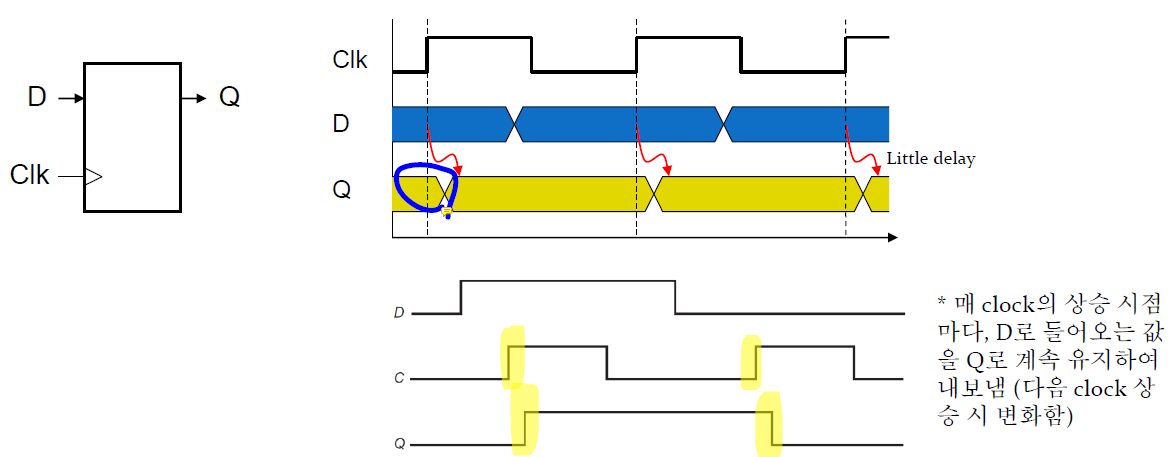
위와 같이 clock의 주기마다 D의 값이 Q로 유지되며 그 과정에서 약간의 delay가 발생한다.
Register Files
레지스터들은 읽어지거나 쓰여질 수 있다. 그리고 각 레지스터는 64개의 비트들로 구성되어 있다.
flip-flop은 하나의 비트의 값을 변경하거나 유지, 저장할 수 있으며 하나의 레지스터는 64개의 flip-flop으로 이루어져있다.
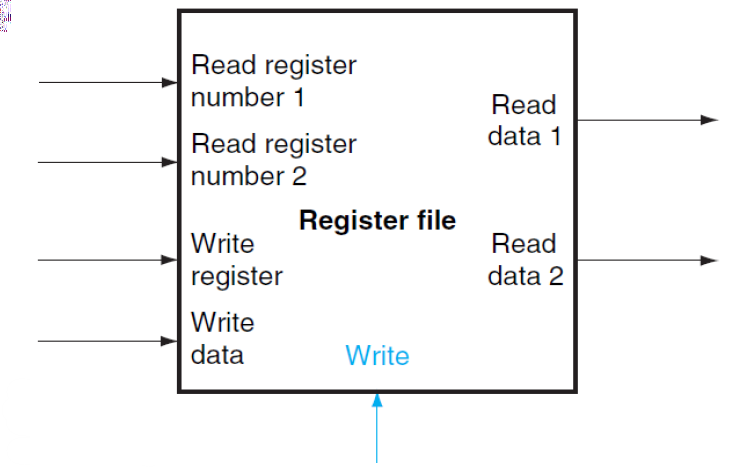
레지스터 파일은 위처럼 생겼고 3개의 피연산자를 입력받을 수 있다. (2개의 read register, 1개의 write register) 그리고 2개의 read register을 읽은 값을 출력하는 2개의 output이 있다.
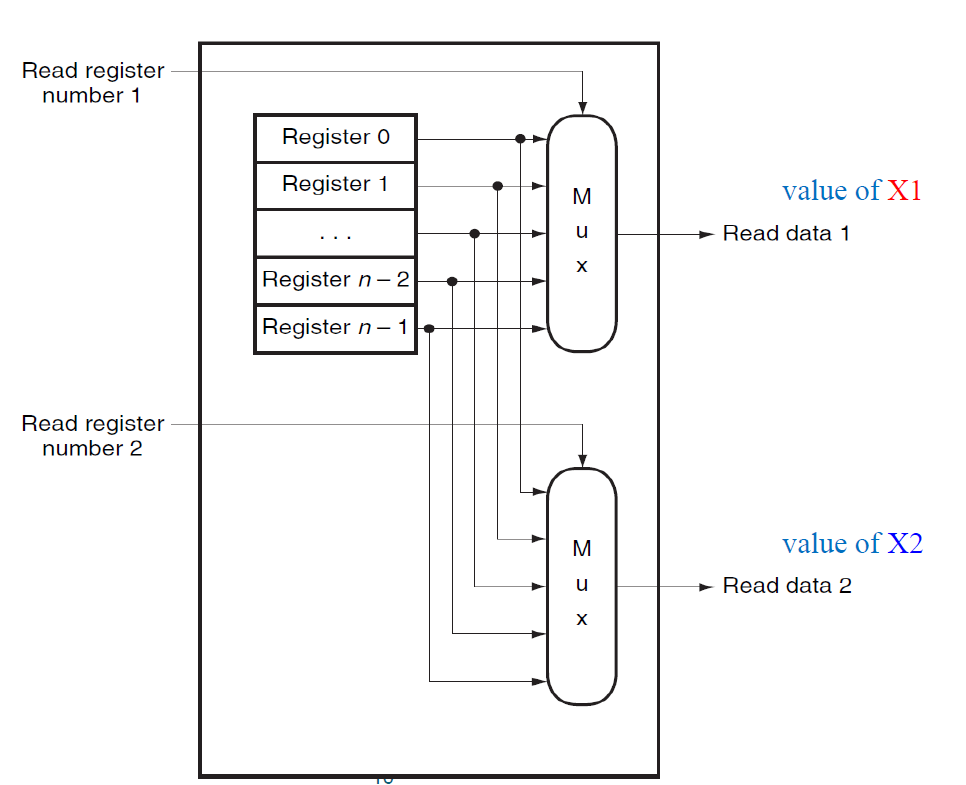
어떤 레지스터의 값을 output으로 내보낼 지는 mux를 통해서 결정할 수 있다.
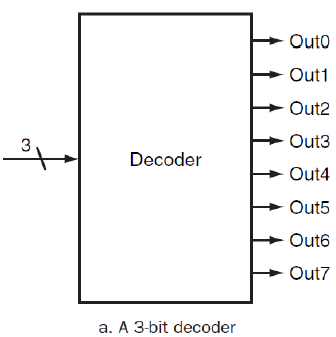
decoder
one-hot의 형태로, n-bit를 입력받아서 2^n개의 output을 만들어내는 기능을 한다.
Datapath
Single-cycle design에서 CPU가 명령어를 어떻게 실행하는지 알아보자.
Instruction Fetch
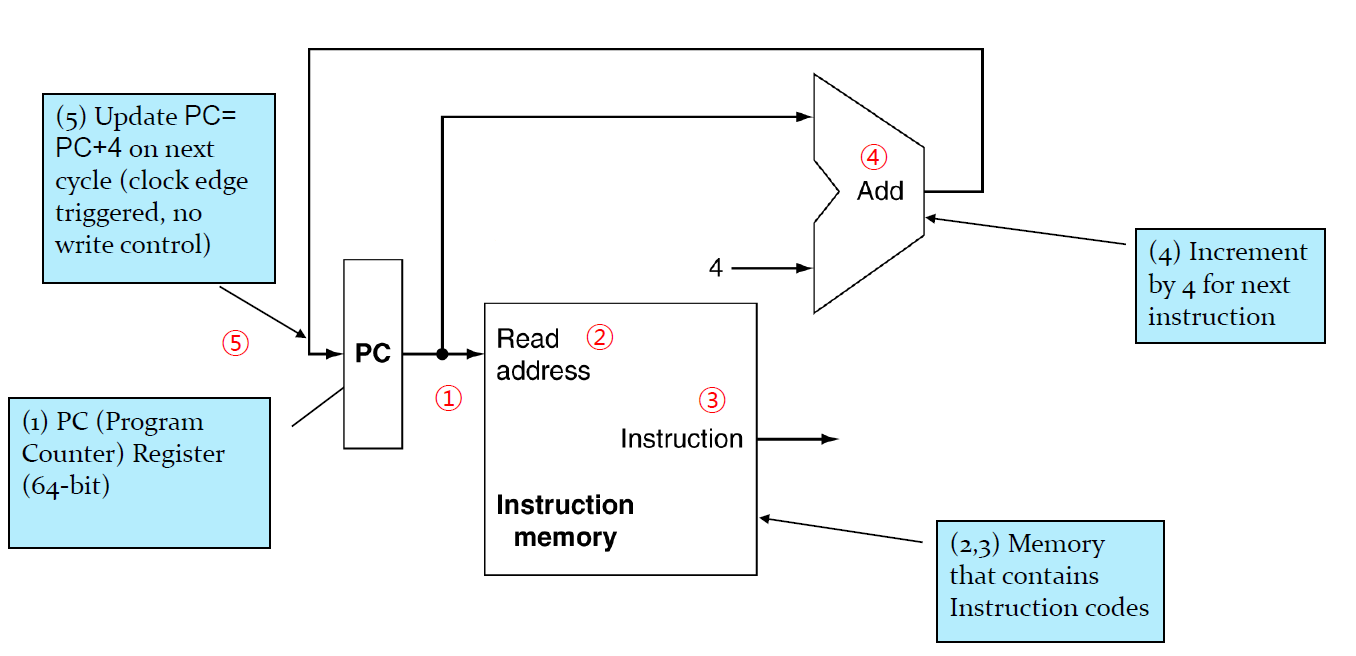
일단 Instruction memory라는 주어진 주소값에 있는 명령어를 읽어와서 signal을 내보내는 하드웨어가 있다. 그래서 명령어를 fetch하는 과정은 다음과 같다.
- 현재 PC값을 input으로 받아서 수행해ㅑㅇ하는 명령어의 주소를 차즌ㄴ다.
- 내부적으로 명령어를 해석한다.
- 명령어를 내보낸 후 명령어 수행을 한다.
- PC에다가 4를 더한다.(다음 명령어의 주소를 취한다.) 단위가 byte이고 명령어의 크기는 4bytes이므로 4를 더하는 것이다.
R-Type Instruction
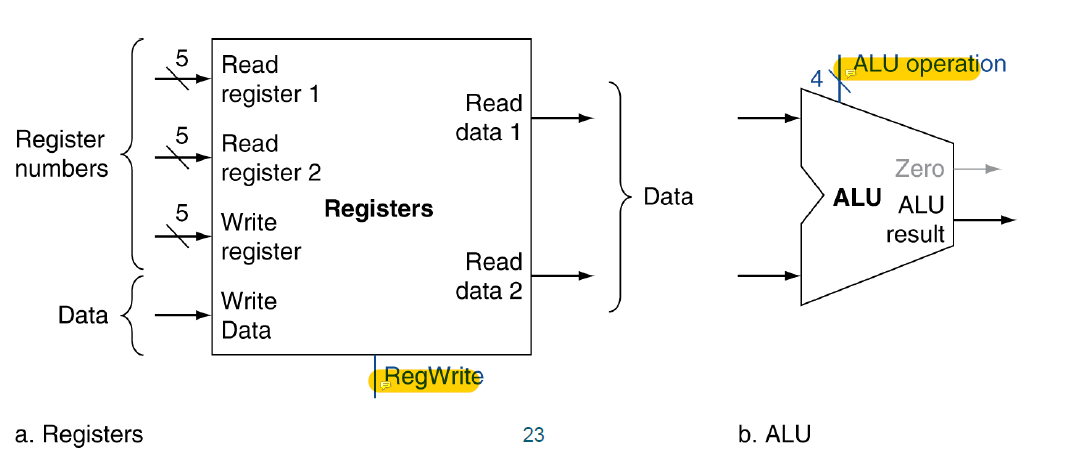
먼저 Register files는 앞서 얘기했듯이 4개의 input이 있다. 3개의 input은 피연산자이므로 각각 5개의 bit를 입력받는다. 그리고 data는 레지스터에 저장될 데이터이므로 레지스터의 크기인 64비트이다. 또 하나의 signal을 입력을 받는다. 바로 RegWrite이다. 레지스터에 쓰기 동작을 수행할 것인지에 대한 여부를 입력받는다.
Register files는 input으로 들어온 Read Register 2개에 대응하는 값을 output으로 내보낸 후에 ALU에 전달한다. ALU는 어떤 연산을 수행할 것인지에 대한 signal(ALU Operation)을 입력받으며 그 목록은
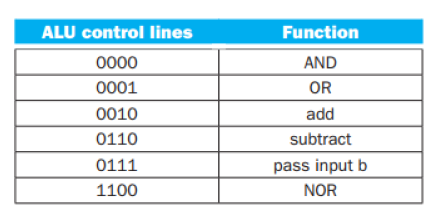
위와 같다. pass input b는 input값이 0이 맞는지 아닌지에 대한 여부를 계산하는 명령어이며 수행결과로 condition code 중 zero를 만들어낸다.
D-Type Instruction
D-Type 명령어의 포멧을 확인하면 2개의 레지스터와 1개의 immediate 값을 입력받는다는 것을 알 수 있다. 둘 다 결국엔 메인메모리에 I/O 작업을 수행하므로 실제로 메인메모리와 소통하는 하드웨어가 필요하다. 그것을 Data memory unit이라고 한다.
또, immmediate는 결국엔 레지스터에 들어있는 값과 더해져서 실제 주소값을 만들어내야하기 때문에 64비트의 형태로 변경되어야 한다. 그래서 32비트 길이의 명령어를 input으로 받아서 immediate값을 64비트의 길이로 output으로 내보내는 Sign extension unit이 있다.

Data memory에는 데이터를 메인메모리에 입력할 것인지 출력할 것인지에 대해서 2개의 비트를 통해서 입력을 받는다.
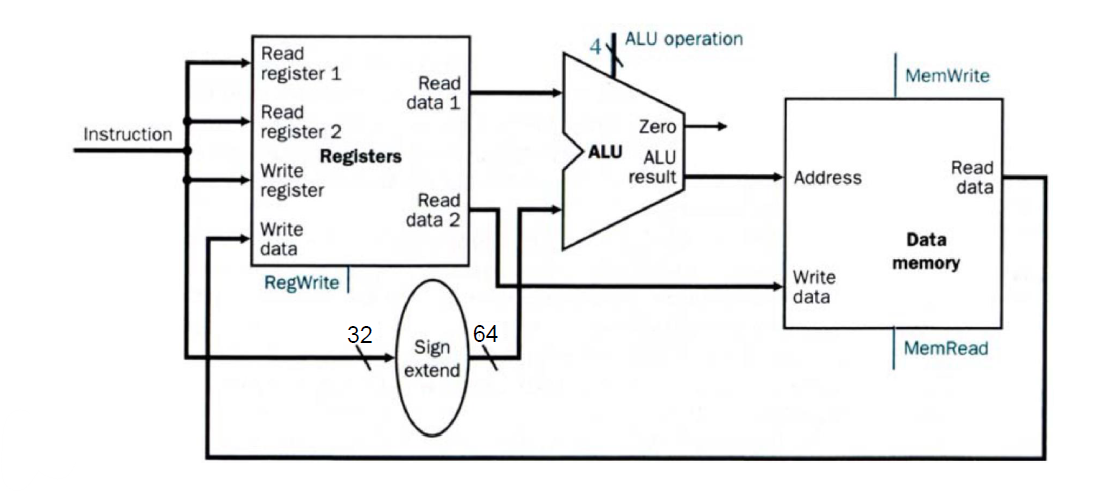
그래서 D-Type을 수행하기 위한 DataPath 구조는 위와 같다. 그리고 여기서 Load와 Store을 구분하기 위한 mux가 추가되면
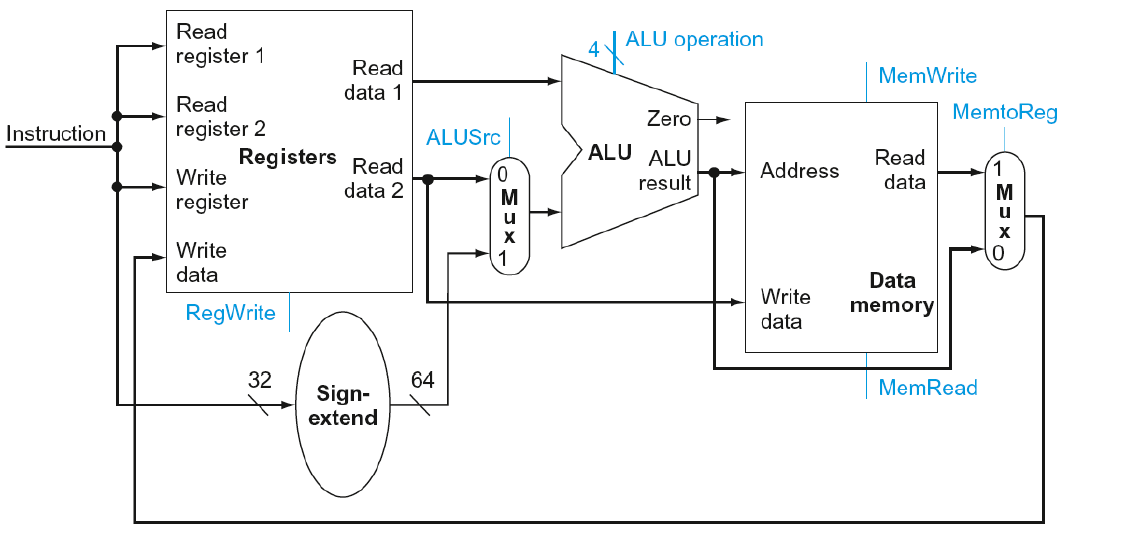
위와 같은 구조를 볼 수 있다. 2개의 mux가 존재하는 것을 볼 수 있다.
Store을 할 때 위 mux들이 어떤 값을 인가받는지에 대해서 알아보자.
먼저 Store명령어는 어디에다가 저장할 것인지에 대한 주소와 어떤 레지스터에 있는 값을 저장할 것인지에 대한 정보, 그리고 immediate가 있다.
Read register1에는 메인 메모리에 저장할 base address가 들어있고 Read register2에는 메인 메모리에 저장할 data가 들어있다. 그리고 ALU를 통해서 메인 메모리의 어디에다가 저장할 건지 address를 계산하게 되는데 이 때, 첫번째 mux가 1로 인가됨으로써 immediate 값을 64비트로 변경한 후 메인메모리 주소를 계산하게 된다.
그러면 Data memory unit에서 메인 메모리의 주소와 data를 받고 MemWrite signal이 1로 들어오면서 메인메모리에 쓰기 동작을 수행하게 된다.
Branch Instruction
CBZ 명령어를 예시로, 먼저 레지스터로 주어진 값이 0인지 아닌지에 대해서 판별한 후에 그 값이 0이면은 label로 분기한다.
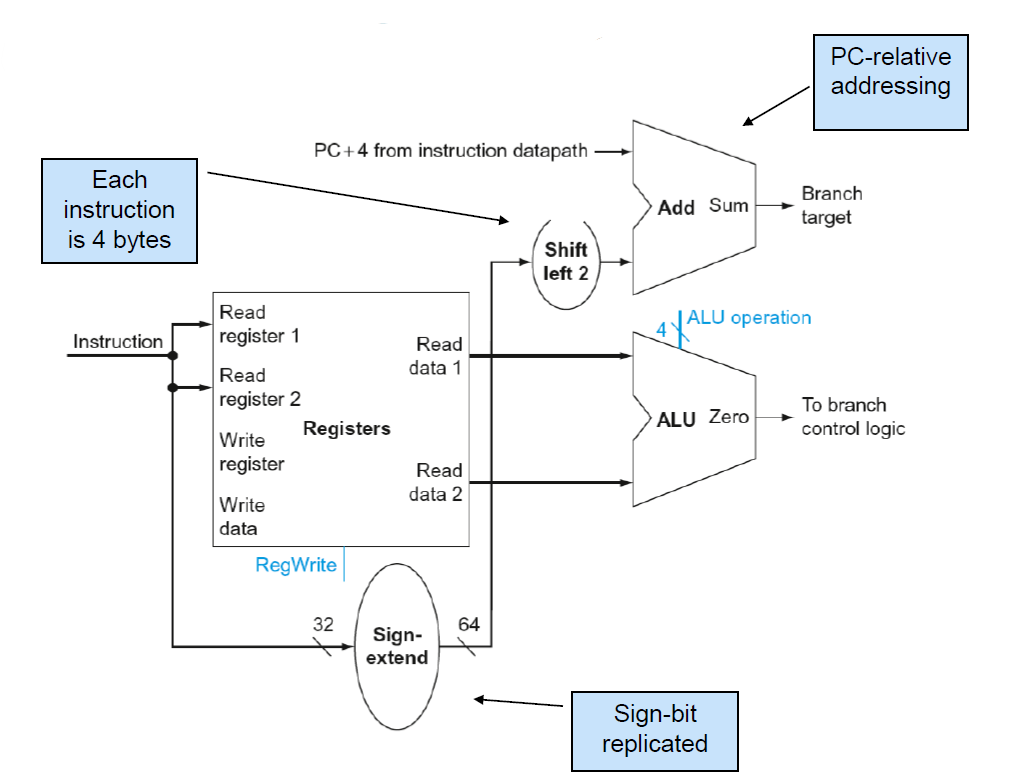
Branch Instruction을 수행하기 위한 Data path 구조는 위와 같다.
add 연산을 수행하는 덧셈기가 하나 추가된 것을 볼 수 있고 또 그 바로 직전에 2bit LSL연산이 위치해있다는 것을 알 수 있다. 2bit LSL이 있는 이유는 Branch 명령어에 저장된 label은 현재 PC값의 기준으로 얼마나 떨어져있는지를 word단위로 저장해놓은 것이다. 즉, 실제로 PC값과 label값을 산술연산해서 분기할 address를 구하기 위해서는 4를 곱해서 실제 address로 변환해야하기 때문에 2bit LSL이 위치해있는 것이다.
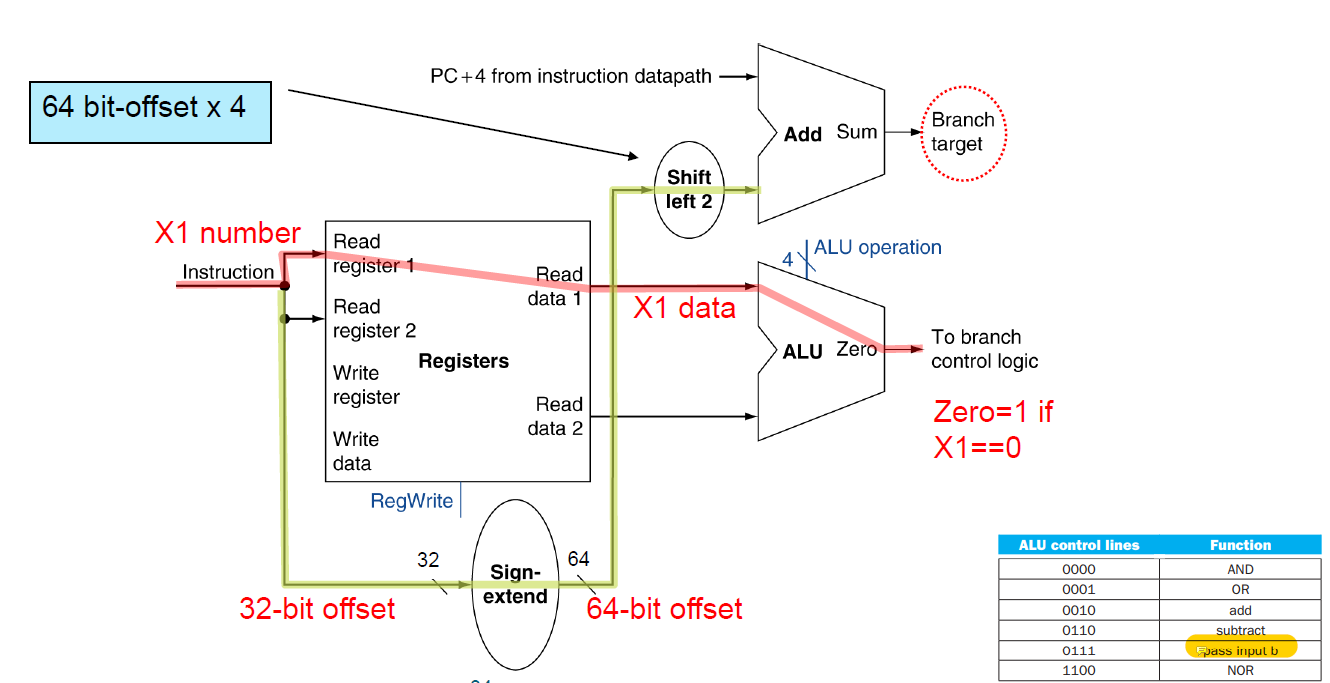
실제로 데이터가 흐르는 방향은 위의 사진에서 확인할 수 있다. Read register1는 실제로 값이 들어있는 레지스터이고 그 값이 0인지 아닌지는 ALU에서 판별한다. 그러면 ALU의 ALU operation signal은 pass input b이고 결과로 zero(condition code)를 만들어낸다.
그리고 명령어는 Sign-extend unit에게 전달되어서 PC값에서 어느정도 떨어져있는지를 게산하기 위한 label의 주소를 64비트로 추출된다.
CBZ가 아니라 S-suffix가 붙은 명령어는
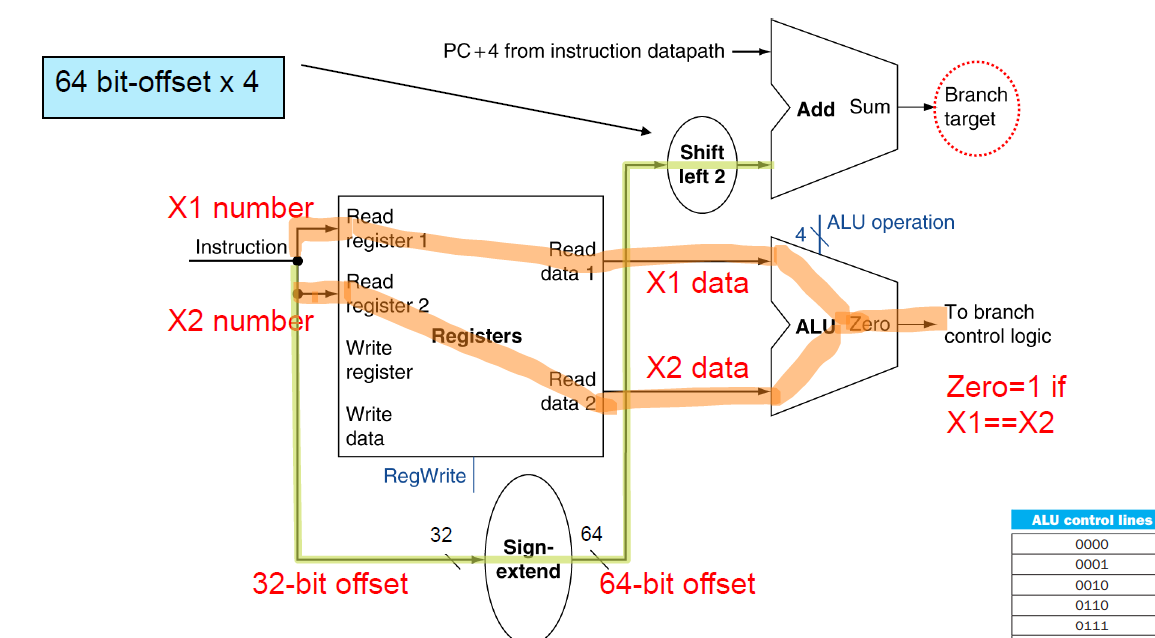
위 사진과 같은 흐름을 따라서 condition code가 생성된다.
이렇게 한 사이클에 명령어를 시행할 수 있는 것은 바로 명령어를 해석해서 저장하는 Instruction memory와 레지스터를 저장하는 Register files, 그리고 메모리에서 데이터를 읽어오는 Data memory unit이 분리되어있기 때문이다.
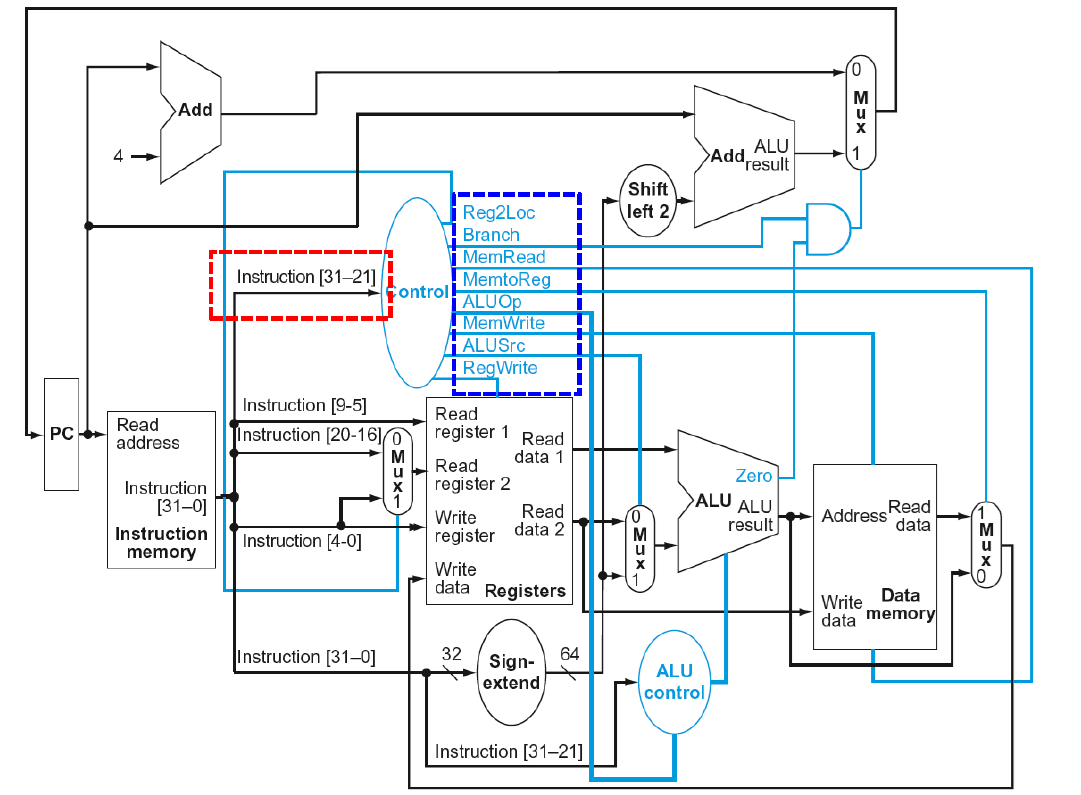
Single Cycle CPU에서 전체 Datapath는
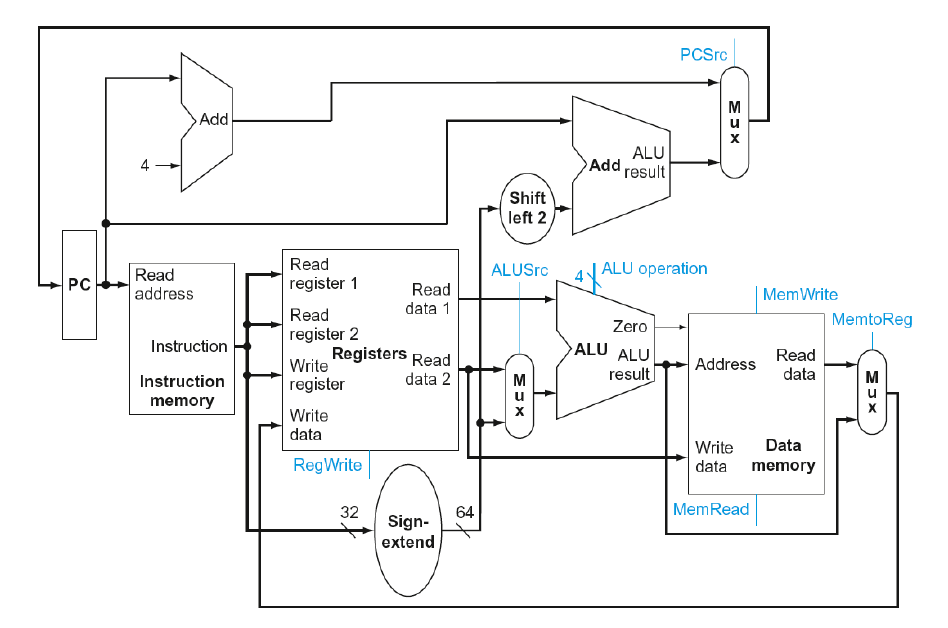
위 사진과 같다. 자 그러면 여기서 저 Control 신호들은 누가 만들어내는걸까? 답은 Main Control이다.
Control path
이제 ALU나 다른 component에 어떤 동작을 해야하는지 제어신호를 보내는 Control path에 대해서 알아보자.
ALU Control
ALU는 단순히 두 레지스터의 값을 산술, 논리 연산하는데에만 그치지 않고, D-Type 명령어에서 메모리 주소를 게산하거나 CBZ명령어에서 값이 0인지 아닌지를 식별하는 곳에서도 사용된다.

그림이 다소 복잡해보일 수는 있지만 주목해야할 포인트는 3가지이다. 중앙에 파란색 타원으로 표시된 Control, 그리고 ALU, 그 아래에 있는 ALU Control 이 세 개이다.
먼저 Control은 Instruction의 opcode를 해석해서 어떤 연산을 수행해야하는지를 ALU control에게 2개의 비트로 알려준다. 좌측하단에 그 표가 있다. 그래서 D-type이나 CBZ타입일 경우에는 ALU가 해야할 연산은 하나 뿐이다. 그런데 R-Type일 경우에는 수행해야하는 경우의 수가 여러 개이다. 그래서 ALU control은 32비트 길이의 전체 Instruction을 입력값으로 받아서 어떤 연산을 해야하는지를 구체화해서 ALU에게 ALU operation(signal)을 전달한다.
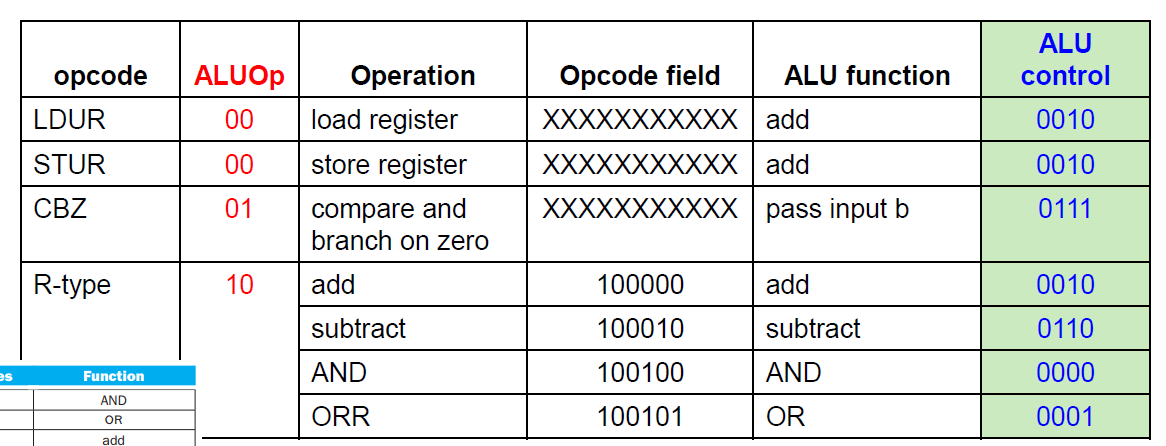
위 사진처럼, D-type와 CBZ명령어의 경우에는 수행해야 하는 ALU function이 고정이므로 opcode에 영향을 받지 않아서 Don't care임을 확인할 수 있다.
Signal
위와 같이 Control은 많은 signal을 생성해서 각 component에게 전달한다. 그 종류는
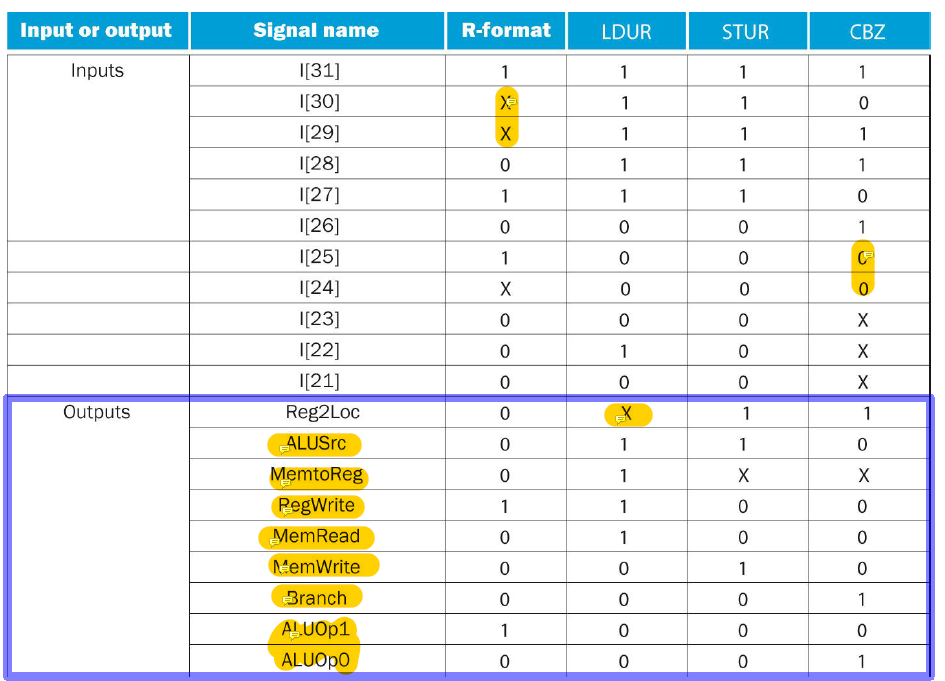
위 사진과 같다. input으로 opcode를 받고 그 opcode에 따라서 각각 다른 output(signal)을 생성한다.
- ALUSrc:
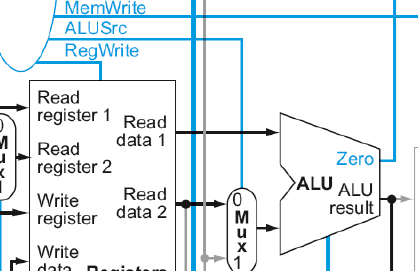
ALUSrc는 Register files 뒤에 위치한 mux에게 전달되며, register files에서 읽은 데이터와 immediate 중에서 어떤 값을 ALU에게 전달할 것인지를 결정한다. - MemtoReg:
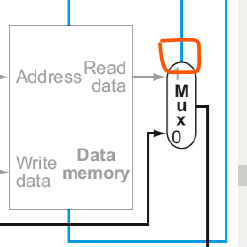
위 빨간색으로 표시된 곳이 MemtoReg가 전달되는 곳이다. 잘 보이지는 않지만, Data memory unit에서 읽은 데이터와 ALU에서 계산된 데이터 중에서 어떤 데이터를 register에 전달해서 write을 할 건지를 결정한다. - RegWrite: 레지스터에 데이터를 저장할 건지 아닌지를 결정하낟.
- MemWrite, MemRead: 메모리에서 데이터를 읽을건지 쓸건지에 대한 정보를 Data memory unit에 전달한다.
- Branch: 분기가 되면은 PC값에 label 데이터를 전달하기 위해 사용된다.
- ALUOp0, 1: ALU control에게 어떤 Type의 명령어가 들어왔는지 알려주는 signal이다.
한계점
Single-Cycle에서는 연산을 위해서 많은 control signal과 mux가 필요하다. 그리고 모든 명령어들을 한 사이클 내에서 해결하기 때문에 clock 속도를 높이는데에 한계가 분명하다. LDUR 의 경우 메모리에서 데이터를 가져오기까지 기다여야하기 때문에 시간이 오래 걸린다.
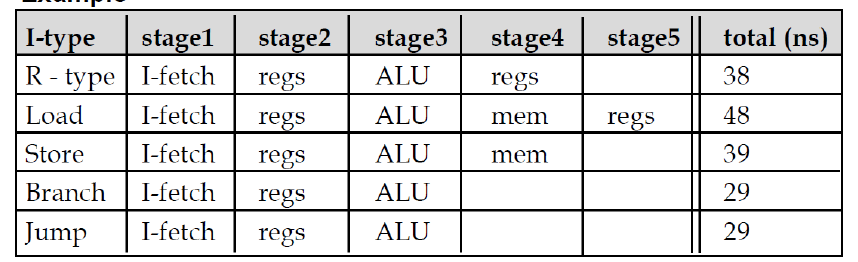
실제로도 Load 명령어가 다른 명령에 비해서 확연히 속도가 느리다는 것을 알 수 있고 이로 인해 single-cycle design은 현재 상장되었다.
