✏️ Kafka
- apache kafka 는 실시간으로 기록되는 스트림을 게시, 구독, 저장, 처리할 수 있는 분산형 이벤트 스트리밍 플랫폼이다.
- 여러 소스에서 data 스트림을 처리하고,
여러 사용자에게 전달하도록 설걔되었다.
- 즉, A 지점에서 B 지점까지 이동하는 것 외에 필요한 모든 곳에서 대규모 데이터를 동시에 이동시킬 수 있다.
📍 필요성
-
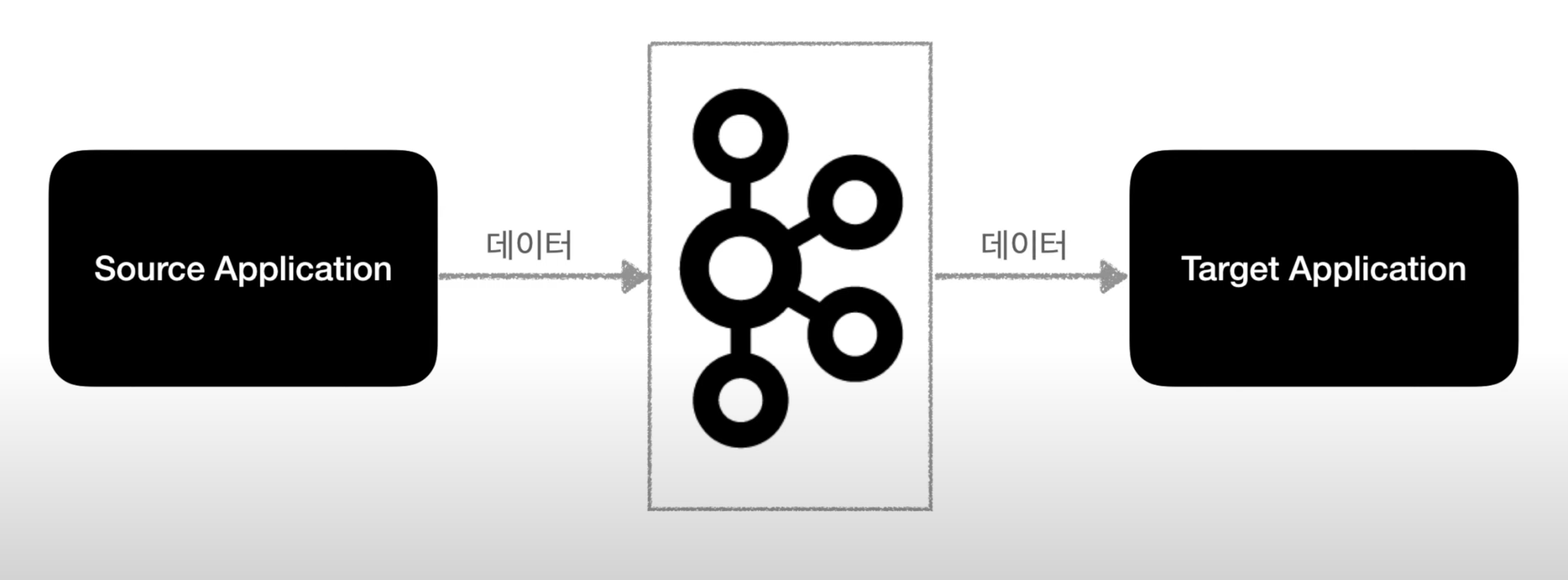
Data 를 전송하는 Source Application 과 Data 를 받는 Target Application 이 있을 때,
이것이 각각 하나밖에 없을 땐 아무 문제가 없지만,
application 들이 점점 늘어나게 되면 data 를 전송하는 라인이 많아지게 된다.
- 이렇게 되면 복잡도가 증가하게 되고, 배포와 장애에 대응하기 어려준다.
- 각각의 application 들의 특징이 뚜렷하다 보니 data 처리에 있어서 파편화 문제도 심각해진다.
- 또한 변경사항이 생길 때 유지보수하는것도 매우 까다로워진다. -
Kafka 는 이러한 문제를 해결하기 위해 링크드인에서 만든 오픈소스이다.
- 다이렉트로 통신하던 방식에서 kafka 를 통해 통신하는 방식으로 구조를 변경해줌으로써 sorse application 과 target application 의 커플링을 느슨하게 해준다.
- data 의 처리를 각각의 Application 이 아닌 한곳에서 처리할 수 있도록 중앙 집중화를 했다.
- 또한 Source application 의 data 형식은 json, tsv, avro, etc 등 거의 모든 포맷을 지원한다.
- 다이렉트로 통신하던 방식에서 kafka 를 통해 통신하는 방식으로 구조를 변경해줌으로써 sorse application 과 target application 의 커플링을 느슨하게 해준다.
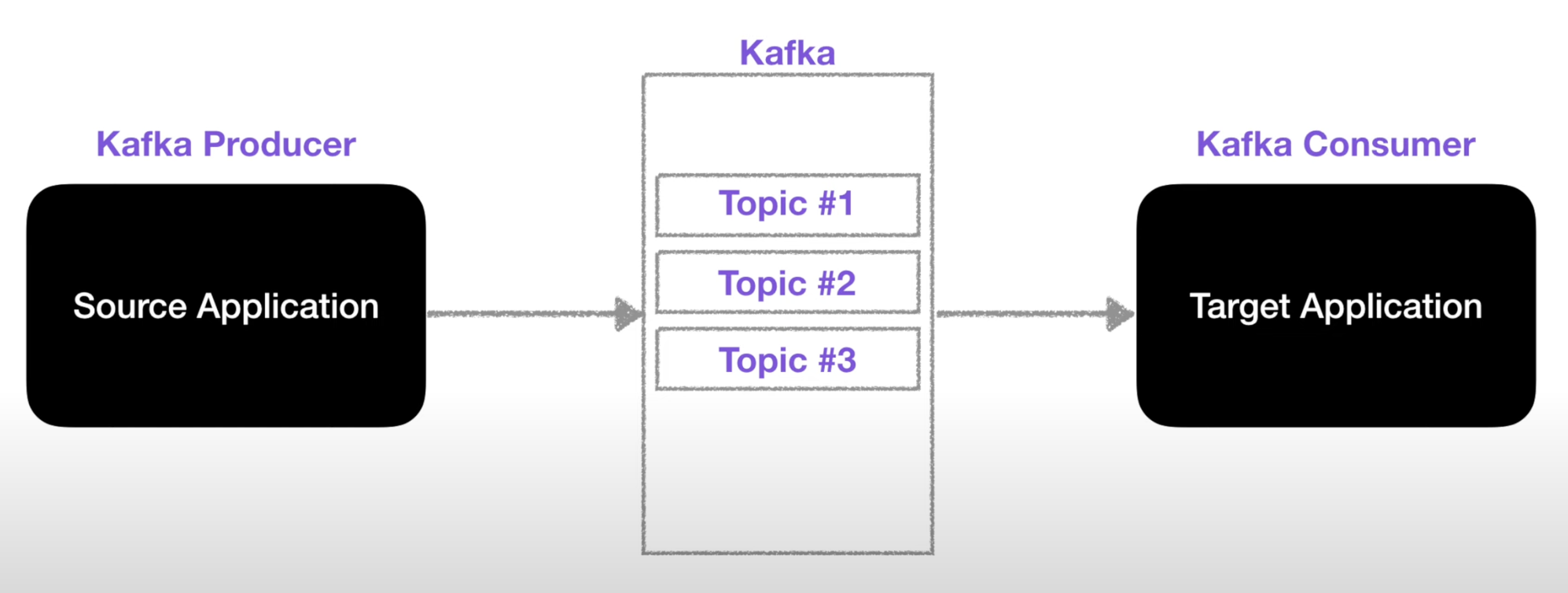
✏️ Kafka 의 구조
- Topic
- data 를 담아두는 패키지 같은 개념 (큐라고 생각하면 됨)
- Producer
- Topic 에 data 를 넣는 역할
- Consumer
- Topic 에서 data 를 가져가는 역할
- 이런 구조로 Kafka 는 고가용성으로 서버에 이슈가 생기거나 서버가 터지더라도 data 를 손실없이 복구할 수 있다.
- 또한 낮은 지연과 높은 처리량을 통해 효과적으로 대용량 data 를 처리할 수 있다.
- 빅데이터 분야에서 카프카는 필수적이라고 생각하면 된다.
📍 Kafka 클러스터
- 메시지를 저장하는 저장소
- 여러개의 브로커로 구성되어있음
- 데이터 이동에 대한 핵심 역할을 담당함
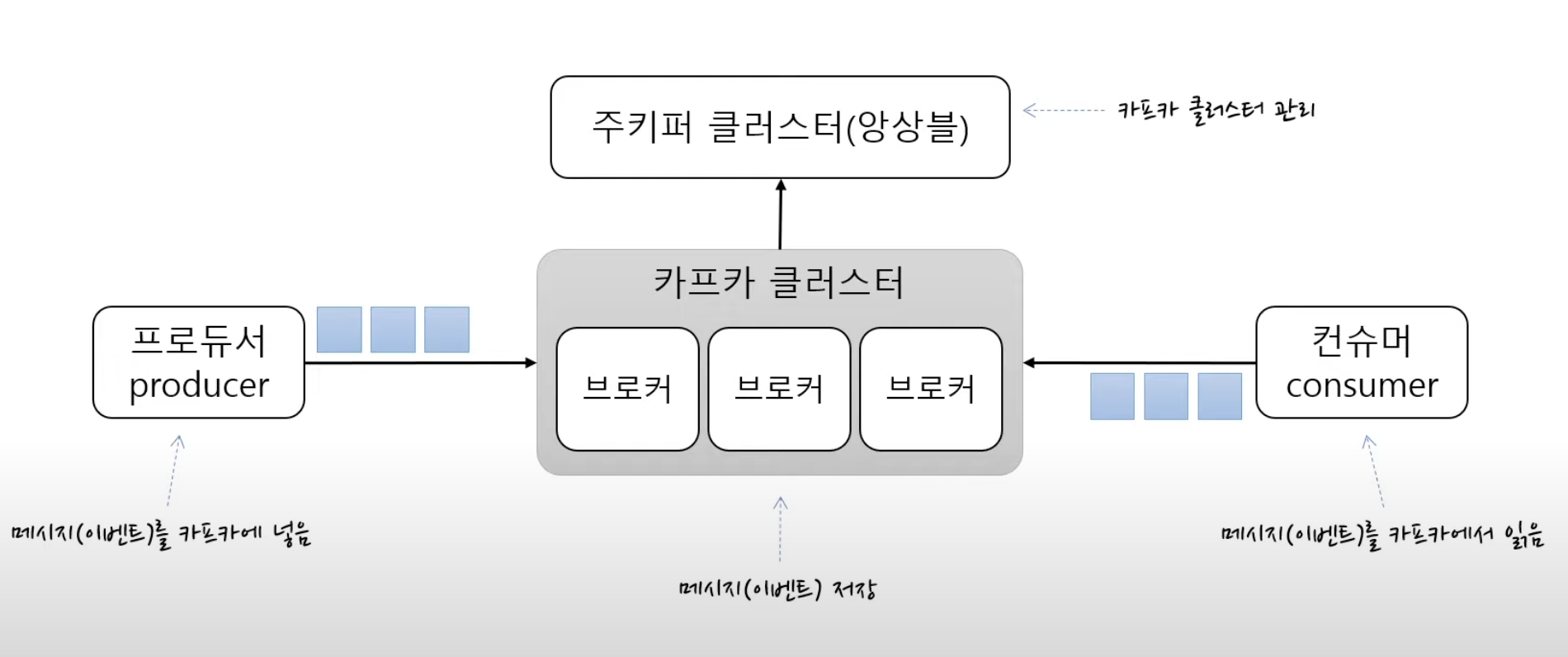
📍 주키퍼 클러스터
- 카프카 클러스터에 대한 내용이 기록해 카프카 클러스터를 관리하는 역할
📍 브로커
- 카프카 클러스터에 속한 각각의 서버
- 메시지를 나눠서 저장, 이중화 처리, 장애 대응 등 울 덤덩험
- 토픽을 보관하고 있다.
📍 토픽
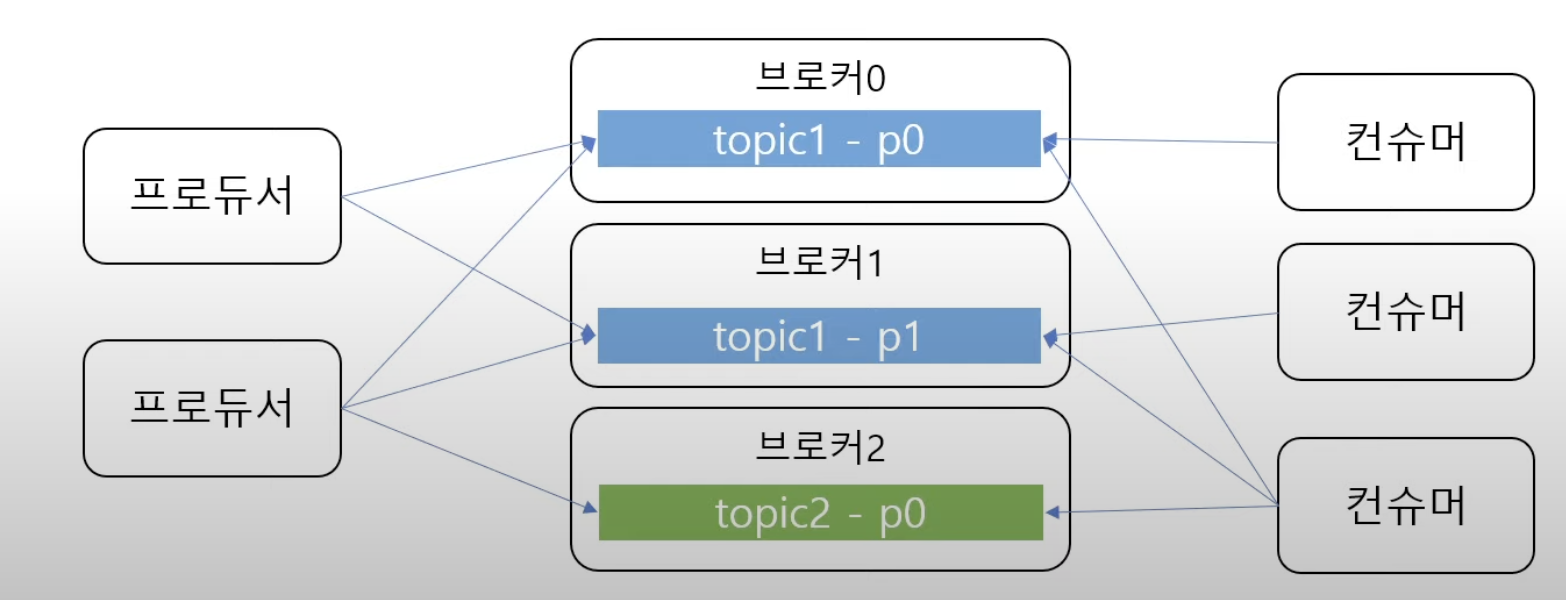
- 메시지의 카테고리를 구분하는 역할
- 각각의 메시지를 알맞게 구분하기 위해 사용됨
- 하나의 토픽은 하나 이상의 파티션을 갖을 수 있다.
- Consumer 와 Produer 는 토픽을 기준으로 메시지를 저장하고 불러온다.
📍 파티션
- 메시지를 저장하는 물리적인 파일
- 즉, kafka 에 있어서 메시지의 가작 작은 단위라고 생각하면 된다.
- 메시지 자체라고 생각하면 됨
📍 오프셋
- 토픽 내에서 파티션이 위치한 순서
- List 의 Index 개념으로 생각하면 된다.
- 토픽은 메시지를 0번부터 순서대로 저장하고,
내보낼 때도 특정 오프셋 부터 순서대로 내보낸다.
- 예를들어 3번 오프셋 부터 읽는다면 3,4,5 … 와 같은 방식으로만 메시지를 읽을 수 있다.
- 방금 예시처럼 메시지들을 묶어서 보내고 묶어서 조회할 수 있기 때문에 낱개 처리보다 효율이 증가한다.
- 임의로 메시지의 오프셋 순서를 변경할 수 없는 구조이다.
- 즉, 토픽은 메시지의 순서를 보장할 수 있다.
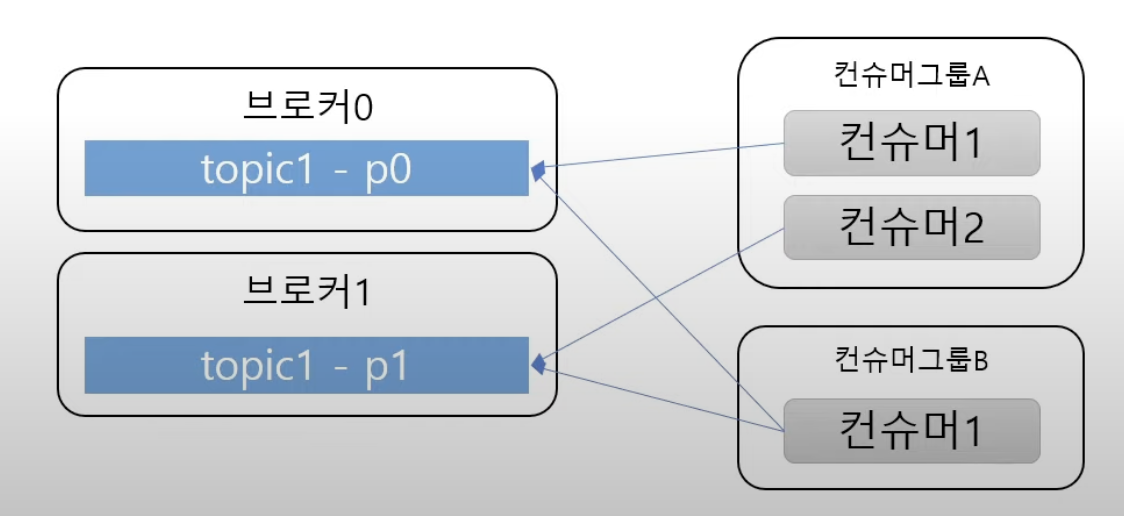
📍 Consumer Group
- Consumer 는 하나 이상의 Consumer 그룹에 속해야만 한다.
- 하나의 파티션은 하나의 Consumer 그룹에만 할당될 수 있다.
- 컨슈머 그룹 A 는 2개의 컨슈머가 속해있기 때문에 파티션 2개를 각각 하나씩만 가질 수 있다.
- 컨슈머 그룹 B 는 하나의 컨슈머 밖에 없기 때문에 2개의 파티션을 모두 가질 수 있다.
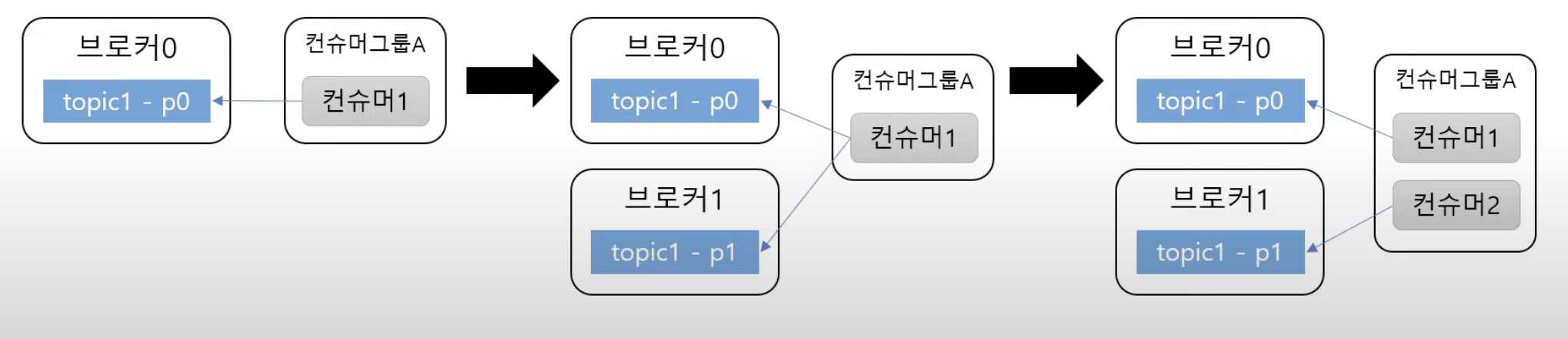
✏️ Kafka 의 유지보수
📍 손쉬운 처리량 증가
- 1개의 장비에 용량의 한계가 오면 브로커와 파티션을 추가하면 된다.
- 컨슈머의 처리속도가 밀리면 컨슈머를 하나 더 추가하면 된다.
📍 리플리카
- 파티션을 복제하는 기능이다.
- 리더 (원본) 와 팔로워 (복제품) 으로 구분되는데,
리더가 컨슈머, 프로듀서와 통신하고 팔로워는 리더의 데이터를 복제해서 보관한다. - 만약 리더에 장애가 생길경우 팔로워중 하나가 리더가 되어 장애를 빠르게 극복할 수 있게된다.
- 리더 (원본) 와 팔로워 (복제품) 으로 구분되는데,
- 복제 수 만큼 파티션의 복제본이 각 브로커에 생기게 된다.

잘못된 내용 PR 환영