1. Abstract
논문명
- Controllable Multi-Interest Framework for Recommendation(KDD 2020)
요약
- Taobao 에서 사용하는 추천시스템 프레임 워크인 ComiRec를 소개
- Multi-Interest Extraction 모듈과 Aggregation 모듈을 이용해 실험 데이터, 자사의 산업 데이터셋에서 SOTA 달성
- Multi-Interest Extraction 모듈: 순차적 추천 문제와 유저의 관심벡터를 포착하기 위한 전략으로 Dynamic Routing Method(캡슐 네트워크), Self-Attention Method를 제안
- Aggregation 모듈: 추출한 관심 벡터로 부터 아이템 pool에서 추천 목록을 Aggregation하는 Module
2. Introduction
-
추천 시스템은 이커머스 회사의 기본적으로 사용되고 전통적인 추천 방법은 CF, 최근에는 뉴럴넷 기반의 방법론이 널리 사용됨
-
뉴럴넷 기반 추천 시스템은 사용자 및 아이템에 대한 다양한 표현을 생성하고 기존의 추천 성능을 능가함
-
그러나 대규모 사용자 및 아이템 데이터가 존재하므로 각 사용자의 쌍과 아이템 간의 클릭률을 직접 예측하는 모델을 사용하기는 어려움
-
기존 추천 방법론에서의 순차적 추천 방식 문제점이 있음을 주장
GraphSAGE 기반의 그래프 임베딩 방법을 이용한 사용자, 아이템 표현 학습도 사용되나, 사용자 행동의 순차 정보가 잘 반영되지 않고 사용자 행동 간의 상관관계를 잘 표현할 수 없다고 주장
기존 RNN기반 순차적 추천 문제점은 하나의 관심사만 포착한다는 것
따라서 해당 논문에서는 단순히 하나의 관심사가 아니라 여러 관심사를 나타내는 추천하는 방법론을 제시 -
이 논문에서는 ComiRec이라는 Controllable Multi-interest 추천이 가능한 프레임워크를 제안함
-
- Multi-Interest Extraction 모듈
사용자의 여러 관심을 포착 할 수 있고 이를 후보 아이템검색에 사용
- Multi-Interest Extraction 모듈
-
- Aggregation 모듈
여러 관심사에서 추천에 사용할 최종 아이템 N개를 추리는 과정
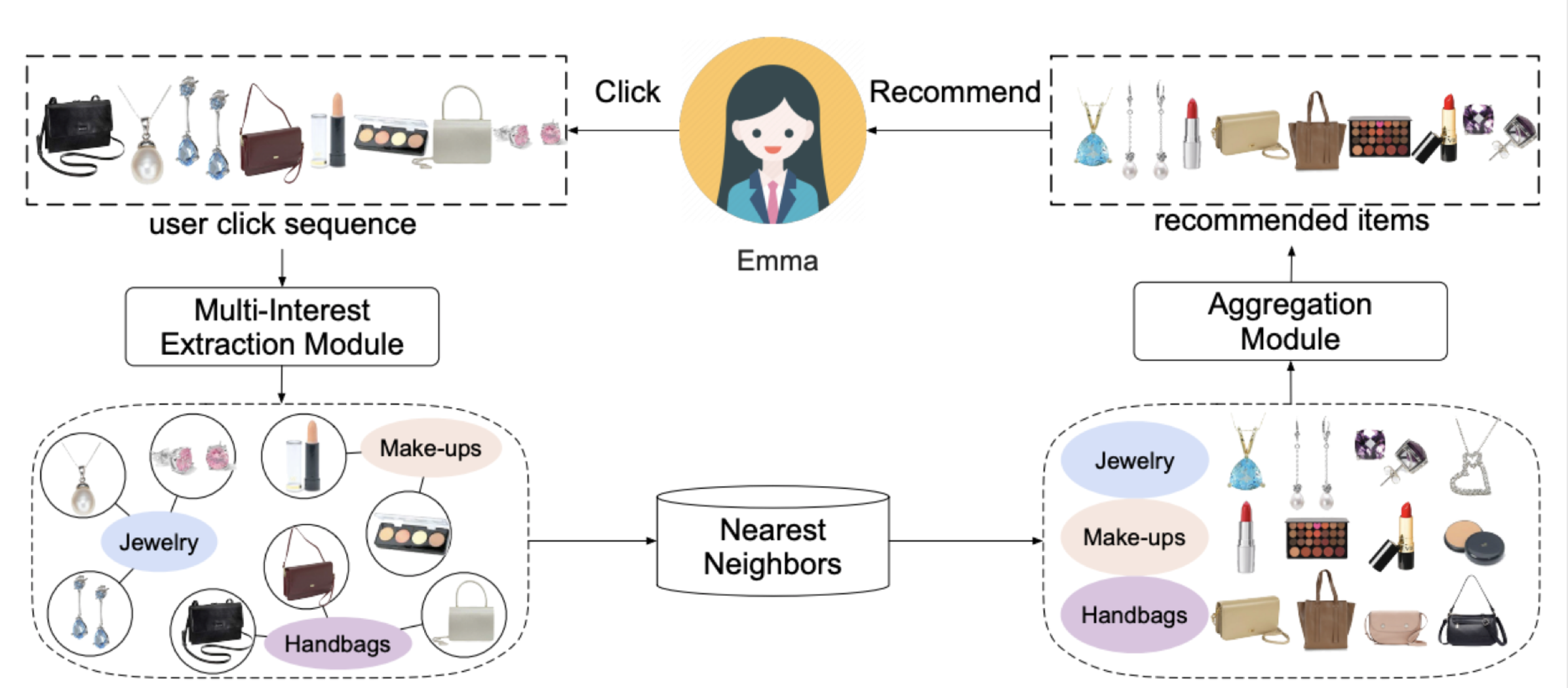
- Aggregation 모듈
-
여러 관심사가 있는 이커머스 유저 Emma가 있고, Emma의 클릭 시퀀스 정보를 구성
-
Multi-interest Extraction 모듈은 해당 시퀀스 정보를 통해 보석, 메이크업, 핸드백 관심을 포착 할 수 있음
-
Nearest Neighbors 알고리즘을 통해 대규모 아이템 풀에서 유사 아이템을 뽑아 낼 수 있음
-
Aggregation 모듈은 서로 다른 관심사의 아이템을 결합하고 Emma에 대한 전체 상위 N 개 추천 아이템을 출력
-
Contribution
- 제어 가능성과 다중 관심 요소를 통합하는 프레임 워크를 제안함
- 제어가능성의 역할을 조사
- 두 종류의 Real world challenging 데이터셋에서 SOTA 스코어를 달성
-
3. METHODOLOGY
Problem Formulation
- 각 사용자에 대해 일련의 사용자 과거 행동 시퀀스 가 존재할 때 (: 유저 u에 의한 t번째 아이템 인터렉션)
- 순차적 추천의 문제는 사용자가 상호 작용할 다음 아이템을 예측하는 것
- 산업 추천 시스템은 일반적으로 매칭 단계(상위 N개의 후보 아이템을 검색)와 순위 단계(후보 아이템의 랭킹을 정렬)의 두 단계로 이루어지나, 이 논문은 주로 매칭 단계에서 효율성을 높이는 데 중점을 둠

Multi-Interest Framework
임베딩 품질의 중요성
-
산업 추천 시스템의 아이템 풀은 수십억 개의 아이템으로 구성되기 때문에 매칭 단계는 추천 시스템에서 중요
-
매칭 모델은 사용자 클릭 시퀀스에서 사용자 임베딩을 계산 한 다음 임베딩 값을 기반으로 각 사용자에 대한 후보 아이템
세트를 검색
-
Nearest Neighbor 알고리즘으로 대규모 아이템 풀에서 가장 가까운 아이템을 선택하여 각 사용자에 대한 후보 집합을
생성 -
즉, 매칭 단계의 결정적인 요소는 사용자 과거 행동으로부터 추출된 사용자 임베딩의 품질이 관건
-
Multi-Interest Extraction 모듈을 이용해 각 사용자 행동 시퀀스를 Input으로 하여 Multi-Interest를 생성할 수 있음
-
Multi-Interest을 추출하기 위한 두 방법 제시
- 다중 관심 추출 모듈로서 1)동적 라우팅 방법(dynamic routing method)과 2)Self-Attention 방법(self-attentive method)을 제시.
두 방법을 각각 ComiRec-DR, ComiRec-SA로 명명
- 다중 관심 추출 모듈로서 1)동적 라우팅 방법(dynamic routing method)과 2)Self-Attention 방법(self-attentive method)을 제시.
-
전체 흐름
-
아이템 ID로 구성된 사용자 행동 시퀀스 데이터가 존재하며, 각 아이템 ID는 아이템 임베딩 벡터로 변환시킴
-
Train 과정에서 Sampled Softmax Loss를 계산하기 위해 대상 임베딩에 가장 가까운 관심 임베딩이 선택
-
서빙을 위해 각 관심사 임베딩은 가장 가까운 상위 N개 아이템을 독립적으로 검색한다음 집계 모듈에 넣어줌.
-
집계모듈은 추천 정확도와 다양성의 균형을 고려해 상위 N개 아이템을 추천
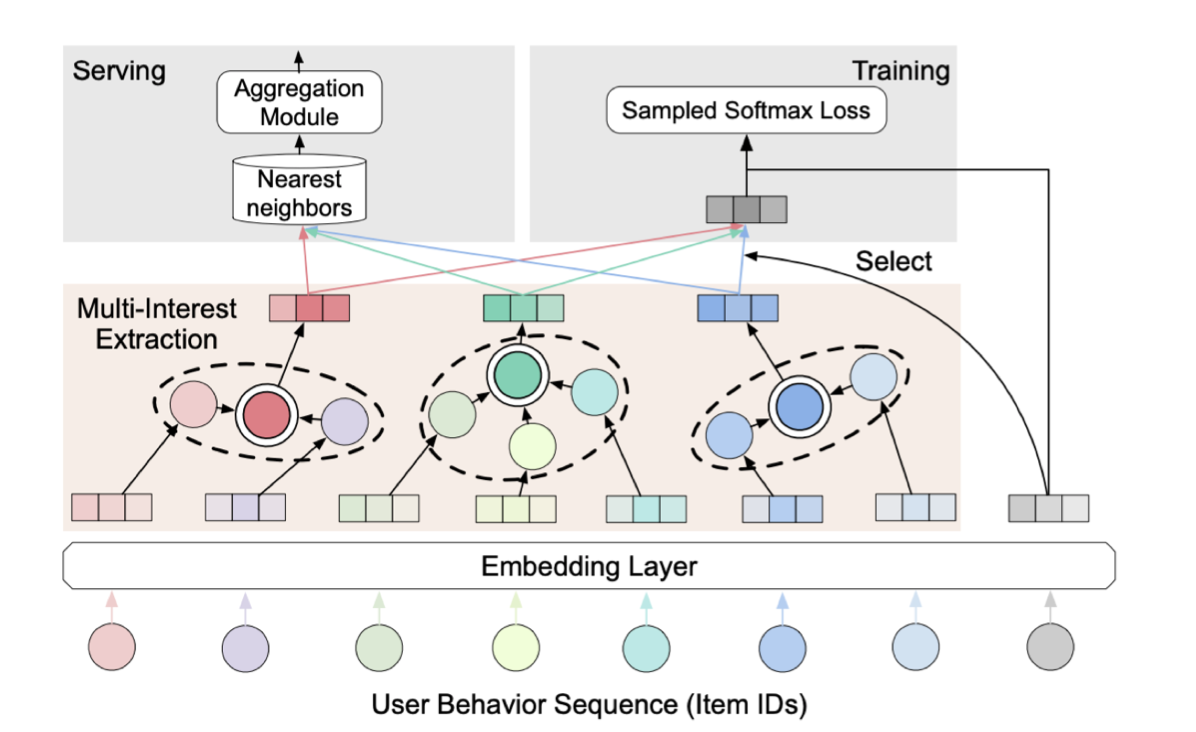
-
Dynamic Routing Method

- : primary layer의 캡슐 i, 즉 아이템 임베딩 값
- : 를 기반으로 다음 레이어의 캡슐 j를 예측한 것
- 는 Dynamic Routing 프로세스가 반복되며 결정되는 결합 계수
- 캡슐 i와 다음 층에 있는 모든 캡슐 사이의 결합 계수의 합은 1이 됨
- 는 캡슐 i와 j간의 연결 강도
,
- 비선형 squashing 함수는 짧은 벡터가 거의 제로 길이로 축소되고 긴 벡터는 1보다 약간 작은 길이로 축소되로록 보장하기 위해 제안
- 는 결합계수가 고려된 캡슐 j의 총 입력
- 사용자 u의 출력 관심 캡슐은 행렬 로 구성
Self-Attentive Method
- 사용자 u의 특정 관심사에 대한 것을 먼저 생각해보면, 사용자 행동 임베딩 (n은 사용자 시퀀스이 길이)이 주어졌을 때, self-attention 을 사용하여 아래의 벡터 a를 얻을 수 있음
- 크기가 n인 벡터 a는 사용자 행동의 어텐션 가중치에 따라 사용자 행동의 임베딩을 합산하면 사용자 u에 대한 관심 벡터 를 얻을 수 있음
- 사용자의 전체 관심사로 확장하기 위해, 행렬로 표현하면 아래의 Attention Matrix A로 표현됨
- 사용자 관심사 의 최종 행렬은 다음과 같이 계산
Model Training
- 사용자 관심 임베딩 행렬에 argmax하여 대상 item i 에 해당하는 임베딩 벡터를 선택
- : 아이템 i의 임베딩, : 사용자 관심 임베딩 행렬
- 사용자 u가 아이템 i와 상호작용할 가능성을 다음과 같이 구함
- 모델의 목적 함수는 다음과 같은 음의 로그 가능성을 최소화 하는 것
- 위의 계산 비용을 줄이기 위한 샘플링 소프트 맥스 테크닉을 이용
Online Serving
- 사용자의 각 관심 벡터는 nearest neighbor library(Faiss)를 사용해 대규모 아이템 항목 풀에서 상위 N 개 항목을 검색
- 여러 관심 분야에서 검색된 항목을 Aggregation Module의 Input으로 넘겨줌
Aggregation Module
Aggregation Module
- 추천시스템의 다양성을 고려하기 위한 요소를 고려한 함수를 정의
- 는 사용자 u의 K개의 관심 중, k번째 관심 임베딩이며, 계수 λ를 사용하여 추천의 정확성과 다양성의 균형을 맞춤
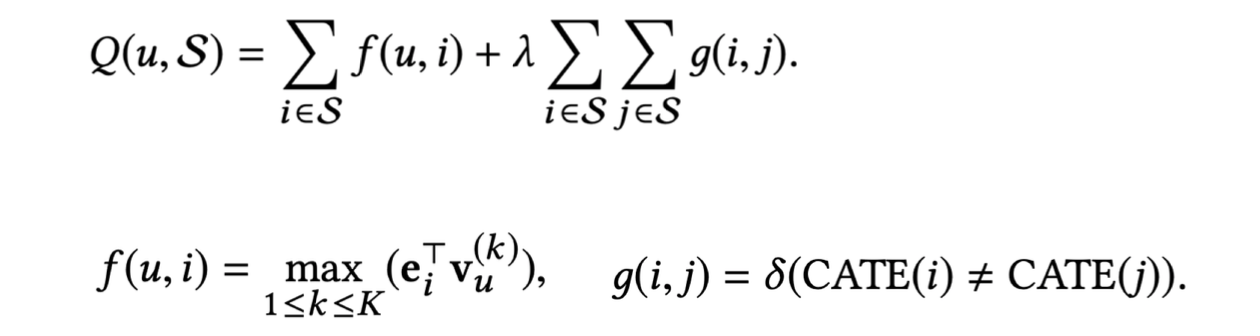
- inner production proximit을 토대로 아이템과 사용자 관심사의 유사도를 측정
- CATE (i)는 항목 i의 범주, δ (·)는 indicator 함수
- 가장 정확한 경우, 즉 λ=0의 경우 위의 간단한 방법을 사용하여 전체 항목을 얻음
- 가장 다양한 경우(예:λ=∞)의 경우 제어 가능한 모듈이 사용자를 위해 가장 다양한 항목을 찾음
Greedy Inference
- N:추천해 줄 아이템 갯수, M:후보 아이템 집합이 있을 때,
- 각 iteration 단계 마다 Q(u,S)함수를 최대화 하는 아이템 j를 최종 리턴할 결과 집합 S에추가 하는 알고리즘

4. EXPERIMENTS
실험 세팅
- 8:1:1의 비율로 훈련/검증/테스트 데이터 셋 분할
- 각 사용자 u의 행동 시퀀스는 로 구성
- 모델은 유저 u의 k개 동작을 사용하여(k+1)번째 동작을 예측하는 문제를 풀게됨. K는1,2,...,(n−1)
- 아마존 Books, Taobao 데이터셋을 사용

- 논문에서 제안한 ComiRec-SA, ComiRec-DR 모델을 여러 최신 모델과 비교
• MostPopular, Youtube DNN, GRU4Rec, MIND
평가지표
Recall
• 더 나은 해석을 위해 글로벌 평균 대신 사용자 당 평균을 사용
• 은사용자 u에 대한 상위 N개 추천 아이템 집합. 는 사용자 u에 대한 테스트 아이템 집합
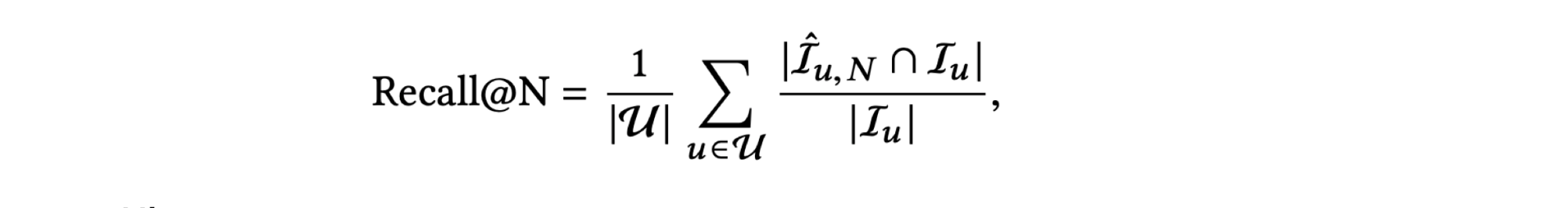
Hit rate
• 추천 아이템에 사용자가 상호 작용한 아이템이 적어도 하나 이상 포함되어있는 비율
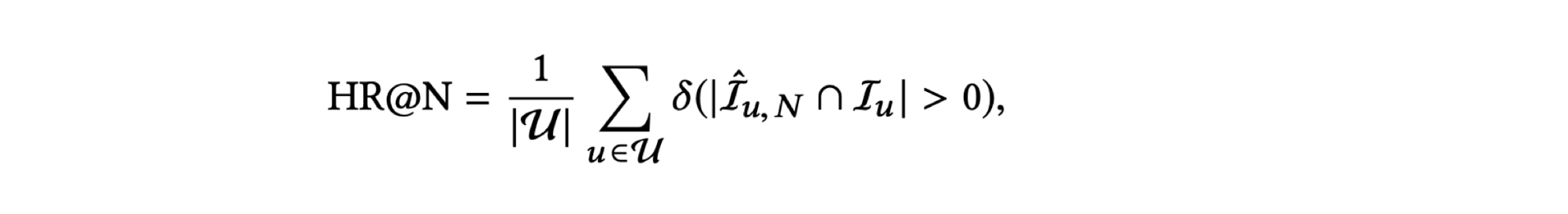
Normalized Discounted Cumulative Gain
• 랭킹기반 추천시스템에 주로 사용되는 평가지표
• 는 사용자 u에 대한 k 번째 추천 아이템. Z는 정규화 상수
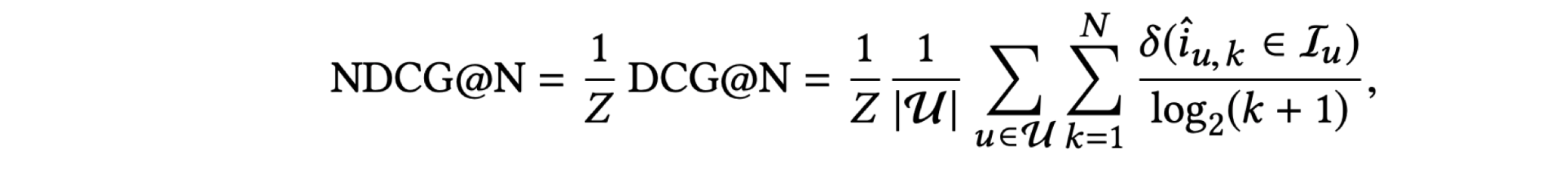
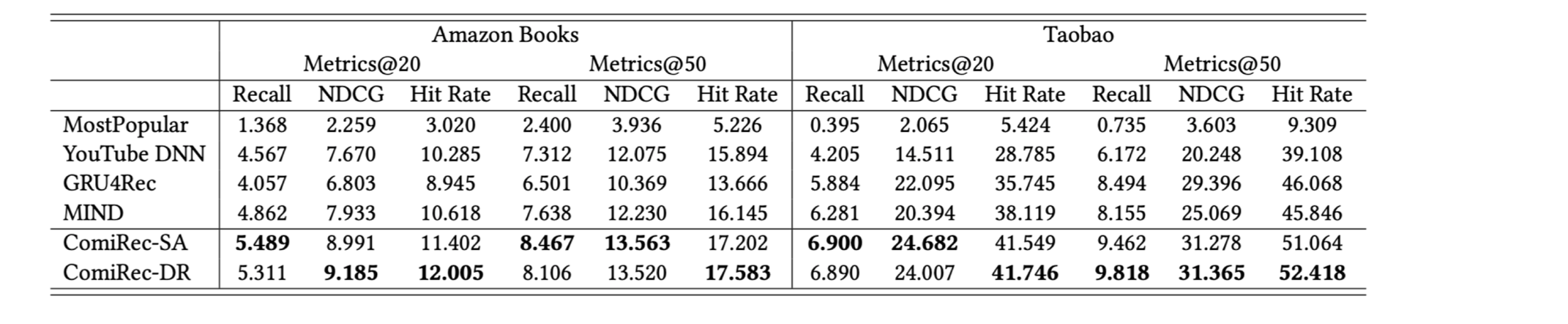
Quantitative Results
- 다른 모델과 공정하게 비교하기 위해 Aggregation 모듈에서 다양성과 관련된 계수 λ = 0로 설정
- 하이퍼 파라미터K(관심사)가 변경될 때 성능 평가

Controllable Study
다양성 평가
- 단조로움을 피하고 고객 경험을 개선하기 위한 목적으로 다양성에 대한 실험을 진행
- 항목 범주에 따라 다음과 같은 개인 다양성 정의를 사용
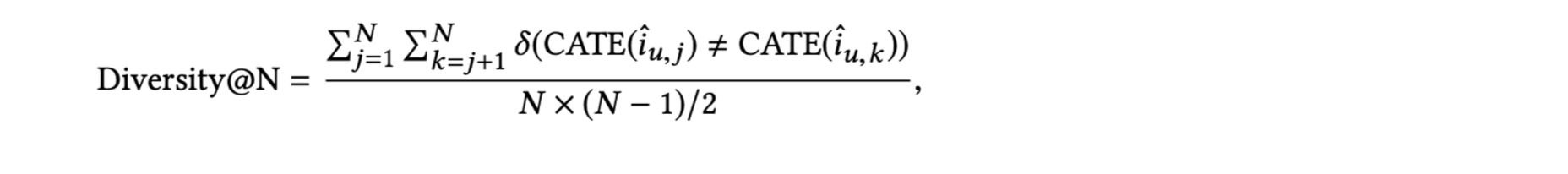
- CATE(i) 는 항목 i의 범주, 는 사용자 u에 대한 j번째 추천 아이템, δ(·)는 지시 함수
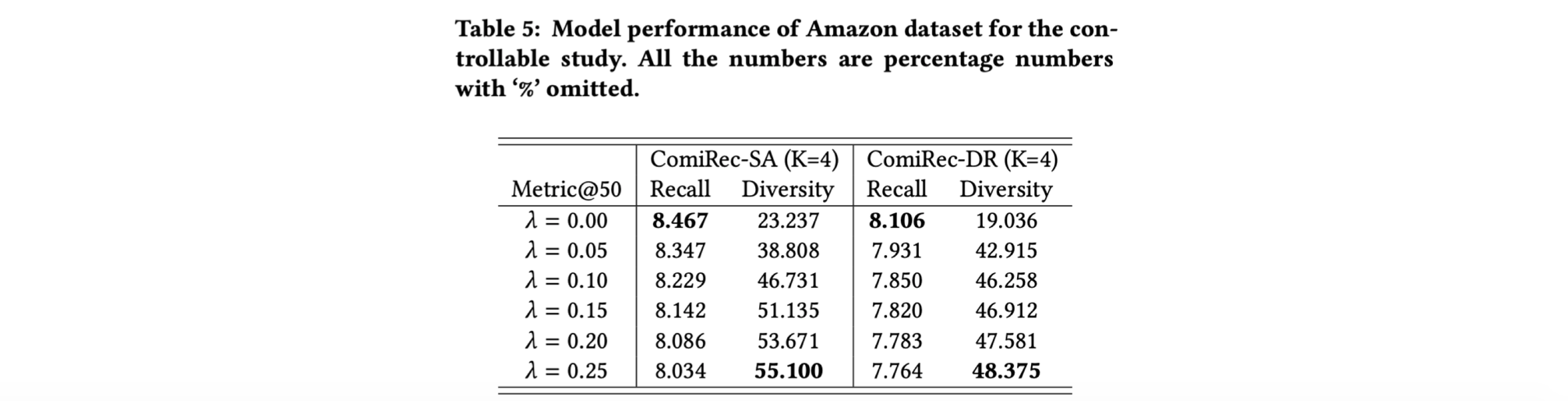
- 표5는 다양성의 계수λ를 제어할 때 Amazon 데이터 세트의 모델 성능 평가표
- 계수 λ가 증가하면 추천 다양성이 크게 증가하고 재현율은 약간만 감소함
산업 데이터 셋에 대한 추가 실험
- 모바일 Taobao 앱에서 수집한 산업 데이터 세트에 대해 추가로 실험 진행
- 2,200만개의 아이템,1억4,500만명의 사용자,40억개의 행동이 포함
- 16GB NVIDIA Tesla P100 GPU 사용
- 논문에서 제안한 ComiRec-SA와 ComiRec-DR이 베이스라인인 MIND에 비해 Recall@ 50이 각각 1.39 %, 8.65 % 향상

5. CONCLUSION
- Multi-Interest Extraction 모듈을 사용하여 여러 사용자 관심사를 생성하고 Aggregation 모듈을 사용하여 전체 상위 N 개 항목을 얻을
수 있었음 - 두 종류 데이터 셋에 실험한 결과를 통해 제안한 모델 방식이 타 Baseline모델 보다 우수한 성능을 보임
- 해당 프레임 워크는 Alibaba 분산 클라우드 플랫폼에도 성공적으로 배포
- 실험용 데이터 셋 뿐만 아니라 추가적으로 대규모의 Taobao 산업 데이터 셋에서도 제안한 모델의 성능이 우수함
- 앞으로 메모리 네트워크를 활용한 사용자 모델링을 만들 계획
