Shallow Encoder의 한계(딥러닝 이전의 방식)
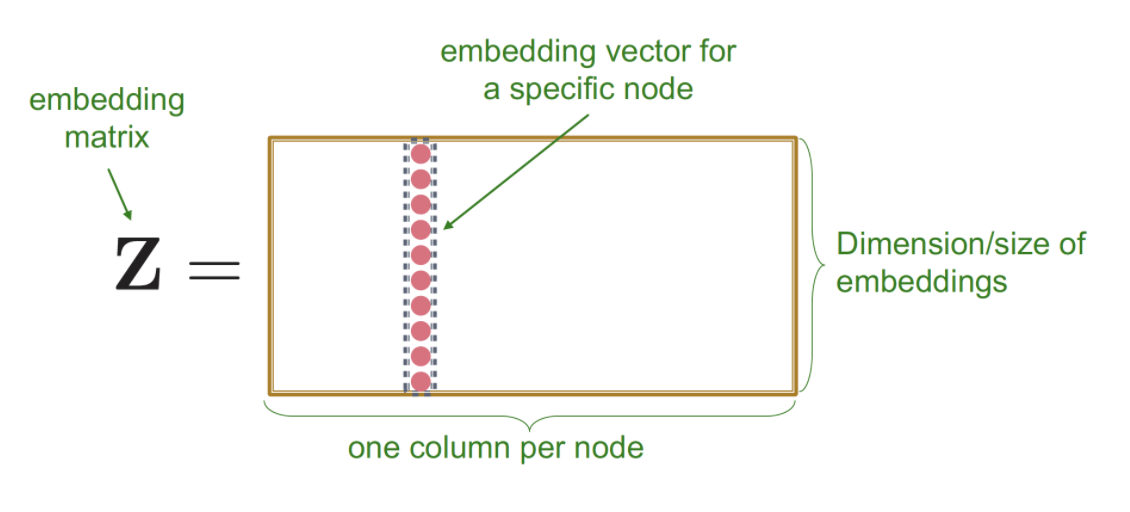
- Shallow Encoder는 Single layer(f)로 구성되어 있고, 이를 통해 node embedding 진행( → , 유사도 계산()
- Lookup table 형식으로 노드 임베딩 값을 꺼내 사용
Shallow encoder의 한계(Node2vec)
1) 각 node끼리 파라미터 공유 X
- 각 node들은 unique 임베딩 값 가짐(#parameters = #nodes)
2) Inherently "transductive"
- unseen node를 generalize할 수가 없음
3) node attribute feature 사용 X
Deep Graph Encoder
- Shallow Encoder의 한계를 극복하고자, Multi layer로 구성된 Deepencoder를 고려
Encoder(u) = multiple layers of non-linear transformaties of graph structure
- 그냥 딥인코더라 하면 다른 도메인의 딥러닝 모델 구조를 때려박으면 되지않을까 하지만 아래 한계점이 존재함
- Image/Text에 특화된 아키텍쳐이기 때문에 그래프구조에 적합한지 의문
- Network의 복잡한 위상학적 구조를 반영하기에 기존 딥러닝 모델을 그대로 쓰기에 한계가 있음
- Dynamic함
- GNN 개요
- Input : Adjacency Matrix, Node feature matrix
- Output : 노드 분류 결과
- 알고리즘 : Aggregation(이웃 정보)와 Combine(내 정보)의 반복
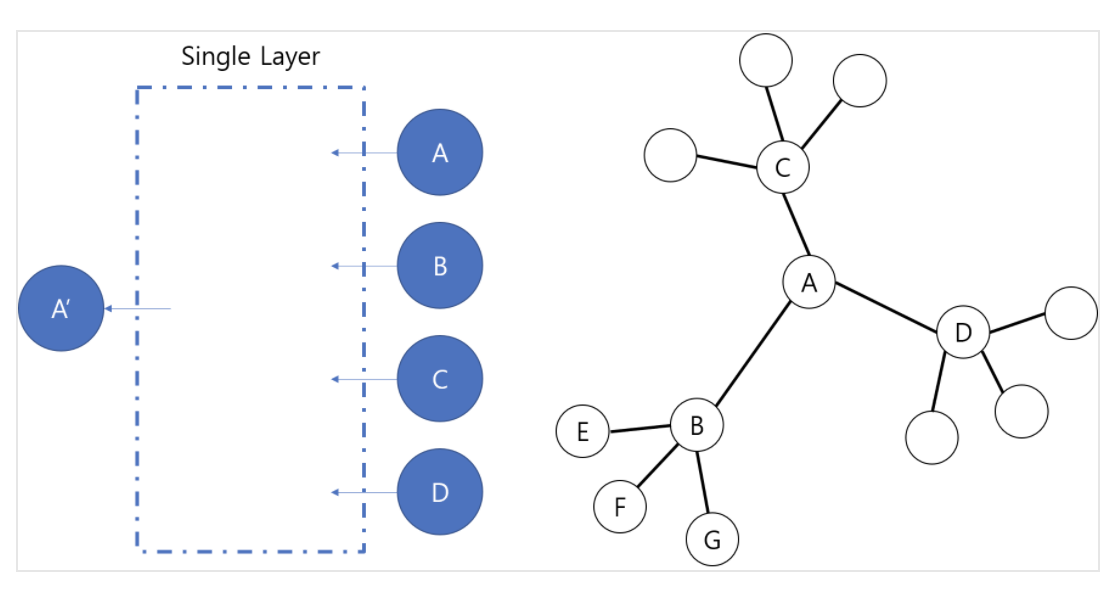
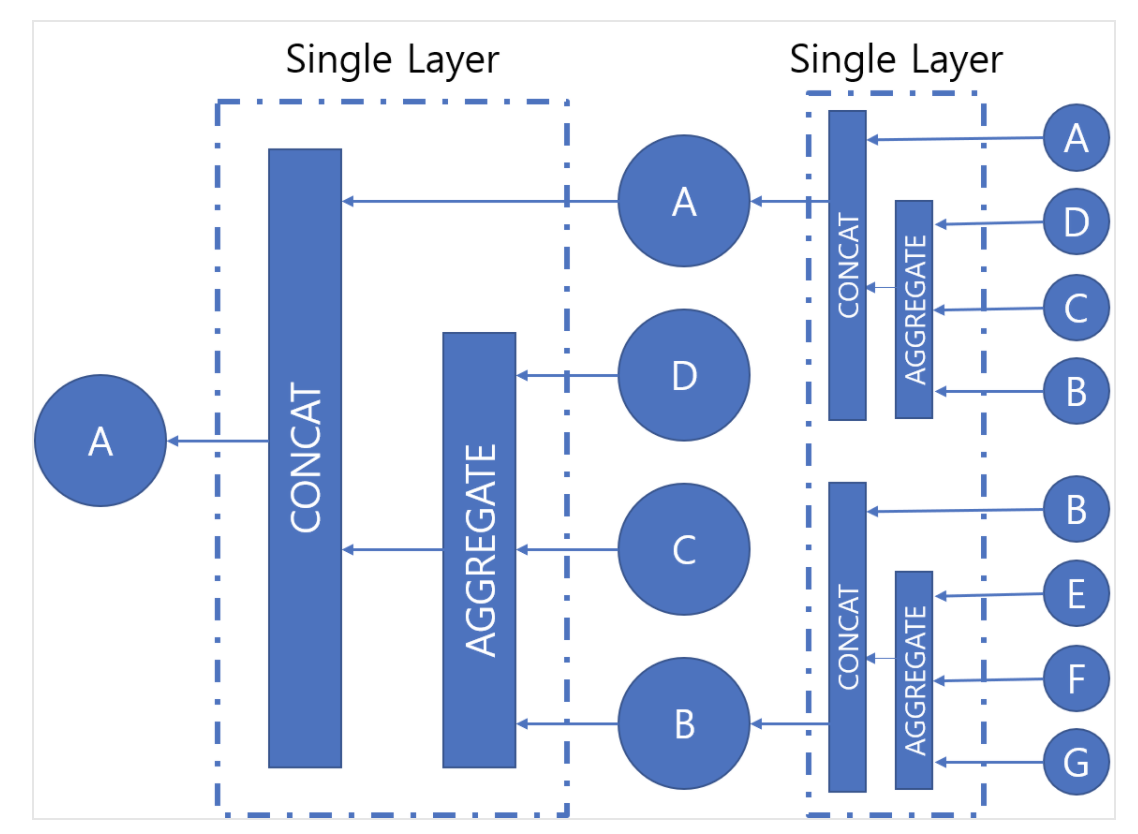
[출처 : http://www.secmem.org/blog/2019/08/17/gnn/]
→ Agg함수를 이용해 이웃정보를 모으고, Combine하여 자신의 정보를 더해 다음 상태의 자신 임베딩 값을 만들겠다.
-
Vanila GNN
-
Aggregation함수, Combine함수
: 노드 의 초기 임베딩(=노드피쳐)
: 학습 파라미터
에 해당하는 Term(Neighbors aggregation term) : 노드 에 대한 이전 Layer의 이웃도의 임베딩 평균
에 해당하는 Term(Self-transform term) : 이전 layer의 의 임베딩 벡터
-
-
여러 GNN모델은 이 Aggregation 함수의 차이가 있는 것
