[Arxiv 2023] TEMPO : Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Paper Reading
왜 이 연구를 했을까
Generative Pre-trained Transformer (GPT)가 NLP에서 잘 작동하는 만큼 time-series에서도 효과적이거나 고유한 dynamic attributes를 포착해서 정확도 향상에 도움이 될까? 라는 호기심에서 시작된 것 같다.
이 논문에서와 마찬가지로 많은 종류의 시계열을 위한 Pre-trained Large Language Model들이 있다.
많은 종류의 Pre-trained 모델들이 복잡한 dependencies나 textual data의 맥락들을 잘 파악한다는 것은 최근의 많은 연구들을 통해서 증명되었다. 이를 토대로 대다수의 모델들이 단지 시계열 데이터를 GPT 모델에 적용하고, fine-tuning을 통해 성능을 향상시키는 것에 그친다. 즉, GPT 계열의 시계열 모델은 아직 연구가 필요하다. 그나마 METS라는 논문이 이 연구의 방향으로 제대로 하고 있다고 이야기함. 하지만, METS는 ECG 데이터에 특화되어있기 때문에 다양한 데이터셋에서는 활용하기 힘들다는 의견이다.
그래서 이 논문에서는
pre-trained model에 대한 inductive bias를 사용한다.
-
Trend, Seasonality, residual 등의 복잡한 상호작용
-
non-stationary time-series의 distribution adaptation을 위한 prompt selection-based prompts 도입.
Prompt tuning
효율적이고, low-cost로 새로운 downstream task에 적용할 수 있는 방법이다.
TEMPO : prompt pool + time-series decomposition + pre-trained transformer based backbone.
—> 모델이 다양한 time-series components의
Time-series representation learning을 위한 해석 가능한 prompt tuning based generative transformer
어떻게?
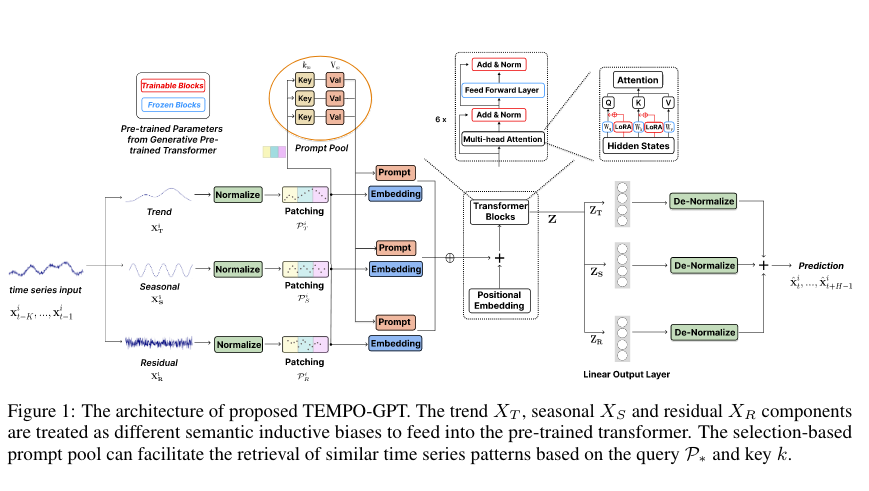
STL로 시계열 데이터를 분해하고 이 분해된 결과와 pre-trained model을 통합하는 방법을 제안한다.
—> 이렇게 함으로써, 기존의 통계학적, 머신러닝 방법등의 장점을 사용해서 모델의 성능을 향상 시킬 수 있다.
Time series decomposition
기존의 transformer-based model들이 trend, seasonality를 자동으로 풀지 못하기 때문에 이러한 시계열 분해는 transformer-based 방법론에서는 더 중요하다.
Prompt Design
Prompt-pool을 적용함으로써, non-stationary time series의 distribution shift 문제를 해결한다.
Prompt-pool은 temporal effect을 encoding해서 모델이 과거의 데이터를 적절하게 사용할 수 있도록 (회상) 해준다.
Temporal effect : 키, 쿼리 기반의 유사성 검색 기능
Generative Pre-trained transformer architecture
pre-trained model을 사용해서 최종 예측을 만들어낸다.
