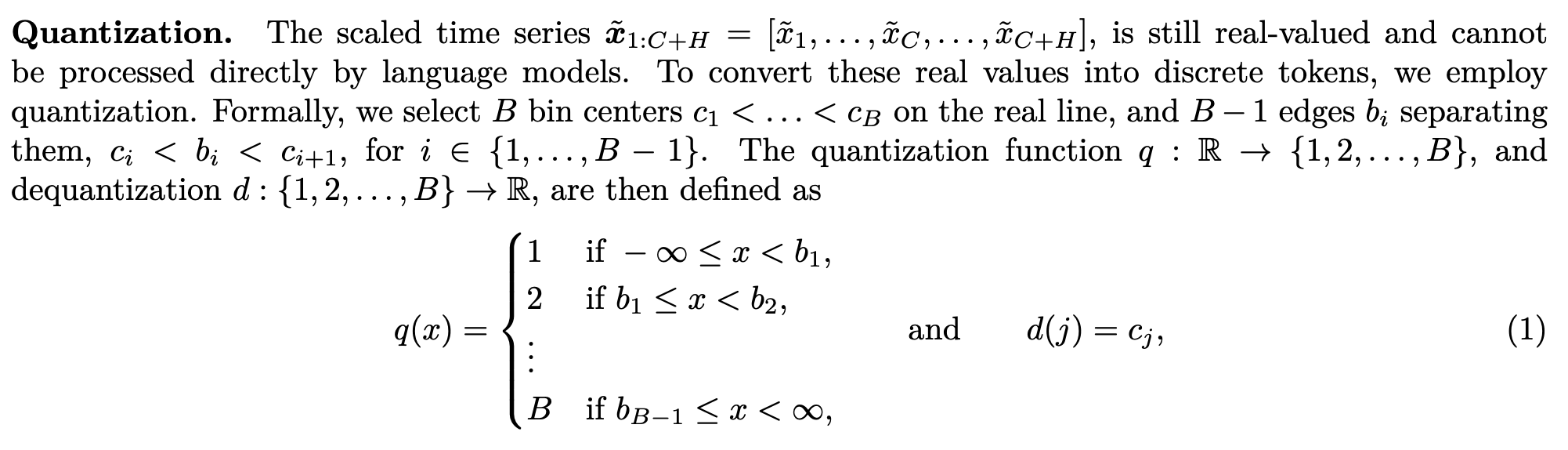
⚡ Motivation
What are the fundamental differences between a language model that predicts the next token, and a time-series forecasting model that predicts the next values?
GOAL : LLM처럼 범용적이고 zero-shot 으로도 잘 작동하는 시계열 예측 모델
- 기존 시계열 모델들은 dataset-specific하게 학습되기 때문에 범용성이 부족함.
- 자연어처럼 시계열 데이터를 tokenization해서 language model (Transformer language model T5, GPT-2)에 입력가능한 형태로 바꿈.
🔍 LLM-based forecasters :
- PromptCast : 시계열의 input-output forecasting task를 Language model의 테스크처럼 question answering task처럼 풀고자 함. 하지만, dataset-specific templates(numerical data → text prompts)
- LLMTime : pretrained LLM 모델이 zero-shot forecasting으로 benchmark time-series dataset에서의 성능을 보여줌. 물론, new tokenization scheme (real-valued data를 sting of digit으로 encoding하는 것)
- GPT4TS : pretrained GPT-2 모델을 backbone으로 사용하였으며 단순하게 fine-tuning positional embedding과 layer normalization등만 사용함.
- Time-LLM : Time series patch를 text prototype들과 align함.
→ GPT4TS와 Time-LLM은 모두 in-domain training과 fine-tuning이 필요함. 즉, 각 데이터셋에서 fine-tuning이 적용됨. 하지만, Chronos 는 Scaling, Quantization을 통해서 tokenized된 time-series tokens에서 language model을 처음부터 훈련시킴!
🔍 Zero-Shot forecasting :
-
Unseen dataset에서의 예측 성능을 보는 것
-
ForecastPFN : prior distribution으로 정의된 추세, 계절성에 따라서 생성된 synthetic dataset을 transformer모델로 학습시키며 이때 실제 시계열 데이터를 예측하는데 사용됨.
-
Chronos에서는 Gaussian Process를 통해서 Synthetic dataset을 생성하도록 하며, 실제 시계열 데이터를 함께 학습함으로써 zero-shot 성능을 향상시킴.
-
ForecastPFN은 point forecasting만 가능한데, Chronos는 probablisitic forecasting이 가능함.
-
이외에도 기존의 transformer 기반의 시계열 모델들을 pre-train해서 zero-shot forecasting을 수행함. 이러한 기존의 모델들은 시계열의 실제 수치값을 사용함. time-feature, patching, real-valued distribution head, lags등의 요소들이 포함됨.
-
Chronos : minimalist approach 를 채택함.
- 실수값을 token으로 quantization을 통해서 바꿈.
- 기존의 언어모델 아키텍처를 그대로 사용함.
- 시계열에 특화된 어떤 설계도 사용하지 않음.
→ 즉, 실수 regression을 classification문제로 다룸
🕶️ Solution (Chronos):
Time Series Tokenization
- Scaling : 시계열 데이터는 단일 시계열 안에서도 scale다른 문제가 존재함. 이는 시계열 데이터로 학습을 할때 최적화를 어렵게 만듬. 그래서 개별 시계열을 정규화함. 이논문에서의 목표는 시계열 값을 quantization을 위한 범위로 매핑하는 것.
- 시계열 값의 스케일이 너무 다양하기 때문에 이걸 나누어서 input을 집어넣으면 그 안에 차이가 생기기 때문에 모든 시계열을 동일한 스케일로 맞춰야 학습 안정성이 생기고 같은 token vocabulary를 쓸 수 있음!!
- 이 논문에서는 Mean Scaling을 선택함. ,
- mean scaling을 선택하면 0값이 보존됨.
- scale-invariant하게 만들 수 있음 → 작은 값이든 큰 값이든 token별 분 포가 유사하게 형성됨.
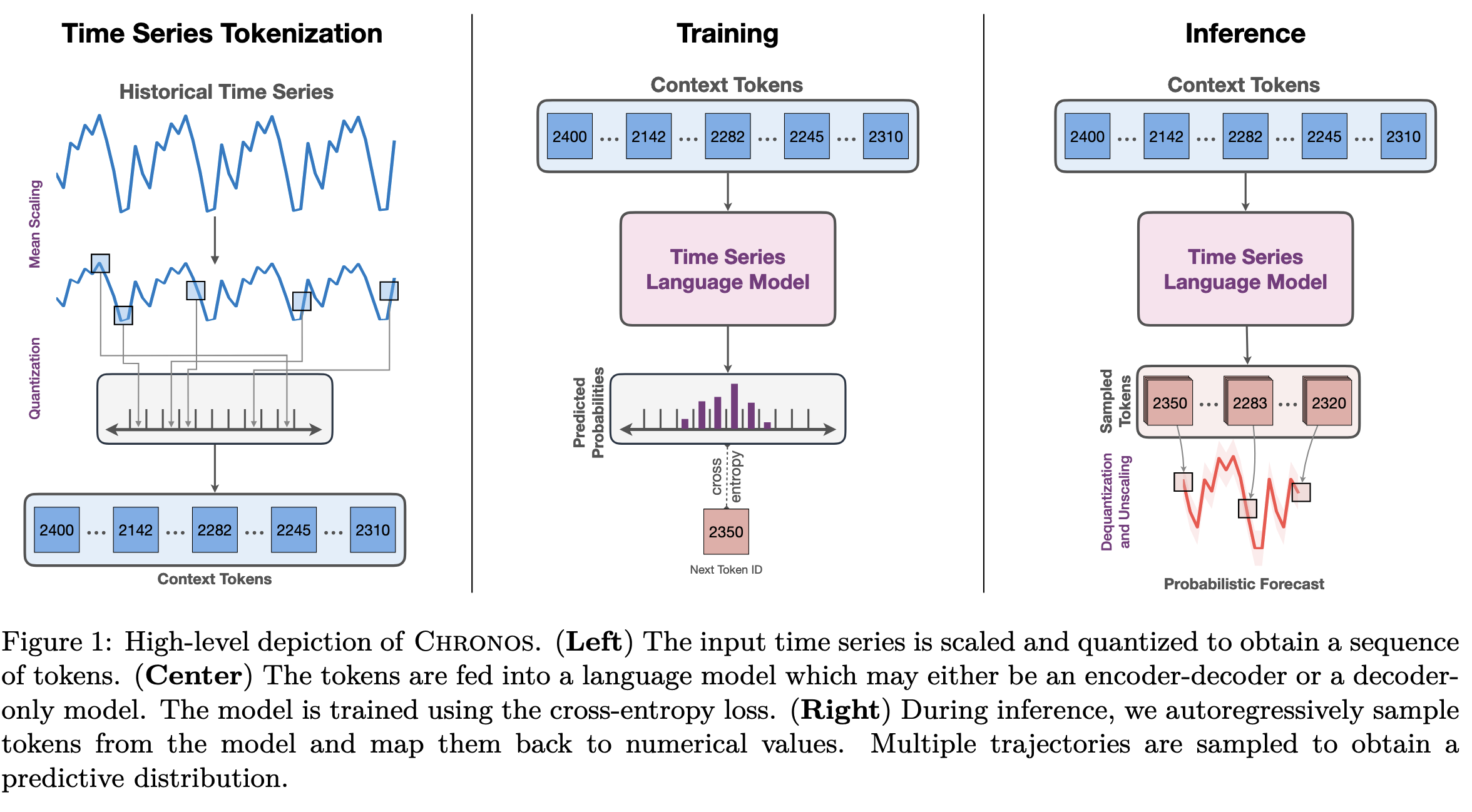
- Quantization
language model에 input으로 time-series 데이터를 넣기 위해서 scaled time-series를 quantization을 통해서 나눔.
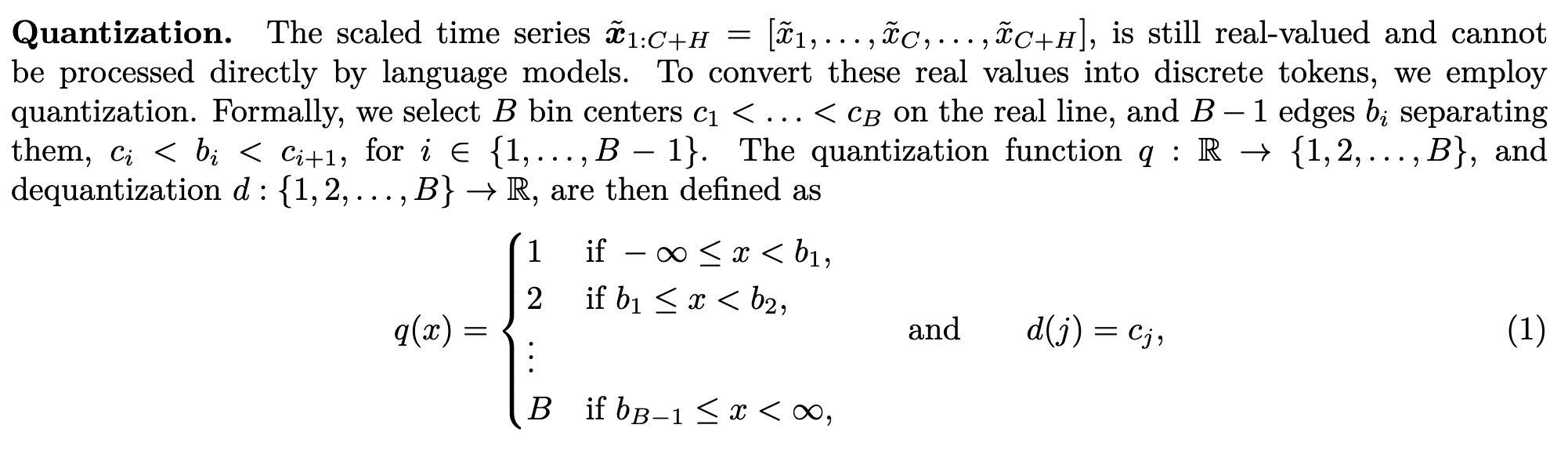
복원할때도 해당 token에 대응되는 중심값 를 실수로 되돌림.
이 논문에서는 uniform binning 방법을 사용하는데, 분포가 치우치는 경우가 있을 수 있지만, train/test 간에 스케일이 달라도 적용이 가능함.
Chronos는 다양한 도메인에서 적용하기 위해서 uniform binning을 선택함.
하지만 이런식으로 데이터를 quantized하면 트렌드가 강한 시계열에서는 잘 안될 수 있음.
Objective Function

tokenized된 값(bin ID)를 맞추는 분류문제가 되었기 때문에 Cross-Entropy loss로 학습하는 것 하지만, 이 정수 token은 실제로는 실수 값을 대표하는 bin이기 때문에 연속적인 실수값을 예측하는 regression 문제를 분류문제로 풀었다고 할 수 있음..
한계점 : Cross-entropy는 distance-aware loss가 아니기 때문에 모델이 이런 정보를 경험적으로 학습하기를 기대하는 것.. 예를 들어서 bin 30이라고 모델이 예측했는데, 실제 정답이 bin 29인것과 bin 1인것은 큰 차이가 있지만 cross-entropy를 사용하면 이러한 구별이 사라짐.
Forecasting
softmax 결과로 나온 token 분포에서 샘플링하여 결과를 얻음.
예를 들어서 (sample paths)를 얻음. 그래서 다른 모델들과 비교를 위해서는 multiple sampled trajectories의 평균을 대표값으로 사용함.
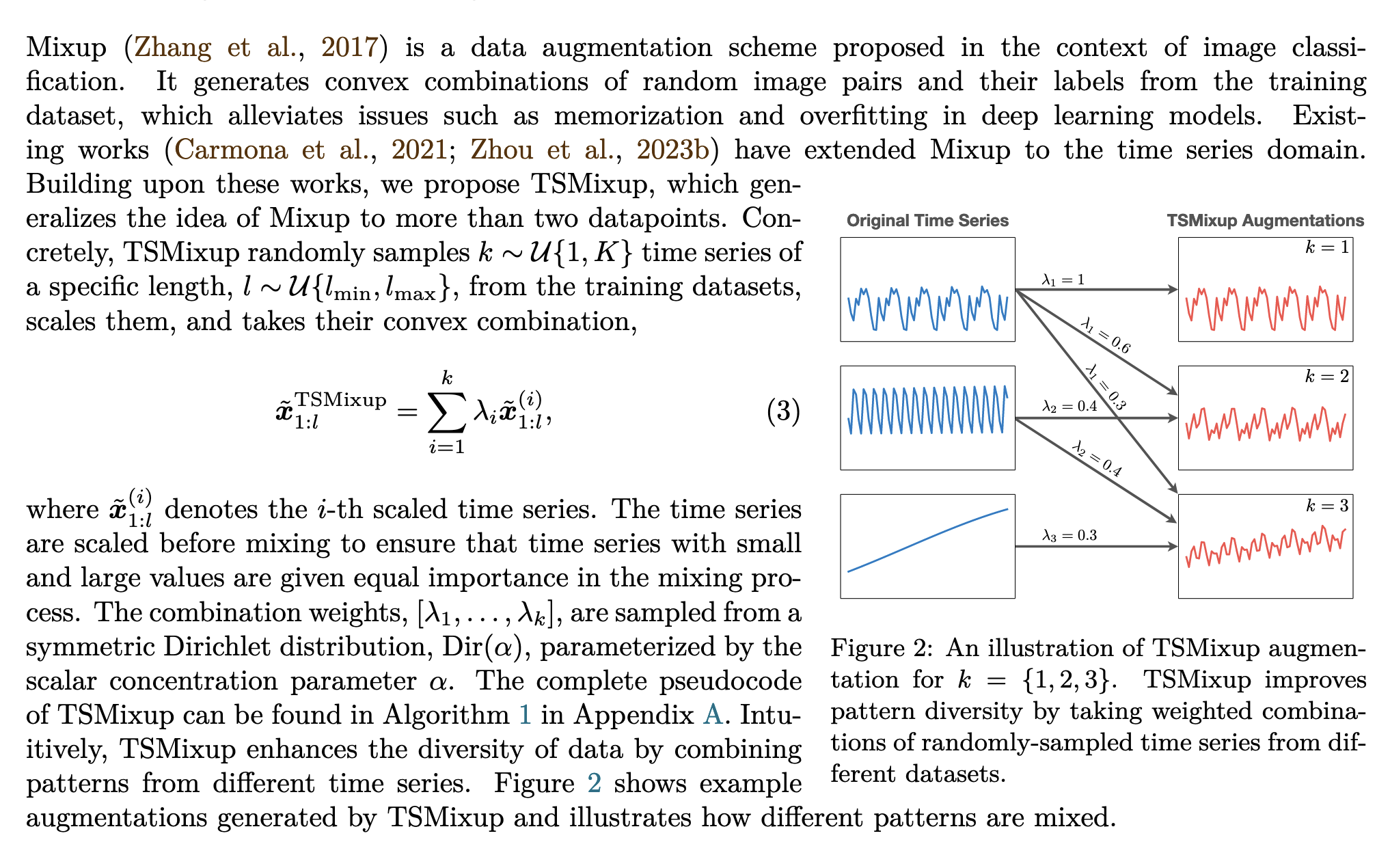
Data Augmentation:
TSMixup : 다른 시계열 데이터들을 섞어서 새로운 시계열데이터를 만들어냄.
Kernelsynth : Gaussian process를 기반으로 시계열 데이터 생성

