TS Foundation Model
1.Chronos: Learning the Language of Time Series
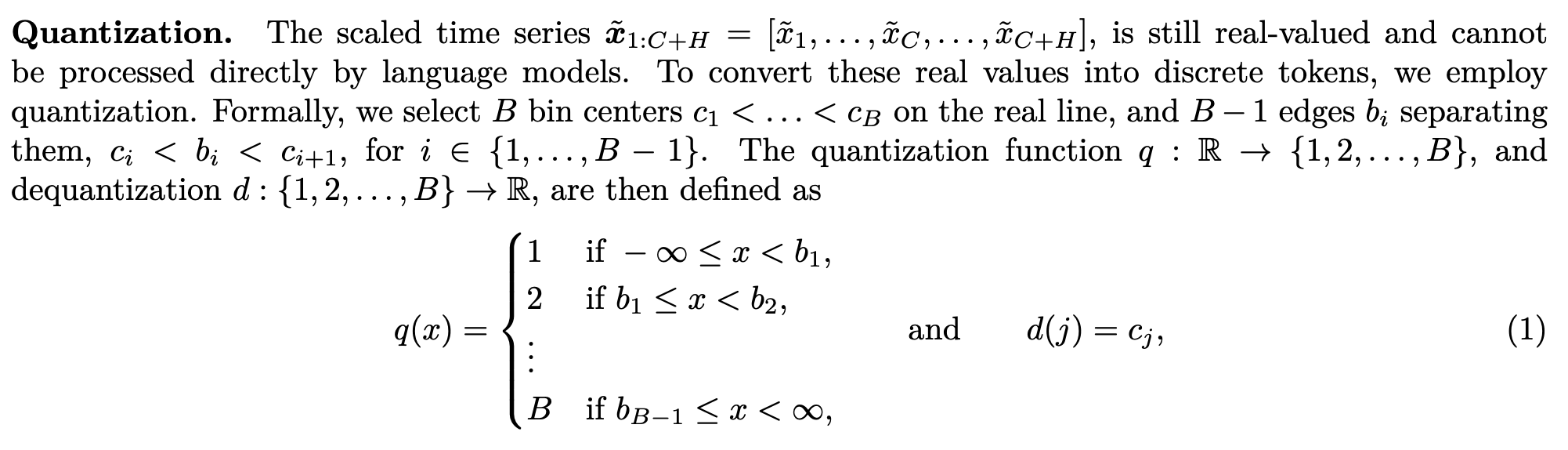
What are the fundamental differences between a language model that predicts the next token, and a time-series forecasting model that predicts the next
2025년 7월 3일
What are the fundamental differences between a language model that predicts the next token, and a time-series forecasting model that predicts the next