NN Network 11
Transformer
Transformer가 나오게 된 배경은 우리가 이때까지 블로그에다가 올린 글을 통해서 알 수 있습니다.
RNN -> LSTM -> LSTM + Attention -> Only Attention(Transformer)
이 순서로 발전해왔습니다.
Transformer는 Encoder의 집합과 Decoder들의 집합으로 이루어져있습니다.
각각의 Encoder는 아래와 같은 구조로 이루어져있습니다.
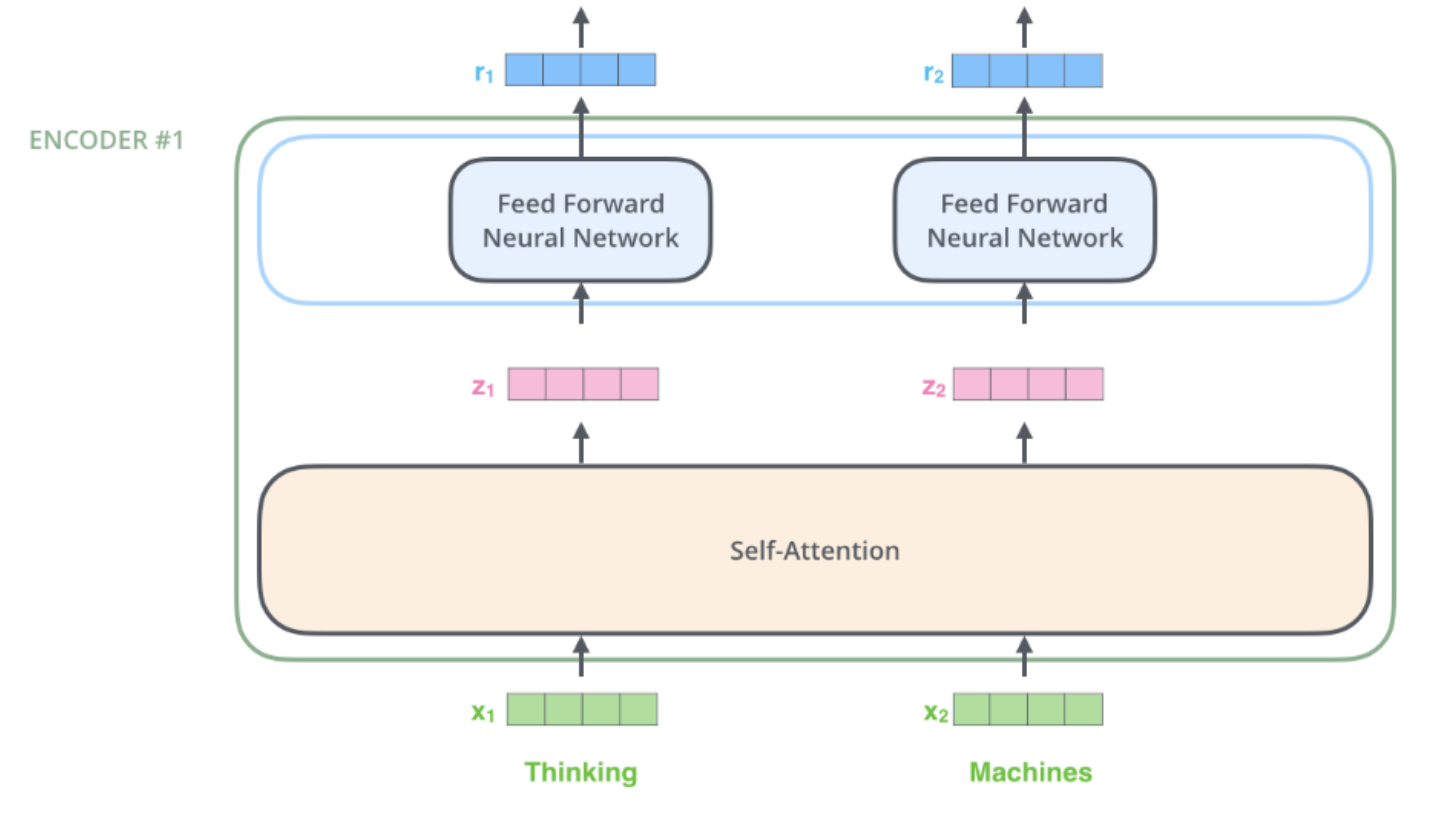

SheoYon.Jhin