NN Network 2
Neural NETWORK
Neural Network 신경망 네트워크는 이제 인공지능을 조금이라도 접해본 사람들에게 정말 익숙한 말이죠?
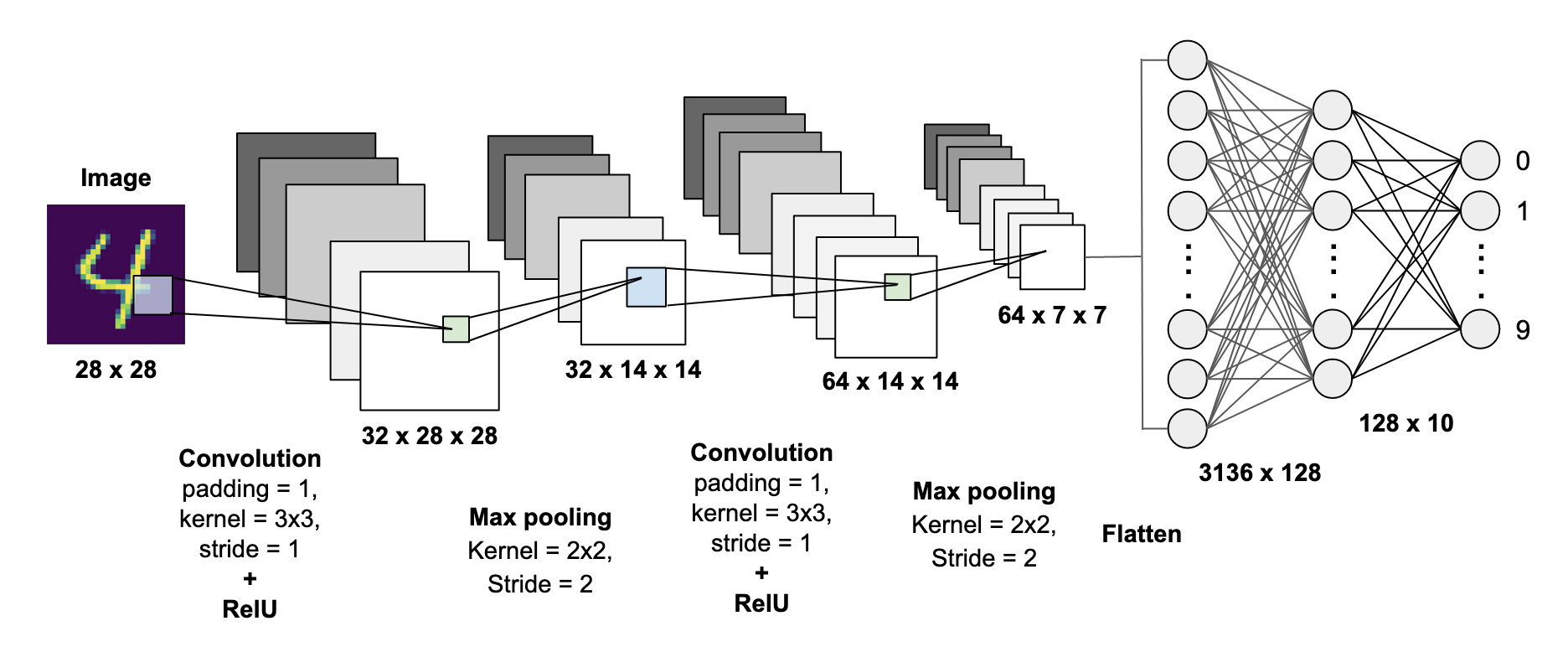
위의 그림과 같이 28*28 pixels = 784의 데이터가 신경망 네트워크로 들어갑니다.
우리는 앞에서의 포스팅을 통해서 이미지 데이터가 어떻게 신경망으로 들어가서 어떤 결과로 나오는지 잘 알 고 있습니다.
한번 더 이야기해보면, 흑백의 이미지인 MNIST가 들어가서 Convolution연산을 하는 Neural Network를 통과해서 10개의 class(0,1,2,3,4,5,6,7,8,9)의 확률을 결과로 보여주죠.
가장 높은 확률이란, "4"라는 이미지를 Neural Network연산을 통과했을 때 인공지능 모델이 말해주는 "4"일 확률이 가장 높다고 말해주는 결과를 말합니다.
이제 이미지를 자연어(말)로 바꾸어서 생각해보자, 이미지는 말그대로 디지털 데이터죠, 그렇기 때문에 픽셀로 나누어서 각각의 값을 신경망을 통해서 연산하는 과정에 대한 이해가 쉽습니다.
하지만, 자연어는 다르죠!
예를 들어, 영화 인터스텔라에 대한 감상평을 보고 긍정적인 리뷰인지 부정적인 리뷰인지 classification 하는 모델을 만든다고 생각해봅시다.
"Last Week, I saw Interstellar with a blind date, and it was so fun that i explained about the black hole to her in a cafe for an hour but, now no message from her, but it's okay because this movie was really amazing"
이런 감상평을 우리는 Neural Network에 넣기 위해서 one-hot vector/Encoding의 과정을 필요로 합니다.
One-Hot encoding
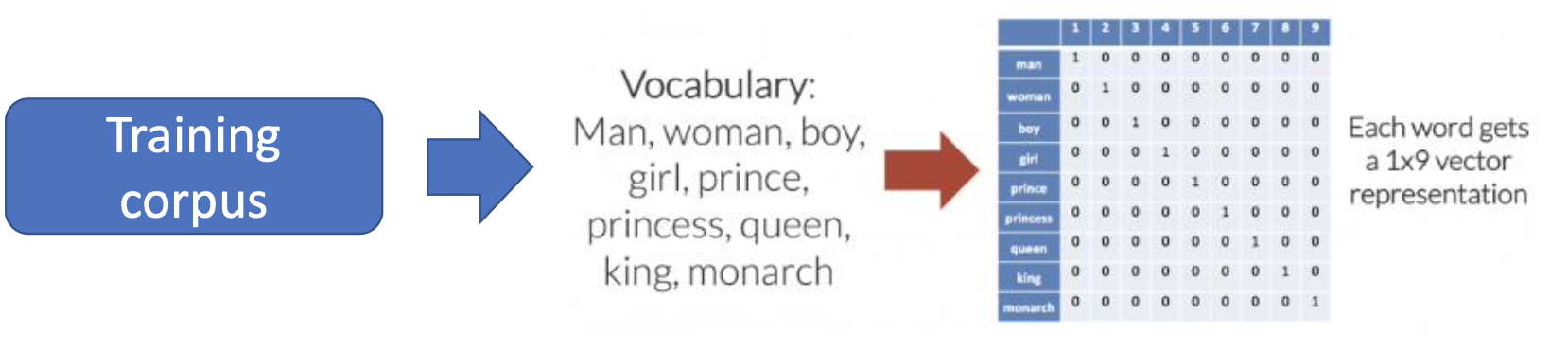
Training Corpus에는 Woman,Man,Girl, Boy, Princess,Prince,Queen,King,Monarch 등의 단어들이 존재한다. One Hot Encoding을 통해서 우리는 각각의 단어에 값을 주는데, 값을 정해주는 이 과정을 One Hot Encoding이라고 합니다.
우리는 One-Hot 이라는 이름에서부터 어떤식으로 임베딩을 하는지 알 수 있습니다.
전체 9개의 단어중 Queen이 7이라는 값을 부여받는다면, queen을 나타내는 벡터는 다음과 같습니다. -> [0,0,0,0,0,0,0,1,0,0]
즉, 신경망에 Queen이라는 단어를 input으로 넣어줄때 우리는 one-hot embedding을 통해서 [0,0,0,0,0,0,0,1,0,0] 을 넣어줍니다.
이때, 보면 queen에 해당하는 값만 1인것을 알 수 있죠.
이런식으로 임베딩을 하는 것을 one-hot embedding이라고 합니다!

임베딩된 단어들은 위의 그림과 같이 신경망에 들어갈 수 있습니다.
Drawbacks of One-Hot Representation
one-hot 임베딩에는 많은 단점이 존재합니다.
그 중 대표적인 2가지를 이야기하겠습니다.
1. Curse of Dimensionality
2. Orthogonality
1. Curse of Dimensionality (차원의 저주)
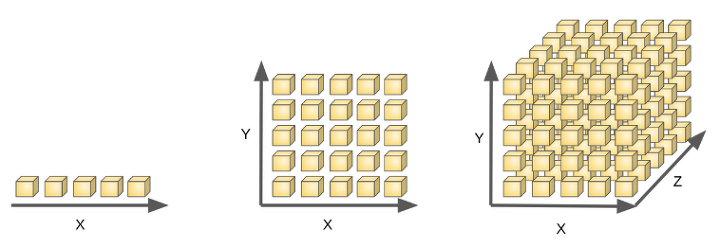
차원이 높아질수록 데이터 사이의 거리가 멀어지고 빈 공간이 증가하는 공간의 sparsity를 보입니다. 즉, 데이터의 차원이 많아질수록 데이터의 질이 낮아지고, 메모리 사용량(Memory use)과 계산 시간(computation time)가 늘어나서 좋지 않겠죠
차원이 증가함에 따라서 모델의 성능이 안좋아지는 현상인데, 주로 관측치의 수보다 변수의 수가 많아지면 발생합니다.
예를들어 우리가 가지고 있는 관측치가 10개인데 변수가 30개일 경우 발생합니다.
차원의 저주를 피하기 위해 우리는 PCA와 같은 차원 감소 알고리즘을 사용합니다.
2. Orthogonality
One-Hot Embedding에는 단어간의 유사성을 알 수 없다는 단점이 있습니다. 예를 들어 queen 을 나타내는 값 [0,0,0,0,0,0,0,1,0,0]과 King을 나타내는 [0,0,0,0,0,0,0,0,1,0]의 거리는
queen과 boy를 나타내는 [0,0,1,0,0,0,0,0,0,0] 의 관계보다 더 가깝다고 가정하겠습니다. 실제로 거리를 계산해보면 queen과 king사이의 거리와 Queen과 boy사이의 거리는 똑같은 것으로 보입니다. 즉, 단어간의 유사성이나 관계성이 전혀 나타나지 않는다는 단점이 있습니다.
이러한 문제점들을 해결하기 위해서 PCA,LDA,LSA등과 같은 기법들을 사용해서 해결해 나가죠.
## PCA , LDA는 다른 포스트에서 자세하게 다루도록 하겠습니다.