NN Network
AI(Artificial Intelligence)안에는 다양한 분야들이 있습니다.
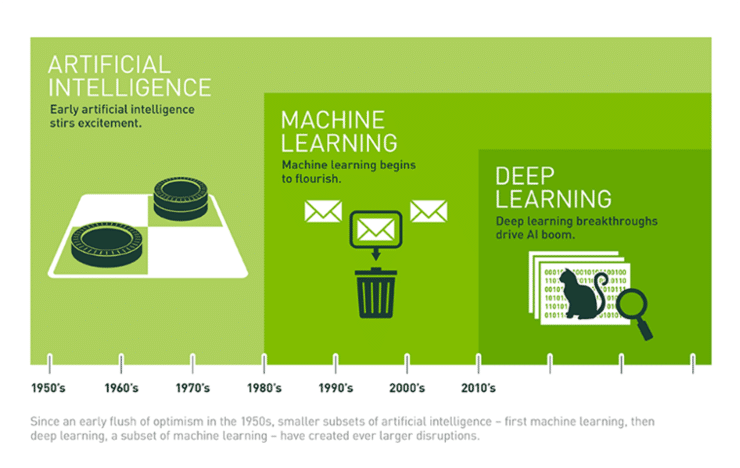
인공지능(Artificial Inteligence)은 쉽게 말해 인간의 지능을 컴퓨터로 구현한 것을 이야기하죠.
하위 개념인 머신러닝(Machine Learning)은 데이터로부터 특징점(Feature map)을 뽑아내고 그 feature들에서의 Pattern, co-relation을 추출등의 데이터 분석을 통해 학습하고, 학습한 내용을 기반으로 판단,예측을 합니다.
예를 들어 IoT서비스에 머신러닝을 적용한다고 생각해볼까요?
음성인식 기술을 통해 "창문을 닫아줘"라고 이야기하면 창문을 닫아주는 기술이 머신러닝입니다.
이때, "창문을 닫아줘"라는 데이터를 받고 이를 분석해서 실제로 프로그래밍된 창문을 닫는 기능이 되도록 하는 것이 머신러닝인 거죠
그렇다면 머신러닝에 포함된 딥러닝(Deep Learning)은 어떤 차이가 있을까요?
딥러닝은 "창문을 닫아줘"보다 "추워" 라는 말을 인식해서 창문을 닫아야 한다는 것을 이해할 수 있도록 자체적인 지능이 있는 것처럼 보이도록 하는 기술입니다.
딥러닝의 테스크중 가장 익숙한 이미지 분류 예시를 들어서 설명하겠습니다.


고양이와 강아지, 사람을 분류하는 딥러닝을 만드는 과정을 이야기하겠습니다.
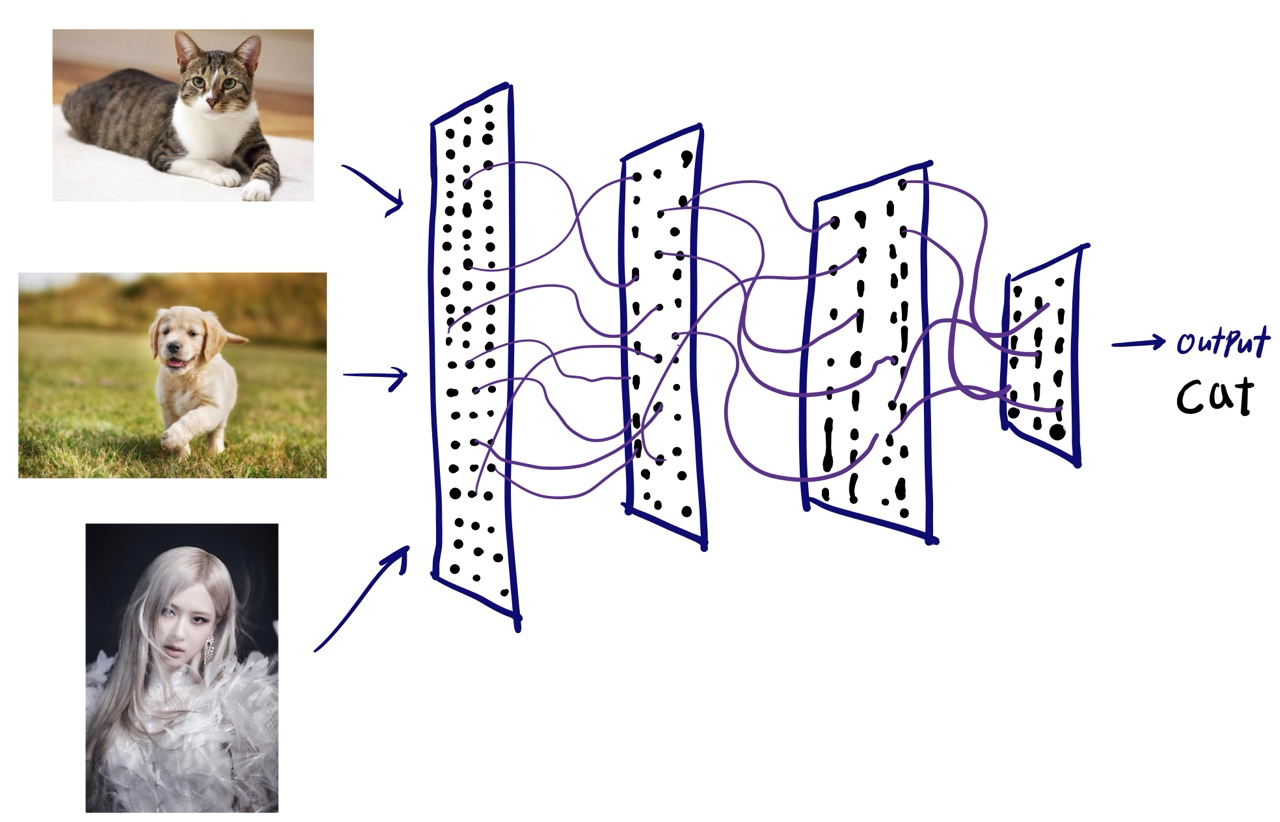
딥러닝에서는 데이터의 feature를 neural network를 통해 생성합니다.
생성된 결과는 여러 Layer들을 통과해 확률 값을 보여주는데요
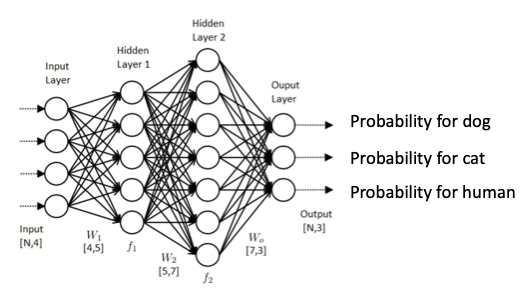
예를 들어, 위의 경우 input데이터를 받아서 여러 Hidden Layer를 통과해서 만들어낸 결과는 3가지(고양이,강아지,사람)의 확률 값을 return하고 그 중 가장 높은 확률을 갖는 class(label)을 반환합니다.
그렇다면!
Neural Network라는게 정확히 어떤 것이길래, 이미지의 feature를 추출하고, 여러 Layer란 어떤 것이길래, 그리고 어떤 과정을 거치길래 각각의 확률이 나오는지는 이제 설명하겠습니다.
위의 그림을 다시 보겠습니다.
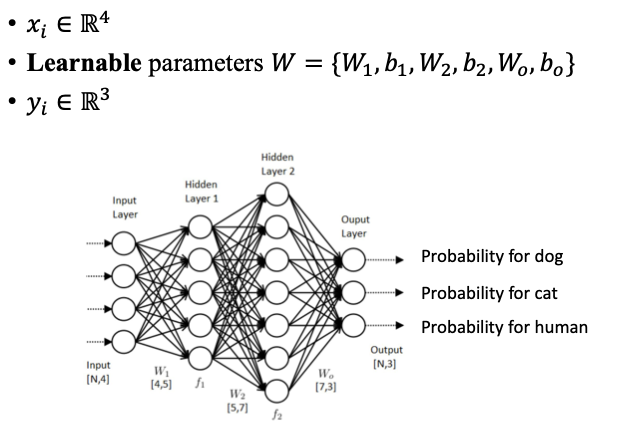
이미지 데이터를 feature extract와 같은 과정을 거쳐서 (N,4)라는 input으로 받아들입니다. (여기서 N은 데이터의 개수겠죠? 예를 들어 이미지를 10장 넘겨준다면, N=10이 됩니다.)
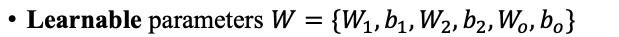
그렇게 받은 데이터를 우리는 Layer를 통과시켜줍니다.
Learnable parameters란 말 그대로 학습이 되는 파라미터들입니다. 여기서 W1,b1,W2,b2,Wo,bo는 linear를 나타냅니다.
linear가 뭔가요? 선형함수입니다.
즉, y = ax +b 와 같은 것들을 말합니다.
그렇다면 Layer1에서 나타내는 함수는 f = W1x+b1 이렇게 되겠죠?
마찬가지로 Layer2, Layero 에서도 전부 같은 형식이고 단지 반환하는 shape만 다른 겁니다.
자! 이제 Learnable parameter를 다시 곱씹어봅시다.
우리의 네트워크는 W1,b1,W2,b2,Wo,bo을 학습하는 겁니다.
linear를 통과한 데이터는 마지막 Layer에서 probability for dog,cat,human 총 3가지 값을 반환합니다.
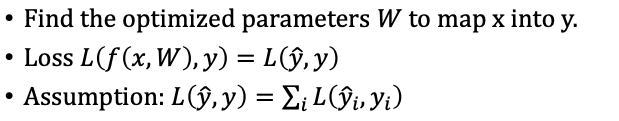
이렇게 반환한 것이 만약 첫번째에 반환하면 첫번째 Epoch에서의 결과라고 할 수 있습니다.
첫술에 배부를 수는 없겠죠?
우리는 이때의 결과를 채점합니다. Loss라는 것을 통해서요 우리의 모델이 얼마나 정확하게 분류했는지 알아내는과정이죠 .
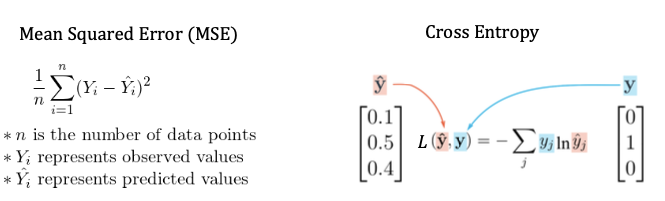
우리가 Loss를 계산하는 방식은 여러가지가 있습니다. 주로 MeanSquared Error와 Cross Entropy들이 있죠.

loss가 최소가 되는 W1,b1,W2,b2,Wo,bo를 알아내는 것이 진짜 딥러닝의 학습인거죠.
