NN Network 5
Word2vec
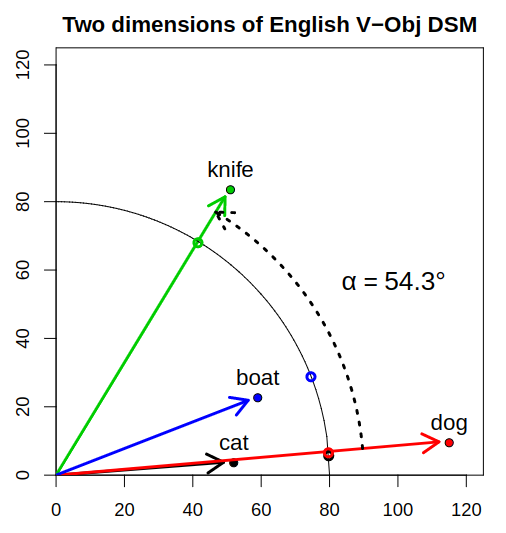
Distributional Hypothesis
Word2vec은 자연어처리에 있어서 계속해서 쓰이는 기술입니다.
Word2vec에서 가장 중요한 개념은 언어학인 Distributional Hypothesis 즉, 분포 의미론입니다. 분포의미론은 언어 데이터의 큰 샘플에서 분포 특성을 기반으로 언어 항목 간의 의미론적 유사성을 정량화하고 분류하기위한 이론과 방법을 개발하고 연구하는 연구 분야입니다.
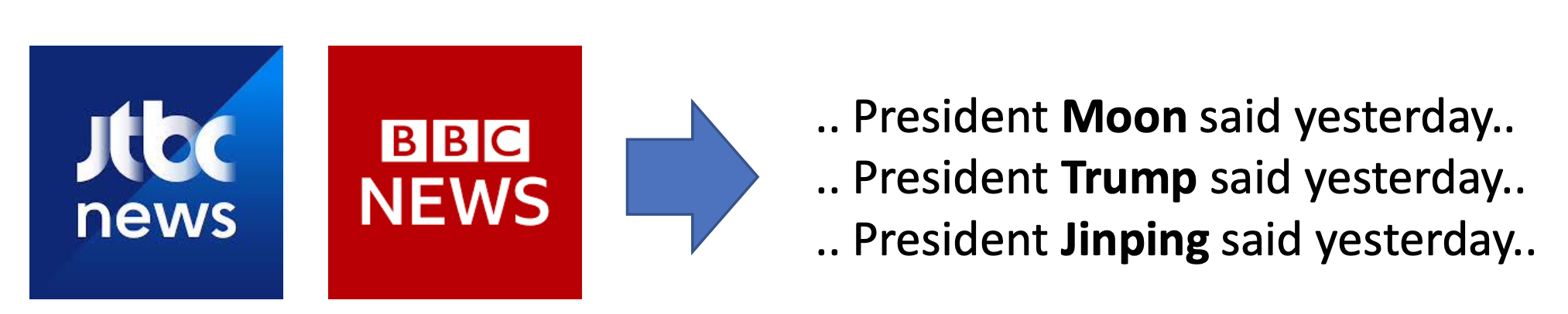
예를 들어, 위의 사진처럼 같은 맥락에서 사용된 횟수가 많을 수록 이 단어들은 비슷한 의미를 가진다는 것을 알 수 있습니다. 즉, Moon,Trump,Jinping 이 3단어는 의미론적 유사성이 높다는 것을 알 수 있습니다.
Word2vec의 모델은 Continuous Bag Of Word(CBOW)와 Skip-Gram모델 두 가지다.
CBOW(Continuous Bag Of Words)
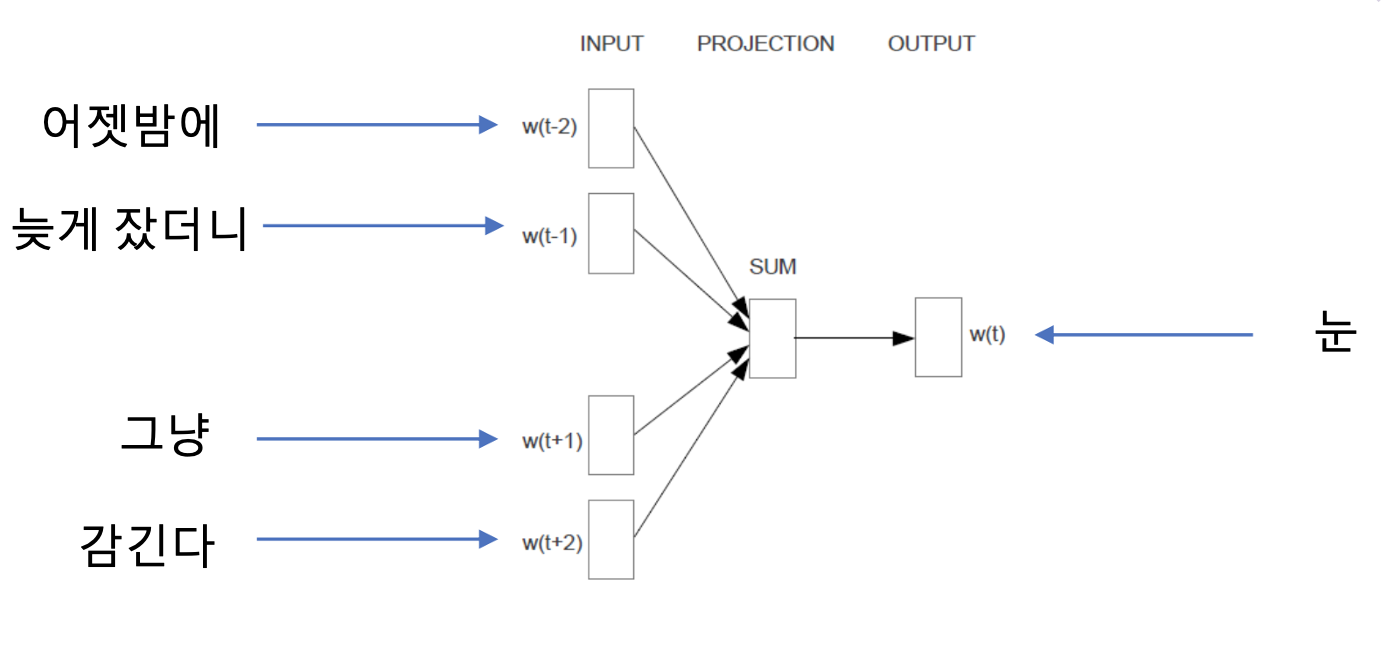
CBOW는 내가 알고싶은 t에서의 단어를 기준으로 t-2,t-1 의 단어들과 t+1,t+2의 단어들을 보고 t에서의 단어를 예측해내는 단어입니다.
예를 들어서 어젯밤에 늦게잤더니 (눈이) 그냥 감긴다. 이런 문장이 있다고 할때,
(눈이) 를 유추하기위해서 "어젯밤에 늦게잤더니" 와 "이 그냥 감긴다"를 보고 CBOW는 (눈이)를 유추할 수 있죠!
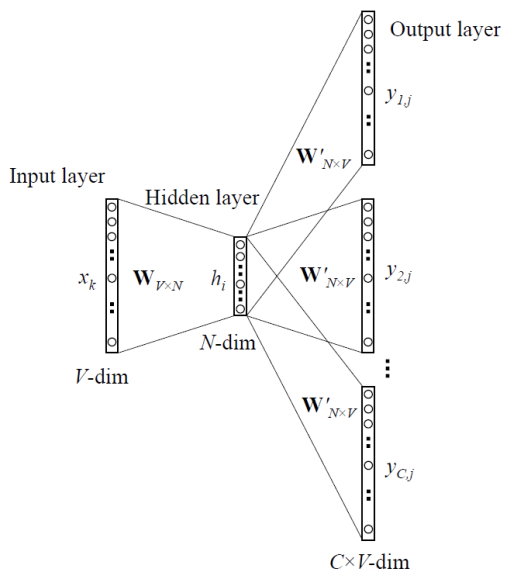
CBOW의 모델 구조는 아래와 같습니다.
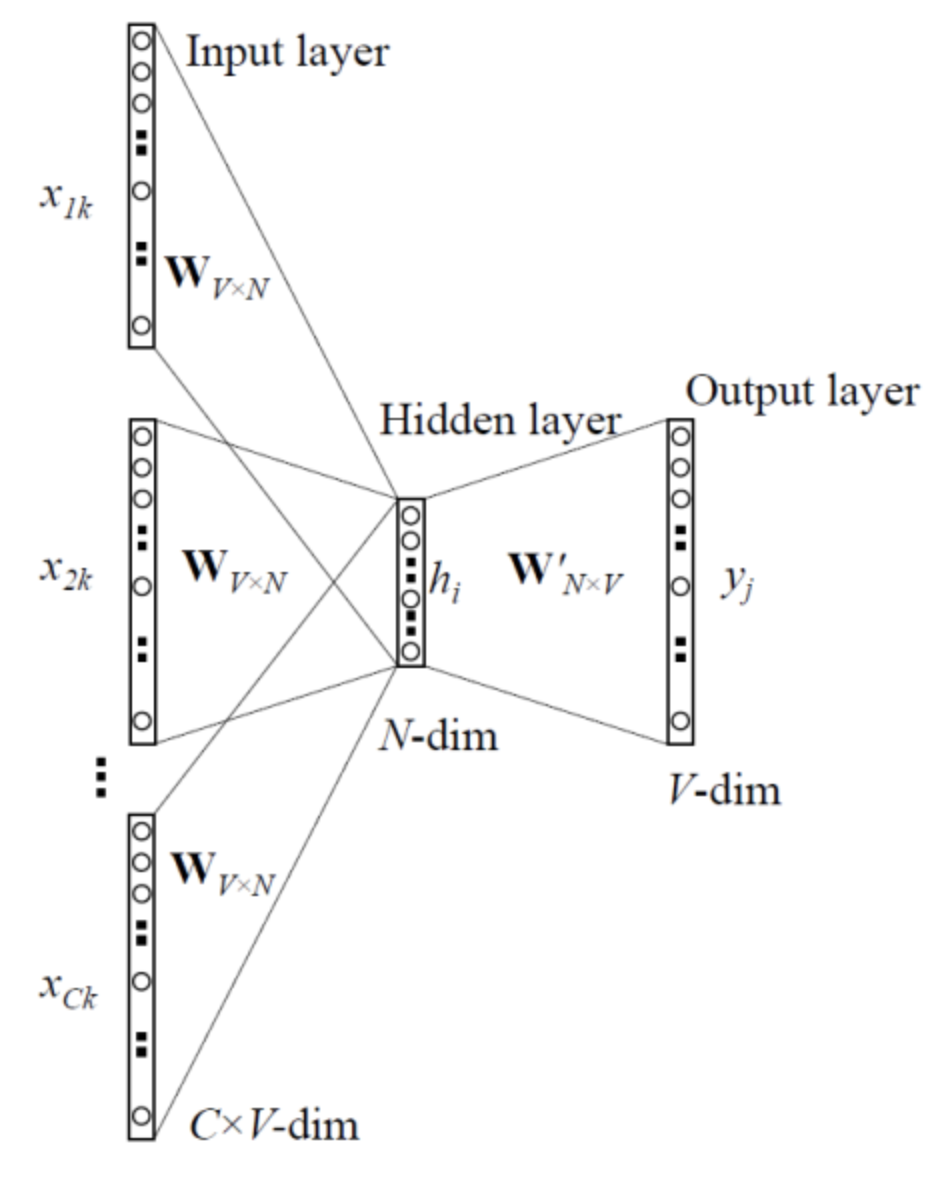
CBOW의 모델을 학습시키기 위해서는 Input으로 주어진 자연어 데이터를 one-hot vector 방식으로 만들어줍니다.
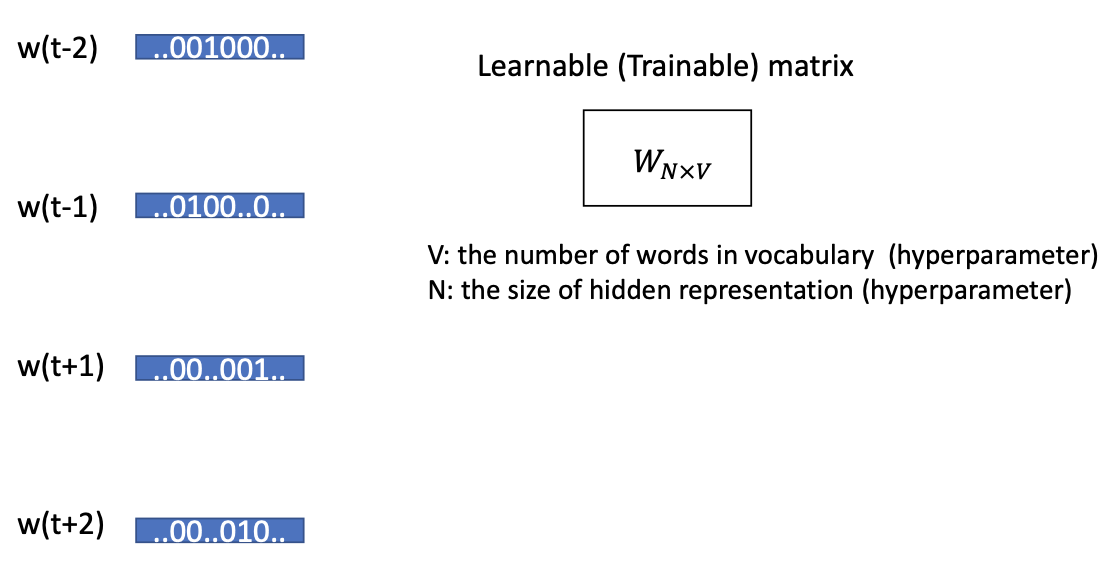
위와 같이 우리가 알고자 하는 t에서의 단어를 알기위해서는 t-1,t-2에서의 단어와 t+1,t+2에서의 단어를 보고 t에서의 단어를 유추할 수 있습니다.
이때, Learnable(Trainable) matrix는 input이 Learnable matrix를 통과해서 Hidden Layer를 생성하는데 사용합니다.
Skip-gram
Skip-gram모델은 CBOW모델과 정반대인 모델입니다.
문맥을 보고 t에서의 단어를 유추했다면, Skip-gram에서는 하나의 단어를 보고 문맥의 단어들을 유추해냅니다.
아래는 Skip-gram 모델의 구조입니다.
보면, 위에서 설명했던 CBOW모델과는 반대의 구조인 것을 알 수 있습니다.
둘을 한번 비교해서 볼까요?
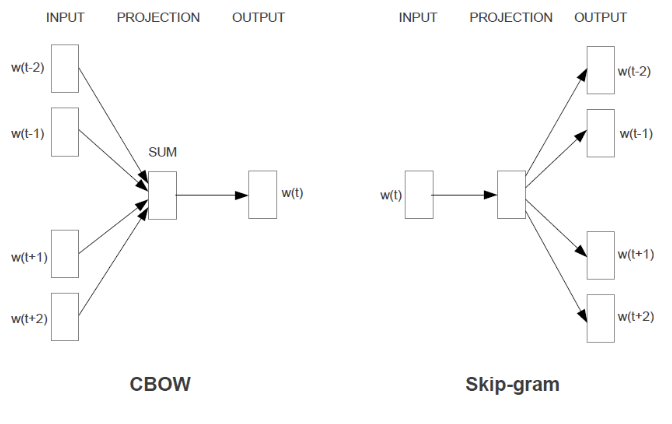
둘을 함께 놓고 보면 encoder - decoder의 모델 구조랑 정말 비슷해보입니다.
Skip-gram도 input으로 들어온 단어를 one-hot-vector로 생성한다.
이 과정을 자세히 보면 아래와같습니다.
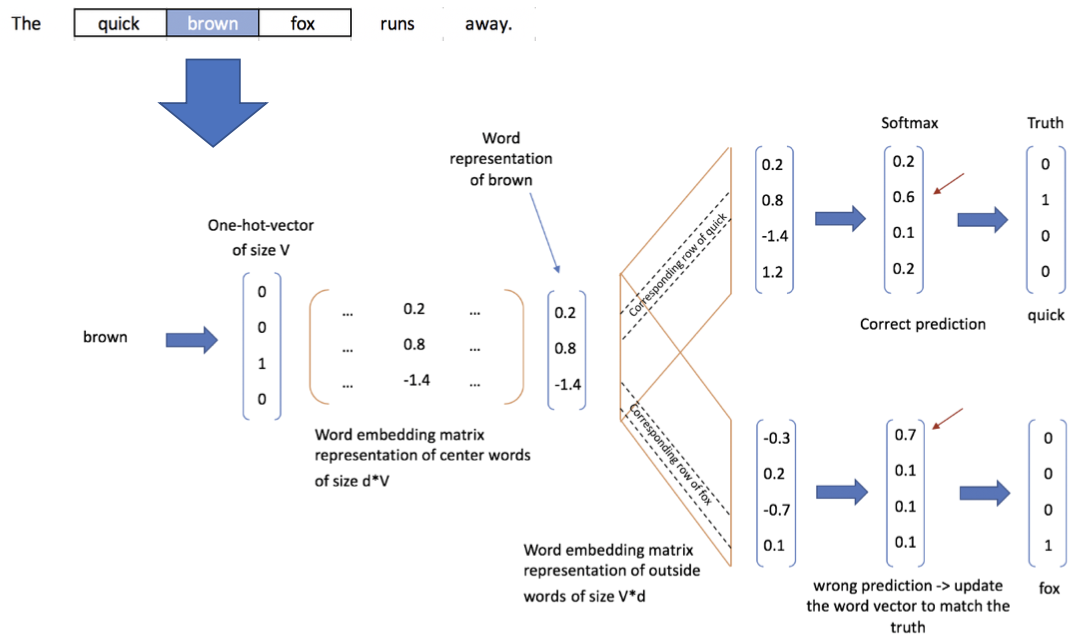
brown이라는 단어를 one-hot-vector로 생성합니다. [0 0 1 0] 으로 이루어진 vector가 나온다. 이 단어를 Learnable Matrix를 통과시켜서 word representation of brown을 만들고. 그 후, 맥락에 있는 단어들을 유추해내죠.
Difference between CBOW and Skip-gram
CBOW의 경우 Skip-gram과 다르게 학습하는 시간이 상대적으로 빠르고 자주 등장하는 단어의 유추일 경우 정확도가 높은 것을 알 수 있습니다.
Skip-gram은 데이터가 많이 필요한 cbow와 달리 작은 데이터로도 잘 유추할 수 있다는 장점이 있습니다.
