NN Network 8
GLUE Benchmark
GLUE(General Language Understanding Evaluation) 벤치마크는 general한 언어 이해 시스템 개발이라는 목적으로 제작된 " 데이터셋 " 입니다.
GLUE를 이용해서 자연어 처리 모델을 훈련시키고, 자연어 이해 능력을 평가할 수 있어졌습니다.

GLUE에는 다양하고 어려운 9가지의 테스크(CoLA, SST-2,MRPC,QQP,STS-B,MNLI,QNLI,RTE,XNLI)가 있습니다.
우선 이 9가지의 테스크를 위의 그림과 같이 크게 Single Sequence Tasks와 Sequence Pair Tasks로 나눌 수 있습니다.
이번 포스팅에서는 제가 자연어에 대해서 아직 공부를 하고 있기때문에 간단하게 각각의 테스크들이 어떤 것인지 알아보겠습니다.
Single Sequence Tasks
우선 Single Sequence Tasks의 테스크에서는 CoLA와 SST-2 두 데이터셋을 사용합니다.
Single Sequence Task는 이진 분류 문제라고 생각했습니다. 단문장을 기준으로 acceptable한지 아닌지 분류하거나 긍정적인 감정인 부정적인 감정인지를 분류하는 TASK입니다.
-
CoLA(Corpus of Linguistic Acceptability): 영어문장이 언어학적으로 acceptable한지 확인하는 이진분류문제
-
SST-2(Stanford Sentiment Treebank): 단문장 이진분류문제. 영화리뷰에서 추출된 문장에 감정이 표기되어있음. 긍정과 부정으로 분류됨.
Sequence Pair Tasks
Sequence Pair Tasks에는 아래와 같이 많은 종류의 Task들이 있습니다.
Sequence Pair Tasks는 단문단을 이용한 TASK였다면 Sequence pair tasks는 다문단을 이용한 Task이다.
Paraphrase Identification
-
MRPC(Microsoft Research Paraphrate Corpus): 문장쌍의 유사성 확인하는 문제로 Sequence Pair Tasks중에서도 Paraphrase Identification을 하는 Task입니다. 2005년에 소개된 데이터셋으로 양이 많지 않은 데이터셋이지만, Sparse data scenario를 테스트하는데 유용한 데이터셋입니다.
-
QQP(Quora Question Pairs): Quora에 올라온 질문 페어가 의미적으로 동일한지 확인하는 테스크입니다. 아래의 이미지는 Quora에 올라오는 질문들을 정리한 데이터의 일부입니다.

Similarity Prediction
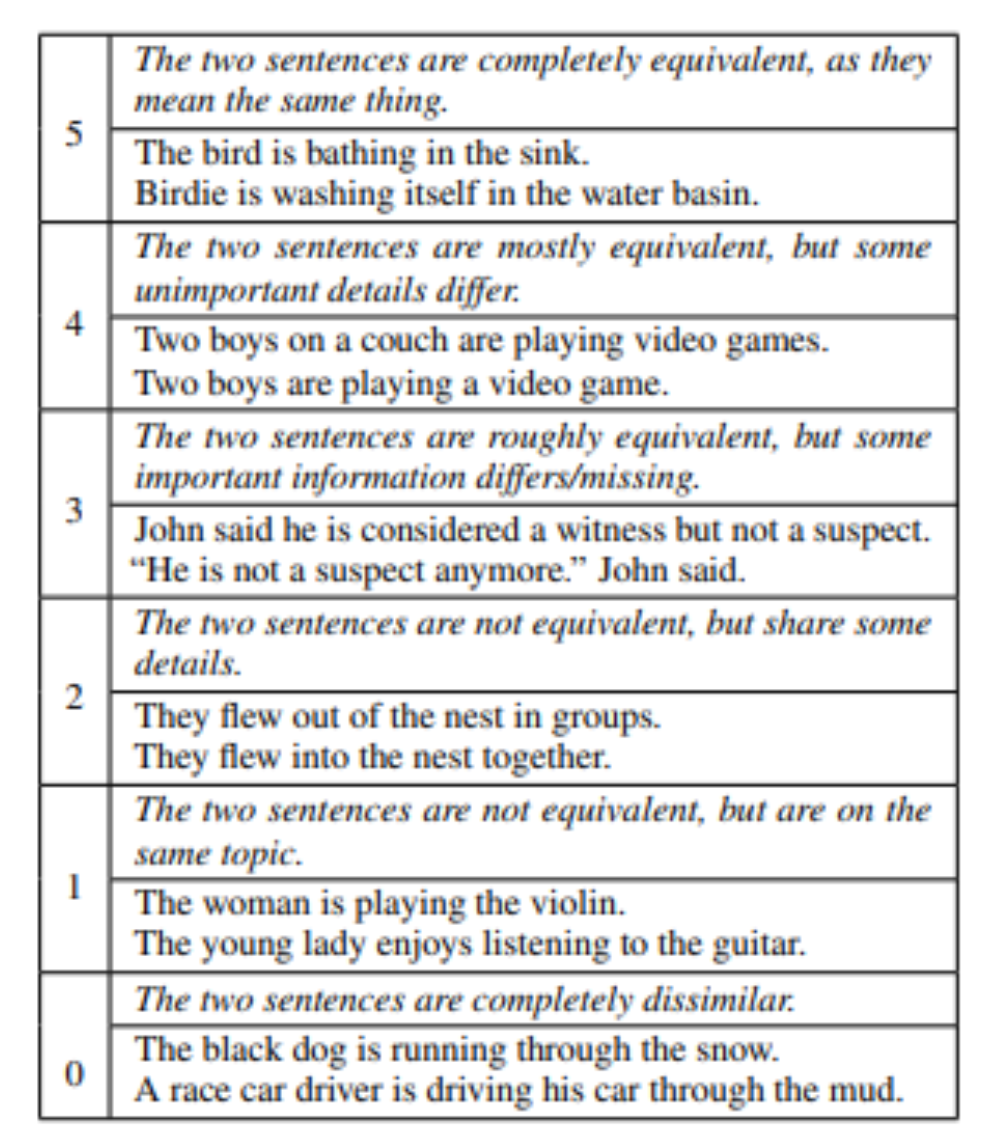
- STS-B(Seemantic Textual Similarity Benchmark): 문장쌍이 얼마나 유사한지 확인하는 문제로 뉴스 헤드라인, 비디오 및 이미지 캡션, 자연어 추론 데이터에서 가져온 문장 쌍의 모음입니다. 각각의 페어는 1점 부터 5점의 유사성 점수가 있습니다. 이 점수는 사람이 직접 입력한 것 입니다.
Natural Language Inference (NLI)
자연어의 이해에는 기본적으로 entailment(함의)와 Contradiction이 기초적으로 되어있어야합니다. 즉, 문장의 뜻을 정확히 이해하는것이 자연어 이해의 기본이겠죠?
-
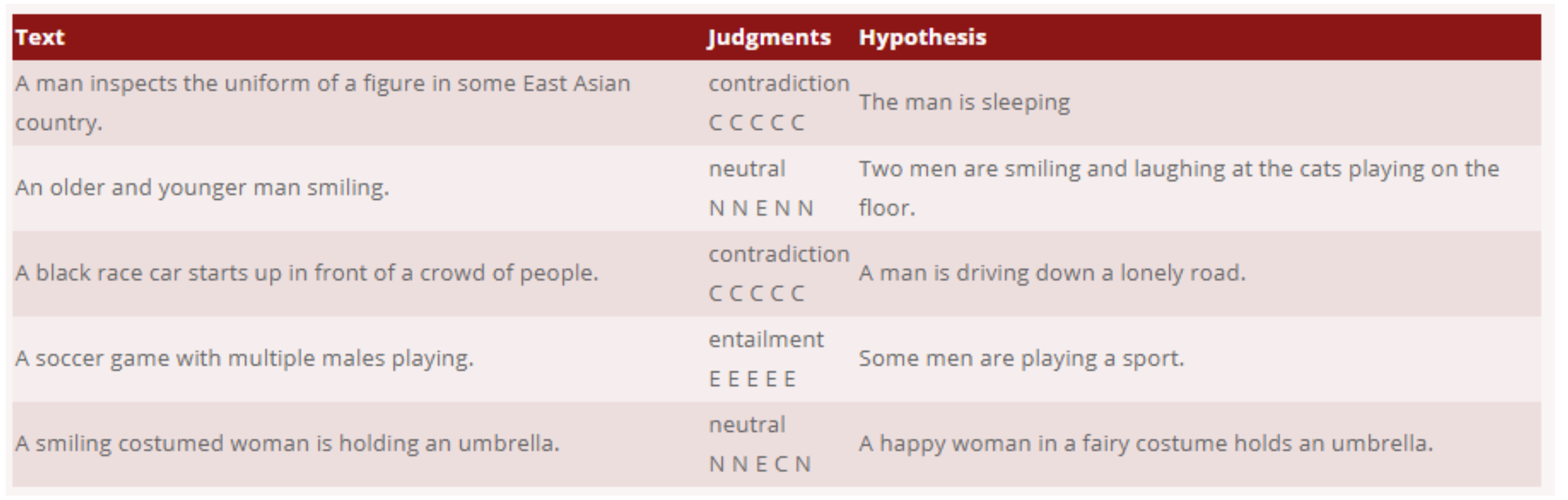
SNLI(Standford NLI) : 약 50 만 자연어 추론 (NLI) 문제 데이터셋입니다. 각 instance 는 한 쌍의 문장 (premise 와 hypothesis)과 label (entailment, contradiction, neutral) 로 구성되어 있습니다. 데이터셋이 그림에 대한 캡션으로만 이루어져있다는 것이 특징입니다.
-
MNLI(Multi-Genre Natural Language Inference): 이 데이터셋은 Stanford NLI(SNLI) 데이터셋의 그림에 대한 캡션으로만 이루어져있다는 단점을 극복한 데이터셋입니다. MNLI는 한정적인 SNLI에서 더 나아가 다양한 분야의 글들이 들어있습니다.
-
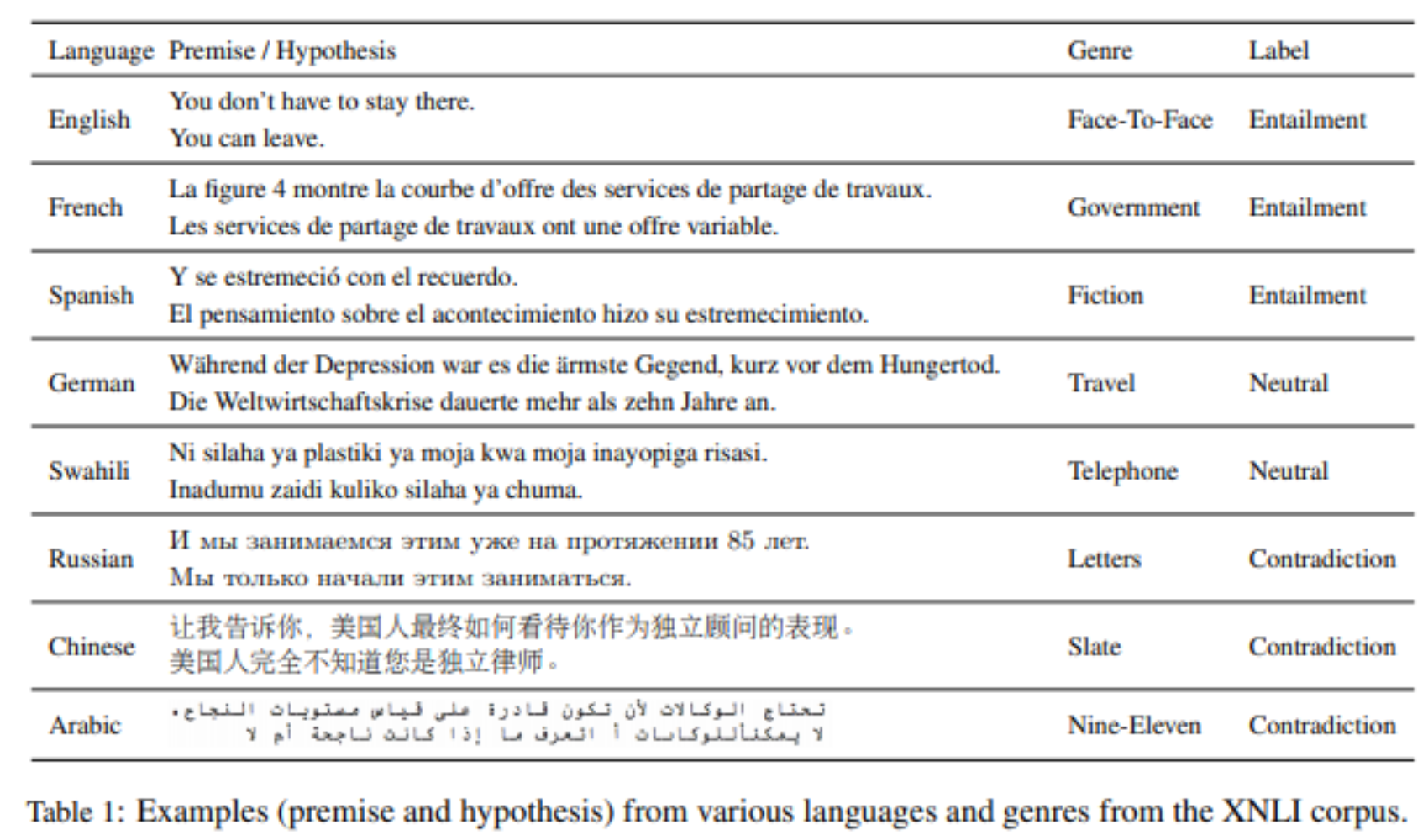
XNLI(The Cross-lingual Natural Language Inference) : 이 데이터셋은 5000개의 test와 2500개의 dev쌍으로 이루어진 데이터 입니다. 각각의 pair는 문맥의 함의를 명시하고 14개의 언어로 번역되어있습니다. XNLI는 English NLI 데이터만 학습으로 사용하였을 때, 다른 언어에서도 inference가 어떤 성능을 가지고 있는지 알 수 있는 TASK에 사용되는 데이터셋입니다.
-
QNLI(Question Natural Language Inference): SQuAD의 이진분류 버전. paragraph가 answer를 포함하는지 안하는지 확인하는 문제입니다.
문맥에서 질문과 문장사이에 페어를 만들고, 질문과 문맥이 있는 문장 사이의 어휘 중첩이 낮은 페어를 필터링합니다.

-
RTE(Recognizing Textual Entailment): MNLI와 유사하나 데이터가 적습니다.
-
WNLI(Winograd NLI): 자연어 추론 데이터셋이나 현재 채점에 이슈가 있어서 BERT 실험에서는 제외됩니다.
