NN Network 9
Seq 2 Seq Attention
Applications of RNNs
자연어처리에 관해서는 RNN은 크게 세가지 용도로 쓰입니다.
1. Many to one (ex Language Classification)
작성된 문장(many)을 보고 어는 나라의 언어(one)인지 분류하는 것
- One to Many (ex Image Description)
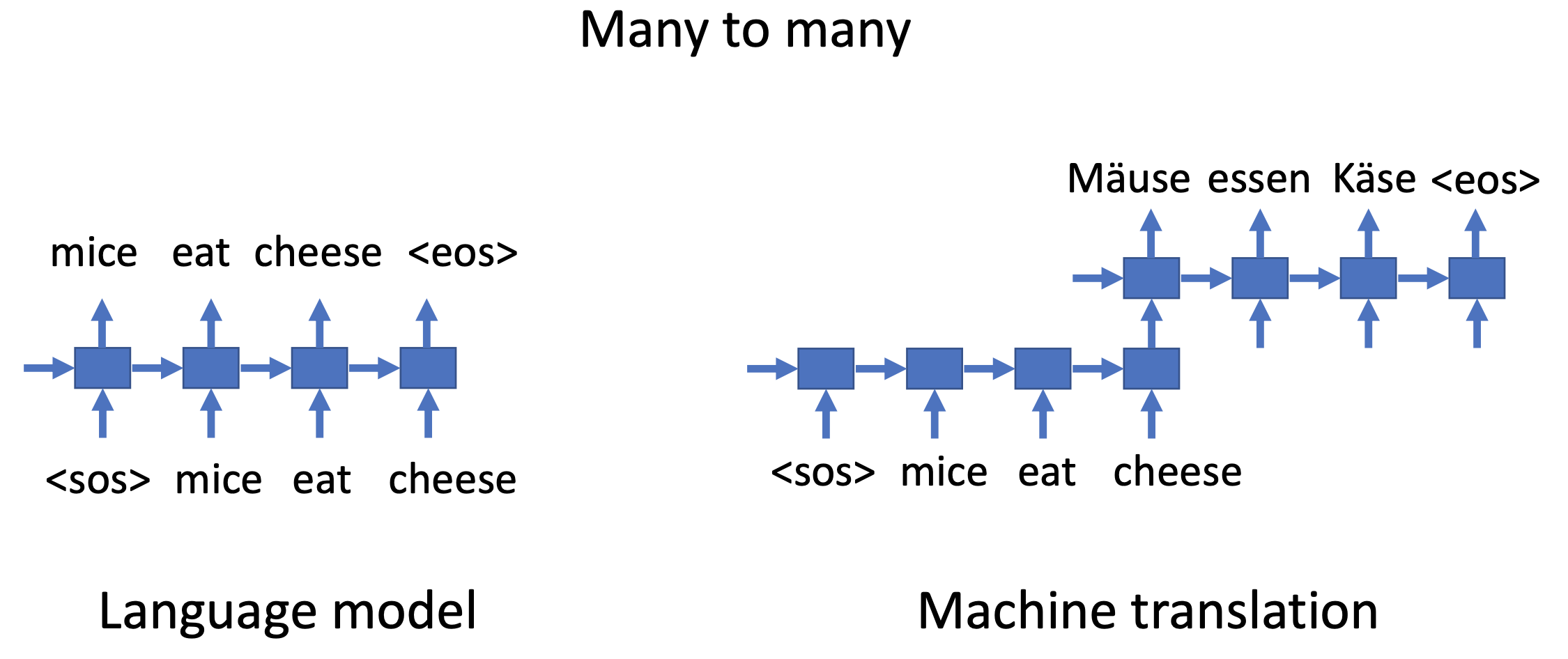
이미지(one)를 보고 이미지에 대한 설명(many)을 하는 것 - Many to Many (ex Language model/ Machine Translation)
작성된 문장(many)을 보고 다른 나라의 언어로 번역(many) 하는 것

Translation
the black cat drank milk을 불어로 번역해보자 le chat noir a bu du lait
input은 5개의 단어(sequence)로 이루어진 것이고 우리가 원하는 output은 7개의 단어로 이루어진 (sequence)입니다.
어떻게 하면 인공지능이 번역을 하도록 할 수 있을까요?
우리는 영어를 encoder에게 맡기고 번역된 언어(불어)를 decoder에 맡깁니다.
Encoder-Decoder model
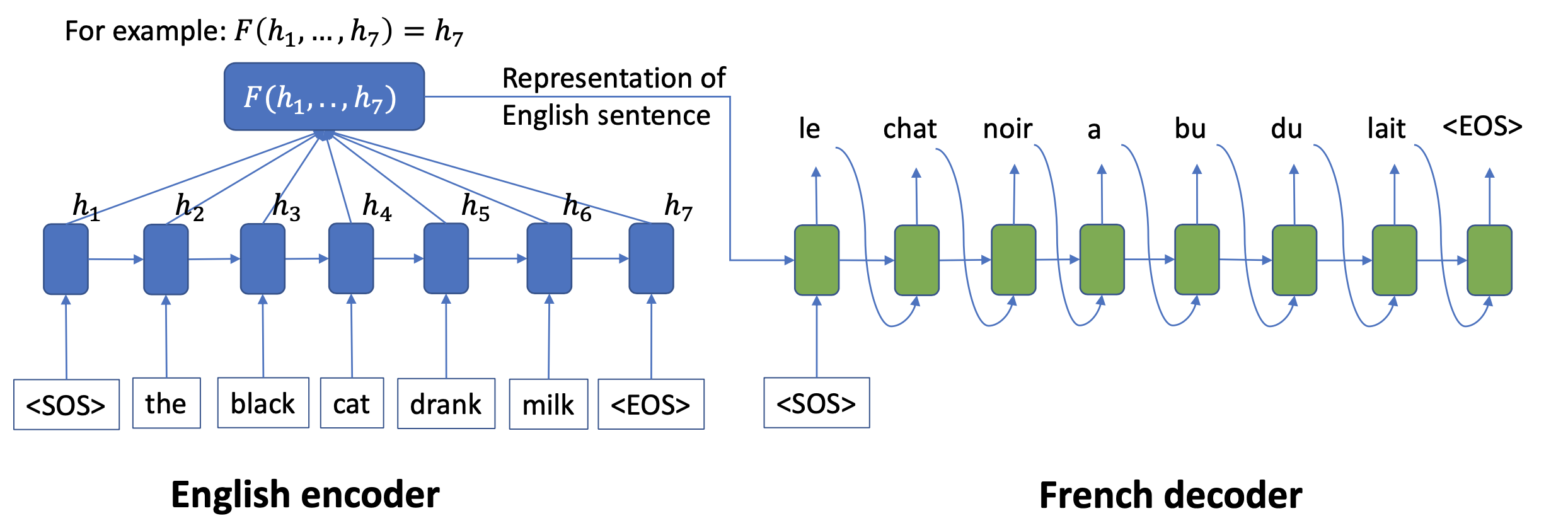
encoder는 영어롤 인코드해서 영어 sequence의 정보를 모두 가져옵니다. 이 hidden vector를 decoder에 넣어주면 영어 sequence에 대한 정보를 받은 decoder는 불어로 번역을 하는 것입니다.
캡션(그림 밑의 글) 생성, 번역등과 같은 자연어의 Task에서는 주로 문장을 예측합니다. 문장이라하면 단어의 연속이라고 할 수 있겠죠?
모델들의 출력은 각 단어들에 대해 사전크기의 확률 분포라고 할 수 있습니다. 이 사전 크기의 확률 분포들은 문장속의 단어를 가르킵니다.
가장 가능성이 높은 출력 시퀀스를 디코딩하는 것은 우리가 얻은 확률분포에 기초하여 가능한 모든 출력 시퀀스를 찾습니다. 우리가 찾아야 하는 정답은 단어의 수간 많아질수록 찾기가 어렵겠죠?
그래서 휴리스틱한 탐색방법인 Greedy Search가 기존의 방법보다 충분하게 디코딩된 출력 시퀀스를 반환하게 됩니다..
단어들의 후보 시퀀스들은 그들의 likelihood에 따라 점수화되고, 다음 텍스트를 예측하는 것에 Greedy Search와 Beam Search을 일반적으로 사용한다.
1. Greedy Inference
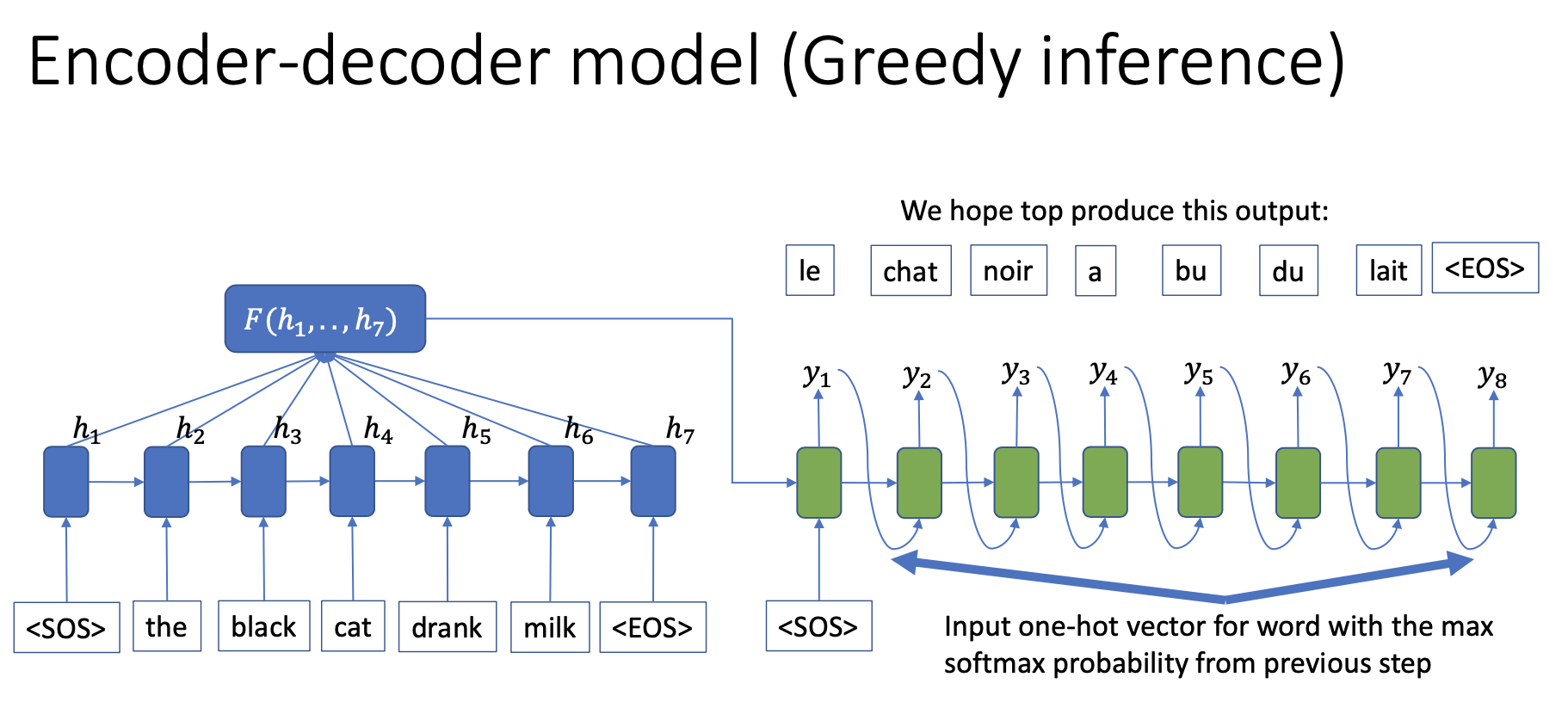
위의 그림을 보면 우리는 Greedy Inference가 decoder에서 쓰인다는 것을 알 수 있습니다.
greedy search는 각 출력을 예측하는데 각 스텝에서 가장 가능성이 높은 단어를 선택합니다.
그래서 탐색하는데 매우 빠르지만, 최종 츌력에서는 최적화된 결과에서부터 멀어지게 됩니다.
2. Beam Search

Greedy Inference가 확장된 Beam Search는 기존의 Greedy Inference와는 다르게 가장 높은 확률 "시퀀스"를 반환합니다.
Beam Search는 모든 가능한 다음 스텝들로 확장하고, k가 사용자 지정 파라미터 이며, 빔의 숫자 또는 확률 시퀀스에서 병렬 탐색들을 조절가능한 곳에서 가능한 k를 유지하려고 한다.
사실상 Greedy Inference도 Beam Search의 일종인데, Beam Search의 step이 1이라면 그때는 Greedy Inference와 같다. Beam의 수는 일반적으로 5 또는 10을 사용하고, Beam이 클수록 타겟 시퀀스가 맞을 확률이 높지만 디코딩 속도가 떨어지게 된다.
Attention
Types of Attention
어텐션에는 우리가 곱하고자 하는 값과의 dot product연산을 하는 방법과 Muliplication을 하는 방법, 그대로 더해주는 방법등이 있다.
이러한 기법들이 하는 것은 한가지를 향하고 있는데, 어떤 데이터에 가중치를 더 줘야하는지를 도와주는 하나의 장치라고 생각하면 된다.
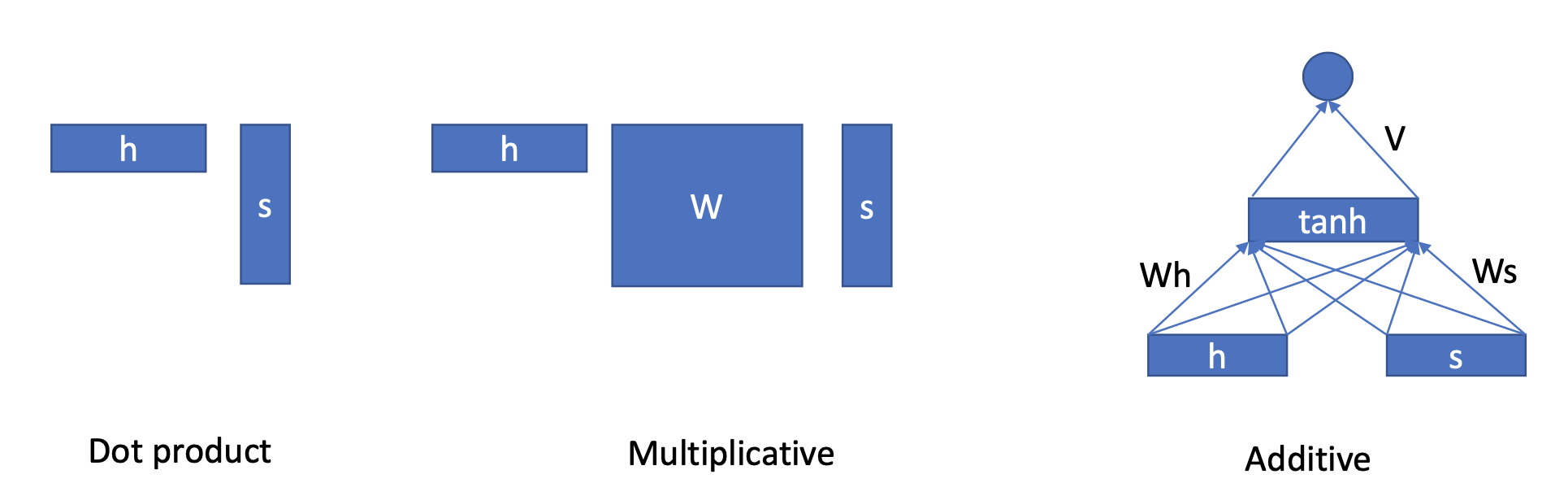
어텐션은 찾아보면 Soft Attention, Hard Attention 등등 다양한 종류의 어텐션들이 존재한다.
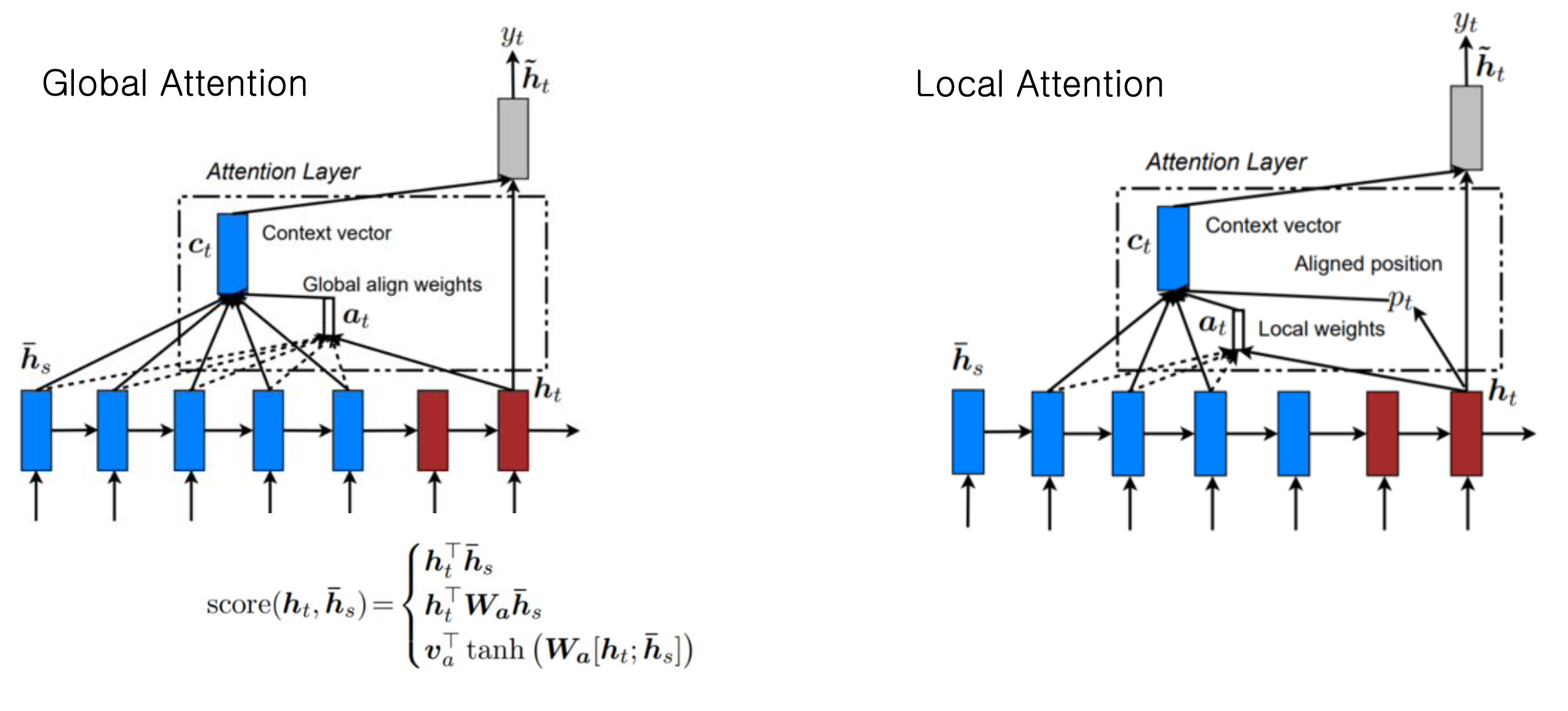
- Global Attention
Global Attention은 전체 source word를 attend한다.
즉, Soft Attention과 비슷하게 모든 데이터에 어텐션을 준다. (강하게 어텐션이 들어가는 부분이 0.9라면 정말 약하게 어텐션이 들어가는 부분 0.01) - Hard Attention
Hard Attention은 SOFT(Global) Attention과 다르게 정말로 중요하다고 생각되는 일부의 정보에만 어텐션을 줍니다. 빠르지만, 미분불가하고 분산감소, 강화학습 등 복잡한 기술을 많이 사용해야합니다.
- Local Attention
Local Attention은 Global Attention(Soft)보다 빠르며, Hard Attention처럼 미분이 안되는 불가피한 상황에서도 사용할 수 있다.