졸업 프로젝트 주제를 결정했다.
구체적인 주제는 못 정했지만 모델 차원의 모달리티 Translation을 통한 연합학습에 대한 내용이 될 것 같다.
교수님께서 제안하신 주제 중 가장 마음에 드는 주제였다. 요즘 핫한 주제인 연합학습과 멀티모달리티를 융합한 주제라 창의적으로 발전시켜나갈 수 있을 것 같았다. 하지만 관련 과목으로 <기계학습> 밖에 수강하지 못해서 스스로 배경 지식이 부족하다고 느꼈다. 그래서 요즘에는 여러 논문들을 찾아서 공부하고 있다. Federated Learning: Challenges, methods, and future directions 는 IEEE Signal Processing Magazine 2020에 실린 글로 연합 학습에 대한 기초적인 설명이 아주 자세히 되어있다.
1. 연합 학습(Federated Learning)이란?
연합 학습은 데이터를 중앙 서버로 모으지 않고, 여러 분산된 장치(예: 스마트폰, 엣지 디바이스)에서 개별적으로 학습을 진행한 후, 각 장치에서 학습된 모델의 업데이트만 중앙 서버로 전송하여 전체 모델을 개선하는 머신러닝 기법이다.
기존의 분산 학습(Distributed Training) 개념과는 약간의 차이가 있다. 중앙 서버에서 데이터를 분배하는 것과 달리, 연합 학습 시스템에서는 각 말단 디바이스가 데이터를 직접 생성, 수집하고 스스로 학습을 한다. 그렇게 학습한 결과를 중앙 서버로 보내서 전체 모델을 업데이트 하는 방식이다. 로컬 데이터는 각 디바이스 내의 학습 과정에서만 사용되고, 서버의 중앙 모델은 그 데이터가 무엇인지 알 수 없어서 개인정보 보호와 보안 측면에서 매우 우수한 방법이다.
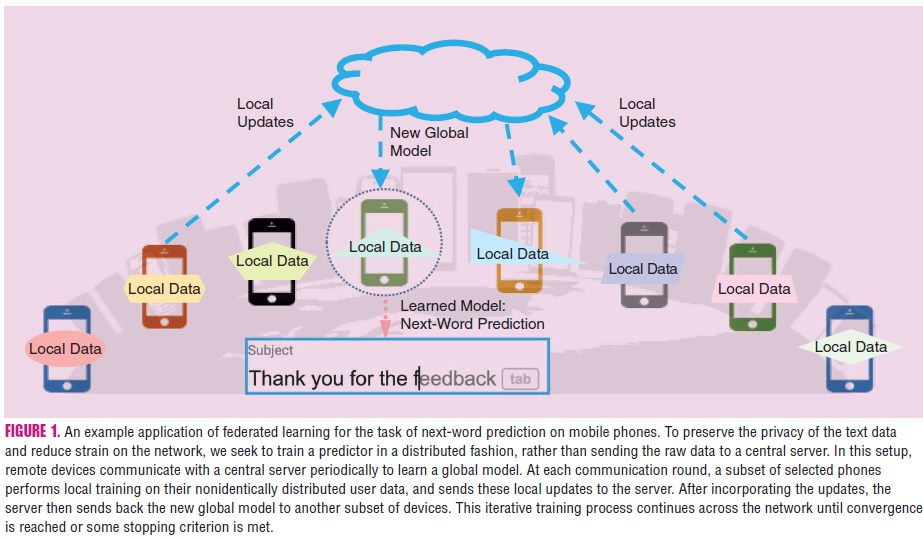
2. 연합 학습의 주요 도전 과제
2.1 통신 비용의 문제 (Expensive Communication)
연합 학습에서는 무수히 많은 말단 디바이스들이 학습 과정에 참여한다. 예를 들어, 수백만 대의 스마트폰이 참여할 수도 있다. 이 수백만 대의 디바이스가 주기적으로 서버와 통신하기 위해서는 매우 큰 communication cost가 발생한다. 데이터들은 각 디바이스 내에서 처리되므로 중앙 서버로 데이터셋을 다 보낼 필요가 없지만, 디바이스의 자원은 제한적이기 때문에 (낮은 bandwidth, energy, power) 여전히 communication cost는 문제가 되고, 이를 줄일 방법들이 제안되고 있다. 두 가지 사항이 고려되는데, 1) 서버와의 통신 횟수를 줄이는 방법 2) 한 번의 통신 과정에서 보내는 메시지 크기를 줄이는 방법이 있다.
2.2 시스템 이질성 (System Heterogeneity)
각 디바이스들이 처한 환경은 제각각이다. 저장 공간(Memory, Storage), 컴퓨팅 파워(Computational Capabilities), 네트워크(Network Connectivity), 전력(Power)가 달라서 데이터를 로컬 환경에서 학습시키는 속도도 제각각이다. 연합 학습 과정에서 각 디바이슨 중앙 서버와 주기적으로 통신을 하는데, 통신이 불가능한 디바이스나(예를 들면, 배터리 용량이 부족하다던가, 네트워크 연결이 되어있지 않은) 아직 계산이 끝나지 않은 디바이스가 있을 수도 있다.
이러한 문제에 대비하기 위해서 아래와 같은 사항들을 고려해야 한다.
1) Anticipate a low amount of participation - 알고리즘은 전체 장치 중 일부만 활성화되는 상황에서도 견딜 수 있어야 하며, 제한된 장치의 기여로도 학습이 진행될 수 있도록 설계되어야 함.
2) Tolerate heterogeneous hardware - 다양한 하드웨어 성능과 능력을 가진 장치들을 수용할 수 있어야 함. 이를 위해 장치 능력에 따라 작업 부하를 조절하거나 학습 속도를 조절하는 기술이 필요할 수 있음.
3) Be robust enough to dropped devices in the communication network - 시스템은 장치 드롭아웃을 원활하게 처리할 수 있어야 함. 이를 위해 결함 탐지, 복구 메커니즘을 마련하고, 장치가 중단되더라도 학습 과정이 크게 방해받지 않도록 해야 함.
2.3 통계적 이질성 (Statistical Heterogeneity)
연합 학습 데이터셋의 특징은 바로 non-identically distributed 되어있다는 것이다. 중앙 서버에서 이상적으로 분포된 데이터를 각 디바이스에 나눠주는 분산 학습과의 큰 차이점이다. 예를 들어, 문자 메시지를 보낼 때 자동 완성을 해 주는 기능을 연합 학습으로 구현했다고 하자. 학습에 참여한 사람마다 자주 쓰는 말이 다르기 때문에 학습 데이터셋은 고르지 않게 분포할 수 밖에 없다. 이런 데이터 분포의 특징 때문에 이미 알려진 분산 최적화 기법을 쓰기에는 무리가 있다. 왜냐하면 분산 최적화에서는 일반적으로 데이터가 독립적이고 동일한 분포를 따른다고 가정하기 때문이다. 따라서 연합학습에서는 이러한 가정이 위반될 수 있고, 통계적 이질성을 극복하기 위한 별도의 학습 과정을 마련해야 한다.
전통적인 연합학습 문제는 하나의 글로벌 모델을 학습하는 것을 목표로 하지만, 통계적 이질성을 다루기 위해 여러 개의 지역 모델을 동시에 학습할 수도 있다. Multitask Learning Framework이나 Metalearning이 그 예시이며, 이렇게 학습시키면 각 장치나 그룹에 맞춘 모델을 개발하여 더 나은 성능과 개인화를 달성할 수 있다.
2.4 개인정보 보호 (Privacy Concerns)
연합 학습은 데이터를 직접 중앙 서버로 보내지 않고, gradient information 같은 모델의 업데이트 결과를 보내므로 개인정보 보호에 유리하다. Secure Multiparty Computation(SMC)이나 Differential Privacy와 같은 기술을 사용하여 연합학습의 개인정보 보호를 강화할 수 있다. 그러나 이들 방법은 데이터를 보호하는 데 도움을 주지만, 모델 성능이나 시스템 효율성에 영향을 미칠 수 있다. 따라서 privacy와 model performance 및 system efficiency간의 trade-off를 고려해서 최적의 균형점을 찾는 것이 필요하다.
3. 이러한 도전 과제들을 해결하기 위한 방법들
3.1 효율적인 통신(Communication)을 위한 방법
3.1.1 Local Updating
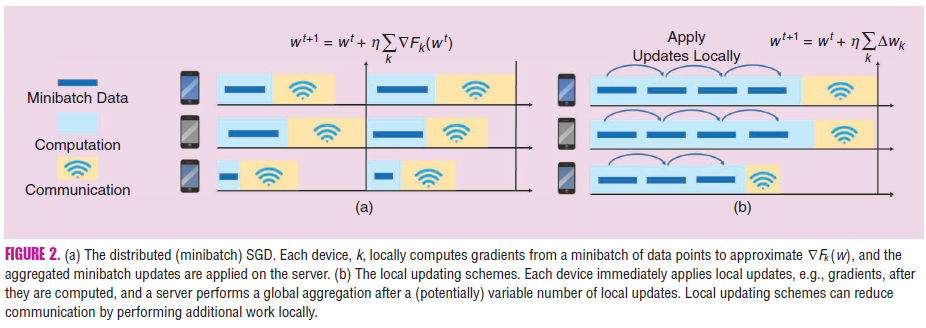
데이터 센터 환경에서는 여러 데이터를 동시에 처리하는 미니배치 최적화가 인기가 있지만, 통신과 계산의 trade-off에 유연하게 대응하기 어려움이 있다. 그래서 각 장치에서 병렬로 업데이트를 적용하여 통신 효율성을 개선할 수 있다.
In response, several recent methods have been proposed to improve communication efficiency in distributed settings by allowing for a variable to be applied on each machine in parallel at each communication round (rather than just computing them locally and then applying them centrally).
convex한 문제에서는 Primal-Dual Method가 효과적이다. 병렬로 해결할 수 있는 하위 문제로 분해하는 방법으로 mini-batch 방법에 비해 큰 성능 향상을 보인다. 연합 학습 환경에서는 로컬 Stochastic Gradient Descent(SGD) 업데이트를 평균화하는 Federated Averaging(FedAvg) 방법을 일반적으로 사용한다. 그런데 이 방법은 non-convex한 문제에 잘 작동하지만, 수렴 보장이 없고 데이터가 이질적일 때 수렴하지 않을 수 있다.
3.1.2 Compression Schemes
통신 횟수를 줄이는 Local Updating 방법도 있지만, 메시지 자체의 크기를 줄이는 압축 기술도 중요하다. Sparsification 은 모델의 파라미터 중 일부를 0으로 만들어 통신할 데이터의 양을 줄이는 방법이다. Quantization은 모델의 파라미터 값을 더 작은 비트 수를 표현하여 데이터 크기를 줄이는 방법이다.
1) Forcing the updating models to be sparse and row rank
2) Performing quantization with structured random rotations
3) Using lossy compression and dropout
같은 실용적인 전략이 제안되었다. 이러한 연구는 비동질적 데이터가 있는 상황에서 저정밀 훈련의 수렴 보장을 탐구했지만, 장치 참여율 저조나 로컬 업데이트 최적화 방법 같은 연합 학습의 특성에 맞게 조정된 접근법이 필요하다.
3.1.3 Decentralized Training
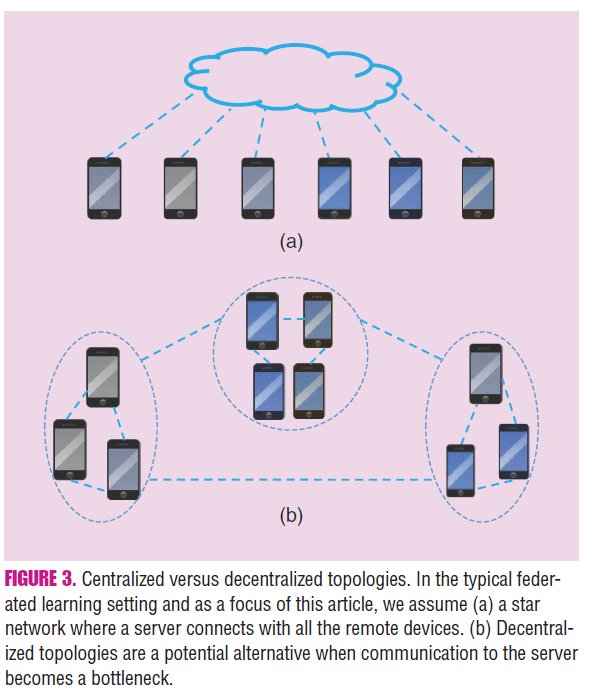
연합 학습에서는 주로 Star Network가 사용된다. 이는 Figure 3(a)처럼 중앙 서버가 여러 장치와 연결된 구조를 말한다. 그런데 Figure 3(b)의 Decentralized Topology를 사용했을 때 속도가 더 빠르고, 중앙 서버의 통신 비용도 줄일 수 있다고 한다. 이런 Decentralized Topology는 연합 학습에서 통신 비용을 줄일 수 있는 잠재력이 있지만, 현재는 선형 모델에 제한되거나 전체 장치 참여를 가정하는 경우가 많아 아직 연구가 더 필요하다.
3.2 System Heterogeneity를 감당하기 위한 방법
3.2.1 Asynchronous Communication
비동기 통신(Asynchronous Communication)은 각 작업자가 독립적으로 실행되며 동기화 없이 진행되는 방식이다. 이 방법은 이질적인 환경에서 지연 문제를 완화하는 데 유용하다. 그러나 연합 학습에서는 지연이 몇 시간에서 며칠까지 또는 무제한일 수 있어서 전통적인 지연 가정이 비현실적일 수 있다.
3.2.2 Active Sampling
Active Sampling은 각 round에서 참여할 장치를 적극적으로 선택하는 접근법이다. 선택 과정에서는 통계적 구조를 고려해야 하는데, 소규모이지만 충분히 대표적인 장치를 샘플링 할 수 있도록 해야한다. 하지만 실시간으로 변동하는 장치의 특성을 고려해야하고, 어떤 기준으로 장치를 선택할 것인가에 대해서는 아직 연구가 더 필요하다.
3.2.3 Fault Tolerance
내결함성(Fault Tolerance)는 시스템의 일부 장치가 학습 과정에서 실패하도라도, 전체 시스템은 계속 작동하도록 보장하는 능력이다. 장치 실패를 효과적으로 처리하기 위한 여러가지 접근법이 제안되고 있는데, FedProx는 시스템 이질성을 처리하기 위해 각 선택된 장치가 시스템 제약에 맞는 부분 작업을 수행하고, 이를 proximal term을 통해 안전하게 통합하는 방식이다. Coded Computation은 데이터 블록과 그래디언트 계산을 복제하여 장치 실패를 해소하는 방법인데, privacy문제와 네트워크 규모 때문에 어려울 수 있다.
3.3 Statistical Heterogeneity를 감당하기 위한 방법
3.3.1 Modeling heterogeneous data
각 디바이스마다 데이터 양이 다르기 때문에 중앙 모델은 데이터 양이 많은 장치에 편향될 수 있다. 장치간 모델 성능의 분산을 줄이기 위해서 아래와 같은 방법들이 연구되고 있다.
1) 지역 손실 기반 업데이트: 장치의 지역 손실에 따라 다양한 수의 로컬 업데이트를 수행.
2) 무차별 연합 학습: 클라이언트 분포의 혼합에 의해 형성된 어떤 목표 분포를 위한 중앙집중 모델을 최적화.
3) q-FFL: 손실이 큰 장치에 상대적으로 높은 가중치를 부여하여 최종 정확도 분포의 변동성을 줄입임.
3.3.2 Convergence Guarantees for non-i.i.d. data
통계적 이질성을 효과적으로 처리하기 위해 FedProx같은 방법을 사용할 수 있다. FedProx는 로컬 업데이트를 초기 글로벌 모델과의 거리를 제한하는 proximal term을 사용하고, 시스템 제약에 따라 작업량을 조절하며, 통계적 이질성을 포착하기 위해 불일치 측정 지표를 사용한다. 이를 통해 데이터의 이질성으로 인한 문제를 줄이고, 모델 학습의 안정성을 높일 수 있다.
3.4 Privacy 향상을 위한 방법
Machine Learning의 privacy 향상을 위한 방법으로는 아래와 같은 방법들이 있다.
1) Differential Privacy: 데이터의 개별 요소가 결과에 미치는 영향을 최소화하여, 특정 샘플이 학습 과정에 포함되었는지 여부를 추론할 수 없게 한다. 이는 알고리즘의 출력에 랜덤 노이즈를 추가하는 방식으로 동작한다. 그러나 많은 노이즈는 모델 정확도를 낮출 수 있다.
2) Homomorphic Encryption: 암호화된 데이터에서 직접 계산을 수행하여 데이터를 암호화된 상태로 유지한다. 보안성이 매우 높지만, 추가적인 계산 및 통신 비용이 발생한다. 따라서 대규모 데이터 처리에는 제한적이다.
3) Secure Function Evaluation (SFE) / Multiparty Computation (SMC): 여러 당사자가 협력하여 합의된 함수를 계산하되, 각 당사자의 입력 정보는 출력에서 추론할 수 있는 정보 외에는 유출되지 않도록 한다.
Federated Learning의 privacy는 global하게, 동시에 local하게 보장되어야 한다. 현재 주로 연구되는 방법은 기존의 암호화 프로토콜(예: SMC) 및 차별적 프라이버시를 기반이다. K. Bonawitz et al. “Practical secure aggregation for privacy-preserving machine learning" 를 참고하면 데이터 프라이버시를 유지하면서도 협력적 학습을 가능하게 하는 방법을 배울 수 있을 것이다.
연합 학습의 다양한 도전과제에 대해 배울 수 있었다. 우리는 멀티 모달리티를 다루는 연합 학습을 연구하려고 하는데, 세부적으로 어떤 방향으로 갈 지는 아직 정하지 못했다. 현재 가장 끌리는 연구 주제는 "모달리티 Translation 과정에서 추가적으로 발생하는 cost에 대한 측정과 이를 최소화 할 수 있는 방법"이다. Communication Cost를 줄이는 방법이 가장 흥미롭다. 일단 멀티모달에 관한 논문을 추가적으로 읽어보고, 멀티 모달 딥러닝의 특성과 한계점에 대해 더 알아보고 결정해야 할 것 같다.
